|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Vorlesungsunterlagen, Spickzettel
Informatik und Informationstechnologien. Spickzettel: kurz das Wichtigste
Verzeichnis / Vorlesungsunterlagen, Spickzettel Inhaltsverzeichnis
1. Informatik. Information Darstellung und Verarbeitung / Auskunft. Zahlensysteme Die Informatik beschäftigt sich mit einer formalisierten Darstellung von Objekten und Strukturen ihrer Beziehungen in verschiedenen Bereichen der Wissenschaft, Technik und Produktion. Zur Modellierung von Objekten und Phänomenen werden verschiedene formale Werkzeuge verwendet, wie logische Formeln, Datenstrukturen, Programmiersprachen usw. In der Informatik hat ein so grundlegender Begriff wie Information verschiedene Bedeutungen: 1) formelle Darstellung externer Informationsformen; 2) abstrakte Bedeutung von Informationen, ihr interner Inhalt, Semantik; 3) Beziehung von Informationen zur realen Welt. Aber in der Regel wird Information als ihre abstrakte Bedeutung verstanden - Semantik. Wenn wir uns austauschen wollen, brauchen wir übereinstimmende Ansichten, damit die Richtigkeit der Interpretation nicht verletzt wird. Dazu wird die Interpretation der Darstellung von Informationen mit einigen mathematischen Strukturen identifiziert. In diesem Fall kann die Informationsverarbeitung durch rigorose mathematische Methoden durchgeführt werden. Eine der mathematischen Beschreibungen von Informationen ist ihre Darstellung als Funktion y = f(x,t) Wo t ist Zeit, x ist ein Punkt in einem Feld, wo der Wert von y gemessen wird. Abhängig von den Funktionsparametern x und t können Informationen klassifiziert werden. Wenn es sich bei den Parametern um skalare Größen handelt, die eine kontinuierliche Reihe von Werten annehmen, werden die auf diese Weise erhaltenen Informationen als kontinuierlich (oder analog) bezeichnet. Wird den Parametern ein bestimmter Änderungsschritt gegeben, so spricht man von diskreten Informationen. Diskrete Informationen gelten als universell. Diskrete Informationen werden üblicherweise mit digitalen Informationen identifiziert, die ein Sonderfall symbolischer Informationen alphabetischer Repräsentation sind. Ein Alphabet ist eine endliche Menge von Symbolen jeglicher Art. Sehr oft tritt in der Informatik eine Situation auf, in der die Zeichen eines Alphabets durch die Zeichen eines anderen repräsentiert werden müssen, d. h. um eine Codierungsoperation durchzuführen. Wie die Praxis gezeigt hat, ist das einfachste Alphabet, mit dem Sie andere Alphabete codieren können, binär und besteht aus zwei Zeichen, die normalerweise mit 0 und 1 bezeichnet werden. Mit n Zeichen des binären Alphabets können Sie 2n Zeichen codieren, und das reicht aus um ein beliebiges Alphabet zu codieren. Der Wert, der durch ein Symbol des binären Alphabets dargestellt werden kann, wird als minimale Informationseinheit oder Bit bezeichnet. Folge von 8 Bits - Bytes. Ein Alphabet, das 256 verschiedene 8-Bit-Folgen enthält, wird als Byte-Alphabet bezeichnet. Ein Zahlensystem ist eine Reihe von Regeln für die Benennung und Schreibweise von Zahlen. Es gibt positionelle und nicht-positionale Zahlensysteme. Das Zahlensystem wird Positional genannt, wenn der Wert der Ziffer der Zahl von der Position der Ziffer in der Zahl abhängt. Andernfalls wird es als nichtpositional bezeichnet. Der Wert einer Zahl wird durch die Position dieser Ziffern in der Zahl bestimmt. 2. Darstellung von Zahlen in einem Computer. Formalisiertes Konzept eines Algorithmus 32-Bit-Prozessoren können mit bis zu 232-1 RAM arbeiten, und Adressen können im Bereich 00000000 - FFFFFFFF geschrieben werden. Im Real-Modus arbeitet der Prozessor jedoch mit einem Speicher von bis zu 220-1, und Adressen fallen in den Bereich von 00000 bis FFFFF. Speicherbytes können zu Feldern sowohl fester als auch variabler Länge kombiniert werden. Ein Wort ist ein Feld fester Länge bestehend aus 2 Bytes, ein Doppelwort ist ein Feld von 4 Bytes. Feldadressen können gerade oder ungerade sein, wobei gerade Adressen Operationen schneller ausführen. Festkommazahlen werden in Computern als ganzzahlige Binärzahlen dargestellt und können 1, 2 oder 4 Bytes groß sein. Ganzzahlige Binärzahlen werden im Zweierkomplement dargestellt. Der Komplementcode einer positiven Zahl ist gleich der Zahl selbst, und der Komplementcode einer negativen Zahl kann mit der folgenden Formel erhalten werden: x = 10n - \x\, wobei n die Bittiefe der Zahl ist. Im binären Zahlensystem erhält man einen zusätzlichen Code durch Invertieren von Bits, d. h. Ersetzen von Einheiten durch Nullen und umgekehrt, und Addieren von Eins zum niedrigstwertigen Bit. Die Anzahl der Bits der Mantisse bestimmt die Genauigkeit der Darstellung von Zahlen, die Anzahl der Maschinenordnungsbits bestimmt den Darstellungsbereich von Gleitkommazahlen. Formalisiertes Konzept eines Algorithmus Ein Algorithmus kann nur existieren, wenn gleichzeitig ein mathematisches Objekt existiert. Das formalisierte Konzept eines Algorithmus ist mit dem Konzept rekursiver Funktionen, normaler Markov-Algorithmen, Turing-Maschinen verbunden. In der Mathematik wird eine Funktion als einwertig bezeichnet, wenn es für einen beliebigen Satz von Argumenten ein Gesetz gibt, durch das der eindeutige Wert der Funktion bestimmt wird. Ein Algorithmus kann als solches Gesetz wirken; in diesem Fall heißt die Funktion berechenbar. Rekursive Funktionen sind eine Unterklasse von berechenbaren Funktionen, und die Algorithmen, die die Berechnungen definieren, werden als begleitende rekursive Funktionsalgorithmen bezeichnet. Erstens werden die grundlegenden rekursiven Funktionen festgelegt, für die der begleitende Algorithmus trivial und eindeutig ist; dann werden drei Regeln eingeführt - Substitutions-, Rekursions- und Minimierungsoperatoren, mit deren Hilfe komplexere rekursive Funktionen auf der Grundlage von Grundfunktionen erhalten werden. Die Grundfunktionen und ihre begleitenden Algorithmen können sein: 1) eine Funktion von n unabhängigen Variablen, identisch gleich Null. Wenn das Vorzeichen der Funktion dann φn ist, dann sollte der Wert der Funktion unabhängig von der Anzahl der Argumente gleich Null gesetzt werden; 2) die Identitätsfunktion von n unabhängigen Variablen der Form Ψ ni. Dann, wenn das Vorzeichen der Funktion Ψ ni ist, dann sollte der Wert der Funktion als der Wert des i-ten Arguments genommen werden, von links nach rechts gezählt; 3) λ-Funktion eines unabhängigen Arguments. Wenn das Vorzeichen der Funktion dann λ ist, dann sollte der Wert der Funktion als der Wert genommen werden, der dem Wert des Arguments folgt. 3. Einführung in die Sprache Pascal Die Grundsymbole der Sprache – Buchstaben, Zahlen und Sonderzeichen – bilden ihr Alphabet. Die Pascal-Sprache enthält den folgenden Satz grundlegender Symbole: 1) 26 lateinische Kleinbuchstaben und 26 lateinische Großbuchstaben: 2) _ (Unterstrich); 3) 10 Ziffern: 0 1 2 3 4 5 6 7 8 9; 4) Betriebszeichen: + - O / = <> < > <= >= := @; 5) Trennzeichen:., ( ) [ ] (..) { } (* *).. : ; 6) Spezifizierer: ^ # $; 7) Dienstwörter (reserviert): ABSOLUTE, ASSEMBLER, AND, ARRAY, ASM, BEGIN, CASE, CONST, CONSTRUCTOR, DESTRUCTOR, DIV, DO, DOWNTO, ELSE, END, EXPORT, EXTERNAL, FAR, FILE, FOR, FORWARD, FUNCTION, GOTO, IF, IMPLEMENTATION, IN, INDEX, INHERITED, INLINE, INTERFACE, INTERRUPT, LABEL, LIBRARY, MOD, NAME, NIL, NEAR, NOT, OBJECT, OF, OR, PACKED, PRIVATE, PROCEDURE, PROGRAMM, ÖFFENTLICH, AUFNAHME, WIEDERHOLEN, RESIDENT, SET, SHL, SHR, STRING, DANN, BIS, TYP, EINHEIT, BIS, VERWENDUNG, VAR, VIRTUELL, WÄHREND, MIT, XOR. Zusätzlich zu den aufgeführten enthält der Satz von Grundzeichen ein Leerzeichen. In Pascal gibt es eine Regel: Der Typ wird explizit in der Deklaration einer Variablen oder Funktion angegeben, die ihrer Verwendung vorausgeht. Das Pascal-Typkonzept hat die folgenden Haupteigenschaften: 1) Jeder Datentyp definiert eine Menge von Werten, zu denen eine Konstante gehört, die eine Variable oder ein Ausdruck annehmen oder eine Operation oder Funktion erzeugen kann; 2) die Art des Werts, der durch eine Konstante, Variable oder einen Ausdruck gegeben wird, kann durch ihre Form oder Beschreibung bestimmt werden; 3) Jede Operation oder Funktion erfordert Argumente mit festem Typ und erzeugt ein Ergebnis mit festem Typ. In Pascal gibt es skalare und strukturierte Datentypen. Skalare Typen umfassen Standardtypen und benutzerdefinierte Typen. Zu den Standardtypen gehören Integer-, Real-, Character-, Boolean- und Adresstypen. Integer-Typen definieren Konstanten, Variablen und Funktionen, deren Werte durch den Satz von Integern realisiert werden, die in einem bestimmten Computer zulässig sind. Pascal hat die folgende Operatorpriorität:
1) Berechnungen in Klammern; 2) Berechnung von Funktionswerten; 3) unäre Operationen; 4) Operationen * / div mod und; 5) Operationen + - oder xor; 6) Beziehungsoperationen = <> < > <= >=. 4. Standardverfahren und -funktionen Arithmetische Funktionen 1. Funktion Abs (X); gibt den absoluten Wert des Parameters zurück. 2. Funktion ArcTan(X: Extended): Erweitert; gibt den Arkustangens des Arguments zurück. 3. Funktion Exp(X: Real): Real; gibt den Exponenten zurück. 4.Frac(X: Real): Real; gibt den Bruchteil des Arguments zurück. 5. Funktion Int(X: Real): Real; gibt den ganzzahligen Teil des Arguments zurück. 6. Funktion Ln(X: Real): Real; gibt den natürlichen Logarithmus (Ln e = 1) eines reellen Ausdrucks x zurück. 7.Funktion Pi: Erweitert; gibt den Wert Pi zurück, der als 3.1415926535 definiert ist. 8.Funktion Sin (X: Erweitert): Erweitert; gibt den Sinus des Arguments zurück. 9.Funktion Sqr (X: Erweitert): Erweitert; gibt das Quadrat des Arguments zurück. 10.Funktion Sqrt (X: Erweitert): Erweitert; gibt die Quadratwurzel des Arguments zurück. Verfahren und Funktionen zur Wertumwandlung 1. Prozedur Str(X [: Breite [: Dezimalstellen]]; var S); wandelt die Zahl X in eine Zeichenfolgendarstellung um. 2. Funktion Chr(X: Byte): Char; gibt das Zeichen mit der Indexnummer x in der ASCII-Tabelle zurück. 3.Funktion hoch (X); gibt den größten Wert im Bereich des Parameters zurück. 4.FunktionLow(X); gibt den kleinsten Wert im Bereich des Parameters zurück. 5.Funktion Ord(X): LongInt; gibt den Ordinalwert eines Aufzählungstypausdrucks zurück. 6. Funktion Round(X: Extended): LongInt; rundet einen reellen Wert auf eine ganze Zahl. 7. Funktion Trunc(X: Extended): LongInt; schneidet einen reellen Typwert auf eine ganze Zahl ab. 8. Prozedur Val(S; var V; var Code: Integer); konvertiert eine Zahl von einem Zeichenfolgenwert S in eine numerische Darstellung V. Ordinalwertprozeduren und -funktionen 1. Prozedur Dec(var X [; N: LongInt]); subtrahiert eins oder N von der Variablen X. 2. Prozedur Inc(var X [; N: LongInt]); addiert eins oder N zur Variablen X. 3. Funktion Odd(X: LongInt): Boolean; gibt True zurück, wenn X eine ungerade Zahl ist, andernfalls False. 4.FunktionPred(X); gibt den vorherigen Wert des Parameters zurück. 5 Funktion Succ(X); gibt den nächsten Parameterwert zurück. 5. Pascal-Sprachoperatoren Bedingter Operator Das Format einer vollständigen bedingten Anweisung ist wie folgt definiert: Wenn B dann S1 sonst S2 wobei B eine Verzweigungs-(Entscheidungs-)Bedingung, ein logischer Ausdruck oder eine Beziehung ist; S1, S2 - eine ausführbare Anweisung, einfach oder zusammengesetzt. Bei der Ausführung einer bedingten Anweisung wird zuerst der Ausdruck B ausgewertet, dann wird sein Ergebnis analysiert: Wenn B wahr ist, wird die Anweisung S1 ausgeführt - die Verzweigung von then und die Anweisung S2 wird übersprungen; wenn B falsch ist, dann wird die Anweisung S2 - der Else-Zweig ausgeführt und die Anweisung S1 übersprungen. Auswahloperator Die Betreiberstruktur ist wie folgt: Fälle von c1: Anweisung1; c2: Anweisung2; ... cn: AnweisungN; sonst Anleitung end; wobei S ein ordinaler Ausdruck ist, dessen Wert berechnet wird; c1, c2,..., on – Konstanten vom Ordinaltyp, mit denen Ausdrücke S verglichen werden; Anweisungl,..., AnweisungN – Operatoren, von denen derjenige ausgeführt wird, dessen Konstante mit dem Wert des Ausdrucks S übereinstimmt; Anweisung - ein Operator, der ausgeführt wird, wenn der Wert des Ausdrucks S mit keiner der Konstanten c1, o2, on übereinstimmt. Schleifenanweisung mit Parameter Wenn die for-Anweisung ausgeführt wird, werden die Start- und Endwerte einmal bestimmt, und diese Werte werden während der gesamten Ausführung der for-Anweisung beibehalten. Die im Hauptteil der for-Anweisung enthaltene Anweisung wird einmal für jeden Wert im Bereich zwischen Start- und Endwert ausgeführt. Der Schleifenzähler wird immer auf einen Anfangswert initialisiert. Schleifenanweisung mit Vorbedingung Während B S tut; wobei B eine logische Bedingung ist, deren Wahrheitsgehalt überprüft wird (es ist eine Bedingung zum Beenden der Schleife)$; S - Schleifenkörper - eine Anweisung. Der Ausdruck, der die Wiederholung einer Anweisung steuert, muss vom Typ Boolean sein. Es wird ausgewertet, bevor die innere Anweisung ausgeführt wird. Die innere Anweisung wird wiederholt ausgeführt, solange der Ausdruck zu Trie ausgewertet wird. Wenn der Ausdruck von Anfang an mit False ausgewertet wird, wird die in der Vorbedingungsschleifenanweisung enthaltene Anweisung nicht ausgeführt. Schleifenanweisung mit Nachbedingung S bis B wiederholen; wobei B eine logische Bedingung ist, deren Wahrheit überprüft wird (es ist eine Bedingung zum Beenden der Schleife); S - eine oder mehrere Schleifenkörperanweisungen. Das Ergebnis des Ausdrucks muss vom Typ Boolean sein. Die zwischen den Schlüsselwörtern repeat und until eingeschlossenen Anweisungen werden nacheinander ausgeführt, bis das Ergebnis des Ausdrucks wahr ist. Die Anweisungsfolge wird mindestens einmal ausgeführt, da der Ausdruck nach jeder Ausführung der Anweisungsfolge ausgewertet wird. 6. Das Konzept eines Hilfsalgorithmus Der Problemlösungsalgorithmus wird entworfen, indem das gesamte Problem in separate Teilaufgaben zerlegt wird. Typischerweise werden Subtasks als Subroutinen implementiert. Ein Unterprogramm ist ein Hilfsalgorithmus, der wiederholt im Hauptalgorithmus mit unterschiedlichen Werten einiger eingehender Größen, Parameter genannt, verwendet wird. Ein Unterprogramm in Programmiersprachen ist eine Folge von Anweisungen, die nur an einer Stelle im Programm definiert und geschrieben sind, aber von einer oder mehreren Stellen im Programm zur Ausführung aufgerufen werden können. Jede Subroutine wird durch einen eindeutigen Namen identifiziert. Es gibt zwei Arten von Subroutinen in Pascal, Prozeduren und Funktionen. Eine Prozedur und eine Funktion sind eine benannte Folge von Deklarationen und Anweisungen. Bei der Verwendung von Prozeduren oder Funktionen muss das Programm den Text der Prozedur oder Funktion und einen Aufruf der Prozedur oder Funktion enthalten. Die in der Beschreibung angegebenen Parameter heißen formal, die im Aufruf des Unterprogramms angegebenen heißen aktuell. Alle formalen Parameter lassen sich in folgende Kategorien einteilen: 1) Parameter-Variablen; 2) konstante Parameter; 3) Parameterwerte; 4) Prozedurparameter und Funktionsparameter, d. h. prozedurale Parameter; 5) untypisierte variable Parameter. Die Texte der Prozeduren und Funktionen werden in die Beschreibungen der Prozeduren und Funktionen gestellt. Prozedur- und Funktionsnamen als Parameter übergeben Bei vielen Problemen, insbesondere in der Computermathematik, ist es notwendig, die Namen von Prozeduren und Funktionen als Parameter zu übergeben. Dazu hat TURBO PASCAL einen neuen Datentyp eingeführt – prozedural oder funktional, je nachdem, was beschrieben wird. (Prozedur- und Funktionstypen werden im Abschnitt Typdeklaration beschrieben.) Ein Funktions- und Prozedurtyp ist definiert als die Überschrift einer Prozedur und eine Funktion mit einer Liste formaler Parameter, aber ohne Namen. Es ist möglich, eine Funktion oder einen Prozedurtyp ohne Parameter zu definieren, zum Beispiel: tippe Proc = Prozedur; Nachdem ein prozeduraler oder funktionaler Typ deklariert wurde, kann er verwendet werden, um formale Parameter zu beschreiben – die Namen von Prozeduren und Funktionen. Außerdem ist es notwendig, solche realen Prozeduren oder Funktionen zu schreiben, deren Namen als Aktualparameter übergeben werden. 