|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Vorlesungsunterlagen, Spickzettel
Datenbank. Vorlesungsskript: kurz das Wichtigste
Verzeichnis / Vorlesungsunterlagen, Spickzettel Inhaltsverzeichnis
Vorlesung Nr. 1. Einführung 1. Datenbankverwaltungssysteme Datenbankmanagementsysteme (DBMS) sind spezialisierte Softwareprodukte, die Folgendes ermöglichen: 1) dauerhaft beliebig große (aber nicht unendliche) Datenmengen speichern; 2) diese gespeicherten Daten auf die eine oder andere Weise zu extrahieren und zu modifizieren, indem sogenannte Abfragen verwendet werden; 3) neue Datenbanken erstellen, d. h. logische Datenstrukturen beschreiben und deren Struktur festlegen, d. h. eine Programmierschnittstelle bereitstellen; 4) von mehreren Benutzern gleichzeitig auf gespeicherte Daten zugreifen (d. h. Zugriff auf den Transaktionsverwaltungsmechanismus gewähren). Dementsprechend kann die Datenbank sind Datensätze unter der Kontrolle von Managementsystemen. Mittlerweile sind Datenbankmanagementsysteme die komplexesten Softwareprodukte auf dem Markt und bilden deren Basis. Zukünftig ist geplant, Entwicklungen an einer Kombination aus herkömmlichen Datenbankmanagementsystemen mit objektorientierter Programmierung (OOP) und Internettechnologien durchzuführen. Ursprünglich basierten DBMS auf hierarchisch и Netzwerkdatenmodelle, d.h. nur mit Baum- und Graphstrukturen arbeiten dürfen. Im Entwicklungsprozess im Jahr 1970 gab es Datenbankverwaltungssysteme, die von Codd (Codd) vorgeschlagen wurden, basierend auf relationales Datenmodell. 2. Relationale Datenbanken Der Begriff „relational“ kommt vom englischen Wort „relation“ – „Beziehung“. Im allgemeinsten mathematischen Sinne (wie Sie sich vielleicht aus dem klassischen Mengenalgebra-Kurs erinnern) Respekt - Es ist ein Satz R = {(x1,..., Xn) | X1 ∈ A1, ..., xn ∈ An}, wo ein1,..., An sind die Mengen, die das kartesische Produkt bilden. Auf diese Weise, Verhältnis R ist eine Teilmenge des kartesischen Mengenprodukts: A1 x... x An : R ⊆ A 1 x... x An. Betrachten Sie zum Beispiel binäre Beziehungen der strengen Reihenfolge "größer als" und "kleiner als" auf der Menge geordneter Zahlenpaare A 1 = A2 = {3, 4, 5}: R> = {(3, 4), (4, 5), (3, 5)} ⊂ A1 x A.2; R< = {(5, 4), (4, 3), (5, 3)} ⊂ A1 x A.2. Diese Beziehungen können in Form von Tabellen dargestellt werden. Verhältnis "größer als">:
Verhältnis "kleiner als" R<:
So sehen wir, dass in relationalen Datenbanken eine Vielzahl von Daten in Form von Beziehungen organisiert sind und in Form von Tabellen dargestellt werden können. Es sei darauf hingewiesen, dass diese beiden Relationen R> und R< sind einander nicht äquivalent, mit anderen Worten, die Tabellen, die diesen Beziehungen entsprechen, sind einander nicht gleich. So können die Formen der Datenrepräsentation in relationalen Datenbanken unterschiedlich sein. Wie äußert sich diese Möglichkeit unterschiedlicher Repräsentation in unserem Fall? Beziehungen R> und R< - das sind Mengen, und eine Menge ist eine ungeordnete Struktur, was bedeutet, dass in Tabellen, die diesen Beziehungen entsprechen, Zeilen miteinander vertauscht werden können. Aber gleichzeitig sind die Elemente dieser Mengen geordnete Mengen, in unserem Fall geordnete Zahlenpaare 3, 4, 5, was bedeutet, dass die Spalten nicht vertauscht werden können. Damit haben wir gezeigt, dass die Darstellung einer Relation (im mathematischen Sinne) als Tabelle mit einer beliebigen Zeilenreihenfolge und einer festen Anzahl von Spalten eine akzeptable, korrekte Form der Repräsentation von Relationen ist. Betrachten wir aber die Beziehungen R> und R< aus Sicht der darin eingebetteten Informationen ist klar, dass sie gleichwertig sind. Daher hat der Begriff "Beziehung" in relationalen Datenbanken eine etwas andere Bedeutung als eine Beziehung in der allgemeinen Mathematik. Es bezieht sich nämlich nicht auf das Ordnen nach Spalten in einer tabellarischen Darstellungsform. Stattdessen werden sogenannte "Zeilen-Spaltenüberschriften"-Beziehungsschemata eingeführt, d. h. jede Spalte erhält eine Überschrift, nach der sie frei ausgetauscht werden können. So wird unsere R-Beziehung aussehen> und R< in einer relationalen Datenbank. Eine strikte Ordnungsrelation (statt der Relation R>):
Eine strikte Ordnungsrelation (statt der Relation R<):
Beide Tabellen-Relationen bekommen eine neue (in diesem Fall die gleiche, da wir durch die Einführung zusätzlicher Überschriften die Unterschiede zwischen den Relationen R> und R<) Titel. Wir sehen also, dass wir mit Hilfe eines so einfachen Tricks wie dem Hinzufügen der erforderlichen Überschriften zu den Tabellen zu der Tatsache kommen, dass die Relationen R> und R< einander gleichwertig werden. Daraus schließen wir, dass der Begriff "Beziehung" im allgemeinen mathematischen und relationalen Sinne nicht vollständig übereinstimmt, sie sind nicht identisch. Gegenwärtig bilden relationale Datenbankverwaltungssysteme die Basis des Informationstechnologiemarktes. Weitere Forschungen werden in Richtung der Kombination unterschiedlicher Grade des relationalen Modells durchgeführt. Vortrag Nr. 2. Fehlende Daten In Datenbankverwaltungssystemen werden zwei Arten von Werten zum Erkennen fehlender Daten beschrieben: leer (oder Leerwerte) und undefiniert (oder Nullwerte). In mancher (meist kommerzieller) Literatur werden Null-Werte manchmal als Leer- oder Null-Werte bezeichnet, was aber falsch ist. Die Bedeutung der leeren und unbestimmten Bedeutungen ist grundlegend unterschiedlich, daher ist es notwendig, den Kontext der Verwendung eines bestimmten Begriffs sorgfältig zu überwachen. 1. Leere Werte (Leerwerte) leerer Wert ist nur einer von vielen möglichen Werten für einen wohldefinierten Datentyp. Wir listen die "natürlichsten", unmittelbaren auf leere Werte (d. h. leere Werte, die wir ohne zusätzliche Informationen selbst zuweisen könnten): 1) 0 (Null) - Nullwert ist leer für numerische Datentypen; 2) falsch (falsch) – ist ein leerer Wert für einen booleschen Datentyp; 3) B'' – leerer Bit-String für Strings variabler Länge; 4) "" - leerer String für Zeichenfolgen variabler Länge. In den oben genannten Fällen können Sie feststellen, ob ein Wert null ist oder nicht, indem Sie den vorhandenen Wert mit der für jeden Datentyp definierten Nullkonstante vergleichen. Datenbankverwaltungssysteme können jedoch aufgrund der darin implementierten Schemata zur langfristigen Datenspeicherung nur mit Zeichenketten konstanter Länge arbeiten. Aus diesem Grund kann eine leere Bitfolge als Folge binärer Nullen bezeichnet werden. Oder eine Zeichenfolge, die aus Leerzeichen oder anderen Steuerzeichen besteht, ist eine leere Zeichenfolge. Hier sind einige Beispiele für leere Zeichenfolgen mit konstanter Länge: 1) B'0'; 2) B'000'; 3) ' '. Wie können Sie in diesen Fällen feststellen, ob eine Zeichenfolge leer ist? In Datenbankverwaltungssystemen wird eine logische Funktion verwendet, um auf Leerheit, d. h. das Prädikat, zu testen IsEmpty(<Ausdruck>), was wörtlich "leer essen" bedeutet. Dieses Prädikat ist normalerweise in das Datenbankverwaltungssystem integriert und kann auf jeden Ausdruckstyp angewendet werden. Wenn es in Datenbankverwaltungssystemen kein solches Prädikat gibt, können Sie selbst eine logische Funktion schreiben und sie in die Liste der Objekte der zu entwerfenden Datenbank aufnehmen. Betrachten Sie ein anderes Beispiel, bei dem es nicht so einfach ist festzustellen, ob wir einen leeren Wert haben. Datumstypdaten. Welcher Wert in diesem Typ soll als leerer Wert betrachtet werden, wenn das Datum im Bereich vom 01.01.0100 schwanken kann. vor dem 31.12.9999? Dazu wird im DBMS eine spezielle Bezeichnung für eingeführt leere Datumskonstanten {...}, wenn der Wert dieses Typs geschrieben wird: {DD. MM. JJ} oder {JJ. MM. DD}. Bei diesem Wert findet ein Vergleich statt, wenn der Wert auf Leerheit geprüft wird. Es wird als wohldefinierter, "vollständiger" Wert eines Ausdrucks dieses Typs und als kleinstmöglicher betrachtet. Bei der Arbeit mit Datenbanken werden häufig Nullwerte als Standardwerte verwendet oder kommen zum Einsatz, wenn Ausdruckswerte fehlen. 2. Undefinierte Werte (Nullwerte) Слово Null verwendet, um zu bezeichnen undefinierte Werte in Datenbanken. Um besser zu verstehen, welche Werte als Null verstanden werden, betrachten Sie eine Tabelle, die ein Fragment einer Datenbank ist:
somit undefinierter Wert oder Nullwert - Das: 1) unbekannter, aber üblicher, d.h. zutreffender Wert. Zum Beispiel hat Herr Khairetdinov, der die Nummer eins in unserer Datenbank ist, zweifellos einige Passdaten (wie eine Person, die 1980 geboren und ein Staatsbürger des Landes ist), aber sie sind nicht bekannt, daher sind sie nicht in der Datenbank enthalten . Daher wird der Nullwert in die entsprechende Spalte der Tabelle geschrieben; 2) nicht zutreffender Wert. Herr Karamasow (Nr. 2 in unserer Datenbank) kann einfach keine Passdaten haben, weil er zum Zeitpunkt der Erstellung dieser Datenbank oder der Eingabe von Daten darin ein Kind war; 3) den Wert einer beliebigen Zelle der Tabelle, wenn wir nicht sagen können, ob er anwendbar ist oder nicht. Beispielsweise kennt Herr Kovalenko, der den dritten Platz in unserer Datenbank einnimmt, das Geburtsjahr nicht, sodass wir nicht mit Sicherheit sagen können, ob er Passdaten hat oder nicht. Und folglich werden die Werte von zwei Zellen in der Zeile, die Herrn Kovalenko gewidmet ist, Nullwerte sein (der erste - als im Allgemeinen unbekannt, der zweite - als ein Wert, dessen Natur unbekannt ist). Wie jeder andere Datentyp haben auch Nullwerte gewisse Werte Eigenschaften. Wir listen die wichtigsten von ihnen auf: 1) Im Laufe der Zeit kann sich das Verständnis des Nullwerts ändern. Zum Beispiel für Herrn Karamasow (Nr. 2 in unserer Datenbank) im Jahr 2014, d. h. bei Erreichen der Volljährigkeit, ändert sich der Null-Wert in einen bestimmten, genau definierten Wert; 2) Ein Nullwert kann einer Variablen oder Konstante eines beliebigen Typs (numerisch, Zeichenkette, boolesch, Datum, Zeit usw.) zugewiesen werden; 3) das Ergebnis von Operationen an Ausdrücken mit Nullwerten als Operanden ist ein Nullwert; 4) Eine Ausnahme von der vorherigen Regel sind die Operationen der Konjunktion und Disjunktion unter den Bedingungen der Absorptionsgesetze (für weitere Einzelheiten zu den Absorptionsgesetzen siehe Abschnitt 4 des Vortrags Nr. 2). 3. Nullwerte und die allgemeine Regel zum Auswerten von Ausdrücken Lassen Sie uns mehr über Aktionen für Ausdrücke sprechen, die Nullwerte enthalten. Die allgemeine Regel für den Umgang mit Nullwerten (dass das Ergebnis von Operationen auf Nullwerten ein Nullwert ist) gilt für die folgenden Operationen: 1) zum Rechnen; 2) zu bitweisen Negations-, Konjunktions- und Disjunktionsoperationen (mit Ausnahme von Absorptionsgesetzen); 3) zu Operationen mit Zeichenfolgen (zum Beispiel Verkettung - Verkettung von Zeichenfolgen); 4) zu Vergleichsoperationen (<, ≤, ≠, ≥, >). Lassen Sie uns Beispiele geben. Als Ergebnis der Anwendung der folgenden Operationen werden Nullwerte erhalten: 3 + Null, 1/ Null, (Iwanow' + '' + Null) ≔ Null Hier verwenden wir anstelle der üblichen Gleichheit Substitutionsbetrieb „≔“ aufgrund der besonderen Art der Arbeit mit Nullwerten. Im Folgenden wird dieses Zeichen auch in ähnlichen Situationen verwendet, was bedeutet, dass der Ausdruck rechts vom Platzhalterzeichen jeden Ausdruck aus der Liste links vom Platzhalterzeichen ersetzen kann. Die Natur von Null-Werten führt oft dazu, dass einige Ausdrücke einen Null-Wert anstelle der erwarteten Null erzeugen, zum Beispiel: (x - x), y * (x - x), x * 0 ≔ Null, wenn x = Null. Die Sache ist die, dass wir beim Ersetzen von beispielsweise dem Wert x = Null in den Ausdruck (x - x) den Ausdruck (Null - Null) und die allgemeine Regel zum Berechnen des Werts des Ausdrucks erhalten, der Nullwerte enthält in Kraft tritt und die Information darüber, dass hier der Nullwert der gleichen Variablen entspricht, verloren geht. Daraus kann geschlossen werden, dass bei der Berechnung anderer Operationen als Boolesche Nullwerte als interpretiert werden nicht anwendbar, und daher ist das Ergebnis auch ein Nullwert. Die Verwendung von Null-Werten in Vergleichsoperationen führt zu nicht weniger unerwarteten Ergebnissen. Beispielsweise erzeugen die folgenden Ausdrücke auch Null-Werte anstelle der erwarteten booleschen True- oder False-Werte: (Null < Null); (Null ≤ Null); (Null = Null); (Null ≠ Null); (Null > Null); (Null ≥ Null) ≔ Null; Daraus schließen wir, dass es unmöglich ist zu sagen, dass ein Nullwert gleich oder ungleich mit sich selbst ist. Jedes neue Auftreten eines Nullwerts wird als unabhängig behandelt, und jedes Mal werden die Nullwerte als unterschiedliche unbekannte Werte behandelt. Dabei unterscheiden sich Null-Werte grundlegend von allen anderen Datentypen, denn wir wissen, dass man bei allen früher übergebenen Werten und deren Typen mit Sicherheit sagen konnte, dass sie gleich oder ungleich sind. Wir sehen also, dass Nullwerte nicht die Werte von Variablen im üblichen Sinne des Wortes sind. Daher wird es unmöglich, die Werte von Variablen oder Ausdrücken zu vergleichen, die Nullwerte enthalten, da wir als Ergebnis nicht die booleschen True- oder False-Werte erhalten, sondern Nullwerte, wie in den folgenden Beispielen: (x <Null); (x ≤ Null); (x = Null); (x ≠ Null); (x > Null); (x ≥ Null) ≔ Null; Daher müssen Sie analog zu leeren Werten ein spezielles Prädikat verwenden, um einen Ausdruck auf Nullwerte zu überprüfen: IsNull(<Ausdruck>), was wörtlich "ist Null" bedeutet. Die boolesche Funktion gibt True zurück, wenn der Ausdruck Null enthält oder gleich Null ist, andernfalls False, gibt aber nie Null zurück. Das IsNull-Prädikat kann auf Variablen und Ausdrücke beliebigen Typs angewendet werden. Bei Anwendung auf Ausdrücke des leeren Typs gibt das Prädikat immer False zurück. Zum Beispiel:
Wir sehen also tatsächlich, dass sich im ersten Fall, als das IsNull-Prädikat von Null genommen wurde, die Ausgabe als False herausstellte. In allen Fällen, einschließlich dem zweiten und dritten, wenn sich herausstellte, dass die Argumente der logischen Funktion gleich dem Nullwert waren, und im vierten Fall, als das Argument selbst ursprünglich gleich dem Nullwert war, gab das Prädikat True zurück. 4. Nullwerte und logische Operationen Typischerweise werden nur drei logische Operationen in Datenbankverwaltungssystemen direkt unterstützt: Negation ¬, Konjunktion & und Disjunktion ∨. Die Operationen der Sukzession ⇒ und Äquivalenz ⇔ werden durch Substitutionen ausgedrückt: (x ⇒ y) ≔ (¬x ∨ y); (x ⇔ y) ≔ (x ⇒ y) & (y ⇒ x); Beachten Sie, dass diese Ersetzungen vollständig erhalten bleiben, wenn Nullwerte verwendet werden. Interessanterweise kann mit dem Negationsoperator "¬" jede der Operationen Konjunktion & oder Disjunktion ∨ wie folgt durcheinander ausgedrückt werden: (x & y) ≔¬ (¬x ∨¬y); (x ∨ y) ≔ ¬(¬x & ¬y); Diese Ersetzungen sowie die vorherigen werden von Null-Werten nicht beeinflusst. Und jetzt geben wir die Wahrheitstabellen der logischen Operationen der Negation, Konjunktion und Disjunktion an, aber zusätzlich zu den üblichen Wahr- und Falsch-Werten verwenden wir auch den Null-Wert als Operanden. Der Einfachheit halber führen wir die folgende Notation ein: Anstelle von True schreiben wir t, anstelle von False - f und anstelle von Null - n. 1. Verweigerung xx.
Beachten Sie die folgenden interessanten Punkte in Bezug auf die Negationsoperation mit Nullwerten: 1) ¬¬x ≔ x - das Gesetz der doppelten Negation; 2) ¬Null ≔ Null - Der Nullwert ist ein Fixpunkt. 2. Konjunktion x & y.
Diese Operation hat auch ihre eigenen Eigenschaften: 1) x & y ≔ y & x - Kommutativität; 2) x & x ≔ x - Idempotenz; 3) False & y ≔ False, hier ist False ein absorbierendes Element; 4) True & y ≔ y, hier ist True das neutrale Element. 3. Disjunktion x ∨ y.
Features: 1) x ∨ y ≔ y ∨ x - Kommutativität; 2) x ∨ x ≔ x - Idempotenz; 3) Falsch ∨ y ≔ y, hier ist Falsch das neutrale Element; 4) True ∨ y ≔ True, hier ist True ein absorbierendes Element. Eine Ausnahme von der allgemeinen Regel bilden die Regeln zur Berechnung der logischen Operationen Konjunktion & und Disjunktion ∨ unter den Aktionsbedingungen Absorptionsgesetze: (Falsch & y) ≔ (x & Falsch) ≔ Falsch; (Wahr ∨ y) ≔ (x ∨ Wahr) ≔ Wahr; Diese zusätzlichen Regeln sind so formuliert, dass beim Ersetzen eines Nullwerts durch False oder True das Ergebnis immer noch nicht von diesem Wert abhängt. Wie zuvor für andere Arten von Operationen gezeigt, kann die Verwendung von Nullwerten in booleschen Operationen auch zu unerwarteten Werten führen. So ist zum Beispiel die Logik auf den ersten Blick eingebrochen das Gesetz des Ausschlusses des Dritten (x ∨ ¬x) und das Gesetz der Reflexivität (x = x), denn für x ≔ Null gilt: (x ∨ ¬x), (x = x) ≔ Null. Gesetze werden nicht durchgesetzt! Dies wird auf die gleiche Weise wie zuvor erklärt: Wenn ein Nullwert in einen Ausdruck eingesetzt wird, geht die Information verloren, dass dieser Wert von derselben Variablen gemeldet wird, und die allgemeine Regel zum Arbeiten mit Nullwerten tritt in Kraft. Daraus schließen wir: Wenn Sie logische Operationen mit Nullwerten als Operanden durchführen, werden diese Werte von Datenbankverwaltungssystemen als bestimmt anwendbar, aber unbekannt. 5. Nullwerte und Zustandsprüfung Aus dem Obigen können wir also schließen, dass es in der Logik von Datenbankverwaltungssystemen nicht zwei logische Werte (Wahr und Falsch) gibt, sondern drei, da der Nullwert auch als einer der möglichen logischen Werte betrachtet wird. Deshalb wird er auch oft als der unbekannte Wert, der unbekannte Wert, bezeichnet. Trotzdem wird in Datenbankverwaltungssystemen nur zweiwertige Logik implementiert. Daher muss eine Bedingung mit einem Nullwert (eine undefinierte Bedingung) von der Maschine entweder als True oder False interpretiert werden. Standardmäßig erkennt die DBMS-Sprache eine Bedingung mit einem Nullwert als False. Wir veranschaulichen dies anhand der folgenden Beispiele für die Implementierung von bedingten If- und While-Anweisungen in Datenbankmanagementsystemen: Wenn P, dann A, sonst B; Dieser Eintrag bedeutet: Wenn P als True ausgewertet wird, wird Aktion A ausgeführt, und wenn P als False oder Null ausgewertet wird, wird Aktion B ausgeführt. Jetzt wenden wir die Negationsoperation auf diesen Operator an, wir erhalten: Wenn ¬P, dann B, sonst A; Dieser Operator bedeutet wiederum Folgendes: Wenn ¬P den Wert True ergibt, wird Aktion B ausgeführt, und wenn ¬P den Wert False oder Null ergibt, wird Aktion A ausgeführt. Und wieder, wie wir sehen können, stoßen wir auf unerwartete Ergebnisse, wenn ein Nullwert erscheint. Der Punkt ist, dass die beiden If-Anweisungen in diesem Beispiel nicht äquivalent sind! Obwohl einer von ihnen aus dem anderen erhalten wird, indem die Bedingung negiert und die Zweige neu angeordnet werden, dh durch eine Standardoperation. Solche Operatoren sind im Allgemeinen äquivalent! Aber in unserem Beispiel sehen wir, dass der Nullwert der Bedingung P im ersten Fall dem Befehl B entspricht und im zweiten - A. Betrachten Sie nun die Aktion der bedingten Anweisung while: Während P A tut; B; Wie funktioniert dieser Operator? Solange P wahr ist, wird Aktion A ausgeführt, und sobald P falsch oder Null ist, wird Aktion B ausgeführt. Aber Nullwerte werden nicht immer als False interpretiert. Beispielsweise werden in Integritätsbedingungen undefinierte Bedingungen als wahr erkannt (Integritätsbedingungen sind Bedingungen, die den Eingabedaten auferlegt werden und deren Korrektheit sicherstellen). Denn bei solchen Einschränkungen sollten nur absichtlich falsche Daten zurückgewiesen werden. Und wieder gibt es bei Datenbankverwaltungssystemen eine Besonderheit Substitutionsfunktion IfNull (Integritätsbedingungen, True), mit der Nullwerte und undefinierte Bedingungen explizit dargestellt werden können. Lassen Sie uns die bedingten If- und While-Anweisungen mit dieser Funktion umschreiben: 1) If IfNull (P, False) then A else B; 2) Während IfNull (P, False) A ausführt; B; Die Substitutionsfunktion IfNull(Ausdruck 1, Ausdruck 2) gibt also den Wert des ersten Ausdrucks zurück, wenn er keinen Nullwert enthält, und andernfalls den Wert des zweiten Ausdrucks. Es sollte beachtet werden, dass dem Typ des Ausdrucks, der von der IfNull-Funktion zurückgegeben wird, keine Beschränkungen auferlegt werden. Daher können Sie mit dieser Funktion alle Regeln für die Arbeit mit Nullwerten explizit überschreiben. Vorlesung Nr. 3. Relationale Datenobjekte 1. Anforderungen an die tabellarische Darstellung von Relationen 1. Die allererste Voraussetzung für die tabellarische Darstellung von Relationen ist die Endlichkeit. Das Arbeiten mit unendlichen Tabellen, Beziehungen oder anderen Darstellungen und Datenorganisationen ist unbequem, rechtfertigt selten den aufgewendeten Aufwand, und außerdem hat diese Richtung wenig praktische Anwendung. Aber abgesehen davon, ganz zu erwarten, gibt es noch andere Anforderungen. 2. Die Überschrift der Tabelle, die die Beziehung darstellt, muss unbedingt aus einer Zeile bestehen - der Überschrift der Spalten und mit eindeutigen Namen. Überschriften mit mehreren Ebenen sind nicht zulässig. Zum Beispiel diese:
Alle mehrstufigen Überschriften werden durch einstufige Überschriften ersetzt, indem geeignete Überschriften ausgewählt werden. In unserem Beispiel sieht die Tabelle nach den angegebenen Transformationen so aus:
Wir sehen, dass der Name jeder Spalte eindeutig ist, sodass sie beliebig ausgetauscht werden können, d. H. Ihre Reihenfolge wird irrelevant. Und das ist sehr wichtig, weil es die dritte Eigenschaft ist. 3. Die Reihenfolge der Zeilen sollte nicht signifikant sein. Diese Anforderung ist jedoch auch nicht streng einschränkend, da jede Tabelle leicht auf die erforderliche Form reduziert werden kann. Sie können beispielsweise eine zusätzliche Spalte eingeben, die die Reihenfolge der Zeilen bestimmt. Auch in diesem Fall ändert sich durch das Umordnen der Leitungen nichts. Hier ist ein Beispiel für eine solche Tabelle:
4. Es sollten keine doppelten Zeilen in der Tabelle vorhanden sein, die die Beziehung darstellen. Wenn es doppelte Zeilen in der Tabelle gibt, kann dies leicht behoben werden, indem eine zusätzliche Spalte eingefügt wird, die für die Anzahl der Duplikate jeder Zeile verantwortlich ist, zum Beispiel:
Die folgende Eigenschaft wird ebenfalls durchaus erwartet, da sie allen Prinzipien der Programmierung und des Entwurfs relationaler Datenbanken zugrunde liegt. 5. Daten in allen Spalten müssen vom gleichen Typ sein. Außerdem müssen sie von einfacher Art sein. Lassen Sie uns erklären, was einfache und komplexe Datentypen sind. Ein einfacher Datentyp ist einer, dessen Datenwerte nicht zusammengesetzt sind, das heißt, sie enthalten keine Bestandteile. Daher sollten weder Listen noch Arrays noch Bäume oder ähnliche zusammengesetzte Objekte in den Spalten der Tabelle vorhanden sein. Solche Objekte sind zusammengesetzter Datentyp - In relationalen Datenbankverwaltungssystemen werden sie selbst in Form von unabhängigen Tabellenbeziehungen dargestellt. 2. Domänen und Attribute Domänen und Attribute sind grundlegende Konzepte in der Theorie zum Erstellen und Verwalten von Datenbanken. Lassen Sie uns erklären, was es ist. Formal Attributdomäne (bezeichnet durch Dom (a)), wobei a ein Attribut ist, ist definiert als die Menge gültiger Werte desselben Typs des entsprechenden Attributs a. Dieser Typ muss einfach sein, d. h.: dom(a) ⊆ {x | Typ(x) = Typ(a)}; Attribut (mit a bezeichnet) ist wiederum als geordnetes Paar definiert, das aus dem Attribut name name(a) und dem Attribut domain dom(a) besteht, d. h.: a = (name(a): dom(a)); Diese Definition verwendet ":" anstelle des üblichen "," (wie in Standarddefinitionen für geordnete Paare). Dies geschieht, um die Zuordnung der Domäne des Attributs und des Datentyps des Attributs hervorzuheben. Hier sind einige Beispiele für verschiedene Attribute: а1 = (Kurs: {1, 2, 3, 4, 5}); а2 = (MassaKg: {x | type(x) = real, x 0}); а3 = (LengthSm: {x | type(x) = real, x 0}); Beachten Sie, dass die Attribute a2 und ein3 Domänen stimmen formal überein. Die semantische Bedeutung dieser Attribute ist jedoch unterschiedlich, da ein Vergleich der Werte von Masse und Länge bedeutungslos ist. Daher ist eine Attributdomäne nicht nur mit der Art gültiger Werte verbunden, sondern auch mit einer semantischen Bedeutung. In der tabellarischen Form einer Beziehung wird das Attribut als Spaltenüberschrift in der Tabelle angezeigt, und die Domäne des Attributs wird nicht angegeben, sondern impliziert. Es sieht aus wie das:
Es ist leicht zu erkennen, dass hier jede der Überschriften a1, eine2, eine3 Spalten einer Tabelle, die eine Beziehung darstellen, ist ein separates Attribut. 3. Beziehungsschemata. Benannte Werttupel In der Theorie und Praxis von DBMS sind die Konzepte eines Beziehungsschemas und eines benannten Werts eines Tupels für ein Attribut grundlegend. Bringen wir sie mit. Beziehungsschema (bezeichnet durch S) ist definiert als eine endliche Menge von Attributen mit eindeutigen Namen, d. h.: S = {ein | a ∈ S}; In jeder Tabelle, die eine Relation darstellt, werden alle Spaltenüberschriften (alle Attribute) zum Schema der Relation zusammengefasst. Die Anzahl der Attribute in einem Beziehungsschema bestimmt Степень sie Beziehung und wird als Kardinalität der Menge bezeichnet: |S|. Ein Beziehungsschema kann einem Beziehungsschemanamen zugeordnet werden. Wie Sie leicht erkennen können, ist das Beziehungsschema in tabellarischer Form der Beziehungsdarstellung nichts anderes als eine Reihe von Spaltenüberschriften.
S = {ein1, eine2, eine3, eine4} - Beziehungsschema dieser Tabelle. Der Beziehungsname wird als schematische Überschrift der Tabelle angezeigt. In Textform kann das Beziehungsschema als benannte Liste von Attributnamen dargestellt werden, zum Beispiel: Schüler (Klassenbuchnummer, Nachname, Vorname, Patronym, Geburtsdatum). Attributdomänen werden hier, wie in der tabellarischen Form, nicht angegeben, sondern impliziert. Aus der Definition folgt, dass das Schema einer Relation auch leer sein kann (S = ∅). Dies ist zwar nur theoretisch möglich, da das Datenbankverwaltungssystem in der Praxis niemals die Erstellung eines leeren Beziehungsschemas zulassen wird. Benannter Tupelwert im Attribut (bezeichnet durch t(a)) ist analog zu einem Attribut als geordnetes Paar bestehend aus einem Attributnamen und einem Attributwert definiert, also: t(a) = (name(a) : x), x ∈ dom(a); Wir sehen, dass der Attributwert aus der Attributdomäne stammt. In der tabellarischen Form einer Relation ist jeder benannte Wert eines Tupels für ein Attribut eine entsprechende Tabellenzelle:
Hier t(a1), t(a2), t(a3) - benannte Werte des Tupels t auf Attribute a1Und2Und3. Die einfachsten Beispiele für benannte Tupelwerte bei Attributen: (Kurs: 5), (Punktzahl: 5); Hier sind Course und Score die Namen von zwei Attributen, und 5 ist einer ihrer Werte, die aus ihren Domänen stammen. Obwohl diese Werte in beiden Fällen gleich sind, sind sie natürlich semantisch unterschiedlich, da sich die Mengen dieser Werte in beiden Fällen voneinander unterscheiden. 4. Tupel. Tupeltypen Das Konzept eines Tupels in Datenbankverwaltungssystemen lässt sich intuitiv bereits aus dem vorherigen Punkt finden, als wir über den benannten Wert eines Tupels auf verschiedenen Attributen gesprochen haben. So, Tupel (bezeichnet durch t, aus dem Englischen. Tupel - "Tupel") mit dem Beziehungsschema S ist definiert als die Menge der benannten Werte dieses Tupels für alle Attribute, die in diesem Beziehungsschema S enthalten sind. Mit anderen Worten, Attribute werden entnommen Geltungsbereich eines Tupels, def(t), dh: t ≡ t(S) = {t(a) | a ∈ def(t) ⊆ S;. Wichtig ist, dass einem Attributnamen nicht mehr als ein Attributwert entsprechen darf. In der tabellarischen Form der Beziehung ist ein Tupel eine beliebige Zeile der Tabelle, d. h.:
Hier t1(S) = {t(a1), t(a2), t(a3), t(a4)} und T2(S) = {t(a5), t(a6), t(a7), t(a8)} - Tupel. Tupel im DBMS unterscheiden sich in Typen je nach Definitionsbereich. Die Tupel heißen: 1) teilweise, wenn ihr Definitionsbereich im Schema der Relation enthalten ist oder mit diesem übereinstimmt, d. h. def(t) ⊆ S. Dies ist ein häufiger Fall in der Datenbankpraxis; 2) Komplett, für den Fall, dass ihr Definitionsbereich vollständig übereinstimmt, ist gleich dem Relationsschema, d. h. def(t) = S; 3) unvollständig, wenn der Definitionsbereich vollständig im Beziehungsschema enthalten ist, d. h. def(t) ⊂ S; 4) nirgendwo definiert, wenn ihr Definitionsbereich gleich der leeren Menge ist, d. h. def(t) = ∅. Lassen Sie es uns anhand eines Beispiels erklären. Nehmen wir an, wir haben eine Beziehung, die durch die folgende Tabelle gegeben ist.
Lassen Sie hier t1 = {10, 20, 30}, z2 = {10, 20, Null}, z3 = {Null, Null, Null}. Dann sieht man leicht, dass das Tupel t1 - vollständig, da ihr Definitionsbereich def(t ist1) = {a, b, c} = S. Tupel t2 - unvollständig, def(t2) = { a, b} ⊂ S. Schließlich das Tupel t3 - nirgendwo definiert, da def(t3) = ∅. Es sei darauf hingewiesen, dass ein Tupel, das nirgendwo definiert ist, eine leere Menge ist, die dennoch einem Beziehungsschema zugeordnet ist. Manchmal wird ein nirgendwo definiertes Tupel bezeichnet: ∅(S). Wie wir bereits im obigen Beispiel gesehen haben, ist ein solches Tupel eine Tabellenzeile, die nur aus Nullwerten besteht. Interessanterweise vergleichbar, also möglicherweise gleich, sind nur Tupel mit gleichem Beziehungsschema. Daher sind beispielsweise zwei nirgendwo definierte Tupel mit unterschiedlichen Beziehungsschemata nicht gleich, wie man erwarten könnte. Sie werden genauso unterschiedlich sein wie ihre Beziehungsmuster. 5. Beziehungen. Beziehungstypen Und schließlich definieren wir die Beziehung als eine Art Spitze der Pyramide, die aus allen vorherigen Konzepten besteht. So, Respekt (bezeichnet durch r, aus dem Englischen. Relation) mit Relationenschema S ist definiert als eine notwendigerweise endliche Menge von Tupeln mit demselben Relationenschema S. Also: r ≡ r(S) = {t(S) | t ∈r}; In Analogie zu Beziehungsschemata wird die Anzahl der Tupel in einer Beziehung genannt Beziehungskraft und als Kardinalität der Menge bezeichnet: |r|. Relationen unterscheiden sich wie Tupel in ihrem Typ. Die Beziehung heißt also: 1) teilweise, wenn die folgende Bedingung für irgendein in der Relation enthaltenes Tupel erfüllt ist: [def(t) ⊆ S]. Dies ist (wie bei Tupeln) der allgemeine Fall; 2) Komplett, falls falls ∀t ∈ r(S) gilt [def(t) = S]; 3) unvollständig, falls ∃t ∈ r(S) def(t) ⊂ S; 4) nirgendwo definiert, falls ∀t ∈ r(S) [def(t) = ∅]. Achten wir besonders auf die nirgendwo definierten Beziehungen. Im Gegensatz zu Tupeln erfordert die Arbeit mit solchen Beziehungen ein wenig Feingefühl. Der Punkt ist, dass nirgendwo definierte Relationen von zwei Arten sein können: Sie können entweder leer sein oder sie können ein einzelnes nirgendwo definiertes Tupel enthalten (solche Relationen werden mit {∅(S)} bezeichnet). vergleichbar (in Analogie zu Tupeln), also möglicherweise gleich, sind nur Relationen mit gleichem Relationenschema. Daher sind Beziehungen mit unterschiedlichen Beziehungsmustern unterschiedlich. In tabellarischer Form ist eine Relation der Tabellenkörper, dem die Zeile - die Überschrift der Spalten, also buchstäblich - die gesamte Tabelle samt der ersten Zeile mit den Überschriften entspricht. Vorlesung Nr. 4. Relationale Algebra. Unäre Operationen Relationale Algebra, как нетрудно догадаться, - это особая разновидность алгебры, в которой все операции производятся над реляционными моделями данных, т. е. над отношениями. In tabellarischer Hinsicht umfasst eine Relation Zeilen, Spalten und eine Zeile – die Überschrift der Spalten. Daher sind natürliche unäre Operationen Operationen zum Auswählen bestimmter Zeilen oder Spalten sowie zum Ändern von Spaltenüberschriften - Umbenennen von Attributen. 1. Unäre Auswahloperation Die erste unäre Operation, die wir uns ansehen werden, ist Vorgang abrufen - die Operation des Auswählens von Zeilen aus einer Tabelle, die eine Relation darstellt, gemäß einem bestimmten Prinzip, d. h. Auswählen von Zeilen-Tupeln, die eine bestimmte Bedingung oder bestimmte Bedingungen erfüllen. Abrufoperator mit σ bezeichnet , Abtastbedingung - P , d.h. der Operator σ wird immer mit einer bestimmten Bedingung für die Tupel P genommen, und die Bedingung P selbst wird in Abhängigkeit vom Schema der Beziehung S geschrieben. Unter Berücksichtigung all dessen, der Vorgang abrufen über das Schema der Relation S in Bezug auf die Relation r sieht so aus: σ r(S) ≡ σ r = {t(S) |t ∈ r & Pt} = {t(S) |t ∈ r & IfNull(Pt , falsch}; Das Ergebnis dieser Operation ist eine neue Relation mit demselben Relationenschema S, bestehend aus denjenigen Tupeln t(S) des ursprünglichen Relationenoperanden, die die Auswahlbedingung P t erfüllen. Es ist klar, dass es notwendig ist, die Werte der Tupelattribute anstelle der Attributnamen zu ersetzen, um eine Art Bedingung auf ein Tupel anzuwenden. Um besser zu verstehen, wie diese Operation funktioniert, sehen wir uns ein Beispiel an. Gegeben sei folgendes Beziehungsschema: S: Sitzung (Notenbuchnummer, Nachname, Fach, Note). Nehmen wir die Auswahlbedingung wie folgt: P<S> = (Предмет = ‘Информатика’ and Оценка > 3). Wir müssen aus dem anfänglichen Beziehungsoperanden diejenigen Tupel extrahieren, die Informationen über Studenten enthalten, die das Fach "Informatik" mit mindestens drei Punkten bestanden haben. Aus dieser Relation sei auch das folgende Tupel gegeben: t0(S) ∈ r(S): {(Notenbuchnummer: 100), (Nachname: 'Ivanov'), (Betreff: 'Datenbanken'), (Ergebnis: 5)}; Anwendung unserer Auswahlbedingung auf das Tupel t0wir bekommen: Pt0 = (‘Базы данных’ = ‘Информатика’ and 5 > 3); Bei diesem bestimmten Tupel ist die Auswahlbedingung nicht erfüllt. Im Allgemeinen das Ergebnis dieser bestimmten Probe σ<Fach = 'Informatik' und Note > 3 > Sitzung es wird eine "Session"-Tabelle geben, in der Zeilen übrig bleiben, die die Auswahlbedingung erfüllen. 