7. Prozeduren und Funktionen in Pascal Prozeduren in Pascal Die Beschreibung der Prozedur besteht aus einem Header und einem Block, die sich bis auf den Modulanschlussabschnitt nicht vom Programmblock unterscheiden. Der Header besteht aus dem Schlüsselwort Procedure, dem Namen der Prozedur und einer optionalen Liste formaler Parameter in Klammern: Prozedur <Name> [(<Liste formaler Parameter>)]; Für jeden Formalparameter muss sein Typ definiert werden. Parametergruppen in einer Prozedurbeschreibung werden durch Semikolons getrennt. Der Aufbau des Verfahrens ist dem Programm fast vollständig ähnlich. Es gibt jedoch keinen Modulverbindungsabschnitt im Prozedurblock. Der Block besteht aus zwei Teilen: beschreibend und ausführend. Der beschreibende Teil enthält eine Beschreibung der Elemente des Verfahrens. Und im Ausführungsteil werden Aktionen mit Programmelementen angegeben, auf die die Prozedur zugreifen kann (z. B. globale Variablen und Konstanten), die es ermöglichen, das gewünschte Ergebnis zu erhalten. Der Anweisungsteil einer Prozedur unterscheidet sich vom Anweisungsteil eines Programms nur dadurch, dass das Schlüsselwort end den Abschnitt mit einem Semikolon statt mit einem Punkt abschließt. Eine Prozeduraufrufanweisung wird verwendet, um eine Prozedur aufzurufen. Sie besteht aus dem Namen der Prozedur und einer in Klammern eingeschlossenen Liste von Argumenten. Die Anweisungen, die beim Ausführen der Prozedur ausgeführt werden sollen, sind im Anweisungsteil des Prozedurmoduls enthalten. Manchmal möchten Sie, dass sich eine Prozedur selbst aufruft. Diese Art des Aufrufs wird als Rekursion bezeichnet. Die Rekursion ist in Fällen nützlich, in denen die Hauptaufgabe in Teilaufgaben unterteilt werden kann, von denen jede nach einem Algorithmus implementiert wird, der mit der Hauptaufgabe übereinstimmt. Funktionen in Pascal Eine Funktionsdeklaration definiert den Teil des Programms, in dem der Wert berechnet und zurückgegeben wird. Eine Funktionsbeschreibung besteht aus einem Header und einem Block. Der Header enthält das Schlüsselwort Function, den Namen der Funktion, eine optionale Liste formaler Parameter in Klammern und den Rückgabetyp der Funktion. Die allgemeine Form des Funktionskopfes ist wie folgt: Funktion <Name> [(<Liste formaler Parameter>)]: <Rückgabetyp>; In der Borland-Implementierung von Turbo Pascal 7.0 kann der Rückgabewert einer Funktion kein zusammengesetzter Typ sein. Und die Sprache Object Pascal, die in den integrierten Entwicklungsumgebungen von Borland Delphi verwendet wird, erlaubt jede Art von Rückgabeergebnis, mit Ausnahme des Dateityps. Ein Funktionsblock ist ein lokaler Block, ähnlich aufgebaut wie ein Prozedurblock. Der Rumpf einer Funktion muss mindestens eine Zuweisungsanweisung enthalten, auf deren linker Seite der Name der Funktion steht. Sie bestimmt den von der Funktion zurückgegebenen Wert. Bei mehreren solcher Anweisungen ist das Ergebnis der Funktion der Wert der zuletzt ausgeführten Zuweisungsanweisung. Die Funktion wird aktiviert, wenn die Funktion aufgerufen wird. Wenn eine Funktion aufgerufen wird, werden die Funktionskennung und alle Parameter angegeben, die zum Auswerten der Funktion erforderlich sind. Ein Funktionsaufruf kann als Operand in Ausdrücke eingefügt werden. Wenn der Ausdruck ausgewertet wird, wird die Funktion ausgeführt und der Wert des Operanden wird zum Rückgabewert der Funktion. Der Operatorteil des Funktionsblocks gibt die Anweisungen an, die ausgeführt werden müssen, wenn die Funktion aktiviert wird. Ein Modul muss mindestens eine Zuweisungsanweisung enthalten, die einem Funktionsbezeichner einen Wert zuweist. Das Ergebnis der Funktion ist der zuletzt zugewiesene Wert. Existiert keine solche Zuweisungsanweisung oder wurde sie nicht ausgeführt, so ist der Rückgabewert der Funktion undefiniert. Wird beim Aufruf einer Funktion innerhalb eines Moduls ein Funktionsbezeichner verwendet - eine Funktion, dann wird die Funktion rekursiv ausgeführt. 8. Weiterleitungsbeschreibungen und Verbindung von Unterprogrammen. Richtlinie Ein Programm kann mehrere Unterprogramme enthalten, d. h. die Struktur des Programms kann kompliziert sein. Diese Subroutinen können sich jedoch auf derselben Verschachtelungsebene befinden, daher muss die Deklaration der Subroutine zuerst kommen und dann der Aufruf, es sei denn, es wird eine spezielle Vorwärtsdeklaration verwendet. Eine Prozedurdeklaration, die anstelle eines Anweisungsblocks eine Vorwärtsdirektive enthält, wird als Vorwärtsdeklaration bezeichnet. Irgendwo nach dieser Deklaration muss eine Prozedur durch eine definierende Deklaration definiert werden. Eine definierende Deklaration ist eine Deklaration, die denselben Prozedurbezeichner verwendet, aber die Liste der formalen Parameter weglässt und einen Anweisungsblock enthält. Die Vorwärtsdeklaration und die definierende Deklaration müssen im selben Teil der Prozedur- und Funktionsdeklaration erscheinen. Dazwischen können weitere Prozeduren und Funktionen deklariert werden, die auf die Forward-Declaration-Prozedur verweisen können. Somit ist eine gegenseitige Rekursion möglich. Die Vorwärtsbeschreibung und die Definitionsbeschreibung sind die vollständige Beschreibung des Verfahrens. Das Verfahren gilt als unter Verwendung der Vorwärtsbeschreibung beschrieben. Wenn das Programm ziemlich viele Unterroutinen enthält, ist das Programm nicht mehr visuell und es ist schwierig, darin zu navigieren. Um dies zu vermeiden, werden einige Unterprogramme als Quelldateien auf der Festplatte gespeichert und bei Bedarf über eine Kompilierungsdirektive mit dem Hauptprogramm beim Kompilieren verbunden. Eine Direktive ist ein spezieller Kommentar, der überall in einem Programm platziert werden kann, wo ein normaler Kommentar stehen kann. Sie unterscheiden sich jedoch dadurch, dass die Direktive eine spezielle Notation hat: Direkt nach der schließenden Klammer ohne Leerzeichen wird das $-Zeichen geschrieben und dann wieder ohne Leerzeichen die Direktive angegeben. Beispiel: 1) {$E+} - mathematischen Koprozessor emulieren; 2) {$F+} - bilden den fernen Typ von aufrufenden Prozeduren und Funktionen; 3) {$N+} - mathematischen Koprozessor verwenden; 4) {$R+} - Prüfen Sie, ob die Bereiche außerhalb der Grenzen liegen. Einige Kompilierungsschalter können einen Parameter enthalten, zum Beispiel: {$I Dateiname} - fügt die benannte Datei in den Text des kompilierten Programms ein 9. Unterprogrammparameter Die Beschreibung einer Prozedur oder Funktion spezifiziert eine Liste formaler Parameter. Jeder Parameter, der in einer formalen Parameterliste deklariert ist, ist lokal für die beschriebene Prozedur oder Funktion und kann in dem Modul, das dieser Prozedur oder Funktion zugeordnet ist, durch seine Kennung angesprochen werden. Es gibt drei Arten von Parametern: Wert, Variable und nicht typisierte Variable. Sie sind wie folgt gekennzeichnet: 1. Eine Gruppe von Parametern ohne vorangestelltes Schlüsselwort ist eine Liste von Wertparametern. 2. Eine Gruppe von Parametern, denen das Schlüsselwort const vorangestellt ist und auf die ein Typ folgt, ist eine Liste konstanter Parameter. 3. Eine Gruppe von Parametern, denen das Schlüsselwort var vorangestellt ist und auf die ein Typ folgt, ist eine Liste variabler Parameter. Wertparameter Ein formaler Wertparameter wird wie eine lokale Variable einer Prozedur oder Funktion behandelt, mit der Ausnahme, dass er seinen Anfangswert vom entsprechenden tatsächlichen Parameter erhält, wenn die Prozedur oder Funktion aufgerufen wird. Änderungen, die ein formaler Wertparameter erfährt, wirken sich nicht auf den Wert des tatsächlichen Parameters aus. Der entsprechende Istwert-Parameterwert muss ein Ausdruck sein, und sein Wert darf kein Dateityp oder ein Strukturtyp sein, der einen Dateityp enthält. Der Aktualparameter muss von einem Typ sein, der zuweisungskompatibel zum Typ des formalen Wertparameters ist. Wenn der Parameter vom Typ String ist, dann hat der formale Parameter ein Größenattribut von 255. Konstante Parameter Im Hauptteil einer Subroutine kann der Wert eines konstanten Parameters nicht geändert werden. Parameter-Konstanten können verwendet werden, um diejenigen Parameter anzuordnen, deren Änderungen im Unterprogramm unerwünscht sind und verboten werden sollten. Variable Parameter Ein variabler Parameter wird verwendet, wenn ein Wert von einem Unterprogramm an einen aufrufenden Block übergeben werden muss. In diesem Fall wird beim Aufruf des Unterprogramms der formale Parameter durch das Variablenargument ersetzt, und alle Änderungen am formalen Parameter werden im Argument widergespiegelt. Prozedurale Variablen Nach der Definition eines prozeduralen Typs wird es möglich, Variablen dieses Typs zu beschreiben. Solche Variablen werden als prozedurale Variablen bezeichnet. Wie einer ganzzahligen Variablen, der ein Wert eines ganzzahligen Typs zugewiesen werden kann, kann einer prozeduralen Variablen ein Wert eines prozeduralen Typs zugewiesen werden. Ein solcher Wert könnte natürlich eine andere Prozedurvariable sein, aber es könnte auch eine Prozedur- oder Funktionskennung sein. Die Deklaration einer Prozedur oder Funktion kann in diesem Zusammenhang als Beschreibung einer speziellen Art von Konstanten angesehen werden, deren Wert die Prozedur oder Funktion ist. Wie bei jeder anderen Zuweisung müssen die Werte der Variablen auf der linken Seite und auf der rechten Seite zuweisungskompatibel sein. Prozedurale Typen müssen, um zuweisungskompatibel zu sein, die gleiche Anzahl von Parametern haben, und die Parameter an den entsprechenden Positionen müssen vom gleichen Typ sein. Parameternamen in einer prozeduralen Typdeklaration haben keine Auswirkung. Um die Zuweisungskompatibilität sicherzustellen, darf eine Prozedur oder Funktion, wenn sie einer Prozedurvariablen zugewiesen werden soll, außerdem nicht standardmäßig oder verschachtelt sein. 10. Arten von Unterprogrammparametern Wertparameter Ein formaler Wertparameter wird als lokale Variable behandelt; er erhält seinen Anfangswert vom entsprechenden tatsächlichen Parameter, wenn die Prozedur oder Funktion aufgerufen wird. Änderungen, die ein formaler Wertparameter erfährt, wirken sich nicht auf den Wert des tatsächlichen Parameters aus. Der entsprechende tatsächliche Wert des Wertparameters muss ein Ausdruck sein, und sein Wert darf kein Dateityp sein. Konstante Parameter Formale konstante Parameter erhalten ihren Wert, wenn eine Prozedur oder Funktion aufgerufen wird. Zuweisungen an einen formal konstanten Parameter sind nicht erlaubt. Ein formal konstanter Parameter kann nicht als aktueller Parameter an eine andere Prozedur oder Funktion übergeben werden. Variable Parameter Ein variabler Parameter wird verwendet, wenn ein Wert von einer Prozedur oder Funktion an das aufrufende Programm übergeben werden muss. Bei Aktivierung wird die formale Parameter-Variable durch die tatsächliche Variable ersetzt, Änderungen an der formalen Parameter-Variable werden in den tatsächlichen Parameter übernommen. Nicht typisierte Parameter Wenn der formale Parameter ein untypisierter variabler Parameter ist, dann kann der entsprechende tatsächliche Parameter eine variable oder konstante Referenz sein. Ein mit dem Schlüsselwort var deklarierter nicht typisierter Parameter kann geändert werden, während ein mit dem Schlüsselwort const deklarierter nicht typisierter Parameter schreibgeschützt ist. Prozedurale Variablen Nach der Definition eines prozeduralen Typs wird es möglich, Variablen dieses Typs zu beschreiben. Solche Variablen werden als prozedurale Variablen bezeichnet. Einer prozeduralen Variablen kann ein Wert eines prozeduralen Typs zugewiesen werden. Die Prozedur oder Funktion bei der Zuweisung muss sein: 1) nicht serienmäßig; 2) nicht verschachtelt; 3) keine Prozedur vom Typ Inline; 4) nicht durch die Interrupt-Prozedur. Prozedurale Parameter Da prozedurale Typen in jedem Kontext verwendet werden können, ist es möglich, Prozeduren oder Funktionen zu beschreiben, die Prozeduren und Funktionen als Parameter annehmen. Prozedurale Parameter sind besonders nützlich, wenn Sie eine gemeinsame Aktion für mehrere Prozeduren oder Funktionen ausführen müssen. Wenn eine Prozedur oder Funktion als Parameter übergeben werden soll, muss sie denselben Typkompatibilitätsregeln folgen wie die Zuweisung. Das heißt, solche Prozeduren oder Funktionen müssen mit der far-Direktive kompiliert werden, sie können keine eingebauten Funktionen sein, sie können nicht verschachtelt werden und sie können nicht mit den Inline- oder Interrupt-Attributen beschrieben werden. 11. Zeichenfolge in Pascal eingeben. Prozeduren und Funktionen für Variablen vom Typ String Eine Folge von Zeichen einer bestimmten Länge wird als String bezeichnet. Variablen vom Typ String werden definiert, indem der Name der Variablen, das reservierte Wort String und optional, aber nicht notwendigerweise, die maximale Größe, d. h. die Länge des Strings, in eckigen Klammern angegeben werden. Wenn Sie die maximale Zeichenfolgengröße nicht festlegen, beträgt sie standardmäßig 255, d. h. die Zeichenfolge besteht aus 255 Zeichen. Auf jedes Element einer Zeichenfolge kann über seine Nummer verwiesen werden. Allerdings werden Strings als Ganzes ein- und ausgegeben, nicht Element für Element, wie es bei Arrays der Fall ist. Die Anzahl der eingegebenen Zeichen darf die in der maximalen Zeichenfolgengröße festgelegte nicht überschreiten. Wenn also eine solche Überschreitung auftritt, werden die „zusätzlichen“ Zeichen ignoriert. Prozeduren und Funktionen für Variablen vom Typ String 1. Function Copy(S: String; Index, Count: Integer): String; Gibt einen Teilstring eines Strings zurück. S ist ein Ausdruck vom Typ String. Index und Count sind ganzzahlige Ausdrücke. Die Funktion gibt eine Zeichenfolge zurück, die Count Zeichen enthält, beginnend an der Indexposition. Wenn Index größer als die Länge von S ist, gibt die Funktion einen leeren String zurück. 2. Prozedur Delete(var S: String; Index, Count: Integer); Entfernt einen Teilstring von Zeichen der Länge Count aus dem String S, beginnend an Position Index. S ist eine Variable vom Typ String. Index und Count sind ganzzahlige Ausdrücke. Wenn Index größer als die Länge von S ist, werden keine Zeichen entfernt. 3. Prozedur Insert(Source: String; var S: String; Index: Integer); Verkettet eine Teilzeichenfolge zu einer Zeichenfolge, beginnend an einer angegebenen Position. Quelle ist ein Ausdruck vom Typ String. S ist eine Variable vom Typ String beliebiger Länge. Index ist ein Ausdruck vom Typ Integer. Insert fügt Source in S ein, beginnend bei Position S. 4. Funktionslänge (S: String): Ganzzahl; Gibt die Anzahl der tatsächlich in String S verwendeten Zeichen zurück. Beachten Sie, dass bei der Verwendung von nullterminierten Strings die Anzahl der Zeichen nicht unbedingt gleich der Anzahl der Bytes ist. 5. Funktion Pos(Substr: String; S: String): Integer; Sucht nach einem Teilstring in einem String. Pos sucht in S nach Substr und gibt einen ganzzahligen Wert zurück, der der Index des ersten Zeichens von Substr in S ist. Wenn Substr nicht gefunden wird, gibt Pos Null zurück. 12. Aufzeichnungen Ein Datensatz ist eine Sammlung einer begrenzten Anzahl logisch zusammenhängender Komponenten, die zu verschiedenen Typen gehören. Die Bestandteile eines Datensatzes werden als Felder bezeichnet, die jeweils durch einen Namen identifiziert werden. Ein Datensatzfeld enthält den Namen des Felds, gefolgt von einem Doppelpunkt, um den Typ des Felds anzugeben. Datensatzfelder können von jedem in Pascal erlaubten Typ sein, mit Ausnahme des Dateityps. Die Beschreibung eines Datensatzes in der Sprache Pascal erfolgt über das Dienstwort RECORD, gefolgt von der Beschreibung der Bestandteile des Datensatzes. Die Beschreibung des Eintrags endet mit dem Dienstwort END. Beispielsweise enthält ein Notizbuch Nachnamen, Initialen und Telefonnummern, daher ist es praktisch, eine separate Zeile in einem Notizbuch als den folgenden Eintrag darzustellen: Geben Sie Zeile = Datensatz ein FIO: Zeichenkette[20]; TEL: Zeichenkette[7]; end; var str: Zeile; Datensatzbeschreibungen sind auch ohne Verwendung des Typnamens möglich, zum Beispiel: var str: Aufzeichnen FIO: Zeichenkette[20]; TEL: Zeichenkette[7]; end; Der Verweis auf einen Datensatz als Ganzes ist nur in Zuweisungsanweisungen erlaubt, in denen Datensatznamen des gleichen Typs links und rechts vom Zuweisungszeichen verwendet werden. In allen anderen Fällen werden getrennte Datensatzfelder betrieben. Um auf eine einzelne Datensatzkomponente zu verweisen, müssen Sie den Namen des Datensatzes angeben und, durch einen Punkt getrennt, den Namen des gewünschten Felds angeben. Ein solcher Name wird zusammengesetzter Name genannt. Eine Datensatzkomponente kann auch ein Datensatz sein, in diesem Fall enthält der Distinguished Name nicht zwei, sondern mehr Namen. Das Referenzieren von Datensatzkomponenten kann vereinfacht werden, indem der with append-Operator verwendet wird. Es ermöglicht Ihnen, die zusammengesetzten Namen, die jedes Feld charakterisieren, durch reine Feldnamen zu ersetzen und den Datensatznamen in der Join-Anweisung zu definieren. Manchmal hängt der Inhalt eines einzelnen Datensatzes vom Wert eines seiner Felder ab. In der Pascal-Sprache ist eine Datensatzbeschreibung erlaubt, die aus gemeinsamen und abweichenden Teilen besteht. Der Variantenteil wird mit dem Fall P des Konstrukts angegeben, wobei P der Name des Felds aus dem gemeinsamen Teil des Datensatzes ist. Die möglichen Werte, die von diesem Feld akzeptiert werden, werden auf die gleiche Weise wie in der Variantenanweisung aufgelistet. Anstatt jedoch die auszuführende Aktion anzugeben, wie dies in einer Variant-Anweisung der Fall ist, werden die Variant-Felder in Klammern angegeben. Die Beschreibung des Variantenteils endet mit dem Servicewort end. In der Überschrift des Variantenteils kann der Feldtyp P angegeben werden. Datensätze werden mit typisierten Konstanten initialisiert. 