2. Unäre Projektionsoperation Eine weitere unäre Standardoperation, die wir untersuchen werden, ist die Projektionsoperation. Projektionsbetrieb ist die Operation der Auswahl von Spalten aus einer Tabelle, die eine Beziehung darstellt, gemäß einem Attribut. Die Maschine wählt nämlich jene Attribute (d. h. buchstäblich jene Spalten) der ursprünglichen Operandenbeziehung aus, die in der Projektion spezifiziert wurden. Projektionsoperator mit [S'] oder π bezeichnet . Hier ist S' ein Subschema des ursprünglichen Schemas der Relation S, dh einiger seiner Spalten. Was bedeutet das? Das bedeutet, dass S' weniger Attribute hat als S, weil nur diejenigen Attribute in S' verblieben sind, für die die Projektionsbedingung erfüllt war. Und in der Tabelle, die die Relation r(S') darstellt, gibt es genauso viele Zeilen wie in der Tabelle r(S), und es gibt weniger Spalten, da nur diejenigen verbleiben, die den verbleibenden Attributen entsprechen. Somit ergibt der auf die Relation r(S) angewendete Projektionsoperator π< S'> eine neue Relation mit einem anderen Beziehungsschema r(S' ), bestehend aus Projektionen t(S) [S' ] von Tupeln des Originals Beziehung. Wie sind diese Tupelprojektionen definiert? Projektion eines beliebigen Tupels t(S) der ursprünglichen Relation r(S) zur Teilschaltung S' wird durch die folgende Formel bestimmt: t(S) [S'] = {t(a)|a ∈ def(t) ∩ S'}, S' ⊆S. Es ist wichtig zu beachten, dass doppelte Tupel aus dem Ergebnis ausgeschlossen werden, d. h. es gibt keine doppelten Zeilen in der Tabelle, die die neue darstellen. Unter Berücksichtigung all dessen würde eine Projektionsoperation in Bezug auf Datenbankverwaltungssysteme wie folgt aussehen: π r(S) ≡ π r ≡ r(S) [S'] ≡ r [S' ] = {t(S) [S'] | t ∈ r}; Sehen wir uns ein Beispiel an, das veranschaulicht, wie die Abrufoperation funktioniert. Gegeben sei die Relation „Session“ und das Schema dieser Relation: S: Sitzung (Klassenbuchnummer, Nachname, Fach, Note); Wir interessieren uns nur für zwei Attribute aus diesem Schema, nämlich die „Notenbuchnummer“ und den „Nachnamen“ des Schülers, sodass das Unterschema von S wie folgt aussieht: S': (Registerbuchnummer, Nachname). Es ist notwendig, die Anfangsbeziehung r(S) auf die Teilschaltung S' zu projizieren. Als nächstes soll uns ein Tupel t gegeben werden0(S) aus der ursprünglichen Beziehung: t0(S) ∈ r(S): {(Notenbuchnummer: 100), (Nachname: 'Ivanov'), (Betreff: 'Datenbanken'), (Ergebnis: 5)}; Daher sieht die Projektion dieses Tupels auf die gegebene Teilschaltung S' wie folgt aus: t0(S) S': {(Kontobuchnummer: 100), (Nachname: 'Iwanow')}; Wenn wir über die Projektionsoperation in Bezug auf Tabellen sprechen, dann ist die Projektionssitzung [Notenbuchnummer, Nachname] der ursprünglichen Beziehung die Sitzungstabelle, aus der alle Spalten gelöscht werden, mit Ausnahme von zwei: Notenbuchnummer und Nachname. Außerdem wurden alle doppelten Zeilen entfernt. 3. Unäre Umbenennungsoperation Und die letzte unäre Operation, die wir uns ansehen werden, ist Attributumbenennungsvorgang. Wenn wir über die Beziehung als Tabelle sprechen, dann ist die Umbenennungsoperation erforderlich, um die Namen aller oder einiger Spalten zu ändern. Betreiber umbenennen sieht so aus: ρ<φ>, hier φ - Funktion umbenennen. Diese Funktion stellt eine Eins-zu-Eins-Entsprechung zwischen den Schemaattributnamen S und Ŝ her, wobei S jeweils das Schema der ursprünglichen Relation und Ŝ das Schema der Relation mit umbenannten Attributen ist. Somit ergibt der auf die Relation r(S) angewendete Operator ρ<φ> eine neue Relation mit dem Schema Ŝ, bestehend aus Tupeln der ursprünglichen Relation mit nur umbenannten Attributen. Schreiben wir die Operation zum Umbenennen von Attributen in Bezug auf Datenbankverwaltungssysteme: ρ<φ> r(S) ≡ ρ<φ>r = {ρ<φ> t(S)| t ∈ r}; Hier ist ein Beispiel für die Verwendung dieser Operation: Betrachten wir die uns bereits bekannte Beziehung Session mit dem Schema: S: Sitzung (Klassenbuchnummer, Nachname, Fach, Note); Lassen Sie uns ein neues Beziehungsschema Ŝ einführen, mit anderen Attributnamen, die wir gerne anstelle der bestehenden sehen würden: Ŝ : (Nr. ZK, Nachname, Thema, Punktzahl); Beispielsweise wollte ein Datenbankkunde andere Namen in Ihrer sofort einsatzbereiten Beziehung sehen. Um diese Reihenfolge umzusetzen, müssen Sie die folgende Umbenennungsfunktion entwerfen: φ : (Rechnungsbuch-Nr., Nachname, Fach, Note) → (ZK-Nr., Nachname, Fach, Note); Tatsächlich müssen nur zwei Attribute umbenannt werden, daher ist es zulässig, die folgende Umbenennungsfunktion anstelle der aktuellen zu schreiben: φ : (Nummer des Rekordbuchs, Note) → (Nr. ZK, Partitur); Weiterhin sei auch das bereits bekannte Tupel der Session-Relation gegeben: t0(S) ∈ r(S): {(Notenbuchnummer: 100), (Nachname: 'Ivanov'), (Betreff: 'Datenbanken'), (Ergebnis: 5)}; Wenden Sie den Umbenennungsoperator auf dieses Tupel an: ρ<φ>t0(S): {(ZK#: 100), (Nachname: 'Ivanov'), (Betreff: 'Datenbanken'), (Punktzahl: 5)}; Dies ist also eines der Tupel unserer Relation, dessen Attribute umbenannt wurden. In tabellarischer Form das Verhältnis ρ < Notenbuchnummer, Note → "Nr. ZK, Partitur > Sitzung - Dies ist eine neue Tabelle, die aus der Beziehungstabelle "Sitzung" durch Umbenennen der angegebenen Attribute erhalten wird. 4. Eigenschaften unärer Operationen Unäre Operationen haben wie alle anderen bestimmte Eigenschaften. Betrachten wir die wichtigsten von ihnen. Die erste Eigenschaft der unären Auswahl-, Projektions- und Umbenennungsoperationen ist die Eigenschaft, die das Verhältnis der Kardinalitäten der Relationen charakterisiert. (Erinnern Sie sich, dass die Kardinalität die Anzahl der Tupel in der einen oder anderen Relation ist.) Es ist klar, dass wir hier jeweils die anfängliche Relation und die Relation betrachten, die als Ergebnis der Anwendung der einen oder anderen Operation erhalten wird. Beachten Sie, dass alle Eigenschaften unärer Operationen direkt aus ihren Definitionen folgen, sodass sie leicht erklärt und auf Wunsch sogar unabhängig voneinander abgeleitet werden können. Also: 1) Leistungsverhältnis: a) für die Auswahloperation: | σ r |≤ |r|; b) für die Projektionsoperation: | r[S'] | ≤ |r|; c) für die Umbenennungsoperation: | ρ<φ>r | = |r|; Insgesamt sehen wir, dass für zwei Operatoren, nämlich für den Auswahloperator und den Projektionsoperator, die Potenz der ursprünglichen Relationen - Operanden größer ist als die Potenz der Relationen, die durch Anwendung der entsprechenden Operationen aus den ursprünglichen erhalten werden. Dies liegt daran, dass die Auswahl, die diese beiden Auswahl- und Projektoperationen begleitet, einige Zeilen oder Spalten ausschließt, die die Auswahlbedingungen nicht erfüllen. Für den Fall, dass alle Zeilen oder Spalten die Bedingungen erfüllen, gibt es keine Potenzabnahme (d. h. die Anzahl der Tupel), sodass die Ungleichung in den Formeln nicht streng ist. Bei der Umbenennungsoperation ändert sich die Potenz der Relation nicht, da beim Ändern von Namen keine Tupel aus der Relation ausgeschlossen werden; 2) idempotente Eigenschaft: a) für den Abtastvorgang: σ σ r = σ ; b) für die Projektionsoperation: r [S'] [S'] = r [S']; c) für die Umbenennungsoperation ist im allgemeinen Fall die Eigenschaft der Idempotenz nicht anwendbar. Diese Eigenschaft bedeutet, dass die zweimalige Anwendung desselben Operators nacheinander auf eine beliebige Beziehung einer einmaligen Anwendung entspricht. Für die Operation der Umbenennung von Beziehungsattributen kann diese Eigenschaft im Allgemeinen verwendet werden, jedoch mit besonderen Einschränkungen und Bedingungen. Die Eigenschaft der Idempotenz wird sehr oft verwendet, um die Form eines Ausdrucks zu vereinfachen und in eine sparsamere, tatsächlichere Form zu bringen. Und die letzte Eigenschaft, die wir betrachten werden, ist die Eigenschaft der Monotonie. Es ist interessant festzustellen, dass unter allen Bedingungen alle drei Operatoren monoton sind; 3) Monotonie Eigenschaft: a) für eine Abrufoperation: r1 ⊆ r2 ⇒σ r1 ⇒ σ r2; b) für die Projektionsoperation: r1 ⊆ r2 ⇒ r1[S'] ⊆ r2 [S']; c) für die Umbenennungsoperation: r1 ⊆ r2 ⇒ ρ<φ>r1 ⊆ ρ<φ>r2; Das Konzept der Monotonie in der relationalen Algebra ähnelt dem Konzept der gewöhnlichen, allgemeinen Algebra. Klären wir: Wenn zunächst die Relationen r1 und r2 so zueinander in Beziehung standen, dass r ⊆ r2, dann bleibt diese Beziehung auch nach Anwendung eines der drei Auswahl-, Projektions- oder Umbenennungsoperatoren erhalten. Vorlesung Nr. 5. Relationale Algebra. Binäre Operationen 1. Operationen der Vereinigung, Schnittmenge, Differenz Alle Operationen haben ihre eigenen Anwendbarkeitsregeln, die beachtet werden müssen, damit Ausdrücke und Aktionen nicht ihre Bedeutung verlieren. Die binären mengentheoretischen Operationen Vereinigung, Durchschnitt und Differenz können nur auf zwei Relationen mit notwendigerweise gleichem Relationenschema angewendet werden. Das Ergebnis solcher binären Operationen sind Beziehungen, die aus Tupeln bestehen, die die Bedingungen der Operationen erfüllen, aber mit demselben Beziehungsschema wie die Operanden. 1. Das Ergebnis Gewerkschaftliche Operationen zwei Beziehungen r1(S) und r2(S) es wird eine neue Relation r geben3(S) bestehend aus diesen Tupeln von Relationen r1(S) und r2(S), die zu mindestens einer der ursprünglichen Relationen gehören und das gleiche Relationenschema haben. Der Schnittpunkt der beiden Relationen ist also: r3(S) = r1(S)r2(S) = {t(S) | t ∈r1 ∪t ∈r2}; Zur Verdeutlichung hier ein Beispiel in Form von Tabellen: Gegeben seien zwei Relationen: r1(S):
r2(S):
Wir sehen, dass die Schemata der ersten und zweiten Relation gleich sind, nur dass sie eine unterschiedliche Anzahl von Tupeln haben. Die Vereinigung dieser beiden Relationen wird die Relation r sein3(S), was der folgenden Tabelle entspricht: r3(S) = r1(S)r2(S):
Das Schema der Relation S hat sich also nicht geändert, nur die Anzahl der Tupel hat zugenommen. 2. Kommen wir zur Betrachtung der nächsten binären Operation - Kreuzungsbetrieb zwei Beziehungen. Wie wir aus der Schulgeometrie wissen, enthält die resultierende Relation nur diejenigen Tupel der ursprünglichen Relationen, die gleichzeitig in beiden Relationen r vorhanden sind1(S) und r2(S) (beachten Sie wieder das gleiche Beziehungsmuster). Die Operation der Schnittmenge zweier Relationen sieht folgendermaßen aus: r4(S) = r1(S)∩r2(S) = {t(S) | t ∈ r1 & t ∈ r2}; Betrachten Sie erneut die Auswirkung dieser Operation auf die in Form von Tabellen dargestellten Beziehungen: r1(S):
r2(S):
Gemäß der Definition der Operation durch den Schnittpunkt der Relationen r1(S) und r2(S) es wird eine neue Relation r geben4(S), dessen Tabellenansicht so aussehen würde: r4(S) = r1(S)∩r2(S):
In der Tat, wenn wir uns die Tupel der ersten und zweiten Anfangsrelation ansehen, gibt es unter ihnen nur eine Gemeinsamkeit: {b, 2}. Es wurde das einzige Tupel der neuen Relation r4(S). 3. Differenzoperation Zwei Relationen werden ähnlich wie bei den vorherigen Operationen definiert. Operandenbeziehungen müssen wie in den vorherigen Operationen dieselben Beziehungsschemata haben, dann enthält die resultierende Beziehung alle Tupel der ersten Beziehung, die nicht in der zweiten sind, d.h.: r5(S) = r1(S)\r2(S) = {t(S) | t ∈ r1 & t ∉ r2}; Die bereits bekannten Beziehungen r1(S) und r2(S), in einer tabellarischen Ansicht, die so aussieht: r1(S):
r2(S):
Wir werden beide Operanden bei der Operation der Schnittmenge zweier Relationen betrachten. Dann sieht nach dieser Definition die resultierende Beziehung r5(S) so aus: r5(S) = r1(S)\r2(S):
Die betrachteten binären Operationen sind grundlegend, andere Operationen, komplexere, basieren darauf. 2. Kartesisches Produkt und natürliche Verknüpfungsoperationen Die kartesische Produktoperation und die natürliche Verknüpfungsoperation sind binäre Operationen des Produkttyps und basieren auf der Vereinigung zweier Beziehungsoperationen, die wir zuvor besprochen haben. Obwohl die Wirkungsweise der kartesischen Produktoperation vielen bekannt vorkommen mag, beginnen wir dennoch mit der Naturproduktoperation, da es sich um einen allgemeineren Fall als die erste Operation handelt. Betrachten Sie also die natürliche Join-Operation. Es sei gleich darauf hingewiesen, dass die Operanden dieser Aktion Relationen mit unterschiedlichen Schemata sein können, im Gegensatz zu den drei binären Operationen Vereinigung, Schnittmenge und Umbenennung. Betrachten wir zwei Relationen mit unterschiedlichen Relationenschemata r1(S1) und r2(S2), dann ihre natürliche Verbindung es wird eine neue Relation r geben3(S3), die nur aus den Tupeln von Operanden bestehen, die an der Schnittmenge von Beziehungsschemata übereinstimmen. Dementsprechend wird das Schema der neuen Beziehung größer sein als jedes der Beziehungsschemata der ursprünglichen, da es ihre Verbindung, das "Kleben", ist. Übrigens werden Tupel aufgerufen, die in zwei Operandenbeziehungen identisch sind, nach denen dieses "Verkleben" erfolgt anschließbar. Schreiben wir die Definition der natürlichen Join-Operation in der Formelsprache von Datenbankverwaltungssystemen: r3(S3) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}; Betrachten wir ein Beispiel, das die Arbeit einer natürlichen Verbindung, ihr "Kleben", gut veranschaulicht. Seien zwei Relationen r1(S1) und r2(S2), in der tabellarischen Darstellungsform jeweils gleich: r1(S1):
r2(S2):
Wir sehen, dass diese Relationen Tupel haben, die am Schnittpunkt der Schemata S zusammenfallen1 und S2 Beziehungen. Lassen Sie uns sie auflisten: 1) Tupel {a, 1} der Relation r1(S1) entspricht dem Tupel {1, x} der Relation r2(S2); 2) Tupel {b, 1} von r1(S1) passt auch auf das Tupel {1, x} von r2(S2); 3) das Tupel {c, 3} passt zum Tupel {3, z}. Daher ist unter Natural Join die neue Relation r3(S3) erhält man, indem man genau auf diese Tupel "klebt". Also r3(S3) in einer Tabellenansicht sieht so aus: r3(S3) = r1(S1)xr2(S2):
Es stellt sich per Definition heraus: Schema S3 stimmt nicht mit dem Schema S überein1, noch mit dem Schema S2, haben wir die beiden ursprünglichen Schemas "verklebt", indem wir Tupel überschneiden, um ihre natürliche Verbindung zu erhalten. Lassen Sie uns schematisch zeigen, wie Tupel verbunden werden, wenn die natürliche Join-Operation angewendet wird. Sei die Beziehung r1 hat eine bedingte Form:
Und das Verhältnis r2 - Aussicht:
Dann würde ihre natürliche Verbindung so aussehen:
Wir sehen, dass das "Verkleben" von Relationen-Operanden nach dem gleichen Schema erfolgt, das wir zuvor anhand des Beispiels angegeben haben. Betrieb Kartesische Verbindung ist ein Sonderfall der natürlichen Verknüpfungsoperation. Genauer gesagt, wenn wir die Auswirkung der kartesischen Produktoperation auf Beziehungen betrachten, stellen wir bewusst fest, dass wir in diesem Fall nur von nicht überschneidenden Beziehungsschemata sprechen können. Als Ergebnis der Anwendung beider Operationen werden Relationen mit Schemata gleich der Vereinigung von Schemas von Operandenrelationen erhalten, nur alle möglichen Paare ihrer Tupel fallen in das kartesische Produkt zweier Relationen, da sich die Schemata von Operanden auf keinen Fall schneiden sollten. Basierend auf dem Vorhergehenden schreiben wir also eine mathematische Formel für die kartesische Produktoperation: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2= ∅; Sehen wir uns nun ein Beispiel an, um zu zeigen, wie das resultierende Beziehungsschema aussehen wird, wenn die kartesische Produktoperation angewendet wird. Seien zwei Relationen r1(S1) und r2(S2), die sich tabellarisch wie folgt darstellen: r1(S1):
r2(S2):
Wir sehen also, dass keines der Beziehungstupel r1(S1) und r2(S2), stimmt in ihrem Schnittpunkt tatsächlich nicht überein. Daher ist in der resultierenden Beziehung r4(S4) fallen alle möglichen Paare von Tupeln der ersten und zweiten Operandenbeziehung. Erhalten: r4(S4) = r1(S1)xr2(S2):
Wir haben ein neues Beziehungsschema r erhalten4(S4) nicht durch "Kleben" von Tupeln wie im vorherigen Fall, sondern durch Aufzählung aller möglichen unterschiedlichen Tupelpaare, die nicht in der Schnittmenge der ursprünglichen Schemata übereinstimmen. Wieder geben wir, wie im Fall der natürlichen Verbindung, ein schematisches Beispiel für die Operation der kartesischen Produktoperation. Lassen Sie r1 wie folgt einstellen:
Und das Verhältnis r2 gegeben:
Dann kann ihr kartesisches Produkt wie folgt schematisch dargestellt werden:
Auf diese Weise erhält man die resultierende Beziehung, wenn man die kartesische Produktoperation anwendet. 3. Eigenschaften binärer Operationen Aus den obigen Definitionen der binären Operationen von Vereinigung, Durchschnitt, Differenz, kartesischem Produkt und natürlicher Verbindung folgen die Eigenschaften. 1. Die erste Eigenschaft, wie im Fall von einstufigen Operationen, veranschaulicht Leistungsverhältnis Beziehungen: 1) für den Gewerkschaftsbetrieb: |r1 ∪r2| ≤ |r1| + |r2|; 2) für den Schnittpunktbetrieb: |r1 ∩r2 | ≤ min(|r1|, |r2|); 3) für die Differenzoperation: |r1 \r2| ≤ |r1|; 4) für die kartesische Produktoperation: |r1 xr2| = |r1| |r2|; 5) für natürliche Join-Operation: |r1 xr2| ≤ |r1| |r2|. Wie wir uns erinnern, charakterisiert das Verhältnis der Potenzen, wie sich die Anzahl der Tupel in Relationen nach Anwendung der einen oder anderen Operation ändert. Was sehen wir also? Leistung Vereinigungen zwei Beziehungen r1 und r2 kleiner als die Summe der Kardinalitäten der ursprünglichen Relationen-Operanden. Warum passiert das? Die Sache ist, dass beim Zusammenführen übereinstimmende Tupel verschwinden und sich gegenseitig überlappen. Wenn Sie sich also auf das Beispiel beziehen, das wir nach Durchlaufen dieser Operation betrachtet haben, können Sie sehen, dass es in der ersten Relation zwei Tupel gab, in der zweiten - drei und im Ergebnis - vier, d.h. weniger als fünf (die Summe der Kardinalitäten der Relationen-Operanden ). Durch das passende Tupel {b, 2} werden diese Relationen "zusammengeklebt". Ergebnisleistung Kreuzungen zwei Beziehungen kleiner oder gleich der Mindestkardinalität der ursprünglichen Operandenbeziehungen ist. Kommen wir zur Definition dieser Operation: Nur die Tupel, die in beiden Ausgangsrelationen vorhanden sind, gelangen in die resultierende Relation. Das bedeutet, dass die Kardinalität der neuen Relation die Kardinalität des Relationenoperanden, dessen Tupelzahl die kleinste der beiden ist, nicht überschreiten kann. Und die Potenz des Ergebnisses kann gleich dieser minimalen Kardinalität sein, da immer der Fall erlaubt ist, dass alle Tupel einer Relation mit niedrigerer Kardinalität mit einigen Tupeln des zweiten Relationenoperanden übereinstimmen. Im Betriebsfall Unterschiede alles ganz trivial. Wenn nämlich alle Tupel, die auch in der zweiten Relation vorhanden sind, vom ersten Relationenoperanden "subtrahiert" werden, dann nimmt ihre Anzahl (und folglich ihre Potenz) ab. Für den Fall, dass kein einziges Tupel der ersten Relation mit irgendeinem Tupel der zweiten Relation übereinstimmt, d. h. es gibt nichts zu „subtrahieren“, nimmt seine Stärke nicht ab. Interessanterweise, wenn die Operation kartesisches Produkt die Potenz der resultierenden Beziehung ist genau gleich dem Produkt der Potenzen der beiden Operandenbeziehungen. Es ist klar, dass dies geschieht, weil alle möglichen Tupelpaare der ursprünglichen Relationen in das Ergebnis geschrieben werden und nichts ausgeschlossen wird. Und schließlich die Operation natürliche Verbindung man erhält eine Relation, deren Potenz größer oder gleich dem Produkt der Potenzen der beiden ursprünglichen Relationen ist. Dies geschieht wiederum, weil die Operandenbeziehungen durch übereinstimmende Tupel "zusammengeklebt" werden und nicht übereinstimmende Tupel vollständig aus dem Ergebnis ausgeschlossen werden. 2. Idempotenz-Eigenschaft: 1) für die Vereinigungsoperation: r ∪ r = r; 2) für die Schnittoperation: r ∩ r = r; 3) für die Differenzoperation: r \ r ≠ r; 4) für die kartesische Produktoperation (im allgemeinen Fall ist die Eigenschaft nicht anwendbar); 5) für die natürliche Join-Operation: rxr = r. Interessanterweise gilt die Eigenschaft der Idempotenz nicht für alle oben genannten Operationen, und für die Operation des kartesischen Produkts ist sie überhaupt nicht anwendbar. In der Tat, wenn Sie eine Beziehung kombinieren, schneiden oder auf natürliche Weise mit sich selbst verbinden, wird sie sich nicht ändern. Aber wenn Sie von einer genau gleichen Relation subtrahieren, wird das Ergebnis eine leere Relation sein. 3. Kommutativgesetz: 1) für den Gewerkschaftsbetrieb: r1 ∪r2 = r2 ∪r1; 2) für den Schnittpunktbetrieb: r ∩ r = r ∩ r; 3) für die Differenzoperation: r1 \r2 ≠r2 \r1; 4) für die kartesische Produktoperation: r1 xr2 = r2 xr1; 5) für natürliche Join-Operation: r1 xr2 = r2 xr1. Die Kommutativitätseigenschaft gilt für alle Operationen außer der Differenzoperation. Dies ist leicht zu verstehen, da sich ihre Zusammensetzung (Tupel) nicht ändert, wenn die Beziehungen stellenweise neu angeordnet werden. Und bei der Anwendung der Differenzoperation ist es wichtig, welche der Operandenrelationen zuerst kommt, denn es hängt davon ab, welche Tupel welcher Relation als Referenz genommen werden, d. h. mit welchen Tupeln andere Tupel auf Ausschluss verglichen werden. 4. Assoziativitätseigenschaft: 1) für den Gewerkschaftsbetrieb: (r1 ∪r2)∪r3 = r1 ∪(r2 ∪r3); 2) für den Schnittpunktbetrieb: (r1 ∩r2)∩r3 = r1 ∩(r2 ∩r3); 3) für die Differenzoperation: (r1 \r2)\r3 ≠r1 \ (R2 \r3); 4) für die kartesische Produktoperation: (r1 xr2)xr3 = r1 x(r2 xr3); 5) für natürliche Join-Operation: (r1 xr2)xr3 = r1 x(r2 xr3). Und wieder sehen wir, dass die Eigenschaft für alle Operationen außer der Differenzoperation ausgeführt wird. Dies wird genauso erklärt wie bei der Anwendung des Kommutativgesetzes. Im Großen und Ganzen ist es den Operationen Vereinigung, Schnittmenge, Differenz und natürlicher Verknüpfung egal, in welcher Reihenfolge die Operandenbeziehungen sind. Aber wenn Beziehungen voneinander "weggenommen" werden, spielt die Ordnung eine dominierende Rolle. Basierend auf den obigen Eigenschaften und Überlegungen kann die folgende Schlussfolgerung gezogen werden: Die letzten drei Eigenschaften, nämlich die Eigenschaft der Idempotenz, der Kommutativität und der Assoziativität, gelten für alle betrachteten Operationen, mit Ausnahme der Operation der Differenz zweier Relationen , für die keine der drei angegebenen Eigenschaften überhaupt erfüllt war, und nur in einem Fall wurde die Eigenschaft als nicht anwendbar befunden. 4. Verbindungsbetriebsoptionen Ausgehend von den zuvor betrachteten unären Operationen Auswahl, Projektion, Umbenennung und binären Operationen Vereinigung, Schnitt, Differenz, kartesisches Produkt und natürliche Verknüpfung (allgemein bezeichnet als Verbindungsoperationen), können wir neue Operationen einführen, die unter Verwendung der obigen Konzepte und Definitionen abgeleitet wurden. Diese Aktivität wird Kompilieren genannt. Join-Operationsoptionen. Die erste derartige Variante von Join-Operationen ist die Operation innere Verbindung entsprechend der angegebenen Anschlussbedingung. Die Operation einer inneren Verknüpfung wird durch eine bestimmte Bedingung als abgeleitete Operation aus den Operationen des kartesischen Produkts und der Auswahl definiert. Wir schreiben die Formeldefinition dieser Operation: r1(S1)X P r2(S2) = σ (r1 xr2), st1 ∩S2 = ∅; Hier ist P = P<S1 ∪S2> - eine Bedingung, die der Vereinigung zweier Schemata der ursprünglichen Beziehungsoperanden auferlegt wird. Durch diese Bedingung werden Tupel aus den Relationen r ausgewählt1 und r2 in die resultierende Beziehung. Beachten Sie, dass die Inner Join-Operation auf Beziehungen mit unterschiedlichen Beziehungsschemas angewendet werden kann. Diese Schemata können beliebig sein, sollten sich jedoch auf keinen Fall überschneiden. Die Tupel der ursprünglichen Beziehungsoperanden, die das Ergebnis der Inner-Join-Operation sind, werden aufgerufen verbindbare Tupel. Um die Operation der Inner-Join-Operation visuell zu veranschaulichen, geben wir das folgende Beispiel. Gegeben seien zwei Relationen r1(S1) und r2(S2) mit unterschiedlichen Beziehungsschemata: r1(S1):
r2(S2):
Die folgende Tabelle gibt das Ergebnis der Anwendung der Inner-Join-Operation auf die Bedingung P = (b1 = b2). r1(S1)X P r2(S2):
Wir sehen also, dass das "Verkleben" der beiden Tabellen, die die Beziehung darstellen, wirklich genau für die Tupel passiert ist, in denen die Bedingung der Inner-Join-Operation P = (b1 = b2) erfüllt ist. Basierend auf der bereits eingeführten Operation Inner Join können wir nun die Operation einführen Linke äußere Verbindung и rechter äußerer Join. Lassen Sie uns erklären. Das Ergebnis der Operation Left Outer Join ist das Ergebnis des Inner Join, vervollständigt mit nicht verknüpfbaren Tupeln des linken Quellbeziehungsoperanden. In ähnlicher Weise ist das Ergebnis einer rechten äußeren Verknüpfungsoperation als das Ergebnis einer inneren Verknüpfungsoperation definiert, die mit nicht verknüpfbaren Tupeln des rechtshändigen Quellbeziehungsoperanden erweitert ist. Die Frage, wie die resultierenden Relationen der Operationen der linken und rechten Outer-Joins ergänzt werden, ist durchaus zu erwarten. Tupel eines Beziehungsoperanden werden auf dem Schema eines anderen Beziehungsoperanden ergänzt Nullwerte. Es ist erwähnenswert, dass die auf diese Weise eingeführten Links- und Rechts-Outer-Join-Operationen von der Inner-Join-Operation abgeleitete Operationen sind. Um die allgemeinen Formeln für die Links- und Rechts-Outer-Join-Operationen aufzuschreiben, führen wir einige zusätzliche Konstruktionen durch. Gegeben seien zwei Relationen r1(S1) und r2(S2) mit verschiedenen Beziehungsschemata S1 und S2, die sich nicht schneiden. Da wir bereits festgelegt haben, dass die Left- und Right-Inner-Join-Operationen Ableitungen sind, erhalten wir folgende Hilfsformeln zur Bestimmung der Left-Outer-Join-Operation: 1) r3 (S2 ∪S1) ≔ r1(S1)X Pr2(S2); r 3 (S2 ∪S1) ist einfach das Ergebnis der inneren Verknüpfung der Relationen r1(S1) und r2(S2). Der Left Outer Join ist eine abgeleitete Operation des Inner Join, weshalb wir unsere Konstruktionen damit beginnen; 2) r4(S1) ≔ r 3(S2 ∪S1) [S1]; Wir haben also mit Hilfe einer unären Projektionsoperation alle verbindbaren Tupel des linken initialen Relationenoperanden r selektiert1(S1). Das Ergebnis wird mit r bezeichnet4(S1) für Benutzerfreundlichkeit; 3) r5 (S1) ≔ r1(S1)\r4(S1); Hier r1(S1) sind alle Tupel des linken Quellrelationsoperanden und r4(S1) - seine eigenen Tupel, nur verbunden. Somit wird die binäre Operation der Differenz in Bezug auf r verwendet5(S1) haben wir alle nicht verknüpfbaren Tupel der linken Operandenbeziehung; 4) r6(S2)≔{∅(S2)}; {∅(S2)} ist eine neue Relation mit dem Schema (S2) enthält nur ein Tupel und besteht aus Nullwerten. Der Einfachheit halber haben wir dieses Verhältnis als r bezeichnet6(S2); 5) r7 (S2 ∪S1) ≔ r5(S1)xr6(S2); Hier haben wir die unverbundenen Tupel der linken Operandenrelation (r5(S1)) und ergänzte sie nach dem Schema des zweiten Relationenoperanden S2 Nullwerte, d. h. kartesisch, multiplizierten die Relation, die aus denselben nicht verknüpfbaren Tupeln besteht, mit der Relation r6(S2) definiert in Absatz XNUMX; 6) r1(S1) →x P r2(S2) ≔ (r1 x P r2)∪r7 (S2 ∪S1); Dies ist Linke äußere Verbindung, erhalten, wie man sehen kann, durch die Vereinigung des kartesischen Produkts der ursprünglichen Beziehungsoperanden r1 und r2 und Beziehungen r7 (S2 ∪ S1) im Sinne von Absatz XNUMX. Jetzt haben wir alle notwendigen Berechnungen, um nicht nur die Operation des Left Outer Joins zu bestimmen, sondern analog auch die Operation des Right Outer Joins zu bestimmen. So: 1) Betrieb Linke äußere Verbindung in strenger Form sieht es so aus: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r1 \ (R1 x P r2) [S1]) x {∅(S2)}]; 2) Betrieb rechter äußerer Join ist ähnlich wie die Left-Outer-Join-Operation definiert und hat folgende Form: r1(S1) →x P r2(S2) ≔ (r1 x P r2) ∪ [(r2 \ (R1 x P r2) [S2]) x {∅(S1)}]; Diese beiden abgeleiteten Operationen haben nur zwei erwähnenswerte Eigenschaften. 1. Kommutativitätseigenschaft: 1) für die Operation Left Outer Join: r1(S1) →x P r2(S2) ≠ r2(S2) →x P r1(S1); 2) für die rechte Outer-Join-Operation: r1(S1) ←x P r2(S2) ≠ r2(S2) ←x P r1(S1) Wir sehen also, dass die Kommutativitätseigenschaft für diese Operationen in allgemeiner Form nicht erfüllt ist, aber gleichzeitig sind die Operationen der linken und rechten äußeren Verknüpfungen zueinander invers, d.h. es gilt: 1) für die Operation Left Outer Join: r1(S1) →x P r2(S2) = r2(S2) →x P r1(S1); 2) für die rechte Outer-Join-Operation: r1(S1) ←x P r2(S2) = r2(S2) ←x Pr1(S1). 2. Die Haupteigenschaft von Left- und Right-Outer-Join-Operationen ist, dass sie es zulassen wiederherstellen der anfängliche Beziehungsoperand gemäß dem Endergebnis einer bestimmten Join-Operation, d. h. Folgendes wird ausgeführt: 1) für die Operation Left Outer Join: r1(S1) = (r1 →x P r2) [S1]; 2) für die rechte Outer-Join-Operation: r2(S2) = (r1 ←x P r2) [S2]. Wir sehen also, dass der erste ursprüngliche Beziehungsoperand aus dem Ergebnis der Links-Rechts-Join-Operation wiederhergestellt werden kann, genauer gesagt durch Anwendung auf das Ergebnis dieses Joins (r1 xr2) die unäre Operation der Projektion auf das Schema S1, [S.1]. Und in ähnlicher Weise kann der zweite ursprüngliche Beziehungsoperand wiederhergestellt werden, indem der rechte äußere Join (r1 xr2) die unäre Operation der Projektion auf das Schema der Relation S2. Lassen Sie uns zur näheren Betrachtung der Funktionsweise die Operationen der linken und rechten Outer-Joins an einem Beispiel anführen. Führen wir die bereits bekannten Beziehungen r ein1(S1) und r2(S2) mit unterschiedlichen Beziehungsschemata: r1(S1):
r2(S2):
Nicht verbindbares Tupel des linken Beziehungsoperanden r2(S2) ist ein Tupel {d, 4}. Sie sind es, der Definition folgend, die das Ergebnis der internen Verknüpfung der beiden ursprünglichen Operandenbeziehungen ergänzen sollen. Inner-Join-Bedingung von Relationen r1(S1) und r2(S2) lassen wir auch gleich: P = (b1 = b2). Dann das Ergebnis der Operation Linke äußere Verbindung Es wird folgende Tabelle geben: r1(S1) →x P r2(S2):
Tatsächlich wurde, wie wir sehen können, als Ergebnis der Operation des Left Outer Join das Ergebnis der Inner Join-Operation mit nicht verbindbaren Tupeln der linken Seite aufgefüllt, d. h. in unserem Fall die erste Relation. Operand. Die Auffüllung des Tupels nach dem Schema des zweiten (rechten) Source-Relation-Operanden geschah per Definition mit Hilfe von Null-Werten. Und ähnlich dem Ergebnis rechter äußerer Join nach wie vor die Bedingung P = (b1 = b2) der ursprünglichen Relationsoperanden r1(S1) und r2(S2) ist die folgende Tabelle: r1(S1) ←x P r2(S2):
Tatsächlich sollte in diesem Fall das Ergebnis der inneren Verknüpfungsoperation mit nicht verknüpfbaren Tupeln des rechten, in unserem Fall des zweiten anfänglichen Beziehungsoperanden, ergänzt werden. Ein solches Tupel, wie man unschwer erkennen kann, in der zweiten Relation r2(S2) eins, nämlich {2, y}. Als nächstes arbeiten wir an der Definition der Operation des rechten äußeren Joins, ergänzen das Tupel des ersten (linken) Operanden im Schema des ersten Operanden mit Null-Werten. Schauen wir uns zum Schluss die dritte Version der obigen Verknüpfungsoperationen an. Vollständiger Outer-Join-Vorgang. Diese Operation kann nicht nur als eine Operation angesehen werden, die von Inner-Join-Operationen abgeleitet ist, sondern auch als Vereinigung von Left- und Right-Outer-Join-Operationen. Vollständiger Outer-Join-Vorgang ist definiert als das Ergebnis der Vervollständigung desselben inneren Joins (wie im Fall der Definition von linken und rechten äußeren Joins) mit nicht verknüpfbaren Tupeln sowohl der linken als auch der rechten Anfangsoperandenbeziehung. Basierend auf dieser Definition geben wir die formelhafte Form dieser Definition an: r1(S1) ↔x P r2(S2) = (r1 →x P r2) ∪ (r1 ←x P r2); Die vollständige Outer-Join-Operation hat auch eine ähnliche Eigenschaft wie die linke und die rechte Outer-Join-Operation. Nur aufgrund der ursprünglichen reziproken Natur der vollständigen Outer-Join-Operation (schließlich wurde sie als Vereinigung von linken und rechten Outer-Join-Operationen definiert) funktioniert sie Kommutativitätseigenschaft: r1(S1) ↔x P r2(S2)=r2(S2) ↔ x P r1(S1); Und um die Betrachtung der Optionen für Join-Operationen abzuschließen, sehen wir uns ein Beispiel an, das die Operation einer vollständigen Outer-Join-Operation veranschaulicht. Wir führen zwei Relationen r ein1(S1) und r2(S2) und die Join-Bedingung. Lassen r1(S1)
r2(S2):
Und lassen Sie die Bedingung der Verbindung von Relationen r1(S1) und r2(S2) ist: P = (b1 = b2), wie in den vorherigen Beispielen. Dann das Ergebnis der vollständigen Outer-Join-Operation der Beziehungen r1(S1) und r2(S2) durch die Bedingung P = (b1 = b2) ergibt sich folgende Tabelle: r1(S1) ↔x P r2(S2):
Wir sehen also, dass die vollständige Outer-Join-Operation eindeutig ihre Definition als Vereinigung der Ergebnisse von linken und rechten Outer-Join-Operationen rechtfertigt. Die resultierende Relation der Inner-Join-Operation wird durch gleichzeitig nicht verknüpfbare Tupel ergänzt, da die linke (erste, r1(S1)) und rechts (zweite, r2(S2)) des ursprünglichen Beziehungsoperanden. 5. Derivatgeschäfte Wir haben also verschiedene Varianten von Join-Operationen betrachtet, nämlich die Operationen Inner Join, Left, Right und Full Outer Join, die Ableitungen der acht ursprünglichen Operationen der relationalen Algebra sind: unäre Operationen der Auswahl, Projektion, Umbenennung und binäre Operationen von Vereinigung, Schnittmenge, Differenz, kartesisches Produkt und natürliche Verbindung. Aber auch unter diesen ursprünglichen Operationen gibt es Beispiele für abgeleitete Operationen. 1. Zum Beispiel Betrieb Kreuzungen zwei Verhältnisse ist eine Ableitung der Operation der Differenz der gleichen zwei Verhältnisse. Zeigen wir es. Die Schnittoperation kann durch die folgende Formel ausgedrückt werden: r1(S)∩r2(S) = r1 \r1 \r2 oder, was das gleiche Ergebnis liefert: r1(S)∩r2(S) = r2 \r2 \r1; 2. Ein weiteres Beispiel einer aus acht ursprünglichen Operationen abgeleiteten Basisoperation ist die Operation natürliche Verbindung. In seiner allgemeinsten Form wird diese Operation von der binären Operation des kartesischen Produkts und den unären Operationen des Auswählens, Projizierens und Umbenennens von Attributen abgeleitet. Die Inner Join-Operation ist jedoch wiederum eine abgeleitete Operation derselben Operation des kartesischen Beziehungsprodukts. Betrachten Sie daher das folgende Beispiel, um zu zeigen, dass die natürliche Join-Operation eine abgeleitete Operation ist. Vergleichen wir die vorherigen Beispiele für natürliche und innere Verknüpfungsoperationen. Gegeben seien zwei Relationen r1(S1) und r2(S2), die als Operanden fungieren. Sie sind gleich: r1(S1):
r2(S2):
Wie wir bereits früher erhalten haben, wird das Ergebnis der natürlichen Verknüpfungsoperation dieser Beziehungen eine Tabelle der folgenden Form sein: r3(S3) ≔ r1(S1)xr2(S2):
Und das Ergebnis der inneren Verknüpfung derselben Relationen r1(S1) und r2(S2) durch die Bedingung P = (b1 = b2) ergibt sich folgende Tabelle: r4(S4) ≔ r1(S1)X P r2(S2):