13. Sätze Das Konzept einer Menge in der Pascal-Sprache basiert auf dem mathematischen Konzept von Mengen: Es ist eine begrenzte Sammlung verschiedener Elemente. Ein Aufzählungs- oder Intervalldatentyp wird verwendet, um einen konkreten Mengentyp zu konstruieren. Der Typ der Elemente, aus denen eine Menge besteht, wird als Basistyp bezeichnet. Ein multipler Typ wird mit dem Satz von Funktionswörtern beschrieben, zum Beispiel: Typ M = Satz von B; wobei M der Pluraltyp ist, B der Basistyp ist. Die Zugehörigkeit von Variablen zu einem Pluraltyp kann direkt im Variablendeklarationsabschnitt bestimmt werden. Mengentypkonstanten werden als eine eingeklammerte Folge von Basistypelementen oder Intervallen geschrieben, die durch Kommas getrennt sind. Zuweisungs- (:=), Vereinigungs- (+), Schnittpunkt- (*) und Subtraktions- (-) Operationen sind auf Variablen und Konstanten eines Mengentyps anwendbar. Das Ergebnis dieser Operationen ist ein Wert vom Typ Plural: 1) ['A','B'] + ['A','D'] ergibt ['A','B','D']; 2) ['A'] * ['A','B','C'] ergibt ['A']; 3) ['A','B','C'] - ['A','B'] ergibt ['C'] Die folgenden Operationen sind auf mehrere Werte anwendbar: Identität (=), Nichtidentität (<>), enthalten in (<=), enthält (>=). Das Ergebnis dieser Operationen hat einen booleschen Typ: 1) ['A','B'] = ['A','C'] ergibt FALSE; 2) ['A','B'] <> ['A','C'] ergibt TRUE; 3) ['B'] <= ['B','C'] ergibt TRUE; 4) ['C','D'] >= ['A'] ergibt FALSE. Um mit Werten eines Mengentyps zu arbeiten, wird zusätzlich zu diesen Operationen die In-Operation verwendet, die prüft, ob das Element des Basistyps links vom Operationszeichen zu der Menge rechts vom Operationszeichen gehört . Das Ergebnis dieser Operation ist ein boolescher Wert. Werte eines multiplen Typs können keine Elemente einer E/A-Liste sein. In jeder konkreten Implementierung des Compilers aus der Pascal-Sprache ist die Anzahl der Elemente des Basistyps, auf dem die Menge aufgebaut ist, begrenzt. 14. Dateien. Dateioperationen Der Dateidatentyp definiert eine geordnete Sammlung von Komponenten des gleichen Typs. Beim Arbeiten mit Dateien werden I/O-Operationen durchgeführt. Eine Eingabeoperation ist eine Übertragung von Daten von einem externen Gerät zu einem Speicher, eine Ausgabeoperation ist eine Übertragung von Daten von einem Speicher zu einem externen Gerät. Textdateien Um solche Dateien zu beschreiben, gibt es einen Texttyp: var TF1, TF2: Text; Komponentendateien Eine Komponente oder typisierte Datei ist eine Datei mit dem deklarierten Typ ihrer Komponenten. Typ M = Datei von T; wobei M der Name des Dateityps ist; T - Komponententyp. Operationen werden unter Verwendung von Prozeduren durchgeführt. Schreiben(f, X1,X2,...XK) Untypisierte Dateien Nicht typisierte Dateien ermöglichen es Ihnen, beliebige Bereiche des Computerspeichers auf die Festplatte zu schreiben und sie zu lesen. var f: Datei; 1. Prozedur Assign(var F; FileName: String); Es ordnet einen Dateinamen einer Variablen zu. 2. Prozedur Schließen (varF); Es unterbricht die Verknüpfung zwischen der Dateivariablen und der Datei auf der externen Festplatte und schließt die Datei. 3.Funktion Eof(var F): Boolean; {Typisierte oder nicht typisierte Dateien} Funktion Eof[(var F: Text)]: Boolean; {Textdateien} Sucht nach dem Ende einer Datei. 4. Prozedur löschen (var F); Löscht die mit F verknüpfte externe Datei. 5. Funktion FileSize(var F): Integer; Gibt die Größe der Datei F in Bytes zurück. 6.Funktion FilePos(varF): LongInt; Gibt die aktuelle Position innerhalb einer Datei zurück. 7. Prozedur Reset(var F [: File; RecSize: Word]); Öffnet eine vorhandene Datei. 8. Prozedur Rewrite(var F: File [; Recsize: Word]); Erstellt und öffnet eine neue Datei. 9. Prozedursuche (var F; N: LongInt); Verschiebt die aktuelle Dateiposition zur angegebenen Komponente. 10. Prozedur Append(var F: Text); Zusatz. 11.Funktion Eoln[(var F: Text)]: Boolean; Prüft auf das Ende einer Zeichenfolge. 12. Prozedur Read(F, V1 [, V2..., Vn]); {Typisierte und nicht typisierte Dateien} Prozedur Read([var F: Text;] V1 [, V2..., Vn]); {Textdateien} Liest eine Dateikomponente in eine Variable ein. 13. Prozedur Readln([var F: Text;] V1 [, V2..., Vn]); Liest eine Zeile mit Zeichen in der Datei, einschließlich der Zeilenende-Markierung, und springt zum Anfang der nächsten. 14. Funktion SeekEof[(var F: Text)]: Boolean; Gibt das Dateiendezeichen zurück. Wird nur für offene Textdateien verwendet. 15. Prozedur Writeln([var F: Text;] [P1, P2..., Pn]); {Textdateien} Führt einen Schreibvorgang durch und platziert dann eine Zeilenende-Markierung in der Datei. 15. Module. Arten von Modulen Eine Unit (UNIT) in Pascal ist eine speziell entworfene Bibliothek von Subroutinen. Ein Modul kann im Gegensatz zu einem Programm nicht alleine gestartet werden, es kann nur am Aufbau von Programmen und anderen Modulen teilnehmen. Ein Modul in Pascal ist eine separat gespeicherte und unabhängig kompilierte Programmeinheit. Alle Programmelemente des Moduls lassen sich in zwei Teile gliedern: 1) Programmelemente, die für die Verwendung durch andere Programme oder Module bestimmt sind, solche Elemente werden außerhalb des Moduls sichtbar genannt; 2) Softwareelemente, die nur für den Betrieb des Moduls selbst erforderlich sind, werden als unsichtbar (oder versteckt) bezeichnet. unit <Modulname>; {Modultitel} Schnittstelle {Beschreibung der sichtbaren Programmelemente des Moduls} Implementierung {Beschreibung der versteckten Programmierelemente des Moduls} beginnen {Anweisungen zur Initialisierung von Modulelementen} Ende. Um auf eine in einem Modul deklarierte Variable zu verweisen, müssen Sie einen zusammengesetzten Namen verwenden, der aus dem Modulnamen und dem Variablennamen, getrennt durch einen Punkt, besteht. Die rekursive Verwendung von Modulen ist verboten. Lassen Sie uns die Arten von Modulen auflisten. 1. SYSTEM-Modul. Das SYSTEM-Modul implementiert untergeordnete Unterstützungsroutinen für alle eingebauten Einrichtungen wie E/A, String-Manipulation, Gleitkommaoperationen und dynamische Speicherzuordnung. 2. DOS-Modul. Das DOS-Modul implementiert zahlreiche Pascal-Routinen und -Funktionen, die den am häufigsten verwendeten DOS-Aufrufen wie GetTime, SetTime, DiskSize usw. entsprechen. 3. CRT-Modul. Das CRT-Modul implementiert eine Reihe leistungsstarker Programme, die eine vollständige Kontrolle über die Funktionen des PCs bieten, wie z. B. Bildschirmmodussteuerung, erweiterte Tastaturcodes, Farben, Fenster und Sounds. 4. GRAPH-Modul. Mit den in diesem Modul enthaltenen Prozeduren und Funktionen können Sie verschiedene Grafiken auf dem Bildschirm erstellen. 5. OVERLAY-Modul. Mit dem OVERLAY-Modul können Sie den Speicherbedarf eines Real-Modus-DOS-Programms reduzieren. 16. Referenzdatentyp. dynamisches Gedächtnis. dynamische Variablen. Arbeiten mit dynamischem Speicher Eine statische Variable (statisch zugewiesen) ist eine explizit im Programm deklarierte Variable, auf die mit Namen verwiesen wird. Der Platz im Speicher zum Platzieren statischer Variablen wird bestimmt, wenn das Programm kompiliert wird. Im Gegensatz zu solchen statischen Variablen können Pascal-Programme dynamische Variablen erstellen. Die Haupteigenschaft dynamischer Variablen besteht darin, dass sie während der Programmausführung erstellt und ihnen Speicher zugewiesen wird. Dynamische Variablen werden in einem dynamischen Speicherbereich (Heap-Bereich) abgelegt. Eine dynamische Variable wird in Variablendeklarationen nicht explizit angegeben und kann nicht namentlich angesprochen werden. Auf solche Variablen wird unter Verwendung von Zeigern und Referenzen zugegriffen. Ein Referenztyp (Zeiger) definiert eine Reihe von Werten, die auf dynamische Variablen eines bestimmten Typs zeigen, der als Basistyp bezeichnet wird. Eine Referenztypvariable enthält die Adresse einer dynamischen Variablen im Speicher. Wenn der Basistyp ein nicht deklarierter Bezeichner ist, muss er im selben Teil der Typdeklaration deklariert werden wie der Zeigertyp. Das reservierte Wort nil bezeichnet eine Konstante mit einem Zeigerwert, der auf nichts zeigt. Lassen Sie uns ein Beispiel für die Beschreibung dynamischer Variablen geben. var p1, p2: ^real; p3, p4: ^ ganze Zahl; ... Dynamische Speicherprozeduren und -funktionen 1. Prozedur Neu {var p: Pointer). Weist Platz im dynamischen Speicherbereich zu, um die dynamische Variable p" aufzunehmen, und weist ihre Adresse dem Zeiger p zu. 2. Prozedur Dispose(var p: Pointer). Gibt den von der New-Prozedur für die dynamische Variablenzuordnung zugewiesenen Speicher frei, und der Wert des Zeigers p wird undefiniert. 3. Prozedur GetMem(var p: Zeiger; Größe: Wort). Weist einen Speicherabschnitt im Heap-Bereich zu, weist dem p-Zeiger die Adresse seines Anfangs zu, die Größe des Abschnitts in Bytes wird durch den Größenparameter angegeben. 4. Prozedur FreeMem(varp: Zeiger; Größe: Wort). Gibt den Speicherbereich frei, dessen Anfangsadresse durch den p-Zeiger angegeben wird und dessen Größe durch den Größenparameter angegeben wird. Der Zeigerwert p wird undefiniert. 5. Die Prozedur Mark{var p: Pointer) schreibt in den Zeiger p die Adresse des Beginns des freien dynamischen Speicherabschnitts zum Zeitpunkt ihres Aufrufs. 6. Die Prozedur Release(var p: Pointer) gibt einen Abschnitt des dynamischen Speichers frei, beginnend mit der Adresse, die von der Mark-Prozedur in den Zeiger p geschrieben wurde, d. h. löscht den dynamischen Speicher, der nach dem Aufruf der Mark-Prozedur belegt war. 7. Funktion MaxAvail: Longint gibt die Länge des längsten freien Abschnitts des dynamischen Speichers in Bytes zurück. 8. Funktion MemAvail: Longint gibt die Gesamtmenge des freien dynamischen Speichers in Bytes zurück. 9. Die Hilfsfunktion SizeOf(X):Word gibt die von X belegte Größe in Bytes zurück, wobei X entweder ein Variablenname eines beliebigen Typs oder ein Typname sein kann. 17. Abstrakte Datenstrukturen Strukturierte Datentypen wie Arrays, Sets und Records sind statische Strukturen, da sich ihre Größe während der gesamten Ausführung des Programms nicht ändert. Häufig ist es erforderlich, dass Datenstrukturen im Zuge der Lösung eines Problems ihre Größe ändern. Solche Datenstrukturen werden dynamisch genannt. Dazu gehören Stapel, Warteschlangen, Listen, Bäume usw. Die Beschreibung dynamischer Strukturen unter Verwendung von Arrays, Datensätzen und Dateien führt zu einer Verschwendung von Computerspeicher und erhöht die Zeit zum Lösen von Problemen. Jede Komponente einer dynamischen Struktur ist ein Datensatz, der mindestens zwei Felder enthält: ein Feld vom Typ "Zeiger" und das zweite - für die Datenplatzierung. Im Allgemeinen kann ein Datensatz nicht einen, sondern mehrere Zeiger und mehrere Datenfelder enthalten. Ein Datenfeld kann eine Variable, ein Array, eine Menge oder ein Datensatz sein. Wenn der zeigende Teil die Adresse eines Elements der Liste enthält, wird die Liste als unidirektional (oder einfach verknüpft) bezeichnet. Wenn es zwei Komponenten enthält, ist es doppelt verbunden. Sie können verschiedene Operationen auf Listen ausführen, zum Beispiel: 1) Hinzufügen eines Elements zur Liste; 2) Entfernen eines Elements aus der Liste mit einem gegebenen Schlüssel; 3) Suche nach einem Element mit einem gegebenen Wert des Schlüsselfeldes; 4) Sortieren der Elemente der Liste; 5) Teilung der Liste in zwei oder mehr Listen; 6) Kombinieren von zwei oder mehr Listen zu einer; 7) andere Operationen. In der Regel besteht jedoch nicht die Notwendigkeit aller Operationen zur Lösung verschiedener Probleme. Daher gibt es je nach anzuwendenden Grundoperationen unterschiedliche Arten von Listen. Die beliebtesten davon sind Stack und Queue. 18. Stapel Ein Stack ist eine dynamische Datenstruktur, bei der das Hinzufügen einer Komponente und das Entfernen einer Komponente an einem Ende, dem oberen Ende des Stacks, erfolgt. Der Stapel arbeitet nach dem LIFO-Prinzip (Last-In, First-Out) – „Last in, first out“. Es gibt normalerweise drei Operationen, die auf Stacks ausgeführt werden: 1) anfängliche Bildung des Stapels (Aufzeichnung der ersten Komponente); 2) Hinzufügen einer Komponente zum Stack; 3) Auswahl der Komponente (Löschung). Um einen Stapel zu bilden und damit zu arbeiten, müssen Sie zwei Variablen vom Typ "Zeiger" haben, von denen die erste die Spitze des Stapels bestimmt und die zweite eine Hilfsvariable ist. Beispiel. Schreiben Sie ein Programm, das einen Stapel bildet, ihm eine beliebige Anzahl von Komponenten hinzufügt und dann alle Komponenten liest. STAPEL programmieren; verwendet Crt; tippe Alpha = Zeichenkette[10]; PKomp = ^Komp; Comp = Rekord SD: Alpha; pWeiter: PComp end; jung pTop:PComp; sc: Alfa; ProzedurStack erstellen (var pTop: PComp; var sC: Alfa); beginnen Neu (pOben); pTop^.pNext:= NIL; pTop^.sD:= sc; end; ProzedurComp hinzufügen (var pTop: PComp; var sC: Alfa); var pAux: PComp; beginnen NEU(pAux); pAux^.pNext:= pTop; pTop:=pAux; pTop^.sD:= sc; end; Prozedur DelComp(var pTop: PComp; var sC: ALFA); beginnen sc:= pTop^.sD; pTop:= pTop^.pNext; end; beginnen Clrscr; schreiben( ENTER STRING ); readln(sC); CreateStack(pTop, sc); wiederholen schreiben( ENTER STRING ); readln(sC); AddComp(pTop, sc); bis sC = 'ENDE'; 19. Warteschlangen Eine Warteschlange ist eine dynamische Datenstruktur, bei der eine Komponente an einem Ende hinzugefügt und am anderen Ende abgerufen wird. Die Warteschlange funktioniert nach dem FIFO-Prinzip (First-In, First-Out) – „First in, first served“. Beispiel. Schreiben Sie ein Programm, das eine Warteschlange bildet, ihr eine beliebige Anzahl von Komponenten hinzufügt und dann alle Komponenten liest. ProgrammQUEUE; verwendet Crt; tippe Alpha = Zeichenkette[10]; PKomp = ^Komp; Comp = Rekord SD: Alpha; pWeiter: PComp; end; jung pBegin, pEnd: PComp; sc: Alfa; Create ProcedureQueue(var pBegin,pEnd: PComp; var sc: Alfa); beginnen Neu(pBeginn); pBegin^.pNext:= NIL; pBegin^.sD:= sc; pEnd:=pBeginn; end; Prozedur AddQueue(var pEnd: PComp; var sC: Alpha); var pAux: PComp; beginnen Neu(pAux); pAux^.pNext:= NIL; pEnd^.pNext:= pAux; pEnd:= pAux; pEnd^.sD:= sc; end; Prozedur DelQueue(var pBegin: PComp; var sC: Alpha); beginnen sc:=pBegin^.sD; pBegin:= pBegin^.pNext; end; beginnen Clrscr; schreiben( ENTER STRING ); readln(sC); CreateQueue(pBegin, pEnd, sc); wiederholen schreiben( ENTER STRING ); readln(sC); AddQueue(pEnd, sc); bis sC = 'ENDE'; 20. Baumdatenstrukturen Eine baumartige Datenstruktur ist eine endliche Menge von Elementen – Knoten, zwischen denen Beziehungen bestehen – die Verbindung zwischen der Quelle und dem Generierten. Wenn wir die von N. Wirth vorgeschlagene rekursive Definition verwenden, dann ist eine Baumdatenstruktur vom Basistyp t entweder eine leere Struktur oder ein Knoten vom Typ t, bei dem sich eine endliche Menge von Baumstrukturen vom Basistyp t, sogenannte Teilbäume, befindet damit verbundenen. Als nächstes geben wir die Definitionen an, die beim Arbeiten mit Baumstrukturen verwendet werden. Wenn Knoten y direkt unter Knoten x liegt, dann wird Knoten y als unmittelbarer Nachkomme von Knoten x bezeichnet, und x ist der unmittelbare Vorfahre von Knoten y, d. h. wenn sich Knoten x auf der i-ten Ebene befindet, dann ist Knoten y entsprechend befindet sich auf der (i + 1)-ten Ebene. Die maximale Ebene eines Baumknotens wird als Höhe oder Tiefe des Baums bezeichnet. Ein Vorfahre hat nicht nur einen Knoten des Baums - seine Wurzel. Baumknoten, die keine Kinder haben, werden Blattknoten (oder Blätter des Baums) genannt. Alle anderen Knoten werden interne Knoten genannt. Die Anzahl der unmittelbaren Kinder eines Knotens bestimmt den Grad dieses Knotens, und der maximal mögliche Grad eines Knotens in einem gegebenen Baum bestimmt den Grad des Baums. Vorfahren und Nachkommen können nicht vertauscht werden, d.h. die Verbindung zwischen dem Original und dem Generierten wirkt nur in eine Richtung. Wenn Sie von der Wurzel des Baums zu einem bestimmten Knoten gehen, wird die Anzahl der Zweige des Baums, die in diesem Fall durchlaufen werden, als Länge des Pfads für diesen Knoten bezeichnet. Wenn alle Zweige (Knoten) eines Baums geordnet sind, dann wird der Baum als geordnet bezeichnet. Binäre Bäume sind ein Spezialfall von Baumstrukturen. Dies sind Bäume, in denen jedes Kind höchstens zwei Kinder hat, die linken und rechten Teilbäume genannt werden. Somit ist ein binärer Baum eine Baumstruktur, deren Grad zwei ist. Die Reihenfolge eines Binärbaums wird durch die folgende Regel bestimmt: Jeder Knoten hat sein eigenes Schlüsselfeld, und für jeden Knoten ist der Schlüsselwert größer als alle Schlüssel in seinem linken Teilbaum und kleiner als alle Schlüssel in seinem rechten Teilbaum. Ein Baum, dessen Grad größer als zwei ist, heißt stark verzweigt. 21. Operationen an Bäumen Außerdem betrachten wir alle Operationen in Bezug auf binäre Bäume. I. Einen Baum bauen. Wir stellen einen Algorithmus zur Konstruktion eines geordneten Baums vor. 1. Wenn der Baum leer ist, werden die Daten an die Wurzel des Baums übertragen. Wenn der Baum nicht leer ist, wird einer seiner Äste so absteigend, dass die Ordnung des Baums nicht verletzt wird. Als Ergebnis wird der neue Knoten zum nächsten Blatt des Baums. 2. Um einem bereits bestehenden Baum einen Knoten hinzuzufügen, können Sie den obigen Algorithmus verwenden. 