Vergleichen wir diese beiden Ergebnisse, die daraus resultierenden neuen Beziehungen r3(S3) und r4(S4). Es ist klar, dass die natürliche Join-Operation durch die innere Join-Operation ausgedrückt wird, aber vor allem mit einer speziellen Join-Bedingung. Lassen Sie uns eine mathematische Formel schreiben, die die Aktion der natürlichen Join-Operation als Ableitung der inneren Join-Operation beschreibt. r1(S1)xr2(S2) = {ρ<ϕ1> r1 x E ρ< ϕ2>r2}[S1 ∪S2], wo E - Konnektivitätszustand Tupel; E= ∀a ∈S1 ∩S2 [IstNull(b1) & IsNull(2) ∪b1 = b2]; b1 = φ1 (Name(a)), b2 = φ2 (nennen Sie ein)); Hier ist einer von Funktionen umbenennen ϕ1 identisch ist, und eine andere Umbenennungsfunktion (nämlich ϕ2) benennt die Attribute um, an denen sich unsere Schemas überschneiden. Die Konnektivitätsbedingung E für Tupel ist in allgemeiner Form geschrieben, wobei das mögliche Auftreten von Null-Werten berücksichtigt wird, da die Inner-Join-Operation (wie oben erwähnt) eine Ableitungsoperation aus dem kartesischen Produkt zweier Relationen und der unären Auswahloperation ist . 6. Ausdrücke der relationalen Algebra Lassen Sie uns zeigen, wie die zuvor betrachteten Ausdrücke und Operationen der relationalen Algebra im praktischen Betrieb verschiedener Datenbanken verwendet werden können. Nehmen wir zum Beispiel an, wir hätten ein Fragment einer kommerziellen Datenbank zur Verfügung: Lieferanten (Lieferantencode, Anbietername, Anbieterstadt); Werkzeug (Werkzeugcode, Werkzeugname,...); Lieferungen (Lieferantencode, Teilecode); Die unterstrichenen Attributnamen[1] sind Schlüsselattribute (d. h. identifizierende) Attribute, jedes in seiner eigenen Beziehung. Angenommen, wir als Entwickler dieser Datenbank und Verwahrer von Informationen zu diesem Thema werden angewiesen, die Namen von Lieferanten (Name des Lieferanten) und ihren Standort (Stadt des Lieferanten) zu erhalten, falls diese Lieferanten keine Werkzeuge liefern einen Gattungsnamen "Zangen". Um in unserer möglicherweise sehr großen Datenbank alle Lieferanten zu ermitteln, die diese Anforderung erfüllen, schreiben wir ein paar Ausdrücke der relationalen Algebra. 1. Wir bilden eine natürliche Verbindung der Beziehungen "Lieferanten" und "Lieferungen", um mit jedem Lieferanten die Codes der von ihm gelieferten Teile abzugleichen. Die neue Beziehung – das Ergebnis der Anwendung der Operation der natürlichen Verknüpfung – bezeichnen wir zur Vereinfachung der weiteren Anwendung mit r1. Lieferanten x Lieferungen ≔ r1 (Lieferantencode, Lieferantenname, Lieferantenstadt, In Klammern haben wir alle Attribute der Relationen aufgeführt, die an dieser natürlichen Verknüpfungsoperation beteiligt sind. Wir können sehen, dass das Attribut „Vendor ID“ dupliziert wird, aber im Transaktionszusammenfassungsdatensatz sollte jeder Attributname nur einmal erscheinen, d. h.: Lieferanten x Lieferungen ≔ r1 (Lieferantencode, Lieferantenname, Lieferantenstadt, Instrumentencode); 2. Wieder bilden wir eine natürliche Verbindung, nur diesmal die in Absatz XNUMX erhaltene Beziehung und die Beziehung Instrumente. Wir tun dies, um den Namen dieses Werkzeugs mit jedem im vorherigen Absatz erhaltenen Werkzeugcode abzugleichen. r1 x Werkzeuge [Werkzeugcode, Werkzeugname] ≔ r2 (Lieferantencode, Lieferantenname, Lieferantenstadt, Das resultierende Ergebnis wird mit r bezeichnet2, werden doppelte Attribute ausgeschlossen: r1 x Werkzeuge [Werkzeugcode, Werkzeugname] ≔ r2 (Lieferantencode, Lieferantenname, Lieferantenstadt, Instrumentencode, Instrumentenname); Beachten Sie, dass wir nur zwei Attribute aus der Tools-Beziehung übernehmen: „Tool-Code“ und „Tool-Name“. Dazu verwenden wir, wie aus der Notation der Relation r ersichtlich ist2, wendete die unäre Projektionsoperation an: Tools [Toolcode, Toolname], d.h. wenn die Relation Tools als Tabelle dargestellt würde, wären das Ergebnis dieser Projektionsoperation die ersten beiden Spalten mit den Überschriften „Toolcode“ und „Tool Namen" bzw. Es ist interessant festzustellen, dass die ersten beiden Schritte, die wir bereits betrachtet haben, ziemlich allgemein sind, das heißt, sie können verwendet werden, um beliebige andere Anforderungen umzusetzen. Aber die nächsten beiden Punkte stellen wiederum konkrete Schritte dar, um die konkrete Aufgabenstellung zu erreichen. 3. Schreiben Sie eine unäre Auswahloperation gemäß der Bedingung <"Werkzeugname" = "Zange"> in Bezug auf das Verhältnis r2im vorigen Absatz erhalten. Und wir wiederum wenden die unäre Projektionsoperation [Supplier Code, Supplier Name, Supplier City] auf das Ergebnis dieser Operation an, um alle Werte dieser Attribute zu erhalten, da wir diese Informationen basierend auf erhalten müssen bestellen. Also: (σ<Werkzeugname = "Zange"> r2) [Lieferantencode, Lieferantenname, Lieferantenstadt] ≔ r3 (Lieferantencode, Lieferantenname, Lieferantenstadt, Werkzeugcode, Werkzeugname). Im resultierenden Verhältnis, bezeichnet mit r3, stellten sich heraus, dass nur diese Lieferanten (mit all ihren Identifikationsdaten) Werkzeuge mit der Gattungsbezeichnung "Zangen" lieferten. Aufgrund der Bestellung müssen wir jedoch diejenigen Lieferanten herausgreifen, die im Gegenteil solche Werkzeuge nicht liefern. Lassen Sie uns daher zum nächsten Schritt unseres Algorithmus übergehen und den letzten Ausdruck der relationalen Algebra aufschreiben, der uns die gesuchten Informationen liefert. 4. Lassen Sie uns zunächst den Unterschied zwischen dem Verhältnis „Lieferanten“ und dem Verhältnis r machen3, und nach Anwendung dieser binären Operation wenden wir die unäre Projektionsoperation auf die Attribute „Supplier Name“ und „Supplier City“ an. (Lieferanten\r3) [Name des Lieferanten, Stadt des Lieferanten] ≔ r4 (Lieferantencode, Lieferantenname, Lieferantenstadt); Das Ergebnis wird mit r bezeichnet4, umfasste diese Relation nur die Tupel der ursprünglichen „Suppliers“-Relation, die der Bedingung unserer Bestellung entsprechen. Wir haben also gezeigt, wie Sie mit Ausdrücken und Operationen der relationalen Algebra alle Arten von Aktionen mit beliebigen Datenbanken ausführen, verschiedene Befehle ausführen usw. Vorlesung Nr. 6. SQL-Sprache Lassen Sie uns zunächst einen kleinen historischen Hintergrund geben. Die SQL-Sprache, die für die Interaktion mit Datenbanken entwickelt wurde, erschien Mitte der 1970er Jahre. (erste Veröffentlichungen stammen aus dem Jahr 1974) und wurde von IBM als Teil eines experimentellen relationalen Datenbankverwaltungssystemprojekts entwickelt. Der ursprüngliche Name der Sprache lautet SEQUEL (Structured English Query Language) - spiegelte das Wesen dieser Sprache nur teilweise wider. Ursprünglich, unmittelbar nach ihrer Erfindung und während der Hauptbetriebszeit der SQL-Sprache, war ihr Name eine Abkürzung für den Ausdruck Structured Query Language, der mit "Structured Query Language" übersetzt wird. Natürlich konzentrierte sich die Sprache hauptsächlich auf die Formulierung von Anfragen an relationale Datenbanken, die für Benutzer bequem und verständlich sind. Tatsächlich war es jedoch fast von Anfang an eine vollständige Datenbanksprache, die zusätzlich zu den Mitteln zur Formulierung von Abfragen und zur Manipulation von Datenbanken die folgenden Funktionen bereitstellte: 1) Mittel zum Definieren und Manipulieren des Datenbankschemas; 2) Mittel zum Definieren von Integritätsbeschränkungen und Auslösern (die später erwähnt werden); 3) Mittel zum Definieren von Datenbankansichten; 4) Mittel zum Definieren von physikalischen Schichtstrukturen, die die effiziente Ausführung von Anforderungen unterstützen; 5) Mittel zum Autorisieren des Zugriffs auf Beziehungen und ihre Felder. Der Sprache fehlte die Möglichkeit, den Zugriff auf Datenbankobjekte von Seiten paralleler Transaktionen explizit zu synchronisieren: Von Anfang an wurde davon ausgegangen, dass die notwendige Synchronisation implizit vom Datenbankmanagementsystem durchgeführt wird. Aktuell ist SQL keine Abkürzung mehr, sondern der Name einer eigenständigen Sprache. Außerdem ist die strukturierte Abfragesprache derzeit in allen kommerziellen relationalen Datenbankverwaltungssystemen und in fast allen DBMS implementiert, die ursprünglich nicht auf einem relationalen Ansatz basierten. Alle produzierenden Unternehmen behaupten, dass ihre Implementierung dem SQL-Standard entspricht, und tatsächlich sind die implementierten Dialekte der Structured Query Language sehr ähnlich. Dies wurde nicht sofort erreicht. Ein Merkmal der meisten modernen kommerziellen Datenbankverwaltungssysteme, das es schwierig macht, bestehende SQL-Dialekte zu vergleichen, ist das Fehlen einer einheitlichen Beschreibung der Sprache. Typischerweise ist die Beschreibung über verschiedene Handbücher verstreut und mit einer Beschreibung systemspezifischer Sprachmerkmale vermischt, die nicht direkt mit der strukturierten Abfragesprache in Verbindung stehen. Dennoch kann gesagt werden, dass der grundlegende Satz von SQL-Anweisungen, der Anweisungen zur Bestimmung des Datenbankschemas, zum Abrufen und Manipulieren von Daten, zum Autorisieren des Datenzugriffs, zur Unterstützung der Einbettung von SQL in Programmiersprachen und zu dynamischen SQL-Anweisungen umfasst, in gut etabliert ist kommerzielle Implementierungen und entspricht mehr oder weniger dem Standard. Im Laufe der Zeit und der Arbeit an der Structured Query Language war es möglich, einen Standard für eine klare Standardisierung der Syntax und Semantik von Datenabrufanweisungen, Datenmanipulation und Behebung von Einschränkungen der Datenbankintegrität zu erreichen. Es wurden Mittel zum Definieren der Primär- und Fremdschlüssel von Beziehungen und sogenannten Integritätsprüfungsbeschränkungen spezifiziert, die eine Teilmenge von sofort geprüften SQL-Integritätsbeschränkungen sind. Die Werkzeuge zur Definition von Fremdschlüsseln machen es einfach, die Anforderungen an die sogenannte referentielle Integrität von Datenbanken (auf die wir später noch zu sprechen kommen) zu formulieren. Diese bei relationalen Datenbanken übliche Anforderung könnte auch auf Basis des allgemeinen Mechanismus der SQL-Integritätsbeschränkungen formuliert werden, jedoch ist die Formulierung auf Basis des Fremdschlüsselkonzepts einfacher und verständlicher. Unter Berücksichtigung all dessen ist die strukturierte Abfragesprache derzeit also nicht nur der Name einer Sprache, sondern der Name einer ganzen Klasse von Sprachen, da trotz bestehender Standards verschiedene Dialekte der strukturierten Abfragesprache implementiert sind in verschiedenen Datenbankverwaltungssystemen, die natürlich eine gemeinsame Basis haben. 1. Die Select-Anweisung ist die grundlegende Anweisung der Structured Query Language Den zentralen Platz in der strukturierten SQL-Abfragesprache nimmt die Select-Anweisung ein, die die am meisten nachgefragte Operation bei der Arbeit mit Datenbanken implementiert – Abfragen. Die Select-Anweisung wertet sowohl relationale als auch pseudorelationale Algebra-Ausdrücke aus. In diesem Kurs betrachten wir nur die Implementierung der bereits behandelten unären und binären Operationen der relationalen Algebra sowie die Implementierung von Abfragen mit den sogenannten Unterabfragen. Übrigens ist zu beachten, dass bei der Arbeit mit relationalen Algebra-Operationen doppelte Tupel in den resultierenden Relationen auftreten können. In den Regeln der strukturierten Abfragesprache gibt es kein striktes Verbot des Vorhandenseins doppelter Zeilen in Relationen (anders als in der gewöhnlichen relationalen Algebra), sodass es nicht erforderlich ist, Duplikate aus dem Ergebnis auszuschließen. Schauen wir uns also die Grundstruktur der Select-Anweisung an. Es ist ziemlich einfach und enthält die folgenden obligatorischen Standardphrasen: Wählen... Von ... Wo... ; Anstelle der Auslassungspunkte in jeder Zeile sollten Relationen, Attribute und Bedingungen einer bestimmten Datenbank und Aufgaben dafür stehen. Im allgemeinsten Fall sollte die grundlegende Select-Struktur wie folgt aussehen: Auswählen einige Attribute auswählen Aus aus einer solchen Beziehung Wo mit solchen und solchen Bedingungen zum Sampling von Tupeln Wir wählen also Attribute aus dem Beziehungsschema (Überschriften einiger Spalten) aus, geben an, aus welchen Beziehungen (und wie Sie sehen, kann es mehrere geben) treffen wir unsere Auswahl und schließlich brechen wir auf der Grundlage der Bedingungen ab unsere Wahl auf bestimmte Tupel. Es ist wichtig zu beachten, dass Attributreferenzen unter Verwendung ihrer Namen erstellt werden. Somit wird das Folgende erhalten Arbeitsalgorithmus diese grundlegende Select-Anweisung: 1) die Bedingungen zum Auswählen von Tupeln aus der Relation werden gespeichert; 2) es wird geprüft, welche Tupel die angegebenen Eigenschaften erfüllen. Solche Tupel werden gespeichert; 3) Die in der ersten Zeile des Grundaufbaus der Select-Anweisung aufgeführten Attribute mit ihren Werten werden ausgegeben. (Sprechen wir von der tabellarischen Form der Beziehung, dann werden die Spalten der Tabelle angezeigt, deren Überschriften als notwendige Attribute aufgeführt wurden; natürlich werden die Spalten nicht vollständig angezeigt, sondern jeweils nur diese Tupel die die genannten Bedingungen erfüllten, bleiben bestehen.) Betrachten wir ein Beispiel. Gegeben sei die folgende Beziehung r1, als Fragment einer Buchhandlungsdatenbank:
Angenommen, wir erhalten auch den folgenden Ausdruck mit der Select-Anweisung: Auswählen Titel des Buches, Autor des Buches Aus r1 Wo Buchpreis > 200; Das Ergebnis dieses Operators ist das folgende Tupelfragment: (Handy, S. King). (Im Folgenden betrachten wir viele Beispiele für Abfrageimplementierungen, die diese Grundstruktur verwenden, und untersuchen ihre Anwendung im Detail.) 2. Unäre Operationen in der strukturierten Abfragesprache In diesem Abschnitt betrachten wir, wie die bereits bekannten unären Operationen Auswahl, Projektion und Umbenennung in der strukturierten Abfragesprache mit dem Select-Operator implementiert werden. Es ist wichtig anzumerken, dass, wenn wir früher nur mit einzelnen Operationen arbeiten konnten, es uns sogar eine einzelne Select-Anweisung im allgemeinen Fall erlaubt, einen ganzen relationalen Algebra-Ausdruck zu definieren, und nicht nur eine einzelne Operation. Fahren wir also direkt mit der Analyse der Darstellung unärer Operationen in der Sprache strukturierter Abfragen fort. 1. Probenahmevorgang. Die Auswahloperation in SQL wird durch die Select-Anweisung der folgenden Form implementiert: Auswählen alle Attribute Aus Beziehungsname Wo Auswahlbedingung; Anstatt "alle Attribute" zu schreiben, können Sie hier das "*"-Zeichen verwenden. In der Theorie der strukturierten Abfragesprache bedeutet dieses Symbol, dass alle Attribute aus dem Beziehungsschema ausgewählt werden. Die Auswahlbedingung wird hier (und in allen anderen Implementierungen von Operationen) als logischer Ausdruck mit Standardkonnektiven not (not), and (and), or (or) geschrieben. Beziehungsattribute werden mit ihren Namen bezeichnet. Betrachten Sie ein Beispiel. Lassen Sie uns das folgende Beziehungsschema definieren: Akademischeleistung (Notenbuchnummer, Semester, Fachcode, Bewertung, Datum); Dabei bilden, wie bereits erwähnt, die unterstrichenen Attribute den Beziehungsschlüssel. Lassen Sie uns eine Select-Anweisung der folgenden Form verfassen, die die unäre Auswahloperation implementiert: Auswählen * Von der schulischen Leistung Wo Notenbuch # = 100 und Semester = 6; Es ist klar, dass die Maschine als Ergebnis dieser Aussage den Fortschritt eines Studenten mit der Rekordnummer einhundert für das sechste Semester anzeigen wird. 2. Projektionsvorgang. Die Projektionsoperation in der strukturierten Abfragesprache ist sogar noch einfacher zu implementieren als die Abrufoperation. Denken Sie daran, dass beim Anwenden der Projektionsoperation keine Zeilen ausgewählt werden (wie beim Anwenden der Auswahloperation), sondern Spalten. Daher reicht es aus, die Überschriften der erforderlichen Spalten (d. h. Attributnamen) aufzulisten, ohne irgendwelche irrelevanten Bedingungen anzugeben. Insgesamt erhalten wir einen Operator der folgenden Form: Auswählen Liste der Attributnamen Aus Beziehungsname; Nach Anwendung dieser Anweisung gibt die Maschine die Spalten der Beziehungstabelle zurück, deren Namen in der ersten Zeile dieser Select-Anweisung angegeben wurden. Wie bereits erwähnt, ist es nicht erforderlich, doppelte Zeilen und Spalten aus der resultierenden Beziehung auszuschließen. Aber wenn es in einem Auftrag oder einer Aufgabe erforderlich ist, Duplikate zu eliminieren, sollten Sie eine spezielle Option der strukturierten Abfragesprache verwenden - deutlich. Diese Option legt die automatische Eliminierung doppelter Tupel aus der Relation fest. Wenn diese Option angewendet wird, sieht die Select-Anweisung wie folgt aus: Auswählen eindeutige Liste von Attributnamen Aus Beziehungsname; In SQL gibt es eine spezielle Notation für optionale Elemente von Ausdrücken – eckige Klammern [...]. Daher sieht die Projektionsoperation in ihrer allgemeinsten Form wie folgt aus: Auswählen [eindeutige] Liste von Attributnamen Aus Beziehungsname; Wenn das Ergebnis der Anwendung der Operation jedoch garantiert keine Duplikate enthält oder Duplikate noch zulässig sind, dann ist die Option deutlich es ist besser, nichts anzugeben, um den Datensatz nicht zu überladen, d. h. aus Gründen der Bedienerleistung. Betrachten wir ein Beispiel, das die Möglichkeit eines XNUMX%igen Vertrauens in Abwesenheit von Duplikaten veranschaulicht. Gegeben sei das uns bereits bekannte Beziehungsschema: Akademischeleistung (Notenbuchnummer, Semester, Fachcode, Bewertung, Datum). Gegeben sei die folgende Select-Anweisung: Auswählen Notenbuchnummer, Semester, Fachcode Aus Akademischeleistung; Hier ist leicht zu erkennen, dass die drei vom Operator zurückgegebenen Attribute den Schlüssel der Relation bilden. Deshalb die Möglichkeit deutlich wird überflüssig, da es garantiert keine Duplikate gibt. Dies ergibt sich aus einer Anforderung an Schlüssel, die als Unique Constraint bezeichnet wird. Wir werden diese Eigenschaft später genauer betrachten, aber wenn das Attribut ein Schlüssel ist, dann gibt es keine Duplikate darin. 3. Vorgang umbenennen. Die Operation zum Umbenennen von Attributen in der strukturierten Abfragesprache ist recht einfach. Es wird nämlich in der Realität durch den folgenden Algorithmus verkörpert: 1) in der Liste der Attributnamen der Select-Phrase sind die Attribute aufgeführt, die umbenannt werden müssen; 2) das spezielle Schlüsselwort as wird zu jedem spezifizierten Attribut hinzugefügt; 3) Nach jedem Vorkommen des Wortes as wird der Name des entsprechenden Attributs angegeben, zu dem der ursprüngliche Name geändert werden muss. Unter Berücksichtigung all dessen sieht die Anweisung, die der Operation zum Umbenennen von Attributen entspricht, folgendermaßen aus: Auswählen Attributname 1 als neuer Attributname 1,... Aus Beziehungsname; Lassen Sie uns anhand eines Beispiels zeigen, wie dieser Operator funktioniert. Gegeben sei das uns bereits bekannte Beziehungsschema: Akademischeleistung (Notenbuchnummer, Semester, Fachcode,Bewertung, Datum); Lassen Sie uns einen Befehl geben, die Namen einiger Attribute zu ändern, und zwar sollte anstelle von "Kontobuchnummer" "Kontonummer" und anstelle von "Punktzahl" - "Punktzahl" stehen. Schreiben wir auf, wie die Select-Anweisung aussehen wird, die diese Umbenennungsoperation implementiert: Auswählen Rekordbuch als Rekordnummer, Semester, Fachcode, Note als Punktzahl, Datum Aus Akademischeleistung; Somit ist das Ergebnis der Anwendung dieses Operators ein neues Beziehungsschema, das sich von dem ursprünglichen Beziehungsschema "Leistung" durch die Namen von zwei Attributen unterscheidet. 3. Binäre Operationen in der Sprache der strukturierten Abfragen Wie unäre Operationen haben auch binäre Operationen ihre eigene Implementierung in der strukturierten Abfragesprache oder SQL. Betrachten wir also die Implementierung der binären Operationen, die wir bereits durchlaufen haben, in dieser Sprache, nämlich die Operationen Vereinigung, Schnitt, Differenz, kartesisches Produkt, natürliche Verknüpfung, innere und linke, rechte, vollständige äußere Verknüpfung. 1. Gewerkschaftsoperation. Um die Operation des Kombinierens zweier Relationen zu implementieren, ist es notwendig, zwei Select-Operatoren gleichzeitig zu verwenden, von denen jeder einem der ursprünglichen Relationen-Operanden entspricht. Und auf diese beiden grundlegenden Select-Anweisungen muss eine spezielle Operation angewendet werden Union. Lassen Sie uns unter Berücksichtigung all dessen aufschreiben, wie die Union-Operation aussehen wird, wenn die Semantik der strukturierten Abfragesprache verwendet wird: Auswählen Attributnamen von Relation 1 auflisten Aus Beziehungsname 1 Union Auswählen Attributnamen von Relation 2 auflisten Aus Beziehungsname 2; Es ist wichtig zu beachten, dass die Listen der Attributnamen der beiden zu verbindenden Beziehungen auf Attribute kompatibler Typen verweisen und in konsistenter Reihenfolge aufgelistet sein müssen. Wenn diese Voraussetzung nicht erfüllt ist, kann Ihre Anfrage nicht erfüllt werden und der Computer zeigt eine Fehlermeldung an. Interessant ist jedoch, dass die Attributnamen selbst in diesen Beziehungen unterschiedlich sein können. In diesem Fall werden der resultierenden Relation die in der ersten Select-Anweisung angegebenen Attributnamen zugewiesen. Sie müssen auch wissen, dass die Verwendung der Union-Operation automatisch alle doppelten Tupel aus der resultierenden Beziehung ausschließt. Wenn Sie also alle doppelten Zeilen im Endergebnis beibehalten möchten, sollten Sie anstelle der Union-Operation eine Modifikation dieser Operation verwenden - die Operation Union all. In diesem Fall sieht die Operation zum Kombinieren zweier Relationen folgendermaßen aus: Auswählen Attributnamen von Relation 1 auflisten Aus Beziehungsname 1 Union all Auswählen Attributnamen von Relation 2 auflisten Aus Beziehungsname 2; In diesem Fall werden doppelte Tupel nicht aus der resultierenden Relation entfernt. Unter Verwendung der zuvor erwähnten Notation für optionale Elemente und Optionen in Select-Anweisungen schreiben wir die allgemeinste Form der Verknüpfung zweier Relationen in der strukturierten Abfragesprache: Auswählen Attributnamen von Relation 1 auflisten Aus Beziehungsname 1 Vereinigung [Alle] Auswählen Attributnamen von Relation 2 auflisten Aus Beziehungsname 2; 2. Kreuzungsbetrieb. Die Operation der Schnittmenge und die Operation der Differenz zweier Relationen in der strukturierten Abfragesprache werden auf ähnliche Weise implementiert (wir betrachten die einfachste Darstellungsmethode, denn je einfacher die Methode, desto wirtschaftlicher, relevanter und daher am meisten gefragt). Wir werden also analysieren, wie die Schnittpunktoperation mit implementiert wird ключей. Diese Methode beinhaltet die Teilnahme von zwei Select-Konstrukten, aber sie sind nicht gleich (wie in der Darstellung der Vereinigungsoperation), eines davon ist sozusagen eine "Unterkonstruktion", ein "Unterzyklus". Ein solcher Operator wird normalerweise aufgerufen Unterabfrage. Nehmen wir also an, wir haben zwei Beziehungsschemata (R1 und R2), grob wie folgt definiert: R1 (Schlüssel,...) und R2 (Schlüssel,...); Bei der Aufzeichnung dieses Vorgangs verwenden wir auch die spezielle Option in, was wörtlich „in“ oder (wie in diesem speziellen Fall) „enthalten in“ bedeutet. Unter Berücksichtigung all dessen wird die Operation der Schnittmenge zweier Relationen unter Verwendung der strukturierten Abfragesprache wie folgt geschrieben: Auswählen * Aus R1 Wo eintippen (Auswählen ключ Von R2); Wir sehen also, dass die Unterabfrage in diesem Fall der Operator in Klammern ist. Diese Unterabfrage gibt in unserem Fall eine Liste von Schlüsselwerten der Relation R zurück2. Und wie aus unserer Notation der Operatoren hervorgeht, fallen aus der Analyse der Auswahlbedingung nur die Tupel der Relation R in die resultierende Relation1, deren Schlüssel in der Liste der Schlüssel der Relation R enthalten ist2. Das heißt, in der letzten Relation bleiben, wenn wir uns an die Definition der Schnittmenge zweier Relationen erinnern, nur die Tupel übrig, die zu beiden Relationen gehören. 3. Differenzoperation. Wie bereits erwähnt, wird die unäre Operation der Differenz zweier Relationen ähnlich wie die Schnittoperation implementiert. Hier kommt neben der Hauptabfrage mit dem Select-Operator eine zweite, unterstützende Abfrage zum Einsatz – die sogenannte Subquery. Aber anders als bei der Implementierung der vorherigen Operation ist es beim Implementieren der Differenzoperation notwendig, ein anderes Schlüsselwort zu verwenden, nämlich nicht in, was in wörtlicher Übersetzung "nicht in" oder (wie es in unserem Fall angemessen ist, zu übersetzen) - "ist nicht enthalten in" bedeutet. Also haben wir, wie im vorigen Beispiel, zwei Beziehungsschemata (R1 und R2), ungefähr gegeben durch: R1 (Schlüssel,...) und R2 (Schlüssel,...); Wie Sie sehen, werden unter den Attributen dieser Relationen wiederum Schlüsselattribute gesetzt. Damit erhalten wir folgende Form zur Darstellung der Differenzoperation in der strukturierten Abfragesprache: Auswählen * Aus R1 Wo ключ nicht in (Auswählen ключ Aus R2); Also nur die Tupel der Relation R1, deren Schlüssel nicht in der Liste der Schlüssel der Relation R enthalten ist2. Betrachten wir die Notation wörtlich, so stellt sich wirklich heraus, dass aus der Relation R1 "subtrahiert" das Verhältnis R2. Daraus schließen wir, dass die Auswahlbedingung in diesem Operator richtig geschrieben ist (schließlich wird die Definition der Differenz zweier Relationen durchgeführt) und die Verwendung von Schlüsseln, wie im Fall der Implementierung der Schnittoperation, voll gerechtfertigt ist . Die zwei Verwendungen der "Schlüsselmethode", die wir gesehen haben, sind die häufigsten. Damit ist die Untersuchung der Verwendung von Schlüsseln bei der Konstruktion von Operatoren abgeschlossen, die Relationen darstellen. Alle verbleibenden binären Operationen der relationalen Algebra werden auf andere Weise geschrieben. 4. Kartesischer Produktbetrieb Wie wir uns aus den vorherigen Vorlesungen erinnern, wird das kartesische Produkt zweier Beziehungsoperanden als Menge aller möglichen Paare von benannten Werten von Tupeln auf Attributen zusammengesetzt. Daher wird in der Sprache für strukturierte Abfragen die kartesische Produktoperation unter Verwendung einer Kreuzverbindung implementiert, die durch das Schlüsselwort gekennzeichnet ist Cross Join, was wörtlich übersetzt "Cross Join" oder "Cross Join" bedeutet. Es gibt nur einen Select-Operator in der Struktur, der die kartesische Produktoperation in der Structured Query Language darstellt, und er hat die folgende Form: Auswählen * Aus R1 Cross Join R2 wo R1 und R2 - Namen der anfänglichen Relationen-Operanden. Möglichkeit Cross Join stellt sicher, dass die resultierende Relation alle Attribute enthält (alle, weil die erste Zeile des Operators das Zeichen „*“ hat), die allen Paaren von Relationstupeln R entsprechen1 und R2. Es ist sehr wichtig, sich an ein Merkmal der Implementierung der kartesischen Produktoperation zu erinnern. Dieses Merkmal ist eine Folge der Definition der binären Operation des kartesischen Produkts. Erinnere dich daran: r4(S4) = r1(S1)xr2(S2) = {t(S1 ∪S2) | t[S1] ∈ r1 &t(S2) ∈ r2}, S1 ∩S2= ∅; Wie aus der obigen Definition ersichtlich ist, werden Paare von Tupeln mit notwendigerweise sich nicht überschneidenden Beziehungsschemata gebildet. Daher wird beim Arbeiten in der strukturierten SQL-Abfragesprache ausnahmslos festgelegt, dass die anfänglichen Operandenbeziehungen keine übereinstimmenden Attributnamen haben sollten. Wenn diese Relationen aber immer noch die gleichen Namen haben, lässt sich die aktuelle Situation einfach mit der Attribut-Umbenennungsoperation auflösen, d. h. in solchen Fällen müssen Sie nur die Option verwenden as, was bereits erwähnt wurde. Betrachten wir ein Beispiel, in dem wir das kartesische Produkt zweier Beziehungen finden müssen, die einige der gleichen Attributnamen haben. Gegeben sind also die folgenden Beziehungen: R1 (A, B), R2 (B,C); Wir sehen, dass die R-Attribute1.B und R2.B haben die gleichen Namen. Vor diesem Hintergrund sieht die Select-Anweisung, die diese kartesische Produktoperation in der strukturierten Abfragesprache implementiert, folgendermaßen aus: Auswählen A, R1.B as B1, R2.B as B2,C Aus R1 Cross Join R2; Wenn Sie also die Umbenennungsoption als verwenden, hat die Maschine keine "Fragen" über die übereinstimmenden Namen der beiden ursprünglichen Operandenbeziehungen. 5. Inner Join-Operationen Auf den ersten Blick mag es seltsam erscheinen, dass wir die innere Join-Operation vor der natürlichen Join-Operation betrachten, denn als wir die binären Operationen durchgegangen sind, war alles umgekehrt. Durch die Analyse des Ausdrucks von Operationen in der strukturierten Abfragesprache kann man jedoch zu dem Schluss kommen, dass die natürliche Join-Operation ein Sonderfall der inneren Join-Operation ist. Deshalb ist es sinnvoll, diese Operationen in dieser Reihenfolge zu betrachten. Erinnern wir uns also zunächst an die Definition der Inner-Join-Operation, die wir zuvor durchgegangen sind: r1(S1)X P r2(S2) = σ (r1 xr2), st1 ∩ S2 = ∅. Für uns ist es bei dieser Definition besonders wichtig, dass die betrachteten Schemata der Beziehungsoperanden S1 und S2 dürfen sich nicht schneiden. Um die Inner-Join-Operation in der strukturierten Abfragesprache zu implementieren, gibt es eine spezielle Option innere Verbindung, was wörtlich aus dem Englischen als "inner join" oder "inner join" übersetzt wird. Die Select-Anweisung im Fall einer Inner-Join-Operation sieht folgendermaßen aus: Auswählen * Aus R1 innere Verbindung R2; Hier wie zuvor R1 und R2 - Namen der anfänglichen Relationen-Operanden. Bei der Implementierung dieser Operation dürfen sich die Schemata der Beziehungsoperanden nicht kreuzen. 6. Natürliche Join-Operation Wie wir bereits gesagt haben, ist die natürliche Join-Operation ein Sonderfall der inneren Join-Operation. Wieso den? Ja, denn während der Aktion eines natürlichen Joins werden die Tupel der ursprünglichen Operandenbeziehungen gemäß einer speziellen Bedingung verbunden. Nämlich durch die Bedingung der Gleichheit von Tupeln am Schnittpunkt von Beziehungsoperanden, während bei der Aktion der inneren Verknüpfungsoperation eine solche Situation nicht zugelassen werden könnte. Da die von uns betrachtete natürliche Join-Operation ein Spezialfall der inneren Join-Operation ist, wird dieselbe Option verwendet, um sie zu implementieren wie für die zuvor betrachtete Operation, d. h. die Option innere Verbindung. Aber da beim Kompilieren des Select-Operators für die natürliche Join-Operation auch die Bedingung der Gleichheit der Tupel der ursprünglichen Operandenbeziehungen am Schnittpunkt ihrer Schemata berücksichtigt werden muss, dann zusätzlich zu der angegebenen Option das Schlüsselwort wird angewandt on. Aus dem Englischen übersetzt bedeutet es wörtlich "auf", und in Bezug auf unsere Bedeutung kann es mit "vorbehaltlich" übersetzt werden. Die allgemeine Form der Select-Anweisung zum Ausführen einer natürlichen Join-Operation lautet wie folgt: Auswählen * Aus Beziehungsname 1 innere Verbindung Beziehungsname 2 on Tupel-Gleichheitsbedingung; Betrachten wir ein Beispiel. Gegeben seien zwei Relationen: R1 (A, B, C), R2 (B, C, D); Die natürliche Verknüpfungsoperation dieser Beziehungen kann mit dem folgenden Operator implementiert werden: Auswählen A, R1.B, R1.CD Aus R1 innere Verbindung R2 on R1.B=R2.B und R1.C=R2.C Als Ergebnis dieser Operation werden die in der ersten Zeile des Select-Operators angegebenen Attribute, die Tupeln entsprechen, die an der angegebenen Schnittmenge gleich sind, im Ergebnis angezeigt. Es sei darauf hingewiesen, dass wir uns hier nicht nur namentlich auf die gemeinsamen Attribute B und C beziehen. Dies muss nicht aus dem gleichen Grund geschehen wie bei der Implementierung der kartesischen Produktoperation, sondern weil sonst nicht klar ist, auf welche Relation sie sich beziehen. Interessanterweise ist die verwendete Formulierung der Join-Bedingung (R1.B=R2.B und R1.C=R2.C) geht davon aus, dass die gemeinsamen Attribute der verknüpften Nullwertbeziehungen nicht zulässig sind. Dies ist von Anfang an in das Structured Query Language-System eingebaut. 7. Left Outer Join-Operation Der SQL-Ausdruck der strukturierten Abfragesprache der Left-Outer-Join-Operation wird aus der Implementierung der natürlichen Join-Operation erhalten, indem das Schlüsselwort ersetzt wird innere pro Stichwort links außen. Daher wird diese Operation in der Sprache der strukturierten Abfragen wie folgt geschrieben: Auswählen * Aus Beziehungsname 1 linke äußere Verbindung Beziehungsname 2 on Tupel-Gleichheitsbedingung; 8. Right Outer Join-Operation Der Ausdruck für eine Right-Outer-Join-Operation in einer strukturierten Abfragesprache wird durch Ausführen einer natürlichen Join-Operation durch Ersetzen des Schlüsselworts erhalten innere pro Stichwort rechts außen. Wir erhalten also, dass in der strukturierten Abfragesprache SQL die Operation des rechten äußeren Joins wie folgt geschrieben wird: Auswählen * Aus Beziehungsname 1 rechter äußerer Join Beziehungsname 2 on Tupel-Gleichheitsbedingung; 9. Vollständiger Outer-Join-Vorgang Der Structured-Query-Language-Ausdruck für eine Full-Outer-Join-Operation wird wie in den beiden vorangegangenen Fällen aus dem Ausdruck für eine Natural-Join-Operation durch Ersetzen des Schlüsselworts erhalten innere pro Stichwort voll außen. Daher wird diese Operation in der strukturierten Abfragesprache wie folgt geschrieben: Auswählen * Aus Beziehungsname 1 vollständiger äußerer Join Beziehungsname 2 on Tupel-Gleichheitsbedingung; Es ist sehr praktisch, dass diese Optionen in die Semantik der strukturierten Abfragesprache SQL eingebaut sind, da sonst jeder Programmierer sie unabhängig ausgeben und in jede neue Datenbank eingeben müsste. 4. Verwenden von Unterabfragen Wie aus dem behandelten Material hervorgeht, ist das Konzept der "Unterabfrage" in der strukturierten Abfragesprache ein grundlegendes Konzept und ziemlich weit verbreitet (manchmal werden sie übrigens auch als SQL-Abfragen bezeichnet. Tatsächlich ist die Praxis des Programmierens und Die Arbeit mit Datenbanken zeigt, dass die Zusammenstellung eines Systems von Unterabfragen zur Lösung verschiedener verwandter Aufgaben eine Aktivität ist, die im Vergleich zu einigen anderen Methoden der Arbeit mit strukturierten Informationen viel lohnender ist. Betrachten wir daher ein Beispiel, um die Aktionen mit Unterabfragen besser zu verstehen, ihre Zusammenstellung und verwenden. Es sei das folgende Fragment einer bestimmten Datenbank, die in jeder Bildungseinrichtung verwendet werden kann: Artikel (Produktcode, Artikelname); Studenten (Rekordbuchnummer, Vollständiger Name); Sitzung (Fachcode, Notenbuchnummer, Klasse); Lassen Sie uns eine SQL-Abfrage formulieren, die eine Anweisung zurückgibt, die die Notenbuchnummer, den Nachnamen und die Initialen des Schülers sowie die Note für das Fach "Datenbanken" angibt. Universitäten müssen solche Informationen immer und zeitnah erhalten, daher ist die folgende Abfrage vielleicht die beliebteste Programmiereinheit, die solche Datenbanken verwendet. Nehmen wir der Einfachheit halber zusätzlich an, dass die Attribute "Last Name", "First Name" und "Patronymic" keine Nullwerte zulassen und nicht leer sind. Diese Anforderung ist durchaus verständlich und natürlich, da die ersten Daten für einen neuen Studenten, die in die Datenbank einer Bildungseinrichtung eingegeben werden, die Daten zu seinem Nachnamen, Vornamen und Vatersnamen sind. Und es versteht sich von selbst, dass es in einer solchen Datenbank keinen Eintrag geben kann, der Daten über einen Studenten enthält, dessen Name aber gleichzeitig unbekannt ist. Beachten Sie, dass das Attribut „Elementname“ des Beziehungsschemas „Elemente“ ein Schlüssel ist, sodass alle Elementnamen eindeutig sind, wie aus der Definition hervorgeht (dazu später mehr). Dies ist auch verständlich, ohne die Darstellung der Tonart zu erläutern, da alle Fächer, die in einer Bildungseinrichtung unterrichtet werden, unterschiedliche Namen haben und haben müssen. Bevor wir nun mit dem Kompilieren des Textes des Operators selbst beginnen, werden wir zwei Funktionen vorstellen, die uns im weiteren Verlauf nützlich sein werden. Zuerst brauchen wir die Funktion Trim, wird Trim ("string") geschrieben, das heißt, das Argument dieser Funktion ist ein String. Was macht diese Funktion? Sie geben das Argument selbst ohne Leerzeichen am Anfang und am Ende dieser Zeile zurück, d.h. diese Funktion wird zum Beispiel in den Fällen: Trim ("Bogucharnikov") oder Trim ("Maksimenko") verwendet, wenn nach oder vor Argumente stehen ein paar zusätzliche Leerzeichen wert. Und zweitens ist auch die Left-Funktion zu betrachten, die Left (String, Zahl) geschrieben wird, also eine Funktion mit bereits zwei Argumenten, von denen eines nach wie vor ein String ist. Sein zweites