3. Beim Löschen eines Knotens aus dem Baum sollten Sie vorsichtig sein. Wenn der zu entfernende Knoten ein Blatt ist oder nur ein Kind hat, dann ist die Operation einfach. Wenn der zu löschende Knoten zwei Nachkommen hat, muss unter seinen Nachkommen ein Knoten gefunden werden, der an seine Stelle gesetzt werden kann. Dies ist notwendig, da der Baum bestellt werden muss. Sie können dies tun: Tauschen Sie den zu entfernenden Knoten mit dem Knoten mit dem größten Schlüsselwert im linken Teilbaum oder mit dem Knoten mit dem kleinsten Schlüsselwert im rechten Teilbaum aus und löschen Sie dann den gewünschten Knoten als Blatt. II. Suchen Sie nach einem Knoten mit einem bestimmten Schlüsselfeldwert. Beim Durchführen dieser Operation ist es notwendig, den Baum zu durchqueren. Es ist notwendig, die verschiedenen Schreibweisen eines Baums zu berücksichtigen: Präfix, Infix und Postfix. Es stellt sich die Frage: Wie können die Knoten des Baums so dargestellt werden, dass es am bequemsten ist, mit ihnen zu arbeiten? Es ist möglich, einen Baum mithilfe eines Arrays darzustellen, wobei jeder Knoten durch einen kombinierten Typwert beschrieben wird, der ein zeichenartiges Informationsfeld und zwei referenzartige Felder aufweist. Dies ist jedoch nicht sehr praktisch, da Bäume eine große Anzahl von Knoten haben, die nicht vorbestimmt sind. Daher ist es am besten, bei der Beschreibung eines Baums dynamische Variablen zu verwenden. Dann wird jeder Knoten durch einen gleichartigen Wert repräsentiert, der eine Beschreibung einer bestimmten Anzahl von Informationsfeldern enthält, und die Anzahl der entsprechenden Felder muss gleich dem Grad des Baums sein. Es ist logisch, das Fehlen von Nachkommen durch die Referenz null zu definieren. Dann könnte die Beschreibung eines Binärbaums in Pascal so aussehen: TYPE TreeLink = ^Baum; Baum = Aufzeichnung; Inf: <Datentyp>; Links, rechts: TreeLink; Ende. 22. Beispiele für die Durchführung von Operationen 1. Konstruieren Sie einen Baum mit XNUMX Knoten minimaler Höhe oder einen perfekt ausbalancierten Baum (die Anzahl der Knoten des linken und des rechten Teilbaums eines solchen Baums sollte sich um nicht mehr als einen unterscheiden). Rekursiver Konstruktionsalgorithmus: 1) der erste Knoten wird als Wurzel des Baums genommen; 2) der linke Teilbaum aus nl Knoten wird auf die gleiche Weise aufgebaut; 3) der rechte Teilbaum von nr Knoten wird auf die gleiche Weise aufgebaut; nr = n - nl - 1 Als Informationsfeld nehmen wir die über die Tastatur eingegebenen Knotennummern. Die rekursive Funktion, die diese Konstruktion implementiert, sieht folgendermaßen aus: Funktionsbaum (n: Byte): TreeLink; Vart: TreeLink; nl,nr,x: Byte; Beginnen Wenn n = 0, dann Tree:= nil sonst Beginnen nl:= n div 2; nr = n - nl - 1; writeln('Vertexnummer eingeben ); readln(x); Newt); t^.inf:= x; t^.links:= Baum(nl); t^.right:= Baum(nr); Baum:=t; End; {Baum} Ende. 2. Suchen Sie im binär geordneten Baum den Knoten mit dem gegebenen Wert des Schlüsselfelds. Wenn kein solches Element im Baum vorhanden ist, fügen Sie es dem Baum hinzu. Search Procedure(x: Byte; var t: TreeLink); Beginnen Wenn t = Null dann Beginnen Newt); t^inf:= x; t^.links:= nil; t^.right:= nil; Ende Sonst wenn x < t^.inf dann Suchen(x, t^.links) Sonst wenn x > t^.inf dann Suchen(x, t^.rechts) sonst Beginnen {Gefundenes Element verarbeiten} ... End; Ende. 23. Das Konzept eines Graphen. Möglichkeiten, einen Graphen darzustellen Ein Graph ist ein Paar G = (V,E), wobei V eine Menge von Objekten beliebiger Natur ist, Knoten genannt, und E eine Familie von Paaren ei = (vil, vi2), vijOV, Kanten genannt. Im allgemeinen Fall kann die Menge V und (oder) die Familie E eine unendliche Anzahl von Elementen enthalten, aber wir werden nur endliche Graphen betrachten, d. h. Graphen, für die sowohl V als auch E endlich sind. Wenn die Reihenfolge der in ei enthaltenen Elemente von Bedeutung ist, wird der Graph als gerichtet bezeichnet, abgekürzt - digraph, ansonsten - ungerichtet. Die Kanten eines Digraphen heißen Bögen. Wenn e = , dann heißen die Ecken v und u Enden der Kante. Hier sagen wir, dass die Kante e zu jedem der Knoten v und u benachbart (einfallend) ist. Die Knoten v und und werden auch benachbart (incident) genannt. Im allgemeinen Fall sind Kanten der Form e = ; solche Kanten werden Schleifen genannt. Der Grad eines Scheitelpunkts eines Graphen ist die Anzahl der Kanten, die auf den gegebenen Scheitelpunkt fallen, wobei Schleifen doppelt gezählt werden. Die Gewichtung eines Knotens ist eine Zahl (reell, ganzzahlig oder rational), die einem gegebenen Knoten zugeordnet ist (interpretiert als Kosten, Durchsatz usw.). Ein Pfad in einem Diagramm (oder eine Route in einem Digraphen) ist eine abwechselnde Folge von Eckpunkten und Kanten (oder Bögen in einem Digraphen) der Form v0, (v0,v1), v1,..., (vn -1, vn), vn. Die Zahl n nennt man Weglänge. Ein Pfad ohne sich wiederholende Kanten wird als Kette bezeichnet; ein Pfad ohne sich wiederholende Eckpunkte wird als einfache Kette bezeichnet. Ein geschlossener Pfad ohne sich wiederholende Kanten wird als Zyklus (bzw. Kreis) bezeichnet Kontur in einem Digraphen); ohne sich wiederholende Eckpunkte (außer dem ersten und letzten) - ein einfacher Zyklus. Ein Graph heißt zusammenhängend, wenn es zwischen zwei beliebigen seiner Knoten einen Pfad gibt, andernfalls nicht zusammenhängend. Es gibt verschiedene Möglichkeiten, Diagramme darzustellen. 1. Inzidenzmatrix. Dies ist eine rechteckige n x m-Matrix, wobei n die Anzahl der Eckpunkte und m die Anzahl der Kanten ist. 2. Adjazenzmatrix. Dies ist eine quadratische Matrix mit den Dimensionen n × n, wobei n die Anzahl der Ecken ist. 3. Liste der Nachbarschaften (Vorfälle). Stellt eine Datenstruktur dar, die für jeden Scheitelpunkt des Graphen wird eine Liste benachbarter Scheitelpunkte gespeichert. Die Liste ist ein Array von Zeigern, deren i-tes Element einen Zeiger auf die Liste von Scheitelpunkten enthält, die an den i-ten Scheitelpunkt angrenzen. 4. Liste der Listen. Es ist eine baumähnliche Datenstruktur, in der ein Zweig Listen von Knoten enthält, die jeweils benachbart sind. 24. Verschiedene graphische Darstellungen Um ein Diagramm als Inzidenzliste zu implementieren, können Sie den folgenden Typ verwenden: Typenliste = ^S; S=Aufzeichnung; inf: Byte; weiter: Liste; end; Dann ist der Graph wie folgt definiert: Vargr: array[1..n] der Liste; Wenden wir uns nun der Traversierungsprozedur des Graphen zu. Dies ist ein Hilfsalgorithmus, mit dem Sie alle Scheitelpunkte des Diagramms anzeigen und alle Informationsfelder analysieren können. Wenn wir eine Graphtraversierung genauer betrachten, gibt es zwei Arten von Algorithmen: rekursive und nicht rekursive. In Pascal würde das Tiefen-Zuerst-Traversal-Verfahren wie folgt aussehen: Prozedur Obhod(gr: Graph; k: Byte); Varg: Grafik; l:Liste; Beginnen nov[k]:= falsch; g:=gr; Während g^.inf <> k tun g:= g^.nächste; l:= g^.smeg; Während l <> nil beginne Wenn nov[l^.inf] dann Obhod(gr, l^.inf); l:= l^.nächste; End; End; Darstellen eines Diagramms als Liste von Listen Ein Diagramm kann mithilfe einer Liste von Listen wie folgt definiert werden: TypeList = ^Tlist; tlist=record inf: Byte; weiter: Liste; end; Grafik = ^TGpaph; TGpaph = Datensatz inf: Byte; smeg: Liste; weiter: Grafik; end; Wenn wir den Graphen in der Breite durchlaufen, wählen wir einen beliebigen Knoten aus und sehen alle angrenzenden Knoten gleichzeitig durch. Hier ist ein Verfahren zum Durchlaufen eines Diagramms in der Breite in Pseudocode: Verfahren Obhod2(v); Beginnen Warteschlange = O; Warteschlange <= v; nov[v] = Falsch; Während Warteschlange <> O tun Beginnen p <= Warteschlange; Für u in spisok(p) tun Wenn neu[u] dann Beginnen nov[u]:= Falsch; Warteschlange <= u; End; End; End; 25. Objekttyp in Pascal. Das Konzept eines Objekts, seine Beschreibung und Verwendung Eine objektorientierte Programmiersprache zeichnet sich durch drei Haupteigenschaften aus: 1) Kapselung. Das Kombinieren von Datensätzen mit Prozeduren und Funktionen, die die Felder dieser Datensätze manipulieren, bildet einen neuen Datentyp – ein Objekt; 2) Erbschaft. Definition eines Objekts und seine weitere Verwendung zum Aufbau einer Hierarchie von untergeordneten Objekten mit der Fähigkeit für jedes untergeordnete Objekt, das sich auf die Hierarchie bezieht, auf den Code und die Daten aller übergeordneten Objekte zuzugreifen; 3) Polymorphismus. Geben Sie einer Aktion einen einzigen Namen, der dann in der Objekthierarchie nach oben und unten geteilt wird, wobei jedes Objekt in der Hierarchie diese Aktion auf eine für sie geeignete Weise ausführt. Apropos Objekt, wir führen einen neuen Datentyp ein – Objekt. Ein Objekttyp ist eine Struktur, die aus einer festen Anzahl von Komponenten besteht. Jede Komponente ist entweder ein Feld, das Daten eines streng definierten Typs enthält, oder eine Methode, die Operationen an einem Objekt ausführt. Ein Objekttyp kann Komponenten eines anderen Objekttyps erben. Wenn Typ T2 von Typ T1 erbt, dann ist Typ T2 ein untergeordnetes Element von Typ G, und Typ G selbst ist ein übergeordnetes Element von Typ G2. Der folgende Quellcode enthält ein Beispiel für eine Objekttypdeklaration. tippe Punkt = Objekt X, Y: ganze Zahl; end; Rect = Objekt A, B: TPunkt; Prozedur Init(XA, YA, XB, YB: Integer); Prozedur Copy(var R: TRectangle); Prozedur Move(DX, DY: Integer); Prozedur Grow(DX, DY: Integer); Prozedur Intersect(var R: TRectangle); Prozedur Union(var R: TRectangle); Funktion enthält (P: Punkt): Boolean; end; Im Gegensatz zu anderen Typen können Objekttypen nur im Typdeklarationsabschnitt auf der äußersten Ebene des Gültigkeitsbereichs eines Programms oder Moduls deklariert werden. Daher können Objekttypen nicht in einem Variablendeklarationsabschnitt oder innerhalb eines Prozedur-, Funktions- oder Methodenblocks deklariert werden. Ein Dateitypkomponententyp kann keinen Objekttyp oder Strukturtyp haben, der Objekttypkomponenten enthält. 26. Erbschaft Vererbung ist der Prozess der Generierung neuer untergeordneter Typen aus vorhandenen übergeordneten Typen, während das untergeordnete Element alle seine Felder und Methoden vom übergeordneten Typ erhält (erbt). Der Nachkommentyp wird in diesem Fall als Erben- oder Kindtyp bezeichnet. Und der Typ, von dem der untergeordnete Typ erbt, wird als übergeordneter Typ bezeichnet. Geerbte Felder und Methoden können unverändert verwendet oder neu definiert (modifiziert) werden. N. Wirth strebte in seiner Sprache Pascal nach maximaler Einfachheit, also verkomplizierte er sie nicht, indem er die Vererbungsbeziehung einführte. Daher können Typen in Pascal nicht erben. Turbo Pascal 7.0 erweitert diese Sprache jedoch um die Unterstützung der Vererbung. Eine solche Erweiterung ist eine neue Datenstrukturkategorie, die sich auf Datensätze bezieht, aber viel leistungsfähiger ist. Die Datentypen in dieser neuen Kategorie werden mit dem neuen reservierten Wort Object definiert. Die Syntax ist der Syntax zum Definieren von Datensätzen sehr ähnlich: Typ <Typname> = Objekt [(<Übergeordneter Typname>)] ([<Bereich>] <Beschreibung der Felder und Methoden>)+ end; Das „+“-Zeichen hinter einem Syntaxkonstrukt in Klammern bedeutet, dass dieses Konstrukt ein- oder mehrmals in dieser Beschreibung vorkommen muss. Der Geltungsbereich ist eines der folgenden Schlüsselwörter: ▪ Privat; ▪ Geschützt; ▪ Öffentlich. Der Geltungsbereich kennzeichnet, für welche Teile des Programms die Komponenten verfügbar sind, deren Beschreibungen dem Schlüsselwort folgen, das diesen Geltungsbereich benennt. Weitere Informationen zu Komponentenumfängen finden Sie in Frage Nr. 28. Vererbung ist ein mächtiges Werkzeug, das in der Programmentwicklung verwendet wird. Es ermöglicht Ihnen, die objektorientierte Zerlegung des Problems in die Praxis umzusetzen, indem Sie die Sprache verwenden, um die Beziehung zwischen Objekten von Typen auszudrücken, die eine Hierarchie bilden, und fördert auch die Wiederverwendung von Programmcode. 27. Objekte instanziieren Eine Objektinstanz wird erzeugt, indem eine Variable oder Konstante eines Objekttyps deklariert wird oder indem die Standardprozedur New auf eine Variable des Typs "Zeiger auf Objekttyp" angewendet wird. Das resultierende Objekt wird als Instanz des Objekttyps bezeichnet. Wenn ein Objekttyp virtuelle Methoden enthält, müssen Instanzen dieses Objekttyps initialisiert werden, indem ein Konstruktor aufgerufen wird, bevor eine virtuelle Methode aufgerufen wird. Das Zuweisen einer Instanz eines Objekttyps impliziert keine Initialisierung der Instanz. Ein Objekt wird durch vom Compiler generierten Code initialisiert, der zwischen dem Aufruf des Konstruktors und dem Punkt ausgeführt wird, an dem die Ausführung tatsächlich die erste Anweisung im Codeblock des Konstruktors erreicht. Wenn die Objektinstanz nicht initialisiert und die Bereichsprüfung aktiviert ist (durch die {$R+}-Direktive), gibt der erste Aufruf der virtuellen Methode der Objektinstanz einen Laufzeitfehler aus. Wenn die Bereichsprüfung durch die Direktive {$R-} deaktiviert wird), kann der erste Aufruf einer virtuellen Methode eines nicht initialisierten Objekts zu unvorhersehbarem Verhalten führen. Die obligatorische Initialisierungsregel gilt auch für Instanzen, die Komponenten von Strukturtypen sind. Zum Beispiel: jung Kommentar: Array [1..5] von TStrField; I: Ganzzahl beginnen für I:= 1 bis 5 tun Comment [I].Init (1, I + 10, 40, 'Vorname'); . . . for I:= 1 bis 5 do Comment [I].Done; end; Bei dynamischen Instanzen ist die Initialisierung normalerweise die Platzierung und die Bereinigung die Entsorgung, was durch die erweiterte Syntax der Standardprozeduren New und Dispose erreicht wird. Zum Beispiel: jung SP: StrFieldPtr; beginnen New(SP, Init(1, 1, 25, 'Vorname'); SP^.Put('Vladimir'); SP^.Anzeige; . . . Entsorgen (SP, Fertig); Ende. Ein Zeiger auf einen Objekttyp ist zuweisungskompatibel mit einem Zeiger auf einen beliebigen übergeordneten Objekttyp, sodass zur Laufzeit ein Zeiger auf einen Objekttyp auf eine Instanz dieses Typs oder auf eine Instanz eines beliebigen untergeordneten Typs zeigen kann. 28. Bestandteile und Geltungsbereich Der Geltungsbereich eines Bean-Identifizierers geht über den Objekttyp hinaus. Darüber hinaus erstreckt sich der Geltungsbereich eines Bean-Identifikators über die Blöcke von Prozeduren, Funktionen, Konstruktoren und Destruktoren, die die Methoden des Objekttyps und seiner Nachkommen implementieren. Basierend auf diesen Überlegungen muss der Komponentenbezeichner innerhalb des Objekttyps und innerhalb aller seiner Nachkommen sowie innerhalb aller seiner Methoden eindeutig sein. In einer Objekttypdeklaration kann ein Methodenkopf die Parameter des zu beschreibenden Objekttyps spezifizieren, auch wenn die Beschreibung noch nicht vollständig ist. Betrachten Sie das folgende Schema für eine Typdeklaration, die Komponenten aller gültigen Bereiche enthält: Typ <Typname> = Objekt [(<Übergeordneter Typname>)] Privat <private Feld- und Methodenbeschreibungen> Geschützt <geschützte Feld- und Methodenbeschreibungen> Öffentliche <öffentliche Feld- und Methodenbeschreibungen> end; Die im Private-Abschnitt beschriebenen Felder und Methoden können nur innerhalb des Moduls verwendet werden, das ihre Deklarationen enthält, und nirgendwo sonst. Geschützte Felder und Methoden, d. h. die im Abschnitt „Protected“ beschriebenen, sind für das Modul sichtbar, in dem der Typ definiert ist, und für die Nachkommen dieses Typs. Felder und Methoden aus dem öffentlichen Abschnitt haben keine Beschränkungen in ihrer Verwendung und können überall im Programm verwendet werden, das Zugriff auf ein Objekt dieses Typs hat. Der Geltungsbereich des im privaten Teil der Typdeklaration beschriebenen Komponentenbezeichners ist auf das Modul (Programm) beschränkt, das die Objekttypdeklaration enthält. Mit anderen Worten, private Identifier-Beans verhalten sich wie gewöhnliche öffentliche Identifier innerhalb des Moduls, das die Objekttypdeklaration enthält, und außerhalb des Moduls sind alle privaten Beans und Identifier unbekannt und unzugänglich. Indem Sie verwandte Objekttypen in dasselbe Modul einfügen, können Sie diese Objekte auf die privaten Komponenten der anderen zugreifen lassen, und diese privaten Komponenten sind anderen Modulen unbekannt. 