Argument ist eine Zahl, es gibt an, wie viele Zeichen von der linken Seite des Strings im Ergebnis ausgegeben werden sollen. Zum Beispiel das Ergebnis der Operation: Links ("Mikhail, 1") + "." + Links ("Sinowjewitsch, 1") werden die Initialen "M.Z." Um die Initialen der Studenten anzuzeigen, verwenden wir diese Funktion in unserer Abfrage. Fangen wir also an, die gewünschte Abfrage zu kompilieren. Machen wir zunächst eine kleine Hilfsabfrage, die wir dann in der Hauptabfrage verwenden: Auswählen Notenbuchnummer, Note Aus Sitzung Wo Artikelcode = (Auswählen Produktcode Aus Objekte Wo Artikelname = "Datenbanken") as "Schätzungen" Datenbanken "; Die Verwendung der Option als hier bedeutet, dass wir diese Abfrage mit dem Alias "Datenbankschätzungen" versehen haben. Wir haben dies getan, um die weitere Arbeit mit dieser Anfrage zu erleichtern. Als nächstes in dieser Abfrage eine Unterabfrage: Auswählen Produktcode Aus Objekte Wo Artikelname = "Datenbanken"; können Sie aus der Relation "Session" diejenigen Tupel auswählen, die sich auf das betrachtete Thema beziehen, also auf Datenbanken. Interessanterweise kann diese innere Unterabfrage nur einen Wert zurückgeben, da das Attribut „Item Name“ der Schlüssel der „Items“-Beziehung ist, d. h. alle seine Werte sind eindeutig. Und die gesamte Abfrage "Ergebnisse "Datenbank" ermöglicht es Ihnen, aus der "Sitzung"-Beziehungsdaten über diejenigen Studenten (ihre Notenbuchnummern und Noten) auszuwählen, die die in der Unterabfrage angegebene Bedingung erfüllen, d.h. Informationen über das Fach namens "Datenbank" . Jetzt stellen wir die Hauptanfrage unter Verwendung bereits erhaltener Ergebnisse. Auswählen Studenten. Rekordbuchnummer, Trim (Nachname) + " " + Links (Name, 1) + "." + Links (Patronym, 1) + "."as Vollständiger Name, Schätzungen "Datenbanken". Klasse Aus Studierende innere Verbindung ( Auswählen Notenbuchnummer, Note Aus Sitzung Wo Artikelcode = (Auswählen Produktcode Aus Objekte Wo Artikelname = "Datenbanken") ) wie "Schätzungen" Datenbanken ". on Studenten. Notenbuch # = "Datenbank"-Noten. Rekordbuchnummer. Also listen wir zuerst die Attribute auf, die angezeigt werden müssen, nachdem die Abfrage abgeschlossen ist. Zu erwähnen ist, dass das Attribut „Notenbuchnummer“ aus der Relation Students stammt, von dort die Attribute „Nachname“, „Vorname“ und „Patronym“. Allerdings werden die letzten beiden Attribute nicht vollständig abgeleitet, sondern nur die Anfangsbuchstaben. Wir erwähnen auch das Attribut „Score“ aus der Abfrage „Database Score“, die wir zuvor eingegeben haben. All diese Attribute wählen wir aus dem Inner Join der Relation „Schüler“ und der Abfrage „Datenbanknoten“ aus. Diese innere Verbindung wird, wie wir sehen, von uns unter der Bedingung der Gleichheit der Nummern des Registerbuchs genommen. Als Ergebnis dieser inneren Verknüpfungsoperation werden der Schülerbeziehung Noten hinzugefügt. Zu beachten ist, dass, da die Attribute „Nachname“, „Vorname“ und „Patronymic“ per Bedingung keine Null-Werte zulassen und nicht leer sind, die Berechnungsformel, die das Attribut „Name“ (Trim (Nachname) + " " + Links (Name, 1) + "." + Links (Patronym, 1) + "."as Vollständiger Name) bzw. erfordert keine zusätzlichen Prüfungen, wird vereinfacht. Vorlesung Nummer 7. Grundlegende Beziehungen Wie wir bereits wissen, sind Datenbanken eine Art Container, dessen Hauptzweck es ist, Daten zu speichern, die in Form von Beziehungen dargestellt werden. Sie müssen wissen, dass Beziehungen je nach Art und Struktur unterteilt werden in: 1) grundlegende Beziehungen; 2) virtuelle Beziehungen. Basisansichtsbeziehungen enthalten nur unabhängige Daten und können nicht in Bezug auf andere Datenbankbeziehungen ausgedrückt werden. In kommerziellen Datenbankverwaltungssystemen werden grundlegende Beziehungen normalerweise einfach als bezeichnet Tabellen im Gegensatz zu Repräsentationen, die dem Konzept virtueller Relationen entsprechen. In diesem Kurs werden wir nur die grundlegenden Beziehungen, die wichtigsten Techniken und Prinzipien der Arbeit mit ihnen im Detail betrachten. 1. Grundlegende Datentypen Datentypen werden wie Beziehungen unterteilt in grundlegend и virtuell. (Wir werden etwas später auf virtuelle Datentypen eingehen; wir werden diesem Thema ein eigenes Kapitel widmen.) Grundlegende Datentypen - dies sind beliebige Datentypen, die initial in Datenbankverwaltungssystemen definiert werden, also dort standardmäßig vorhanden sind (im Gegensatz zu einem benutzerdefinierten Datentyp, den wir unmittelbar nach dem Durchlaufen des Basisdatentyps analysieren). Bevor wir zur Betrachtung der eigentlichen Grunddatenarten übergehen, listen wir auf, welche Arten von Daten es im Allgemeinen gibt: 1) numerische Daten; 2) logische Daten; 3) Zeichenfolgendaten; 4) Daten, die das Datum und die Uhrzeit definieren; 5) Identifikationsdaten. Standardmäßig haben Datenbankverwaltungssysteme mehrere der gängigsten Datentypen eingeführt, von denen jeder zu einem der aufgelisteten Datentypen gehört. Nennen wir sie. 1. In numerisch Datentyp wird unterschieden: 1) Ganzzahl. Dieses Schlüsselwort bezeichnet normalerweise einen Integer-Datentyp; 2) Real, entsprechend dem realen Datentyp; 3) Dezimalzahl (n, m). Dies ist ein dezimaler Datentyp. Darüber hinaus ist in der Notation n eine Zahl, die die Gesamtzahl der Ziffern der Zahl festlegt, und m zeigt an, wie viele Zeichen davon nach dem Dezimalpunkt stehen; 4) Geld oder Währung, speziell eingeführt für eine bequeme Datendarstellung des monetären Datentyps. 2. In logisch Datentypen weisen normalerweise nur einen Grundtyp zu, dieser ist Logisch. 3. Schnur Der Datentyp hat vier Grundtypen (womit natürlich die gebräuchlichsten gemeint sind): 1) Bit(n). Dies sind Bitfolgen mit fester Länge n; 2) Varbit(n). Dies sind ebenfalls Bitfolgen, jedoch mit einer variablen Länge, die n Bits nicht überschreitet; 3) Zeichen(n). Dies sind Zeichenketten mit konstanter Länge n; 4) Varchar(n). Dies sind Zeichenketten, deren variable Länge n Zeichen nicht überschreitet. 4. Geben Sie ein Datum und Uhrzeit umfasst die folgenden grundlegenden Datentypen: 1) Datum - Datumsdatentyp; 2) Zeit – Datentyp, der die Tageszeit ausdrückt; 3) Datum-Uhrzeit ist ein Datentyp, der sowohl Datum als auch Uhrzeit ausdrückt. 5. Identifizierung Der Datentyp enthält nur einen Typ, der standardmäßig im Datenbankverwaltungssystem enthalten ist, und das ist GUID (Globally Unique Identifier). Es ist zu beachten, dass alle Basisdatentypen Varianten unterschiedlicher Datendarstellungsbereiche haben können. Beispielsweise können Varianten des XNUMX-Byte-Integer-Datentyps XNUMX-Byte- (bigint) und XNUMX-Byte- (smallint) Datentypen sein. Lassen Sie uns separat über den grundlegenden GUID-Datentyp sprechen. Dieser Typ soll XNUMX-Byte-Werte des sogenannten Global Unique Identifier speichern. Alle unterschiedlichen Werte dieser Kennung werden automatisch generiert, wenn eine spezielle eingebaute Funktion aufgerufen wird NeueID(). Diese Bezeichnung stammt von dem vollständigen englischen Ausdruck New Identification, was wörtlich "neuer Kennungswert" bedeutet. Jeder auf einem bestimmten Computer erzeugte Kennungswert ist innerhalb aller hergestellten Computer eindeutig. Die GUID-Kennung wird insbesondere verwendet, um die Datenbankreplikation zu organisieren, d. h. wenn Kopien einiger vorhandener Datenbanken erstellt werden. Solche GUIDs können von Datenbankentwicklern zusammen mit anderen Grundtypen verwendet werden. Eine Zwischenstellung zwischen dem GUID-Typ und anderen Basistypen nimmt ein weiterer spezieller Basistyp ein – der Typ Schalter. Ein spezielles Schlüsselwort wird verwendet, um Daten dieses Typs zu bezeichnen. Zähler (x0, ∆x), was wörtlich aus dem Englischen übersetzt wird und "Zähler" bedeutet. Parameter x0 setzt den Anfangswert, und Δx - Inkrementschritt. Werte dieses Zählertyps sind zwangsläufig ganze Zahlen. Es sollte beachtet werden, dass die Arbeit mit diesem grundlegenden Datentyp eine Reihe sehr interessanter Funktionen beinhaltet. Beispielsweise werden Werte dieses Typs Counter nicht gesetzt, wie wir es von allen anderen Datentypen gewohnt sind, sie werden bei Bedarf generiert, ähnlich wie Werte des Typs Global Unique Identifier. Ungewöhnlich ist auch, dass der Zählertyp erst beim Definieren der Tabelle angegeben werden kann, und auch nur dann! Dieser Typ kann nicht im Code verwendet werden. Beachten Sie auch, dass bei der Definition einer Tabelle der Zählertyp nur für eine Spalte angegeben werden kann. Zählerdatenwerte werden automatisch generiert, wenn Zeilen eingefügt werden. Außerdem erfolgt diese Generierung ohne Wiederholung, so dass der Zähler jede Zeile immer eindeutig identifiziert. Dies führt jedoch zu einigen Unannehmlichkeiten beim Arbeiten mit Tabellen, die Zählerdaten enthalten. Wenn sich beispielsweise die Daten in der durch die Tabelle vorgegebenen Relation ändern und diese gelöscht oder vertauscht werden müssen, können die Zählerwerte leicht „die Karten verwechseln“, besonders wenn ein unerfahrener Programmierer am Werk ist. Lassen Sie uns ein Beispiel geben, das eine solche Situation veranschaulicht. Gegeben sei die folgende Tabelle, die eine Beziehung darstellt, in der vier Zeilen eingetragen sind:
Der Zähler gab jeder neuen Zeile automatisch einen eindeutigen Namen. Und jetzt entfernen wir die zweite und vierte Zeile aus der Tabelle und fügen dann eine zusätzliche Zeile hinzu. Diese Operationen führen zu der folgenden Transformation der Quelltabelle:
Daher entfernte der Zähler die zweite und vierte Zeile zusammen mit ihren eindeutigen Namen und "wies" sie nicht neuen Zeilen zu, wie man erwarten könnte. Darüber hinaus erlaubt Ihnen das Datenbankverwaltungssystem niemals, den Wert des Zählers manuell zu ändern, ebenso wie es Ihnen nicht erlaubt, mehrere Zähler gleichzeitig in einer Tabelle zu deklarieren. Typischerweise wird der Zähler als Ersatz verwendet, d. h. als künstlicher Schlüssel in der Tabelle. Es ist interessant zu wissen, dass die eindeutigen Werte eines Vier-Byte-Zählers bei einer Generierungsrate von einem Wert pro Sekunde mehr als 100 Jahre halten werden. Lassen Sie uns zeigen, wie es berechnet wird: 1 Jahr = 365 Tage * 24 h * 60 s * 60 s < 366 Tage * 24 h * 60 s * 60 s < 225 mit. 1 Sekunde > 2-25 Jahr. 24*8 Werte / 1 Wert/Sekunde = 232 c > 27 Jahr > 100 Jahre. 2. Benutzerdefinierter Datentyp Ein benutzerdefinierter Datentyp unterscheidet sich von allen Basistypen dadurch, dass er ursprünglich nicht in das Datenbankverwaltungssystem integriert war und nicht als Standarddatentyp deklariert wurde. Dieser Typ kann von jedem Benutzer und Datenbankprogrammierer nach eigenen Wünschen und Anforderungen erstellt werden. Daher ist ein benutzerdefinierter Datentyp ein Untertyp eines Basistyps, d. h. ein Basistyp mit einigen Einschränkungen hinsichtlich des Satzes zulässiger Werte. In Pseudocode-Notation wird ein benutzerdefinierter Datentyp mit der folgenden Standardanweisung erstellt: Untertyp erstellen Untertypname Typ Name des Basistyps As Untertypbeschränkung; In der ersten Zeile müssen wir also den Namen unseres neuen, benutzerdefinierten Datentyps angeben, in der zweiten, welchen der vorhandenen grundlegenden Datentypen wir als Vorlage genommen haben, um unseren eigenen zu erstellen, und schließlich in der dritten - jene Einschränkungen, die wir zu den bestehenden Einschränkungen für den Wertesatz des Basisdatentyps hinzufügen müssen - Beispiel. Untertypbeschränkungen werden als Bedingung geschrieben, die vom Namen des zu definierenden Untertyps abhängt. Betrachten Sie das folgende Beispiel, um besser zu verstehen, wie die Create-Anweisung funktioniert. Angenommen, wir müssen unseren eigenen spezialisierten Datentyp erstellen, um beispielsweise in der Post zu arbeiten. Dies ist der Typ, der mit Daten wie Postleitzahlen arbeitet. Unsere Zahlen unterscheiden sich von gewöhnlichen sechsstelligen Dezimalzahlen dadurch, dass sie nur positiv sein können. Lassen Sie uns einen Operator schreiben, um den benötigten Subtyp zu erstellen: Untertyp erstellen Postleitzahl Typ dezimal(6, 0) As Postleitzahl > 0. Warum haben wir decimal(6, 0) gewählt? Wenn wir uns an die übliche Form des Index erinnern, sehen wir, dass solche Zahlen aus sechs ganzen Zahlen von null bis neun bestehen müssen. Deshalb haben wir den Dezimaltyp als Basisdatentyp genommen. Es ist merkwürdig anzumerken, dass im Allgemeinen die dem Basisdatentyp auferlegte Bedingung, d. h. die Untertypbeschränkung, die logischen Verknüpfungen not und, or enthalten kann und im Allgemeinen ein Ausdruck beliebiger Komplexität sein kann. So definierte benutzerdefinierte Datensubtypen können zusammen mit anderen Basisdatentypen sowohl im Programmcode als auch bei der Definition von Datentypen in Tabellenspalten frei verwendet werden, d. h. Basisdatentypen und Benutzerdatentypen sind bei der Arbeit damit völlig gleichberechtigt. In der visuellen Entwicklungsumgebung erscheinen sie zusammen mit anderen Basisdatentypen in Listen gültiger Typen. Die Wahrscheinlichkeit, dass wir einen undokumentierten (benutzerdefinierten) Datentyp benötigen, wenn wir eine eigene neue Datenbank entwerfen, ist ziemlich hoch. Tatsächlich werden standardmäßig nur die gängigsten Datentypen in das Datenbankverwaltungssystem eingenäht, die jeweils zur Lösung der häufigsten Aufgaben geeignet sind. Beim Aufbau von Fachdatenbanken kommt man fast nicht mehr ohne die Gestaltung eigener Datentypen aus. Aber seltsamerweise müssen wir mit gleicher Wahrscheinlichkeit den von uns erstellten Untertyp entfernen, um den Code nicht zu überladen und zu verkomplizieren. Datenbankverwaltungssysteme haben dafür meist einen speziellen Operator eingebaut. fallen lassen, was „entfernen“ bedeutet. Die allgemeine Form dieses Operators zum Entfernen unnötiger benutzerdefinierter Typen lautet wie folgt: Subtyp löschen der Name des benutzerdefinierten Typs; Benutzerdefinierte Datentypen werden im Allgemeinen für Untertypen empfohlen, die allgemein genug sind. 3. Standardwerte Datenbankverwaltungssysteme verfügen möglicherweise über die Fähigkeit, beliebige Standardwerte oder, wie sie auch als Standardwerte bezeichnet werden, zu erstellen. Diese Operation hat in jeder Programmierumgebung ein ziemlich großes Gewicht, da es bei fast jeder Aufgabe erforderlich sein kann, Konstanten, unveränderliche Standardwerte, einzuführen. Zur Erstellung einer Vorgabe in Datenbankmanagementsystemen wird die uns bereits von der Passage eines benutzerdefinierten Datentyps bekannte Funktion genutzt Erstellen. Lediglich bei der Bildung eines Vorgabewerts wird zusätzlich ein Schlüsselwort verwendet Standard, was „Standard“ bedeutet. Mit anderen Worten, um einen Standardwert in einer vorhandenen Datenbank zu erstellen, müssen Sie die folgende Anweisung verwenden: Standard erstellen Standardname As konstanter Ausdruck; Es ist klar, dass Sie beim Anwenden dieses Operators anstelle eines konstanten Werts den Wert oder Ausdruck schreiben müssen, den wir zum Standardwert oder -ausdruck machen möchten. Und natürlich müssen wir entscheiden, unter welchem Namen wir es bequem in unserer Datenbank verwenden können, und diesen Namen in die erste Zeile des Operators schreiben. Beachten Sie, dass in diesem speziellen Fall diese Create-Anweisung der in das Microsoft SQL Server-System integrierten Transact-SQL-Syntax folgt. Was haben wir also? Wir haben gefolgert, dass der Standard eine benannte Konstante ist, die in Datenbanken gespeichert ist, genau wie ihr Objekt. In der visuellen Entwicklungsumgebung werden die Standardwerte in der Liste der hervorgehobenen Standardwerte angezeigt. Hier ist ein Beispiel für das Erstellen eines Standardwerts. Angenommen, für den korrekten Betrieb unserer Datenbank ist es notwendig, dass darin ein Wert im Sinne einer unbegrenzten Lebensdauer von etwas funktioniert. Dann müssen Sie in die Werteliste dieser Datenbank den Standardwert eingeben, der diese Anforderung erfüllt. Dies kann schon deshalb notwendig sein, weil es jedes Mal, wenn Sie diesen ziemlich umständlichen Ausdruck im Codetext finden, äußerst umständlich ist, ihn erneut auszuschreiben. Aus diesem Grund werden wir die obige Create-Anweisung verwenden, um einen Standard zu erstellen, mit der Bedeutung einer unbegrenzten Lebensdauer von etwas. Standard erstellen "keine Zeitbegrenzung" As ‘9999-12-31 23: 59:59’ Auch hier wurde die Transact-SQL-Syntax verwendet, nach der die Werte von Datums-Zeit-Konstanten (in diesem Fall ‚9999-12-31 23:59:59‘) als Zeichenketten einer bestimmten Richtung geschrieben werden. Die Interpretation von Zeichenketten als Datetime-Werte wird durch den Kontext bestimmt, in dem die Zeichenketten verwendet werden. In unserem speziellen Fall wird beispielsweise zuerst der Grenzwert des Jahres in die konstante Zeile geschrieben und dann die Uhrzeit. Bei aller Nützlichkeit können Standardwerte, wie ein benutzerdefinierter Datentyp, manchmal auch erfordern, dass sie entfernt werden. Datenbankverwaltungssysteme haben normalerweise ein spezielles eingebautes Prädikat, ähnlich einem Operator, der einen eher benutzerdefinierten Datentyp entfernt, der nicht mehr benötigt wird. Dies ist ein Prädikat Drop und der Operator selbst sieht so aus: Standard löschen Standardname; 4. Virtuelle Attribute Alle Attribute in Datenbankverwaltungssystemen werden (in absoluter Analogie zu Beziehungen) in grundlegende und virtuelle Attribute unterteilt. Sogenannt Basisattribute sind gespeicherte Attribute, die mehr als einmal verwendet werden müssen, und daher ist es ratsam, sie zu speichern. Und wiederum virtuelle Attribute sind keine gespeicherten, sondern berechneten Attribute. Was bedeutet das? Das bedeutet, dass die Werte der sogenannten virtuellen Attribute nicht wirklich gespeichert werden, sondern mittels vorgegebener Formeln on the fly durch die Basisattribute berechnet werden. In diesem Fall werden die Domänen berechneter virtueller Attribute automatisch bestimmt. Lassen Sie uns ein Beispiel einer Tabelle geben, die eine Beziehung definiert, in der zwei Attribute gewöhnlich, grundlegend und das dritte Attribut virtuell sind. Sie wird nach einer speziell eingegebenen Formel berechnet.