29. Methoden Eine Methodendeklaration innerhalb eines Objekttyps entspricht einer Forward-Methodendeklaration (forward). Daher muss eine Methode irgendwo nach einer Objekttypdeklaration, aber innerhalb desselben Geltungsbereichs wie der Geltungsbereich der Objekttypdeklaration implementiert werden, indem ihre Deklaration definiert wird. Bei prozeduralen und funktionalen Methoden nimmt die definierende Deklaration die Form einer normalen Prozedur- oder Funktionsdeklaration an, mit der Ausnahme, dass in diesem Fall der Prozedur- oder Funktionsbezeichner als Methodenbezeichner behandelt wird. Die definierende Beschreibung einer Methode enthält immer einen impliziten Parameter mit dem Bezeichner Self, der einem formalen Variablenparameter eines Objekttyps entspricht. Innerhalb eines Methodenblocks stellt Self die Instanz dar, deren Methodenkomponente zum Aufrufen der Methode angegeben wurde. Somit werden alle Änderungen an den Werten der Self-Felder in der Instanz widergespiegelt. Virtuelle Methoden Methoden sind standardmäßig statisch, aber mit Ausnahme von Konstruktoren können sie virtuell sein (indem die virtual-Direktive in die Methodendeklaration aufgenommen wird). Der Compiler löst Verweise auf statische Methodenaufrufe während des Kompilierungsprozesses auf, während virtuelle Methodenaufrufe zur Laufzeit aufgelöst werden. Dies wird manchmal als späte Bindung bezeichnet. Das Überschreiben einer statischen Methode ist unabhängig vom Ändern des Methodenheaders. Im Gegensatz dazu muss eine virtuelle Methodenüberschreibung die Reihenfolge, Parametertypen und -namen sowie Funktionsergebnistypen, falls vorhanden, beibehalten. Außerdem muss die Neudefinition wieder die virtuelle Direktive beinhalten. Dynamische Methoden Borland Pascal unterstützt zusätzliche spät gebundene Methoden, die als dynamische Methoden bezeichnet werden. Dynamische Methoden unterscheiden sich von virtuellen Methoden nur in der Art und Weise, wie sie zur Laufzeit versendet werden. Im Übrigen sind dynamische Verfahren virtuellen Verfahren gleichgestellt. Eine dynamische Methodendeklaration entspricht einer virtuellen Methodendeklaration, aber die dynamische Methodendeklaration muss den dynamischen Methodenindex enthalten, der unmittelbar nach dem virtuellen Schlüsselwort angegeben wird. Der Index einer dynamischen Methode muss eine ganzzahlige Konstante zwischen 1 und 656535 sein und muss unter den Indizes anderer dynamischer Methoden, die im Objekttyp oder seinen Vorgängern enthalten sind, eindeutig sein. Zum Beispiel: Prozedur FileOpen (var Msg: TMessage); virtuelle 100; Eine Überschreibung einer dynamischen Methode muss mit der Reihenfolge, den Typen und Namen der Parameter übereinstimmen und genau mit dem Ergebnistyp der Funktion der übergeordneten Methode übereinstimmen. Die Überschreibung muss auch eine virtuelle Direktive enthalten, gefolgt von demselben dynamischen Methodenindex, der im Vorgängerobjekttyp angegeben wurde. 30. Konstruktoren und Destruktoren Konstruktoren und Destruktoren sind spezialisierte Formen von Methoden. In Verbindung mit der erweiterten Syntax der Standardprozeduren New und Dispose haben Konstruktoren und Destruktoren die Fähigkeit, dynamische Objekte zu platzieren und zu entfernen. Darüber hinaus haben Konstruktoren die Möglichkeit, die erforderliche Initialisierung von Objekten durchzuführen, die virtuelle Methoden enthalten. Wie alle Methoden können Konstruktoren und Destruktoren vererbt werden, und Objekte können beliebig viele Konstruktoren und Destruktoren enthalten. Konstruktoren werden verwendet, um neu erstellte Objekte zu initialisieren. Typischerweise basiert die Initialisierung auf den Werten, die dem Konstruktor als Parameter übergeben werden. Ein Konstruktor kann nicht virtuell sein, da der Dispatch-Mechanismus einer virtuellen Methode von dem Konstruktor abhängt, der das Objekt zuerst initialisiert hat. Hier sind einige Beispiele für Konstruktoren: Konstruktor Field.Copy(var F: Field); beginnen Selbst:=F; end; Die Hauptaktion eines Konstruktors eines abgeleiteten (untergeordneten) Typs besteht fast immer darin, den entsprechenden Konstruktor seines unmittelbaren Elterntyps aufzurufen, um die geerbten Felder des Objekts zu initialisieren. Nach Ausführung dieser Prozedur initialisiert der Konstruktor die Felder des Objekts, die nur zum abgeleiteten Typ gehören. Destruktoren sind das Gegenteil von Konstruktoren und werden verwendet, um Objekte zu bereinigen, nachdem sie verwendet wurden. Normalerweise besteht die Bereinigung darin, alle Zeigerfelder im Objekt zu entfernen. Beachten Ein Destruktor kann virtuell sein und ist es oft. Ein Destruktor hat selten Parameter. Hier sind einige Beispiele für Destruktoren: Destruktor Feld Fertig; beginnen FreeMem(Name, Länge(Name^) + 1); end; Destruktor StrField.Done; beginnen FreeMem(Wert, Len); Feld erledigt; end; Der Destruktor eines untergeordneten Typs, wie z. B. TStrField oben. Done entfernt normalerweise zuerst die im abgeleiteten Typ eingeführten Zeigerfelder und ruft dann als letzten Schritt den entsprechenden Kollektor-Destruktor des unmittelbar übergeordneten Elements auf, um die geerbten Zeigerfelder des Objekts zu entfernen. 31. Destruktoren Borland Pascal bietet eine spezielle Methode namens Garbage Collector (oder Destruktor) zum Aufräumen und Löschen eines dynamisch zugewiesenen Objekts. Der Destruktor kombiniert den Schritt des Löschens eines Objekts mit allen anderen Aktionen oder Aufgaben, die für diesen Objekttyp erforderlich sind. Sie können mehrere Destruktoren für einen einzelnen Objekttyp definieren. Destruktoren können vererbt werden und sie können entweder statisch oder virtuell sein. Da unterschiedliche Finalizer tendenziell unterschiedliche Objekttypen erfordern, wird allgemein empfohlen, dass Destruktoren immer virtuell sind, damit für jeden Objekttyp der richtige Destruktor ausgeführt wird. Der reservierte Wortdestruktor muss nicht für jede Bereinigungsmethode angegeben werden, auch wenn die Typdefinition des Objekts virtuelle Methoden enthält. Destruktoren funktionieren wirklich nur mit dynamisch zugewiesenen Objekten. Beim Aufräumen eines dynamisch allokierten Objekts erfüllt der Destruktor eine besondere Funktion: Er sorgt dafür, dass im dynamisch allokierten Speicherbereich immer die richtige Anzahl Bytes freigegeben wird. Es besteht kein Grund zur Sorge, einen Destruktor mit statisch zugeordneten Objekten zu verwenden; Indem der Programmierer den Typ des Objekts nicht an den Destruktor übergibt, entzieht der Programmierer einem Objekt dieses Typs die vollen Vorteile der dynamischen Speicherverwaltung in Borland Pascal. Destruktoren werden tatsächlich zu sich selbst, wenn polymorphe Objekte gelöscht und der von ihnen belegte Speicher freigegeben werden muss. Polymorphe Objekte sind solche Objekte, die aufgrund der erweiterten Typkompatibilitätsregeln von Borland Pascal einem übergeordneten Typ zugewiesen wurden. Der Begriff „polymorph“ ist angemessen, da Code, der ein Objekt verarbeitet, zur Kompilierzeit „nicht genau weiß“, welche Art von Objekt er schließlich verarbeiten muss. Das einzige, was es weiß, ist, dass dieses Objekt zu einer Hierarchie von Objekten gehört, die Nachkommen des angegebenen Objekttyps sind. Die Destruktormethode selbst kann leer sein und nur diese Funktion ausführen: destructorAnObject.Done; beginnen end; Was in diesem Destruktor nützlich ist, ist nicht die Eigenschaft seines Hauptteils, jedoch generiert der Compiler Epilogcode als Antwort auf das reservierte Wort des Destruktors. Es ist wie ein Modul, das nichts exportiert, aber unsichtbar arbeitet, indem es seinen Initialisierungsabschnitt ausführt, bevor es das Programm startet. Alle Aktionen finden hinter den Kulissen statt. 32. Virtuelle Methoden Eine Methode wird virtuell, wenn auf ihre Objekttypdeklaration das neue reservierte Wort virtual folgt. Wenn eine Methode in einem übergeordneten Typ als virtuell deklariert wird, müssen alle gleichnamigen Methoden in untergeordneten Typen ebenfalls als virtuell deklariert werden, um einen Compilerfehler zu vermeiden. Das Folgende sind die Objekte aus der Beispiel-Gehaltsabrechnung, richtig virtualisiert: Typ Mitarbeiter = ^Mitarbeiter; Temployee = Objekt Name, Titel: string[25]; Rate: Real; Konstruktor Init(AName, ATitle: String; ARate: Real); Funktion GetPayAmount: Real; virtuell; Funktion GetName: String; Funktion GetTitle: String; Funktion GetRate: Real; Verfahren Zeigen; virtuell; end; PStündlich = ^TStündlich; Thourly = object(TEmployee); Zeit: Ganzzahl; Konstruktor Init(AName, ATitle: String; ARate: Real; Zeit: Ganzzahl); Funktion GetPayAmount: Real; virtuell; Funktion GetTime: Integer; end; PSangestellt = ^TSangestellt; TSalried = object(TEmployee); Funktion GetPayAmount: Real; virtuell; end; PCommissioned = ^TCommissioned; TCommissioned = Objekt (Angestellt); Provision: Real; Verkaufsbetrag: Real; Konstruktor Init(AName, ATitel: String; ARate, AProvision, ASalesAmount: Real); Funktion GetPayAmount: Real; virtuell; end; Ein Konstruktor ist eine spezielle Art von Prozedur, die einige Einrichtungsarbeiten für den virtuellen Methodenmechanismus durchführt. Darüber hinaus muss der Konstruktor aufgerufen werden, bevor eine virtuelle Methode aufgerufen wird. Das Aufrufen einer virtuellen Methode, ohne zuerst den Konstruktor aufzurufen, kann das System blockieren, und der Compiler hat keine Möglichkeit, die Reihenfolge zu überprüfen, in der die Methoden aufgerufen werden. Jeder Objekttyp, der virtuelle Methoden hat, muss einen Konstruktor haben. Der Konstruktor muss aufgerufen werden, bevor eine andere virtuelle Methode aufgerufen wird. Der Aufruf einer virtuellen Methode ohne vorherigen Aufruf des Konstruktors kann eine Systemsperre verursachen und der Compiler kann die Reihenfolge, in der die Methoden aufgerufen werden, nicht überprüfen. 33. Objektdatenfelder und formale Methodenparameter Die Tatsache, dass Methoden und ihre Objekte einen gemeinsamen Gültigkeitsbereich haben, impliziert, dass die formalen Parameter einer Methode nicht mit den Datenfeldern des Objekts identisch sein können. Dies ist keine neue Einschränkung, die durch die objektorientierte Programmierung auferlegt wird, sondern eher die gleichen alten Geltungsbereichsregeln, die Pascal schon immer hatte. Dies entspricht dem Verbot, dass die formalen Parameter einer Prozedur mit den lokalen Variablen der Prozedur identisch sind. Betrachten Sie ein Beispiel, das diesen Fehler für eine Prozedur veranschaulicht: Prozedur CrunchIt(Crunchee: MyDataRec, Crunchby, Fehlercode: Ganzzahl); jung A, B: Zeichen; Fehlercode: Ganzzahl; beginnen . . . end; In der Zeile mit der Deklaration der lokalen Variablen ErrorCode tritt ein Fehler auf. Das liegt daran, dass die Bezeichner des Formalparameters und der lokalen Variablen gleich sind. Die lokalen Variablen einer Prozedur und ihre formalen Parameter haben einen gemeinsamen Geltungsbereich und können daher nicht identisch sein. Sie erhalten die Meldung "Fehler 4: Doppelte Kennung", wenn Sie versuchen, so etwas zu kompilieren. Derselbe Fehler tritt auf, wenn versucht wird, dem Namen des Feldes des Objekts, zu dem diese Methode gehört, einen formalen Methodenparameter zuzuweisen. Die Umstände sind etwas anders, da das Platzieren des Subroutine-Headers in einer Datenstruktur eine Anspielung auf eine Innovation in Turbo Pascal ist, aber die Grundprinzipien des Pascal-Scopes haben sich nicht geändert. Bei der Auswahl von Variablen- und Parameterbezeichnern müssen Sie dennoch eine bestimmte Kultur respektieren. Einige Programmierstile bieten Möglichkeiten zum Benennen von Typfeldern, um das Risiko doppelter Bezeichner zu verringern. Beispielsweise schlägt die ungarische Notation vor, dass Feldnamen mit einem „m“-Präfix beginnen. 34. Einkapselung Die Kombination von Code und Daten in einem Objekt wird Kapselung genannt. Grundsätzlich ist es möglich, genügend Methoden bereitzustellen, damit der Benutzer eines Objekts niemals direkt auf die Felder des Objekts zugreifen wird. Einige andere objektorientierte Sprachen wie Smalltalk erfordern eine obligatorische Kapselung, aber Borland Pascal hat die Wahl. Beispielsweise sind die Objekte TEmployee und Thourly so geschrieben, dass es absolut nicht nötig ist, direkt auf ihre internen Datenfelder zuzugreifen: tippe Temployee = Objekt Name, Titel: string[25]; Rate: Real; Prozedur Init(AName, ATitle: String; ARate: Real); Funktion GetName: String; Funktion GetTitle: String; Funktion GetRate: Real; Funktion GetPayAmount: Real; end; Thourly = object(TEmployee) Zeit: Ganzzahl; Prozedur Init(AName, ATitel: Zeichenkette; ARate: Real, Zeit: Ganzzahl); Funktion GetPayAmount: Real; end; Hier gibt es nur vier Datenfelder: Name, Title, Rate und Time. Die Methoden GetName und GetTitle zeigen den Nachnamen bzw. die Position des Mitarbeiters an. Die GetPayAmount-Methode verwendet Rate und im Fall einer Arbeitszeit Thourly und Time, um die Höhe der Zahlungen an die Arbeitszeit zu berechnen. Auf diese Datenfelder muss nicht mehr direkt verwiesen werden. Unter der Annahme, dass eine AnHourly-Instanz vom Typ THourly existiert, könnten wir eine Reihe von Methoden verwenden, um die Datenfelder von AnHourly wie folgt zu manipulieren: mit einer stündlichen tun beginnen Init (Aleksandr Petrov, Gabelstaplerfahrer' 12.95, 62); {Zeigt den Nachnamen, die Position und den Betrag an Zahlungen} Show; end; Zu beachten ist, dass der Zugriff auf die Felder eines Objekts nur mit Hilfe von Methoden dieses Objekts erfolgt. 35. Expandierende Objekte Wenn ein abgeleiteter Typ definiert ist, werden die Methoden des übergeordneten Typs geerbt, sie können jedoch bei Bedarf überschrieben werden. Um eine geerbte Methode zu überschreiben, deklarieren Sie einfach eine neue Methode mit demselben Namen wie die geerbte Methode, aber mit einem anderen Hauptteil und (falls erforderlich) einem anderen Parametersatz. Lassen Sie uns im folgenden Beispiel einen untergeordneten Typ von TEmployee definieren, der einen Mitarbeiter darstellt, der einen Stundensatz erhält: const Zahlungsperioden = 26; { Zahlungsfristen } Überstundenschwelle = 80; { für die Zahlungsfrist } Überstundenfaktor = 1.5; {Stundensatz} tippe Thourly = object(TEmployee) Zeit: Ganzzahl; Prozedur Init(AName, ATitel: Zeichenkette; ARate: Real, Zeit: Ganzzahl); Funktion GetPayAmount: Real; end; Prozedur THourly.Init(AName, ATitle: string; ARate: Real, Atime: Integer); beginnen TEmployee.Init(AName, ATitle, ARate); Zeit:= AZeit; end; Funktion Thourly.GetPayAmount: Real; jung Überstunden: Ganzzahl; beginnen Overtime:= Time - OvertimeThreshold; wenn Überstunden > 0 dann GetPayAmount:= RoundPay(OvertimeThreshold * Rate + RateOverTime * OvertimeFactor *Rate) sonst GetPayAmount:= RoundPay(Zeit * Rate) end; Beim Aufrufen einer überschriebenen Methode müssen Sie sicher sein, dass der abgeleitete Objekttyp die Funktionalität des übergeordneten Objekts enthält. Darüber hinaus wirkt sich jede Änderung an der übergeordneten Methode automatisch auf alle untergeordneten Methoden aus. Wichtiger Hinweis: Während Methoden überschrieben werden können, können Datenfelder nicht überschrieben werden. Sobald ein Datenfeld in einer Objekthierarchie definiert wurde, kann kein untergeordneter Typ ein Datenfeld mit genau demselben Namen definieren. 36. Kompatibilität von Objekttypen Die Vererbung modifiziert die Typkompatibilitätsregeln von Borland Pascal bis zu einem gewissen Grad. Ein Nachkomme erbt die Typkompatibilität aller seiner Vorfahren. Diese erweiterte Typkompatibilität nimmt drei Formen an: 1) zwischen Implementierungen von Objekten; 2) zwischen Zeigern auf Objektimplementierungen; 3) zwischen formalen und tatsächlichen Parametern. Die Typkompatibilität erstreckt sich nur vom Kind zum Elternteil. Beispielsweise ist „TSalried“ ein untergeordnetes Element von „TEmployee“ und „TCommissioned“ ein untergeordnetes Element von „TSalried“. Betrachten Sie die folgenden Beschreibungen: jung EinMitarbeiter: TEmployee; AAngestellt: TAngestellt; PIn Betrieb genommen: TIn Betrieb genommen; TEmployeePtr: ^TEmployee; TSangestelltPtr: ^TSangestellt; TCommissionedPtr: ^TCommissioned; Unter diesen Beschreibungen gelten die folgenden Zuweisungsoperatoren: AnEmployee:=ASangestellt; ASalied:= ACommissioned; TCommissionedPtr:= ACommissioned; Allgemein wird die Typkompatibilitätsregel wie folgt formuliert: Die Quelle muss den Empfänger vollständig ausfüllen können. Abgeleitete Typen enthalten aufgrund der Vererbungseigenschaft alles, was ihre übergeordneten Typen enthalten. Daher hat der abgeleitete Typ eine Größe, die nicht kleiner ist als die Größe des übergeordneten Typs. Das Zuweisen eines übergeordneten Objekts zu einem untergeordneten Objekt könnte einige Felder des übergeordneten Objekts undefiniert lassen, was gefährlich und daher illegal ist. In Zuweisungsanweisungen werden nur Felder, die beiden Typen gemeinsam sind, von der Quelle zum Ziel kopiert. Im Zuweisungsoperator: AnEmployee:= ACommissioned; Nur die Felder „Name“, „Titel“ und „Rate“ von „ACommissioned“ werden nach „AnEmployee“ kopiert, da dies die einzigen Felder sind, die von „TCommissioned“ und „TEmployee“ gemeinsam genutzt werden. Typkompatibilität funktioniert auch zwischen Zeigern auf Objekttypen und folgt den gleichen allgemeinen Regeln wie für Objektimplementierungen. Ein Zeiger auf ein Kind kann einem Zeiger auf das Elternteil zugewiesen werden. Angesichts der vorherigen Definitionen gelten die folgenden Zeigerzuweisungen: TSalriedPtr:= TCommissionedPtr; TEmployeePtr:= TSalriedPtr; TEmployeePtr:= PCommissionedPtr; Ein formaler Parameter (entweder ein Wert oder ein variabler Parameter) eines bestimmten Objekttyps kann als eigentlichen Parameter ein Objekt seines eigenen Typs oder Objekte aller untergeordneten Typen annehmen. Wenn Sie einen Prozedurkopf wie folgt definieren: Prozedur CalcFedTax(Victim: TSalried); dann können die eigentlichen Parametertypen TSalried oder TCommissioned sein, aber nicht TEmployee. Victim kann auch ein variabler Parameter sein. In diesem Fall gelten die gleichen Kompatibilitätsregeln. Der value-Parameter ist ein Zeiger auf das tatsächliche Objekt, das als Parameter gesendet wird, und der variable Parameter ist eine Kopie des tatsächlichen Parameters. Diese Kopie enthält nur die Felder, die Teil des Typs des formalen Wertparameters sind. Das heißt, der Aktualparameter wird in den Typ des Formalparameters konvertiert. 37. Über Assembler Assembler war einmal eine Sprache, ohne deren Wissen es unmöglich war, einen Computer dazu zu bringen, irgendetwas Nützliches zu tun. Allmählich änderte sich die Situation. Bequemere Kommunikationsmittel mit einem Computer erschienen. Aber im Gegensatz zu anderen Sprachen ist Assembler nicht gestorben und konnte dies im Prinzip auch nicht. Wieso den? Auf der Suche nach einer Antwort werden wir versuchen zu verstehen, was Assemblersprache im Allgemeinen ist. Kurz gesagt, Assemblersprache ist eine symbolische Darstellung der Maschinensprache. Alle Prozesse in der Maschine auf der untersten Hardwareebene werden nur durch Befehle (Anweisungen) der Maschinensprache gesteuert. Daraus wird deutlich, dass trotz des gebräuchlichen Namens die Assemblersprache für jeden Computertyp unterschiedlich ist. Dies gilt auch für das Erscheinungsbild von in Assembler geschriebenen Programmen und die Ideen, die diese Sprache widerspiegelt. Hardwarebezogene Probleme wirklich zu lösen (oder noch mehr hardwarebezogene Probleme, wie etwa die Geschwindigkeit eines Programms zu verbessern), ist ohne Assembler-Kenntnisse unmöglich. Ein Programmierer oder jeder andere Benutzer kann alle High-Level-Tools bis hin zu Programmen zum Erstellen virtueller Welten verwenden und vielleicht nicht einmal ahnen, dass der Computer tatsächlich nicht die Befehle der Sprache ausführt, in der sein Programm geschrieben ist, sondern deren transformierte Darstellung in Form einer langweiligen und langweiligen Folge von Befehlen einer völlig anderen Sprache - der Maschinensprache. Stellen Sie sich nun vor, dass ein solcher Benutzer ein nicht standardmäßiges Problem hat. Beispielsweise muss sein Programm mit einem ungewöhnlichen Gerät funktionieren oder andere Aktionen ausführen, die Kenntnisse über die Prinzipien der Computerhardware erfordern. Egal wie gut die Sprache ist, in der der Programmierer sein Programm geschrieben hat, er kommt nicht ohne Assemblerkenntnisse aus. Und es ist kein Zufall, dass fast alle Compiler von Hochsprachen Mittel enthalten, um ihre Module mit Modulen in Assembler zu verbinden oder den Zugriff auf die Assembler-Programmierebene zu unterstützen. Ein Computer besteht aus mehreren physischen Geräten, die jeweils mit einer einzigen Einheit verbunden sind, die als Systemeinheit bezeichnet wird. 38. Softwaremodell des Mikroprozessors Auf dem heutigen Computermarkt gibt es eine große Vielfalt unterschiedlicher Arten von Computern. Daher kann davon ausgegangen werden, dass der Verbraucher eine Frage hat, wie er die Fähigkeiten eines bestimmten Typs (oder Modells) eines Computers und seine Unterscheidungsmerkmale von Computern anderer Typen (Modelle) bewerten kann. Dazu genügt es nicht, nur das Blockschaltbild eines Computers zu betrachten, da es sich bei verschiedenen Maschinen grundsätzlich kaum unterscheidet: Alle Computer haben RAM, einen Prozessor und externe Geräte. Unterschiedlich sind die Wege, Mittel und verwendeten Ressourcen, mit denen der Computer als ein einziger Mechanismus funktioniert. Um alle Konzepte zusammenzufassen, die einen Computer hinsichtlich seiner funktionalen programmgesteuerten Eigenschaften charakterisieren, gibt es einen speziellen Begriff - Computerarchitektur. Zum ersten Mal wurde das Konzept der Computerarchitektur mit dem Aufkommen von Maschinen der 3. Generation für ihre vergleichende Bewertung erwähnt. Es ist sinnvoll, mit dem Erlernen der Assemblersprache eines beliebigen Computers erst zu beginnen, nachdem Sie herausgefunden haben, welcher Teil des Computers für die Programmierung in dieser Sprache sichtbar und zugänglich bleibt. Dies ist das sogenannte Computerprogrammmodell, zu dem das Mikroprozessorprogrammmodell gehört, das 32 Register enthält, die dem Programmierer mehr oder weniger zur Verfügung stehen. Diese Register lassen sich in zwei große Gruppen einteilen: 1) 16 Benutzerregister; 2) 16 Systemregister. Programme in Assemblersprache verwenden Register sehr stark. Die meisten Register haben einen bestimmten funktionalen Zweck. Zusätzlich zu den oben aufgeführten Registern führen Prozessorentwickler zusätzliche Register in das Softwaremodell ein, die dazu bestimmt sind, bestimmte Klassen von Berechnungen zu optimieren. So wurde in der Pentium Pro (MMX)-Prozessorfamilie der Intel Corporation die MMX-Erweiterung von Intel eingeführt. Es enthält 8 (MM0-MM7) 64-Bit-Register und ermöglicht es Ihnen, ganzzahlige Operationen mit Paaren mehrerer neuer Datentypen durchzuführen: 1) acht gepackte Bytes; 2) vier gepackte Wörter; 3) zwei Doppelwörter; 4) Vierfachwort; Mit anderen Worten, mit einem MMX-Erweiterungsbefehl kann der Programmierer beispielsweise zwei Doppelwörter zusammenfügen. Physikalisch wurden keine neuen Register hinzugefügt. MM0–MM7 sind die Mantissen (untere 64 Bits) eines Stapels von 80-Bit-FPU-Registern (Floating Point Unit – Coprozessor). Darüber hinaus gibt es derzeit folgende Erweiterungen des Programmiermodells - 3DNOW! von AMD; SSE, SSE2, SSE3, SSE4. Die letzten 4 Erweiterungen werden sowohl von AMD- als auch von Intel-Prozessoren unterstützt. 39. Benutzerregistrierungen Wie der Name schon sagt, werden Benutzerregister aufgerufen, weil der Programmierer sie beim Schreiben seiner Programme verwenden kann. Zu diesen Registern gehören: 1) acht 32-Bit-Register, die von Programmierern zum Speichern von Daten und Adressen verwendet werden können (sie werden auch als Universalregister (RON) bezeichnet): ▪ eax/ax/ah/al; ▪ ebx/bx/bh/bl; ▪ edx/dx/dh/dl; ▪ ecx/cx/ch/cl; ▪ ebp/bp; ▪ esi/si; ▪ edi/di; ▪ insb./sp. 2) sechs Segmentregister: ▪ cs; ▪ ds; ▪ SS; ▪ es; ▪fs; ▪gs; 3) Status- und Steuerregister: ▪ Flags registrieren Eflags/Flags; ▪ Befehlszeigerregister eip/ip. Die folgende Abbildung zeigt die Hauptregister des Mikroprozessors: Allgemeine Register
40. Allgemeine Register Alle Register dieser Gruppe erlauben den Zugriff auf ihre "unteren" Teile. Nur die unteren 16- und 8-Bit-Teile dieser Register können für die Selbstadressierung verwendet werden. Die oberen 16 Bit dieser Register stehen nicht als eigenständige Objekte zur Verfügung. Lassen Sie uns die Register auflisten, die zur Gruppe der Mehrzweckregister gehören. Da sich diese Register physisch im Mikroprozessor innerhalb der arithmetischen Logikeinheit (ALU) befinden, werden sie auch als ALU-Register bezeichnet: 1) eax/ax/ah/al (Akkuregister) - Batterie. Wird zum Speichern von Zwischendaten verwendet. Bei einigen Befehlen ist die Verwendung dieses Registers erforderlich; 2) ebx/bx/bh/bl (Basisregister) - Basisregister. Wird verwendet, um die Basisadresse eines Objekts im Speicher zu speichern; 3) ecx/cx/ch/cl (Zählregister) - Zählerregister. Es wird in Befehlen verwendet, die einige sich wiederholende Aktionen ausführen. Seine Verwendung ist oft implizit und versteckt im Algorithmus des entsprechenden Befehls. Beispielsweise analysiert der Schleifenorganisationsbefehl zusätzlich zum Übertragen der Steuerung an einen Befehl, der sich an einer bestimmten Adresse befindet, den Wert des ecx/cx-Registers und dekrementiert ihn um eins; 4) edx/dx/dh/dl (Datenregister) - Datenregister. Genau wie das eax/ax/ah/al-Register speichert es Zwischendaten. Einige Befehle erfordern seine Verwendung; bei einigen Befehlen geschieht dies implizit. Die folgenden zwei Register dienen zur Unterstützung der sogenannten Chain-Operationen, also Operationen, die nacheinander Ketten von Elementen verarbeiten, die jeweils 32, 16 oder 8 Bit lang sein können: 1) esi/si (Quellindexregister) – Quellindex. Dieses Register enthält bei Kettenoperationen die aktuelle Adresse des Elements in der Quellkette; 2) edi/di (Destination Index register) - Index des Empfängers (Empfänger). Dieses Register enthält bei Kettenoperationen die aktuelle Adresse in der Zielkette. In der Architektur des Mikroprozessors auf Hardware- und Softwareebene wird eine solche Datenstruktur wie ein Stack unterstützt. Um mit dem Stack zu arbeiten, gibt es im Mikroprozessor-Befehlssystem spezielle Befehle, und im Mikroprozessor-Softwaremodell gibt es dafür spezielle Register: 1) esp/sp (Stapelzeigerregister) - Stapelzeigerregister. Enthält einen Zeiger auf den Stapelanfang im aktuellen Stapelsegment. 2) ebp/bp (Basiszeigerregister) – Stapelrahmen-Basiszeigerregister. Entwickelt, um den wahlfreien Zugriff auf Daten innerhalb des Stacks zu organisieren. Die Verwendung von Hard-Pinning von Registern für einige Befehle macht es möglich, ihre Maschinendarstellung kompakter zu codieren. Das Wissen um diese Merkmale spart bei Bedarf zumindest einige Bytes an Speicher, der durch den Programmcode belegt wird. 41. Segmentregister Es gibt sechs Segmentregister im Mikroprozessor-Softwaremodell: cs, ss, ds, es, gs, fs. Ihre Existenz ist auf die Besonderheiten der Organisation und Verwendung von RAM durch Intel-Mikroprozessoren zurückzuführen. Sie liegt darin begründet, dass die Mikroprozessorhardware die strukturelle Organisation des Programms in Form von drei Teilen, Segmenten genannt, unterstützt. Dementsprechend wird eine solche Speicherorganisation als segmentiert bezeichnet. Um anzuzeigen, auf welche Segmente das Programm zu einem bestimmten Zeitpunkt Zugriff hat, sind Segmentregister vorgesehen. Tatsächlich (mit einer leichten Korrektur) enthalten diese Register die Speicheradressen, von denen die entsprechenden Segmente beginnen. Die Logik zur Verarbeitung eines Maschinenbefehls ist so aufgebaut, dass Adressen in wohldefinierten Segmentregistern implizit verwendet werden, wenn ein Befehl abgerufen wird, auf Programmdaten zugegriffen wird oder auf den Stapel zugegriffen wird. Der Mikroprozessor unterstützt die folgenden Arten von Segmenten. 1. Codesegment. Enthält Programmbefehle. Um auf dieses Segment zuzugreifen, wird das cs-Register (Code-Segment-Register) verwendet - das Segment-Code-Register. Es enthält die Adresse des Maschinenbefehlssegments, auf das der Mikroprozessor Zugriff hat (d. h. diese Befehle werden in die Mikroprozessor-Pipeline geladen). 2. Datensegment. Enthält die vom Programm verarbeiteten Daten. Um auf dieses Segment zuzugreifen, wird das ds-Register (Data Segment Register) verwendet - ein Segmentdatenregister, das die Adresse des Datensegments des aktuellen Programms speichert. 3. Segment stapeln. Dieses Segment ist ein Speicherbereich, der Stapel genannt wird. Der Mikroprozessor organisiert die Arbeit mit dem Stack nach folgendem Prinzip: Das zuletzt in diesen Bereich geschriebene Element wird zuerst ausgewählt. Um auf dieses Segment zuzugreifen, wird das ss-Register (Stack-Segment-Register) verwendet – das Stack-Segment-Register, das die Adresse des Stack-Segments enthält. 4. Zusätzliches Datensegment. Die Algorithmen zur Ausführung der meisten Maschinenbefehle gehen implizit davon aus, dass sich die von ihnen verarbeiteten Daten im Datensegment befinden, dessen Adresse im ds-Segmentregister steht. Wenn dem Programm ein Datensegment nicht ausreicht, hat es die Möglichkeit, drei weitere zusätzliche Datensegmente zu verwenden. Aber im Gegensatz zum Hauptdatensegment, dessen Adresse im ds-Segmentregister enthalten ist, müssen bei Verwendung zusätzlicher Datensegmente deren Adressen explizit unter Verwendung spezieller Segment-Redefinitionspräfixe im Befehl angegeben werden. Adressen zusätzlicher Datensegmente müssen in den Registern es, gs, fs (Extension Data Segment Registers) enthalten sein. 42. Status- und Steuerregister Der Mikroprozessor enthält mehrere Register, die ständig Informationen über den Zustand sowohl des Mikroprozessors selbst als auch des Programms enthalten, dessen Anweisungen gerade in die Pipeline geladen werden. Zu diesen Registern gehören: 1) Flagregister Flags/Flags; 2) eip/ip-Befehlszeigerregister. Mithilfe dieser Register können Sie Informationen über die Ergebnisse der Befehlsausführung erhalten und den Zustand des Mikroprozessors selbst beeinflussen. Betrachten wir den Zweck und den Inhalt dieser Register genauer. 1. flags/flags (Flag-Register) - Flag-Register. Die Bittiefe von eflags/flags beträgt 32/16 Bit. Einzelne Bits dieses Registers haben einen bestimmten funktionalen Zweck und werden Flags genannt. Der untere Teil dieses Registers ist völlig analog zum Flags-Register für i8086. Je nach Verwendung lassen sich die Flags des eflags/Flags-Registers in drei Gruppen einteilen: 1) acht Statusflags. Diese Flags können sich ändern, nachdem Maschinenbefehle ausgeführt wurden. Die Statusflags des eflags-Registers spiegeln die Einzelheiten des Ergebnisses der Ausführung von arithmetischen oder logischen Operationen wider. Dadurch ist es möglich, den Zustand des Rechenprozesses zu analysieren und mit bedingten Sprungbefehlen und Unterprogrammaufrufen darauf zu reagieren. 2) eine Steuerflagge. Bezeichnet als df (Verzeichnis-Flag). Es befindet sich in Bit 10 des eflags-Registers und wird von verketteten Befehlen verwendet. Der Wert des df-Flags bestimmt die Richtung der elementweisen Verarbeitung bei diesen Operationen: vom Anfang der Zeichenfolge zum Ende (df = 0) oder umgekehrt, vom Ende der Zeichenfolge zum Anfang (df = 1). Um mit dem df-Flag zu arbeiten, gibt es spezielle Befehle: cld (entferne das df-Flag) und std (setze das df-Flag). Durch die Verwendung dieser Befehle können Sie das df-Flag gemäß dem Algorithmus anpassen und sicherstellen, dass Zähler automatisch erhöht oder verringert werden, wenn Sie Operationen an Zeichenfolgen ausführen. 3) fünf Systemflags. Sie steuern E/A, maskierbare Interrupts, Debugging, Taskwechsel und den virtuellen Modus 8086. Es wird Anwendungsprogrammen nicht empfohlen, diese Flags unnötig zu ändern, da dies in den meisten Fällen zum Abbruch des Programms führt. 2. eip/ip (Befehlszeigerregister) - Befehlszeigerregister. Das eip/ip-Register ist 32/16 Bit breit und enthält den Offset des nächsten auszuführenden Befehls relativ zu den Inhalten des cs-Segmentregisters im aktuellen Befehlssegment. Dieses Register ist für den Programmierer nicht direkt zugänglich, aber sein Wert wird durch verschiedene Steuerbefehle geladen und geändert, die Befehle für bedingte und unbedingte Sprünge, das Aufrufen von Prozeduren und das Zurückkehren von Prozeduren umfassen. Das Auftreten von Interrupts modifiziert auch das eip/ip-Register. 43. Mikroprozessorsystemregister Schon der Name dieser Register deutet darauf hin, dass sie bestimmte Funktionen im System ausführen. Die Nutzung von Systemregistern ist streng reglementiert. Sie stellen den geschützten Modus bereit. Sie können auch als Teil der Mikroprozessorarchitektur betrachtet werden, die absichtlich sichtbar gelassen wird, damit ein qualifizierter Systemprogrammierer die einfachsten Operationen ausführen kann. Systemregister können in drei Gruppen eingeteilt werden: 1) vier Steuerregister; Die Gruppe der Steuerregister umfasst 4 Register: ▪ cr0; ▪ cr1; ▪ cr2; ▪ cr3; 2) vier Systemadressenregister (auch Speicherverwaltungsregister genannt); Die Systemadressenregister umfassen die folgenden Register: ▪ globales Deskriptortabellenregister gdtr; ▪ lokales Deskriptortabellenregister Idtr; ▪ Interrupt-Deskriptor-Tabellenregister-IDTR; ▪ 16-Bit-Aufgabenregister tr; 3) acht Debug-Register. Diese beinhalten: ▪ dr0; ▪ dr1; ▪ dr2; ▪ dr3; ▪ dr4; ▪ dr5; ▪ dr6; ▪ dr7. Die Kenntnis von Systemregistern ist nicht erforderlich, um Programme in Assembly zu schreiben, da sie hauptsächlich für die Implementierung der einfachsten Operationen verwendet werden. Allerdings schränken aktuelle Trends in der Softwareentwicklung (insbesondere angesichts der erheblich gesteigerten Optimierungsfähigkeiten moderner Compiler von Hochsprachen, die häufig Code erzeugen, der menschlichem Code in seiner Effizienz überlegen ist) den Anwendungsbereich von Assembler auf die Lösung der einfachsten Ebenenproblemen, bei denen sich die Kenntnis der oben genannten Register als sehr nützlich erweisen kann. 44. Steuerregister Die Gruppe der Steuerregister umfasst vier Register: cr0, cr1, cr2, cr3. Diese Register dienen der allgemeinen Systemsteuerung. Steuerregister stehen nur Programmen mit Privilegstufe 0 zur Verfügung. Obwohl der Mikroprozessor vier Steuerregister hat, sind nur drei davon verfügbar - cr1 ist ausgenommen, dessen Funktionen noch nicht definiert wurden (es ist für zukünftige Verwendung reserviert). Das cr0-Register enthält Systemflags, die die Betriebsmodi des Mikroprozessors steuern und seinen Zustand global widerspiegeln, unabhängig von den spezifischen Aufgaben, die ausgeführt werden. Zweck der Systemmerker: 1) pe (Protect Enable), Bit 0 – geschützten Modus aktivieren. Der Zustand dieses Flags zeigt an, in welchem der beiden Modi – real (pe = 0) oder geschützt (pe = 1) – der Mikroprozessor zu einem bestimmten Zeitpunkt arbeitet; 2) mp (Math Present), Bit 1 – das Vorhandensein eines Coprozessors. Immer 1; 3) ts (Task Switched), Bit 3 – Aufgabenumschaltung. Der Prozessor setzt dieses Bit automatisch, wenn er zu einer anderen Task wechselt; 4) bin (Ausrichtungsmaske), Bit 18 – Ausrichtungsmaske. Dieses Bit aktiviert (am = 1) oder deaktiviert (am = 0) die Ausrichtungssteuerung; 5) cd (Cache Disable), Bit 30 – Cache-Speicher deaktivieren. Mit diesem Bit können Sie die Verwendung des internen Caches (des First-Level-Cache) deaktivieren (cd = 1) oder aktivieren (cd = 0); 6) pg (Paging), Bit 31 – Paging aktivieren (pg = 1) oder deaktivieren (pg = 0). Das Flag wird im Paging-Modell der Speicherorganisation verwendet. Das cr2-Register wird beim RAM-Paging verwendet, um die Situation zu registrieren, wenn der aktuelle Befehl auf die Adresse zugegriffen hat, die in einer Speicherseite enthalten ist, die sich derzeit nicht im Speicher befindet. In einer solchen Situation tritt eine Ausnahmenummer 14 im Mikroprozessor auf, und die lineare 32-Bit-Adresse des Befehls, der diese Ausnahme verursacht hat, wird in das Register cr2 geschrieben. Mit dieser Information bestimmt der Ausnahmebehandler 14 die gewünschte Seite, lagert sie in den Speicher aus und nimmt den normalen Betrieb des Programms wieder auf; Das cr3-Register wird auch für den Paging-Speicher verwendet. Dies ist das sogenannte Seitenverzeichnisregister der ersten Ebene. Es enthält die physikalische 20-Bit-Basisadresse des Seitenverzeichnisses der aktuellen Aufgabe. Dieses Verzeichnis enthält 1024 32-Bit-Deskriptoren, von denen jeder die Adresse der Seitentabelle der zweiten Ebene enthält. Jede der Seitentabellen der zweiten Ebene wiederum enthält 1024 32-Bit-Deskriptoren, die Seitenrahmen im Speicher adressieren. Die Seitenrahmengröße beträgt 4 KB. 45. Register von Systemadressen Diese Register werden auch Speicherverwaltungsregister genannt. Sie dienen dem Schutz von Programmen und Daten im Multitasking-Modus des Mikroprozessors. Beim Betrieb im mikroprozessorgeschützten Modus ist der Adressraum unterteilt in: 1) global – allen Tasks gemeinsam; 2) lokal - getrennt für jede Aufgabe. Diese Trennung erklärt das Vorhandensein der folgenden Systemregister in der Mikroprozessorarchitektur: 1) das Register der globalen Deskriptortabelle gdtr (Global Descriptor Table Register), das eine Größe von 48 Bit hat und eine 32-Bit (Bits 16-47) Basisadresse der globalen Deskriptortabelle GDT und eine 16-Bit (Bits 0-15) Grenzwert, der die Größe in Bytes der GDT-Tabelle ist; 2) das lokale Deskriptortabellenregister ldtr (Local Descriptor Table Register), das eine Größe von 16 Bit hat und den sogenannten Deskriptorselektor der lokalen Deskriptortabelle LDT enthält. Dieser Selektor ist ein Zeiger auf die GDT, die das Segment beschreibt, das die lokale Deskriptortabelle LDT enthält; 3) das Register der Interrupt-Deskriptortabelle idtr (Interrupt Descriptor Table Register), das eine Größe von 48 Bit hat und eine 32-Bit (Bits 16-47) Basisadresse der IDT-Interrupt-Deskriptortabelle und eine 16-Bit (Bits 0–15) Grenzwert, der die Größe in Bytes der IDT-Tabelle ist; 4) 16-Bit-Aufgabenregister tr (Task Register), das wie das ldtr-Register einen Selektor enthält, d. h. einen Zeiger auf einen Deskriptor in der GDT-Tabelle. Dieser Deskriptor beschreibt den aktuellen Aufgabensegmentstatus (TSS). Dieses Segment wird für jede Aufgabe im System angelegt, hat eine streng geregelte Struktur und enthält den Kontext (aktueller Zustand) der Aufgabe. Der Hauptzweck von TSS-Segmenten besteht darin, den aktuellen Status einer Task im Moment des Wechsels zu einer anderen Task zu speichern. 46. Debug-Register Dies ist eine sehr interessante Gruppe von Registern, die für das Hardware-Debugging vorgesehen sind. Hardware-Debugging-Tools tauchten erstmals im i486-Mikroprozessor auf. In der Hardware enthält der Mikroprozessor acht Debug-Register, aber nur sechs davon werden tatsächlich verwendet. Die Register dr0, dr1, dr2, dr3 haben eine Breite von 32 Bit und dienen zum Setzen der linearen Adressen von vier Haltepunkten. Der in diesem Fall verwendete Mechanismus ist der folgende: Jede vom aktuellen Programm generierte Adresse wird mit den Adressen in den Registern dr0 ... dr3 verglichen, und wenn eine Übereinstimmung vorliegt, wird eine Debugging-Ausnahme mit der Nummer 1 generiert. Das Register dr6 wird als Debug-Statusregister bezeichnet. Die Bits in diesem Register werden gemäß den Gründen gesetzt, die das Auftreten der letzten Ausnahme Nummer 1 verursacht haben. Wir listen diese Bits und ihren Zweck auf: 1) b0 – wenn dieses Bit auf 1 gesetzt ist, ist die letzte Ausnahme (Interrupt) als Ergebnis des Erreichens des im Register dr0 definierten Prüfpunkts aufgetreten; 2) b1 - ähnlich wie b0, aber für einen Kontrollpunkt im Register dr1; 3) b2 - ähnlich wie b0, aber für einen Kontrollpunkt im Register dr2; 4) b3 - ähnlich wie b0, aber für einen Kontrollpunkt im Register dr3; 5) bd (Bit 13) – dient zum Schutz der Debug-Register; 6) bs (Bit 14) – auf 1 gesetzt, wenn Ausnahme 1 durch den Zustand des Flags tf = 1 im Flaggs-Register verursacht wurde; 7) bt (Bit 15) wird auf 1 gesetzt, wenn Ausnahme 1 durch einen Wechsel zu einer Task mit gesetztem Trap-Bit in TSS t = 1 verursacht wurde. Alle anderen Bits in diesem Register sind mit Nullen gefüllt. Ausnahmehandler 1 muss basierend auf dem Inhalt von dr6 den Grund für das Auftreten der Ausnahme ermitteln und die erforderlichen Maßnahmen ergreifen. Das Register dr7 wird als Debug-Steuerregister bezeichnet. Es enthält Felder für jedes der vier Debug-Breakpoint-Register, mit denen Sie die folgenden Bedingungen angeben können, unter denen ein Interrupt generiert werden soll: 1) Checkpoint-Registrierungsstandort - nur in der aktuellen Aufgabe oder in jeder Aufgabe. Diese Bits belegen die unteren 8 Bits des Registers dr7 (2 Bits für jeden Haltepunkt (eigentlich ein Haltepunkt), der durch die Register dr0, dr2, dr3 bzw. drXNUMX gesetzt wird). Das erste Bit jedes Paares ist die sogenannte Ortsauflösung; Wenn Sie es setzen, wird der Haltepunkt wirksam, wenn er sich im Adressraum der aktuellen Aufgabe befindet. Das zweite Bit in jedem Paar definiert die globale Berechtigung, die anzeigt, dass der gegebene Haltepunkt innerhalb der Adressräume aller im System befindlichen Tasks gültig ist; 2) die Art des Zugriffs, durch den der Interrupt ausgelöst wird: nur beim Holen eines Befehls, beim Schreiben oder beim Schreiben/Lesen von Daten. Die Bits, die diese Art des Auftretens eines Interrupts bestimmen, befinden sich im oberen Teil dieses Registers. Auf die meisten Systemregister kann programmgesteuert zugegriffen werden. 47. Die Struktur des Programms in Assembler Ein Assemblersprachenprogramm ist eine Sammlung von Speicherblöcken, die als Speichersegmente bezeichnet werden. Ein Programm kann aus einem oder mehreren dieser Blocksegmente bestehen. Jedes Segment enthält eine Sammlung von Sprachsätzen, von denen jeder eine separate Programmcodezeile belegt. Es gibt vier Arten von Assembly-Anweisungen. Befehle oder Anweisungen, die symbolische Gegenstücke zu Maschinenanweisungen sind. Beim Übersetzungsprozess werden Assembleranweisungen in die entsprechenden Befehle des Mikroprozessor-Befehlssatzes umgewandelt. Eine Assembler-Anweisung entspricht in der Regel einer Mikroprozessor-Anweisung, was im Allgemeinen typisch für Niedrigsprachen ist. Hier ist ein Beispiel für einen Befehl, der die im eax-Register gespeicherte Binärzahl um eins erhöht: inkl. zzgl ▪ Makrobefehle – Sätze des Programmtextes, die auf eine bestimmte Weise formatiert sind und während der Ausstrahlung durch andere Sätze ersetzt werden. Ein Beispiel für ein Makro ist das folgende Programmende-Makro: Makro verlassen movax,4c00h Int 21h endm ▪ Direktiven, bei denen es sich um Anweisungen an den Assembler-Übersetzer handelt, bestimmte Aktionen auszuführen. Direktiven haben keine Entsprechungen in der Maschinendarstellung; Als Beispiel hier die TITLE-Direktive, die den Titel der Listing-Datei festlegt: %TITLE "Listing 1" ▪ Kommentarzeilen, die beliebige Zeichen enthalten, einschließlich Buchstaben des russischen Alphabets. Kommentare werden vom Übersetzer ignoriert. Beispiel: ; Diese Zeile ist ein Kommentar 48. Assembly-Syntax Die Sätze, aus denen ein Programm besteht, können ein syntaktisches Konstrukt sein, das einem Befehl, Makro, einer Anweisung oder einem Kommentar entspricht. Damit der Assembler-Übersetzer sie erkennt, müssen sie nach bestimmten syntaktischen Regeln gebildet werden. Verwenden Sie dazu am besten eine formale Beschreibung der Syntax der Sprache, wie die Grammatikregeln. Die gebräuchlichsten Arten, eine Programmiersprache auf diese Weise zu beschreiben, sind Syntaxdiagramme und erweiterte Backus-Naur-Formen. Achten Sie bei der Arbeit mit Syntaxdiagrammen auf die durch die Pfeile angezeigte Traversierungsrichtung. Syntaxdiagramme spiegeln die Logik des Übersetzers wider, wenn er die Eingabesätze des Programms analysiert. Gültige Zeichen: 1) alle lateinischen Buchstaben: A - Z, a - z; 2) Zahlen von 0 bis 9; 3) Zeichen? @, $, &; 4) Trennzeichen. Die Token sind wie folgt. 1. Identifikatoren – Sequenzen gültiger Zeichen, die verwendet werden, um Operationscodes, Variablennamen und Bezeichnungsnamen zu bezeichnen. Ein Bezeichner darf nicht mit einer Zahl beginnen. 2. Zeichenketten - Zeichenfolgen, die in einfache oder doppelte Anführungszeichen eingeschlossen sind. 3. Ganze Zahlen. Mögliche Arten von Assembler-Anweisungen. 1. Arithmetische Operatoren. Diese beinhalten: 1) unäres „+“ und „-“; 2) binär "+" und "-"; 3) Multiplikation "*"; 4) ganzzahlige Division "/"; 5) Erhalten des Rests der Division „mod“. 2. Verschiebeoperatoren verschieben den Ausdruck um die angegebene Anzahl von Bits. 3. Vergleichsoperatoren (Rückgabe „true“ oder „false“) dienen der Bildung logischer Ausdrücke. 4. Logische Operatoren führen bitweise Operationen an Ausdrücken durch. 5. Indexoperator []. 6. Der Typ-Redefinitionsoperator ptr wird verwendet, um den Typ eines Labels oder einer Variable, die durch einen Ausdruck definiert wird, neu zu definieren oder zu qualifizieren. 7. Der Segmentneudefinitionsoperator ":" (Doppelpunkt) bewirkt, dass die physische Adresse relativ zu der angegebenen Segmentkomponente berechnet wird. 8. Benennungsoperator für Strukturtypen "." (Punkt) bewirkt auch, dass der Compiler bestimmte Berechnungen durchführt, wenn es in einem Ausdruck vorkommt. 9. Der Operator zum Erhalten der Segmentkomponente der Adresse des Ausdrucks seg gibt die physische Adresse des Segments für den Ausdruck zurück, die ein Label, eine Variable, ein Segmentname, ein Gruppenname oder irgendein symbolischer Name sein kann. 10. Der Operator zum Abrufen des Offsets des Ausdrucks offset ermöglicht es Ihnen, den Wert des Offsets des Ausdrucks in Bytes relativ zum Anfang des Segments zu erhalten, in dem der Ausdruck definiert ist. 49. Segmentierungsrichtlinien Die Segmentierung ist Teil eines allgemeineren Mechanismus, der sich auf das Konzept der modularen Programmierung bezieht. Es beinhaltet die Vereinheitlichung des Entwurfs von Objektmodulen, die vom Compiler erstellt wurden, einschließlich derjenigen aus verschiedenen Programmiersprachen. Dadurch können Sie Programme kombinieren, die in verschiedenen Sprachen geschrieben sind. Für die Implementierung verschiedener Optionen für eine solche Union sind die Operanden in der SEGMENT-Direktive vorgesehen. Lassen Sie uns sie genauer betrachten. 1. Das Segmentausrichtungsattribut (Ausrichtungstyp) weist den Linker an, sicherzustellen, dass der Anfang des Segments an der angegebenen Grenze platziert wird: 1) BYTE - Ausrichtung wird nicht durchgeführt; 2) WORT – das Segment beginnt an einer Adresse, die ein Vielfaches von zwei ist, d. h. das letzte (niedrigstwertige) Bit der physikalischen Adresse ist 0 (ausgerichtet auf die Wortgrenze); 3) DWORD – das Segment beginnt an einer Adresse, die ein Vielfaches von vier ist; 4) PARA – das Segment beginnt an einer Adresse, die ein Vielfaches von 16 ist; 5) PAGE – das Segment beginnt bei einer Adresse, die ein Vielfaches von 256 ist; 6) MEMPAGE – das Segment beginnt an einer Adresse, die ein Vielfaches von 4 KB ist. 2. Das Combine-Segment-Attribut (kombinatorischer Typ) teilt dem Linker mit, wie Segmente verschiedener Module mit demselben Namen kombiniert werden sollen: 1) PRIVAT – das Segment wird nicht mit anderen Segmenten mit demselben Namen außerhalb dieses Moduls zusammengeführt; 2) PUBLIC – zwingt den Linker, alle Segmente mit demselben Namen zu verbinden; 3) COMMON – hat alle Segmente mit dem gleichen Namen an der gleichen Adresse; 4) AT xxxx – lokalisiert das Segment an der absoluten Adresse des Absatzes; 5) STACK – Definition eines Stapelsegments. 3. Ein Segmentklassenattribut (Klassentyp) ist eine Zeichenfolge in Anführungszeichen, die dem Linker hilft, die richtige Segmentreihenfolge zu bestimmen, wenn er ein Programm aus mehreren Modulsegmenten zusammensetzt. 4. Segmentgrößenattribut: 1) USE16 – das bedeutet, dass das Segment eine 16-Bit-Adressierung zulässt; 2) USE32 – das Segment ist 32-Bit. Es muss einen Weg geben, die Unmöglichkeit zu kompensieren. die Platzierung und Kombination von Segmenten direkt steuern. Dazu begannen sie, die Direktive zum Spezifizieren des MODEL-Speichermodells zu verwenden. Diese Direktive bindet Segmente, die im Falle der Verwendung vereinfachter Segmentierungsdirektiven vordefinierte Namen haben, mit Segmentregistern (obwohl Sie ds immer noch explizit initialisieren müssen). Der obligatorische Parameter der MODEL-Direktive ist das Speichermodell. Dieser Parameter definiert das Speichersegmentierungsmodell für die POE. Es wird davon ausgegangen, dass ein Programmmodul nur bestimmte Arten von Segmenten haben kann, die durch die bereits erwähnten vereinfachten Segmentbeschreibungsdirektiven definiert sind. 50. Maschinenbefehlsstruktur Ein Maschinenbefehl ist eine Anweisung an den Mikroprozessor, die nach bestimmten Regeln codiert ist, um eine Operation oder Aktion auszuführen. Jeder Befehl enthält Elemente, die Folgendes definieren: 1) was tun? 2) Objekte, an denen etwas getan werden muss (diese Elemente werden Operanden genannt); 3) wie zu tun? Die maximale Länge eines Maschinenbefehls beträgt 15 Bytes. 1. Präfixe. Optionale Maschinenbefehlselemente, die jeweils 1 Byte groß sind oder weggelassen werden können. Im Arbeitsspeicher stehen Präfixe vor dem Befehl. Der Zweck von Präfixen besteht darin, die vom Befehl ausgeführte Operation zu modifizieren. Eine Anwendung kann die folgenden Arten von Präfixen verwenden: 1) Segmentersatzpräfix; 2) das Adressbitlängenpräfix gibt die Adressbitlänge (32- oder 16-Bit) an; 3) das Operanden-Bitbreiten-Präfix ist ähnlich dem Adress-Bitbreiten-Präfix, gibt aber die Operanden-Bitlänge (32- oder 16-Bit) an, mit der der Befehl arbeitet; 4) Das Wiederholungspräfix wird bei verketteten Befehlen verwendet. 2. Betriebscode. Erforderliches Element, das die vom Befehl ausgeführte Operation beschreibt. 3. Adressierungsmodusbyte modr/m. Der Wert dieses Bytes bestimmt die verwendete Adressform des Operanden. Operanden können sich im Speicher in einem oder zwei Registern befinden. Wenn sich der Operand im Speicher befindet, gibt das modr/m-Byte die Komponenten an (Offset-, Basis- und Indexregister) verwendet, um seine effektive Adresse zu berechnen. Das modr/m-Byte besteht aus drei Feldern: 1) das mod-Feld bestimmt die Anzahl von Bytes, die in der Anweisung durch die Adresse des Operanden belegt sind; 2) das reg/cop-Feld bestimmt entweder das Register, das sich im Befehl anstelle des ersten Operanden befindet, oder eine mögliche Erweiterung des Opcodes; 3) das r/m-Feld wird in Verbindung mit dem mod-Feld verwendet und bestimmt entweder das im Befehl an der Stelle des ersten Operanden befindliche Register (falls mod = 11) oder die zur Berechnung der effektiven Adresse verwendeten Basis- und Indexregister (zusammen mit dem Offset-Feld im Befehl). 4. Byte-Maßstab – Index – Basis (Byte-Sib). Dient zur Erweiterung der Adressierungsmöglichkeiten von Operanden. Das Sib-Byte besteht aus drei Feldern: 1) Skalenfelder ss. Dieses Feld enthält den Skalierungsfaktor für den Indexkomponentenindex, der die nächsten 3 Bits des Sib-Bytes belegt; 2) Indexfelder. Wird zum Speichern der Indexregisternummer verwendet, die zum Berechnen der effektiven Adresse des Operanden verwendet wird; 3) Grundfelder. Wird zum Speichern der Basisregisternummer verwendet, die auch zum Berechnen der effektiven Adresse des Operanden verwendet wird. 5. Offset-Feld im Befehl. Eine 8-, 16- oder 32-Bit-Ganzzahl mit Vorzeichen, die ganz oder teilweise (vorbehaltlich der obigen Überlegungen) den Wert der effektiven Adresse des Operanden darstellt. 6. Das Feld des unmittelbaren Operanden. Ein optionales Feld, das 8- darstellt, 16- oder 32-Bit-Direktoperand. Das Vorhandensein dieses Feldes spiegelt sich natürlich im Wert des modr/m-Bytes wider. 51. Methoden zum Spezifizieren von Befehlsoperanden Der Operand wird implizit auf Firmware-Ebene gesetzt In diesem Fall enthält die Anweisung explizit keine Operanden. Der Befehlsausführungsalgorithmus verwendet einige Standardobjekte (Register, Flags in Eflags usw.). Der Operand wird in der Anweisung selbst angegeben (Direktoperand) Der Operand steht im Befehlscode, ist also Teil davon. Um einen solchen Operanden zu speichern, wird in der Anweisung ein bis zu 32 Bit langes Feld zugewiesen. Der Direktoperand kann nur der zweite (Quell-)Operand sein. Der Zieloperand kann sich entweder im Speicher oder in einem Register befinden. Der Operand befindet sich in einem der Register Registeroperanden werden durch Registernamen spezifiziert. Register können verwendet werden: 1) 32-Bit-Register EAX, EBX, ECX, EDX, ESI, EDI, ESP, EBP; 2) 16-Bit-Register AX, BX, CX, DX, SI, DI, SP, BP; 3) 8-Bit-Register AH, AL, BH, BL, CH, CL, DH, D.L.; 4) Segmentregister CS, DS, SS, ES, FS, GS. Beispielsweise addiert der Befehl add ax,bx die Inhalte der Register ax und bx und schreibt das Ergebnis nach bx. Der Befehl dec si dekrementiert den Inhalt von si um 1. Der Operand ist im Speicher Dies ist die aufwendigste und zugleich flexibelste Art, Operanden anzugeben. Damit können Sie die folgenden zwei Hauptarten der Adressierung implementieren: direkt und indirekt. Die indirekte Adressierung hat wiederum folgende Varianten: 1) indirekte Basisadressierung; sein anderer Name ist die indirekte Adressierung des Registers; 2) indirekte Basisadressierung mit Offset; 3) indirekte Indexadressierung mit Offset; 4) indirekte Basisindexadressierung; 5) indirekte Basisindexadressierung mit Offset. Der Operand ist ein I/O-Port Zusätzlich zum RAM-Adressraum unterhält der Mikroprozessor einen I/O-Adressraum, der verwendet wird, um auf I/O-Geräte zuzugreifen. Der E/A-Adressraum beträgt 64 KB. Adressen werden für jedes Computergerät in diesem Raum zugewiesen. Ein bestimmter Adresswert innerhalb dieses Raums wird als E/A-Port bezeichnet. Physikalisch entspricht der I/O-Port einem Hardware-Register (nicht zu verwechseln mit einem Mikroprozessor-Register), auf das mit speziellen Assembler-Befehlen ein- und ausgehend zugegriffen wird. Der Operand liegt auf dem Stack Anweisungen können überhaupt keine Operanden haben, können einen oder zwei Operanden haben. Die meisten Befehle erfordern zwei Operanden, von denen einer der Quelloperand und der andere der Zieloperand ist. Wichtig ist, dass sich ein Operand in einem Register oder Speicher befinden kann und der zweite Operand in einem Register oder direkt in der Anweisung stehen muss. Ein Direktoperand kann nur ein Quelloperand sein. In einem Maschinenbefehl mit zwei Operanden sind die folgenden Kombinationen von Operanden möglich: 1) registrieren - registrieren; 2) Register - Speicher; 3) Speicher - Register; 4) Direktoperand - Register; 5) unmittelbarer Operand - Speicher. 52. Adressierungsmethoden Direkte Adressierung Dies ist die einfachste Form der Adressierung eines Operanden im Speicher, da die effektive Adresse in der Anweisung selbst enthalten ist und keine zusätzlichen Quellen oder Register zu ihrer Bildung verwendet werden. Die effektive Adresse wird direkt aus dem Maschinenbefehls-Offsetfeld genommen, das 8, 16, 32 Bits sein kann. Dieser Wert identifiziert eindeutig das im Datensegment befindliche Byte, Wort oder Doppelwort. Es gibt zwei Arten der direkten Adressierung. Relative direkte Adressierung Wird für bedingte Sprungbefehle verwendet, um die relative Sprungadresse anzugeben. Die Relativität eines solchen Übergangs liegt in der Tatsache, dass das Offset-Feld des Maschinenbefehls einen 8-, 16- oder 32-Bit-Wert enthält, der als Ergebnis der Operation des Befehls zum Inhalt von hinzugefügt wird das ip/eip-Befehlszeigerregister. Als Ergebnis dieser Addition erhält man die Adresse, zu der übergegangen wird. Absolute Direktansprache In diesem Fall ist die effektive Adresse Teil des Maschinenbefehls, aber diese Adresse wird nur aus dem Wert des Offset-Felds im Befehl gebildet. Zur Bildung der physikalischen Adresse des Operanden im Speicher addiert der Mikroprozessor dieses Feld mit dem um 4 Bit verschobenen Wert des Segmentregisters. In einem Assembler-Befehl können mehrere Formen dieser Adressierung verwendet werden. Indirekte Grundadressierung (Register). Bei dieser Adressierung kann sich die effektive Adresse des Operanden in jedem der Mehrzweckregister befinden, mit Ausnahme von sp / esp und bp / ebp (dies sind spezielle Register für die Arbeit mit einem Stapelsegment). Syntaktisch wird dieser Adressierungsmodus in einem Befehl ausgedrückt, indem der Registername in eckige Klammern [] gesetzt wird. Indirekte Basis-(Register-)Adressierung mit Offset Diese Art der Adressierung ist eine Ergänzung zur vorherigen und dient dem Zugriff auf Daten mit einem bekannten Offset relativ zu einer Basisadresse. Diese Art der Adressierung ist bequem für den Zugriff auf die Elemente von Datenstrukturen zu verwenden, wenn der Offset der Elemente in der Phase der Programmentwicklung im Voraus bekannt ist und die Basis-(Start-)Adresse der Struktur dynamisch berechnet werden muss die Phase der Programmausführung. Indirekte Indexadressierung mit Offset Diese Art der Adressierung ist der indirekten Basisadressierung mit Offset sehr ähnlich. Auch hier wird eines der Mehrzweckregister zur Bildung der effektiven Adresse verwendet. Aber die Indexadressierung hat ein interessantes Feature, das für die Arbeit mit Arrays sehr praktisch ist. Damit verbunden ist die Möglichkeit der sogenannten Skalierung des Inhalts des Indexregisters. Indirekte Basisindexadressierung Bei dieser Art der Adressierung wird die effektive Adresse als Summe der Inhalte zweier Mehrzweckregister gebildet: Basis und Index. Diese Register können beliebige Mehrzweckregister sein, und häufig wird eine Skalierung des Inhalts eines Indexregisters verwendet. Indirekte Basisindexadressierung mit Offset Diese Art der Adressierung ist die Ergänzung zur indirekten indizierten Adressierung. Die effektive Adresse wird als Summe aus drei Komponenten gebildet: dem Inhalt des Basisregisters, dem Inhalt des Indexregisters und dem Wert des Offset-Felds in der Anweisung. 53. Datenübertragungsbefehle Allgemeine Datenübertragungsbefehle Diese Gruppe umfasst die folgenden Befehle: 1) mov ist der Hauptbefehl für die Datenübertragung; 2) xchg - wird für die bidirektionale Datenübertragung verwendet. Port-E/A-Befehle Grundsätzlich ist die Verwaltung von Geräten direkt über Ports einfach: 1) im Akkumulator, Portnummer - Eingabe in den Akkumulator vom Port mit der Portnummer; 2) Ausgangsport, Akkumulator - gibt den Inhalt des Akkumulators an den Port mit der Portnummer aus. Befehle zur Datenkonvertierung Viele Mikroprozessorbefehle können dieser Gruppe zugeordnet werden, aber die meisten von ihnen haben bestimmte Merkmale, die erfordern, dass sie anderen funktionellen Gruppen zugeordnet werden. Stack-Befehle Diese Gruppe besteht aus einer Reihe spezialisierter Befehle, die sich darauf konzentrieren, flexible und effiziente Arbeit mit dem Stack zu organisieren. Der Stack ist ein Speicherbereich, der speziell für die temporäre Speicherung von Programmdaten reserviert ist. Der Stack hat drei Register: 1) ss - Stapelsegmentregister; 2) sp/esp - Stapelzeigerregister; 3) bp/ebp – Stack-Frame-Basiszeigerregister. Um die Arbeit mit dem Stapel zu organisieren, gibt es spezielle Befehle zum Schreiben und Lesen. 1. Push-Quelle – Schreiben des Quellwerts an die Spitze des Stapels. 2. Pop-Zuweisung – Schreiben des Werts von der Spitze des Stapels an die Stelle, die durch den Zieloperanden angegeben ist. Der Wert wird somit von der Spitze des Stapels "entfernt". 3. pusha - ein Gruppenschreibbefehl auf den Stack. 4. pushaw ist fast gleichbedeutend mit dem Befehl pusha. Das Bitness-Attribut kann entweder use16 oder use32 sein. R 5. pushad - wird ähnlich ausgeführt wie der pusha-Befehl, aber es gibt einige Besonderheiten. Die folgenden drei Befehle führen die Umkehrung der obigen Befehle aus: 1) Papa; 2) Papagei; 3) Pop. Die nachfolgend beschriebene Befehlsgruppe ermöglicht es Ihnen, das Flag-Register auf dem Stack zu speichern und ein Wort oder Doppelwort in den Stack zu schreiben. 1. pushf - speichert das Register der Flags auf dem Stack. 2. pushfw - Speichern eines wortgroßen Flag-Registers auf dem Stack. Funktioniert immer wie pushf mit dem Attribut use16. 3. pushfd – Speichern der Flags oder eflags-Flags-Register auf dem Stack, abhängig von dem Bitbreitenattribut des Segments (dh dasselbe wie pushf). In ähnlicher Weise führen die folgenden drei Befehle die Umkehrung der oben beschriebenen Operationen aus: 1) Puff; 2) popfw; 3) popfd. 54. Arithmetische Anweisungen Solche Befehle funktionieren mit zwei Typen: 1) ganzzahlige Binärzahlen, d. h. mit Zahlen, die im binären Zahlensystem codiert sind. Dezimalzahlen sind eine spezielle Art der Darstellung numerischer Informationen, die auf dem Prinzip beruht, jede Dezimalstelle einer Zahl durch eine Gruppe von vier Bits zu codieren. Der Mikroprozessor führt die Addition von Operanden gemäß den Regeln zum Addieren von Binärzahlen durch. Es gibt drei binäre Additionsbefehle im Befehlssatz des Mikroprozessors: 1) inc operand - erhöht den Wert des Operanden; 2) addiere operand1, operand2 - Addition; 3) adc operand1, operand2 - Addition unter Berücksichtigung des Carry-Flags vgl. Subtraktion von vorzeichenlosen Binärzahlen Ist der Minuend größer als der Subtrahend, dann ist die Differenz positiv. Wenn der Minuend kleiner als der Subtrahierte ist, gibt es ein Problem: Das Ergebnis ist kleiner als 0, und dies ist bereits eine vorzeichenbehaftete Zahl. Nachdem Sie vorzeichenlose Zahlen subtrahiert haben, müssen Sie den Zustand des CF-Flags analysieren. Wenn es auf 1 gesetzt ist, wurde das höchstwertige Bit geborgt und das Ergebnis ist der Zweierkomplementcode. Subtraktion von Binärzahlen mit Vorzeichen Für die Subtraktion durch Addition von Zahlen mit Vorzeichen in einem zusätzlichen Code müssen jedoch beide Operanden dargestellt werden - sowohl der Minuend als auch der Subtrahend. Das Ergebnis sollte auch als Zweierkomplementwert behandelt werden. Aber hier treten Schwierigkeiten auf. Erstens hängen sie damit zusammen, dass das höchstwertige Bit des Operanden als Vorzeichenbit betrachtet wird. Entsprechend dem Inhalt des Überlauf-Flags von. Das Setzen auf 1 zeigt an, dass das Ergebnis für einen Operanden dieser Größe außerhalb des Bereichs der vorzeichenbehafteten Zahlen liegt (d. h. das höchstwertige Bit hat sich geändert), und der Programmierer muss Maßnahmen ergreifen, um das Ergebnis zu korrigieren. Das Prinzip der Subtraktion von Zahlen mit einem das Standard-Bitraster von Operanden überschreitenden Darstellungsbereich ist das gleiche wie bei der Addition, d. h. es wird das Carry-Flag cf verwendet. Sie müssen sich nur den Vorgang des Subtrahierens in einer Spalte vorstellen und die Mikroprozessoranweisungen korrekt mit der sbb-Anweisung kombinieren. Der Befehl zum Multiplizieren von vorzeichenlosen Zahlen lautet mul faktor_1 Der Befehl zum Multiplizieren von Zahlen mit einem Vorzeichen lautet [imul operand_1, operand_2, operand_3] Der Befehl div divisor dient zum Teilen von Zahlen ohne Vorzeichen. Der Befehl idiv divisor dient zum Teilen vorzeichenbehafteter Zahlen. 55. Logikbefehle Gemäß der Theorie können die folgenden logischen Operationen auf Anweisungen (auf Bits) ausgeführt werden. 1. Negation (logisches NICHT) - eine logische Operation an einem Operanden, deren Ergebnis der Kehrwert des Werts des ursprünglichen Operanden ist. 2. Logische Addition (logisches inklusives ODER) – eine logische Operation an zwei Operanden, deren Ergebnis „wahr“ (1) ist, wenn einer oder beide Operanden wahr (1) sind, und „falsch“ (0), wenn beide Operanden wahr sind falsch (0). 3. Logische Multiplikation (logisches UND) – eine logische Operation an zwei Operanden, deren Ergebnis nur dann wahr (1) ist, wenn beide Operanden wahr (1) sind. In allen anderen Fällen ist der Wert der Operation "false" (0). 4. Logische exklusive Addition (logisches exklusives ODER) - eine logische Operation an zwei Operanden, deren Ergebnis "wahr" (1) ist, wenn nur einer der beiden Operanden wahr (1) ist, und falsch (0), wenn Beide Operanden sind entweder falsch (0) oder wahr (1). 4. Logische exklusive Addition (logisches exklusives ODER) - eine logische Operation an zwei Operanden, deren Ergebnis "wahr" (1) ist, wenn nur einer der beiden Operanden wahr (1) ist, und falsch (0), wenn Beide Operanden sind entweder falsch (0) oder wahr (1). Der folgende Satz von Befehlen, die das Arbeiten mit logischen Daten unterstützen: 1) und operand_1, operand_2 - logische Multiplikationsoperation; 2) oder operand_1, operand_2 - logische Additionsoperation; 3) xor operand_1, operand_2 – Operation der logischen exklusiven Addition; 4) test operand_1, operand_2 - "Test"-Operation (durch logische Multiplikation) 5) Nicht-Operand - Operation der logischen Negation. a) um bestimmte Ziffern (Bits) auf 1 zu setzen, wird der Befehl oder operand_1, operand_2 verwendet; b) um bestimmte Ziffern (Bits) auf 0 zurückzusetzen, wird der Befehl und operand_1, operand_2 verwendet; c) Befehl xor operand_1, operand_2 wird angewendet: ▪ um herauszufinden, welche Bits in operand_1 und operand_2 unterschiedlich sind; ▪ um den Zustand der angegebenen Bits in operand_1 umzukehren. Der Befehl test operand_1, operand_2 (check operand_1) wird verwendet, um den Status der angegebenen Bits zu überprüfen. Das Ergebnis des Befehls besteht darin, den Wert des Null-Flags zf zu setzen: 1) wenn zf = 0, dann wurde als Ergebnis der logischen Multiplikation ein Nullergebnis erhalten, d. h. ein Einheitsbit der Maske, das nicht mit dem entsprechenden Einheitsbit von operand1 übereinstimmte; 2) wenn zf = 1, dann führte die logische Multiplikation zu einem Ergebnis ungleich Null, d. h. mindestens ein Einheitsbit der Maske stimmte mit dem entsprechenden einen Bit von operand1 überein. Alle Schiebebefehle verschieben Bits im Operandenfeld je nach Opcode nach links oder rechts. Alle Schichtbefehle haben die gleiche Struktur – Cop-Operand, Schichtzähler. 56. Steuerübertragungsbefehle Welche Programmanweisung als nächstes ausgeführt werden soll, lernt der Mikroprozessor aus dem Inhalt des Registerpaares cs:(e)ip: 1) cs - Codesegmentregister, das die physikalische Adresse des aktuellen Codesegments enthält; 2) eip/ip - Befehlszeigerregister, es enthält den Offset-Wert im Speicher des nächsten auszuführenden Befehls. Bedingungslose Sprünge Was geändert werden muss, hängt ab von: 1) vom Typ des Operanden in der unbedingten Verzweigungsanweisung (nah oder fern); 2) vom Spezifizieren eines Modifikators vor der Übergangsadresse; in diesem Fall kann die Sprungadresse selbst entweder direkt in der Anweisung (direkter Sprung) oder in einem Speicherregister (indirekter Sprung) stehen. Modifikatorwerte: 1) in der Nähe von ptr - direkter Übergang zum Etikett; 2) far ptr – direkter Übergang zu einem Label in einem anderen Codesegment; 3) Wort ptr - indirekter Übergang zum Etikett; 4) dword ptr - indirekter Übergang zu einem Label in einem anderen Codesegment. jmp unbedingte Sprunganweisung jmp [Modifizierer] Sprungadresse Eine Prozedur oder Unterroutine ist die grundlegende Funktionseinheit der Zerlegung einer Aufgabe. Eine Prozedur ist eine Gruppe von Befehlen. Bedingte Sprünge Der Mikroprozessor hat 18 bedingte Sprungbefehle. Mit diesen Befehlen können Sie Folgendes überprüfen: 1) die Beziehung zwischen vorzeichenbehafteten Operanden („mehr ist weniger“); 2) Beziehung zwischen vorzeichenlosen Operanden ("höher niedriger"); 3) Zustände der Rechenflags ZF, SF, CF, OF, PF (aber nicht AF). Bedingte Sprungbefehle haben die gleiche Syntax: jcc Sprungmarke Der cmp-Vergleichsbefehl hat eine interessante Arbeitsweise. Es ist genau dasselbe wie der Subtraktionsbefehl - Unteroperand_1, Operand_2. Der cmp-Befehl subtrahiert wie der sub-Befehl Operanden und setzt Flags. Das einzige, was es nicht tut, ist das Ergebnis der Subtraktion anstelle des ersten Operanden zu schreiben. Die cmp-Befehlssyntax – cmp operand_1, operand_2 (compare) – vergleicht zwei Operanden und setzt Flags basierend auf den Ergebnissen des Vergleichs. Organisation von Zyklen Die zyklische Ausführung eines bestimmten Programmabschnitts können Sie beispielsweise mit der bedingten Übergabe von Steuerbefehlen oder dem unbedingten Sprungbefehl jmp organisieren: 1) Loop-Übergangsetikett (Loop) - Wiederholen Sie die Schleife. Mit dem Befehl können Sie Schleifen ähnlich wie for-Schleifen in Hochsprachen mit automatischem Dekrement des Schleifenzählers organisieren; 2) Sprunglabel loope/loopz Die Befehle loope und loopz sind absolute Synonyme; 3) Sprunglabel loopne/loopnz Auch die Befehle loopne und loopnz sind absolute Synonyme. Die Befehle loope/loopz und loopne/loopnz funktionieren reziprok. Autor: Tsvetkova A.V.
▪ Normale menschliche Anatomie. Krippe ▪ Recht des geistigen Eigentums. Krippe ▪ Geburtshilfe und Gynäkologie. Vorlesungsnotizen
Alkoholgehalt von warmem Bier
07.05.2024 Hauptrisikofaktor für Spielsucht
07.05.2024 Verkehrslärm verzögert das Wachstum der Küken
06.05.2024
▪ Fortschrittliche Technologie für das Recycling von Bürogeräten ▪ ADE7758 und ADE7753 Energiemesschips ▪ Strom aus Salzwasser mit einer zweischichtigen Membran ▪ Prototyp eines Indium-Antimonid-Transistors
▪ Abschnitt der Website mit Gebrauchsanweisungen. Artikelauswahl ▪ Artikel Wasserturbine. Geschichte der Erfindung und Produktion ▪ Artikel Was ist ein Meerschweinchen? Ausführliche Antwort ▪ Artikel über Bram-Sheet-Knoten. Touristische Tipps ▪ Artikel Lunokhod mit Mikrocontroller-Steuerung. Enzyklopädie der Funkelektronik und Elektrotechnik
Startseite | Bibliothek | Artikel | Sitemap | Site-Überprüfungen
www.diagramm.com.ua |


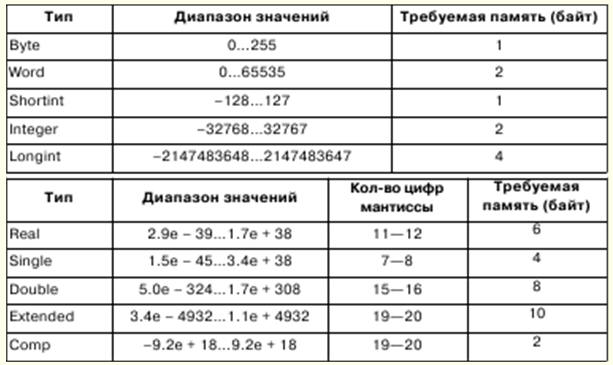

 Siehe andere Artikel Abschnitt
Siehe andere Artikel Abschnitt 