Wir sehen also, dass die Attribute "Gewicht Kg" und "Preis Rub pro Kg" grundlegende Attribute sind, weil sie gewöhnliche Werte haben und in unserer Datenbank gespeichert sind. Aber das Attribut "Kosten" ist ein virtuelles Attribut, da es durch die Formel seiner Berechnung festgelegt wird und nicht tatsächlich in der Datenbank gespeichert wird. Es ist interessant festzustellen, dass virtuelle Attribute aufgrund ihrer Natur keine Standardwerte annehmen können und im Allgemeinen das eigentliche Konzept eines Standardwerts für ein virtuelles Attribut bedeutungslos und daher nicht anwendbar ist. Und Sie müssen sich auch darüber im Klaren sein, dass, obwohl die Domänen virtueller Attribute automatisch bestimmt werden, die Art der berechneten Werte manchmal von der vorhandenen auf eine andere geändert werden muss. Dafür gibt es in der Sprache der Datenbankmanagementsysteme ein spezielles Convert-Prädikat, mit dessen Hilfe der Typ des berechneten Ausdrucks umdefiniert werden kann. Convert ist die sogenannte explizite Typkonvertierungsfunktion. Es ist wie folgt geschrieben: Konvertieren (Datentyp, Ausdruck); Der Ausdruck, der das zweite Argument der Convert-Funktion ist, wird berechnet und als solche Daten ausgegeben, deren Typ durch das erste Argument der Funktion angegeben wird. Betrachten Sie ein Beispiel. Angenommen, wir müssen den Wert des Ausdrucks "2 * 2" berechnen, aber wir müssen diesen nicht als Ganzzahl "4", sondern als Zeichenfolge ausgeben. Um diese Aufgabe zu erfüllen, schreiben wir die folgende Convert-Funktion: Konvertieren (Zeichen (1), 2 * 2). Wir können also sehen, dass diese Notation der Convert-Funktion genau das Ergebnis liefert, das wir brauchen. 5. Das Schlüsselkonzept Bei der Schemadeklaration einer Basisrelation können mehrere Schlüssel deklariert werden. Das ist uns schon oft begegnet. Schließlich ist es an der Zeit, ausführlicher darüber zu sprechen, was Beziehungsschlüssel sind, und sich nicht auf allgemeine Ausdrücke und ungefähre Definitionen zu beschränken. Lassen Sie uns also eine strenge Definition eines Beziehungsschlüssels geben. Beziehungsschemaschlüssel ist ein Unterschema des ursprünglichen Schemas, das aus einem oder mehreren Attributen besteht, für die es deklariert ist Eindeutigkeitsbedingung Werte in Beziehungstupeln. Um zu verstehen, was die Eindeutigkeitsbedingung ist, oder wie sie auch genannt wird, einzigartige Beschränkung, beginnen wir mit der Definition eines Tupels und der unären Operation, ein Tupel auf eine Teilschaltung zu projizieren. Bringen wir sie mit: t = t(S) = {t(a) | a ∈ def( t) ⊆ S} - Definition eines Tupels, t(S) [S' ] = {t(a) | a ∈ def (t) ∩ S'}, S' ⊆ S ist die Definition der unären Projektionsoperation; Es ist klar, dass die Projektion des Tupels auf das Teilschema einem Teilstring der Tabellenzeile entspricht. Was genau ist also eine Eindeutigkeitsbeschränkung für Schlüsselattribute? Die Deklaration des Schlüssels K für das Schema der Relation S führt zur Formulierung der folgenden unveränderlichen Bedingung, die, wie gesagt, genannt wird: Eindeutigkeitsbeschränkung und bezeichnet als: Inv < K → S > r(S): Inv < K → S > r(S) = ∀t1, T2 ∈ r(t 1[K]=t2 [K] → t 1(S) = t2(S)), K ⊆ S; Diese Eindeutigkeitsbeschränkung Inv < K → S > r(S) des Schlüssels K bedeutet also, dass wenn zwei beliebige Tupel t1 und t2, die zur Relation r(S) gehören, in der Projektion auf den Schlüssel K gleich sind, dann folgt zwangsläufig die Gleichheit dieser beiden Tupel und in der Projektion auf das Gesamtschema der Relation S. Mit anderen Worten, alle Werte der zu den Schlüsselattributen gehörenden Tupel sind einzigartig, einzigartig in ihrer Hinsicht. Und die zweite wichtige Voraussetzung für einen Beziehungsschlüssel ist Redundanzanforderung. Was bedeutet das? Diese Anforderung bedeutet, dass keine strikte Teilmenge des Schlüssels eindeutig sein muss. Auf einer intuitiven Ebene ist klar, dass das Schlüsselattribut das Beziehungsattribut ist, das jedes Tupel der Beziehung eindeutig und genau identifiziert. Zum Beispiel in der folgenden Beziehung, die durch eine Tabelle gegeben ist:
Das Schlüsselattribut ist das Attribut „Notenbuchnummer“, da verschiedene Schüler nicht dieselbe Notenbuchnummer haben können, d. h. dieses Attribut unterliegt einer Eindeutigkeitsbeschränkung. Interessant ist, dass im Schema jeder Relation eine Vielzahl von Schlüsseln vorkommen kann. Wir listen die wichtigsten Arten von Schlüsseln auf: 1) einfacher Schlüssel ist ein Schlüssel, der aus einem und keinen weiteren Attributen besteht. In einem Prüfungsbogen für ein bestimmtes Fach ist beispielsweise die Kreditkartennummer ein einfacher Schlüssel, weil sie jeden Studenten eindeutig identifizieren kann; 2) zusammengesetzter Schlüssel ist ein Schlüssel, der aus zwei oder mehr Attributen besteht. Ein zusammengesetzter Schlüssel in der Liste der Klassenzimmer ist beispielsweise die Gebäudenummer und die Klassenzimmernummer. Schließlich ist es nicht möglich, jede Zielgruppe eindeutig mit einem dieser Attribute zu identifizieren, und dies ganz einfach in ihrer Gesamtheit, also mit einem zusammengesetzten Schlüssel; 3) Superschlüssel ist jede Obermenge eines beliebigen Schlüssels. Daher ist das Schema der Relation selbst sicherlich ein Superschlüssel. Daraus können wir schließen, dass jede Relation theoretisch mindestens einen Schlüssel hat und mehrere davon haben kann. Das Deklarieren eines Superschlüssels anstelle eines normalen Schlüssels ist jedoch logischerweise illegal, da dies eine Lockerung der automatisch erzwungenen Eindeutigkeitsbeschränkung beinhaltet. Schließlich hat der Superschlüssel, obwohl er die Eigenschaft der Eindeutigkeit hat, nicht die Eigenschaft der Nicht-Redundanz; 4) Primärschlüssel ist einfach der Schlüssel, der zuerst deklariert wurde, als die Basisrelation definiert wurde. Es ist wichtig, dass genau ein Primärschlüssel deklariert wird. Darüber hinaus können Primärschlüsselattribute niemals Nullwerte annehmen. Beim Erstellen einer Basisrelation in einem Pseudocode-Eintrag wird der Primärschlüssel angegeben Primärschlüssel und in Klammern steht der Name des Attributs, das dieser Schlüssel ist; 5) Kandidatenschlüssel sind alle anderen Schlüssel, die nach dem Primärschlüssel deklariert sind. Was sind die Hauptunterschiede zwischen Kandidatenschlüsseln und Primärschlüsseln? Erstens kann es mehrere Kandidatenschlüssel geben, während der Primärschlüssel, wie oben erwähnt, nur einer sein kann. Und zweitens, wenn die Attribute des Primärschlüssels keine Nullwerte annehmen können, wird diese Bedingung nicht auf die Attribute der Kandidatenschlüssel angewendet. In Pseudocode werden beim Definieren einer Basisbeziehung Kandidatenschlüssel unter Verwendung der Wörter deklariert Kandidatenschlüssel und als nächstes wird in Klammern, wie im Fall der Deklaration eines Primärschlüssels, der Name des Attributs angegeben, das der gegebene Kandidatenschlüssel ist; 6) externer Schlüssel ist ein in einer Basisrelation deklarierter Schlüssel, der sich auch auf einen Primär- oder Kandidatenschlüssel derselben oder einer anderen Basisrelation bezieht. In diesem Fall wird die Beziehung, auf die sich der Fremdschlüssel bezieht, als Referenz (bzw Elternteil) Attitüde. Es wird eine Relation aufgerufen, die einen Fremdschlüssel enthält Kind. Im Pseudocode wird der Fremdschlüssel als bezeichnet Fremdschlüssel, in Klammern unmittelbar nach diesen Wörtern wird der Name des Attributs dieser Relation angegeben, bei dem es sich um einen Fremdschlüssel handelt, und danach wird das Schlüsselwort geschrieben Referenzen ("bezieht sich auf") und geben Sie den Namen der Basisrelation und den Namen des Attributs an, auf das sich dieser spezielle Fremdschlüssel bezieht. Außerdem wird beim Erstellen einer Basisbeziehung für jeden Fremdschlüssel eine Bedingung geschrieben, genannt Einschränkung der referenziellen Integrität, aber wir werden später ausführlich darauf eingehen. Vortrag Nr. 8 Das Thema dieser Vorlesung wird eine ziemlich detaillierte Diskussion des Basisrelationserstellungsoperators sein. Wir werden den Operator selbst in einem Pseudocode-Datensatz analysieren, alle seine Komponenten und ihre Arbeit analysieren und die Modifizierungsmethoden analysieren, d. h. die grundlegenden Beziehungen ändern. 1. Metasprachliche Symbole Beim Beschreiben der syntaktischen Konstruktionen, die beim Schreiben des Operators zur Erzeugung von Basisbeziehungen in Pseudocode verwendet werden, werden verschiedene Verfahren verwendet. metalinguistische Symbole. Dies sind alle Arten von öffnenden und schließenden Klammern, verschiedene Kombinationen von Punkten und Kommas, kurz gesagt, Symbole, die jeweils ihre eigene Bedeutung haben und es dem Programmierer erleichtern, Code zu schreiben. Lassen Sie uns die Bedeutung der wichtigsten metalinguistischen Symbole vorstellen und erklären, die am häufigsten bei der Gestaltung grundlegender Beziehungen verwendet werden. So: 1) metalinguistisches Zeichen "{}". Syntaktische Konstrukte in geschweiften Klammern sind obligatorisch syntaktische Einheiten. Bei der Definition einer Basisrelation sind die erforderlichen Elemente beispielsweise Basisattribute; ohne Basisattribute zu deklarieren, kann keine Beziehung entworfen werden. Daher werden beim Schreiben des Basisrelationserstellungsoperators in Pseudocode die Basisattribute in geschweiften Klammern aufgelistet; 2) das metalinguistische Symbol "[]". In diesem Fall ist das Gegenteil der Fall: Die Syntaxkonstrukte in eckigen Klammern stehen für Optional Syntaxelemente. Die optionalen syntaktischen Einheiten im Basisbeziehungserstellungsoperator wiederum sind die virtuellen Attribute der Primär-, Kandidaten- und Fremdschlüssel. Hier gibt es natürlich auch Feinheiten, aber darauf kommen wir später zu sprechen, wenn wir direkt zum Entwurf des Operators zur Erstellung der Basisrelation übergehen; 3) metalinguistisches Symbol "|". Dieses Symbol bedeutet wörtlich "oder", wie das analoge Symbol in der Mathematik. Die Verwendung dieses metalinguistischen Symbols bedeutet, dass man zwischen zwei oder mehreren Konstruktionen wählen muss, die jeweils durch dieses Symbol getrennt sind; 4) metalinguistisches Symbol „…“. Ein Auslassungszeichen unmittelbar nach einer syntaktischen Einheit bedeutet die Möglichkeit Wiederholungen diese syntaktischen Elemente, die dem metalinguistischen Symbol vorangehen; 5) metalinguistisches Symbol ",..". Dieses Symbol bedeutet fast dasselbe wie das vorherige. Nur bei Verwendung des metalinguistischen Symbols ",..", Wiederholung syntaktische Konstruktionen auftreten durch Kommata abgetrenntwas oft viel bequemer ist. Vor diesem Hintergrund können wir von der Äquivalenz der folgenden beiden syntaktischen Konstruktionen sprechen: Einheit [, Einheit]... и Einheit,.. ; 2. Ein Beispiel für das Erstellen einer grundlegenden Beziehung in einem Pseudocode-Eintrag Nachdem wir nun die Bedeutung der wichtigsten metalinguistischen Symbole geklärt haben, die beim Schreiben des Operators zur Erstellung von Basisrelationen in Pseudocode verwendet werden, können wir mit der eigentlichen Betrachtung dieses Operators selbst fortfahren. Wie aus den obigen Referenzen ersichtlich ist, enthält der Operator zum Erzeugen einer Basisbeziehung in dem Pseudocode-Eintrag Deklarationen von Basis- und virtuellen Attributen, Primär-, Kandidaten- und Fremdschlüsseln. Außerdem deckt dieser Operator, wie oben gezeigt und erläutert wird, auch Attributwertbeschränkungen und Tupelbeschränkungen sowie sogenannte referenzielle Integritätsbeschränkungen ab. Die ersten beiden Einschränkungen, nämlich die Attributwert-Einschränkung und die Tupel-Einschränkung, werden nach dem speziellen reservierten Wort deklariert aus der Ferne überprüfen. Es gibt zwei Arten von referenziellen Integritätsbedingungen: beim Update, was "beim Aktualisieren" bedeutet, und auf löschen, was „beim Löschen“ bedeutet. Was bedeutet das? Dies bedeutet, dass beim Aktualisieren oder Löschen von Attributen von Beziehungen, auf die durch einen Fremdschlüssel verwiesen wird, die Zustandsintegrität aufrechterhalten werden muss. (Wir werden später mehr darüber sprechen.) Der Basisrelationserstellungsoperator selbst wird von uns bereits untersucht - der Operator Erstellen, nur um eine grundlegende Beziehung herzustellen, wird das Schlüsselwort hinzugefügt Tabelle ("Attitüde"). Und da die Relation selbst natürlich größer ist und alle zuvor besprochenen Konstrukte sowie neue zusätzliche Konstrukte enthält, wird der create-Operator ziemlich beeindruckend sein. Lassen Sie uns also in Pseudocode die allgemeine Form des Operators schreiben, der zum Erstellen grundlegender Beziehungen verwendet wird: Tabelle erstellen Name der Basisbeziehung { Name des Basisattributs Werttyp des Basisattributs aus der Ferne überprüfen (Attributwertgrenze) {Null | nicht null} Standard (Standardwert) },.. [Name des virtuellen Attributs as (Berechnungsformel) ],.. [,aus der Ferne überprüfen (Tupelbeschränkung)] [,Primärschlüssel (Attributname,..)] [,Kandidatenschlüssel (Attributname,..)]... [,Fremdschlüssel (Attributname,..) Referenzen Referenzbeziehungsname (Attributname,..) bei Aktualisierung {Einschränken | Kaskade | Null setzen} beim Löschen { Einschränken | Kaskade | Null setzen} ] ... Wir sehen also, dass mehrere grundlegende und virtuelle Attribute, Kandidaten- und Fremdschlüssel deklariert werden können, da nach den entsprechenden syntaktischen Konstruktionen ein metalinguistisches Symbol ",.." Nach der Deklaration des Primärschlüssels ist dieses Symbol nicht mehr vorhanden, da die Basisrelationen, wie bereits erwähnt, nur einen Primärschlüssel zulassen. Als nächstes schauen wir uns den Deklarationsmechanismus genauer an. grundlegende Attribute. Bei der Beschreibung eines Attributs im Basisbeziehungserstellungsoperator werden im allgemeinen sein Name, Typ, Einschränkungen seiner Werte, Nullwert-Gültigkeitskennzeichen und Standardwerte angegeben. Es ist leicht zu erkennen, dass der Typ eines Attributs und seine Wertbeschränkungen seine Domäne bestimmen, d. h. buchstäblich die Menge gültiger Werte für dieses bestimmte Attribut. Einschränkung des Attributwerts wird als vom Attributnamen abhängige Bedingung geschrieben. Hier ist ein kleines Beispiel, um dieses Material verständlicher zu machen: Tabelle erstellen Name der Basisbeziehung Kurs ganze Zahl aus der Ferne überprüfen (1 <= Kurs und Kurs <= 5; Hier bedingt die Bedingung „1 <= Überschrift und Überschrift <= 5“ zusammen mit der Definition eines Integer-Datentyps wirklich vollständig die Menge der zulässigen Werte des Attributs, also buchstäblich seine Domäne. Das Null-Werte-Erlaubnis-Flag (Null | not Null) verbietet (nicht Null) oder erlaubt (Null) das Auftreten von Null-Werten unter Attributwerten. Bei dem gerade besprochenen Beispiel sieht der Mechanismus zum Anwenden von Null-Gültigkeits-Flags wie folgt aus: Tabelle erstellen Name der Basisbeziehung Kurs ganze Zahl aus der Ferne überprüfen (1 <= Kurs und Kurs <= 5); Nicht null; Daher kann die Kursnummer eines Studenten niemals null sein, Datenbank-Compilern nicht unbekannt sein und nicht existieren. Standardwerte (Standard (Standardwert)) werden beim Einfügen eines Tupels in eine Beziehung verwendet, wenn die Attributwerte nicht explizit in der Insert-Anweisung gesetzt werden. Es ist interessant festzustellen, dass Standardwerte auch Nullwerte sein können, solange Nullwerte für das jeweilige Attribut als gültig deklariert werden. Betrachten Sie nun die Definition virtuelles Attribut im Basisrelationserstellungsoperator. Wie wir bereits gesagt haben, besteht das Setzen eines virtuellen Attributs darin, Formeln für seine Berechnung durch andere Basisattribute zu setzen. Betrachten wir ein Beispiel für die Deklaration eines virtuellen Attributs „Cost Rub“. in Form einer Formel in Abhängigkeit von den Grundattributen „Gewicht Kg“ und „Preis Rub. pro Kg“. Tabelle erstellen Name der Basisbeziehung Gewicht (kg Basisattribut Werttyp Gewicht Kg aus der Ferne überprüfen (Einschränkung des Attributwertes Gewicht Kg) nicht null Standard (Standardwert) Preis, reiben. pro kg Werttyp des Basisattributs Price Rub. pro kg aus der Ferne überprüfen (Einschränkung des Werts des Attributs Price Rub. per Kg) nicht null Standard (Standardwert) ... Kosten, reiben. as (Gewicht Kg * Preis Rub. pro Kg) Etwas früher haben wir uns Attributbeschränkungen angesehen, die als Bedingungen geschrieben wurden, die von Attributnamen abhängig sind. Betrachten Sie nun die zweite Art von Einschränkungen, die beim Erstellen einer Basisbeziehung deklariert werden, nämlich Tupel-Einschränkungen. Was ist eine Tupelbeschränkung, wie unterscheidet sie sich von einer Attributbeschränkung? Eine Tupel-Einschränkung wird auch als eine vom Basisattributnamen abhängige Bedingung geschrieben, aber nur im Fall einer Tupel-Einschränkung kann die Bedingung gleichzeitig von mehreren Attributnamen abhängen. Betrachten Sie ein Beispiel, das den Mechanismus der Arbeit mit Tupelbeschränkungen veranschaulicht: Tabelle erstellen Name der Basisbeziehung Mindestgewicht Kg Wert Art des Basisattributs min Gewicht Kg aus der Ferne überprüfen (Einschränkung des Attributwertes min Gewicht Kg) nicht null Standard (Standardwert) max. Gewicht Kg Wert Art des Basisattributs max. Gewicht Kg aus der Ferne überprüfen (Einschränkung des Attributwertes max. Gewicht Kg) nicht null Standard (Standardwert) aus der Ferne überprüfen (0 < min Gewicht Kg und Mindestgewicht kg < Höchstgewicht kg); Das Anwenden einer Einschränkung auf ein Tupel läuft also darauf hinaus, die Werte des Tupels durch Attributnamen zu ersetzen. Betrachten wir nun den Basisrelationserstellungsoperator. Einmal deklariert, können Basis- und virtuelle Attribute deklariert werden oder nicht. Schlüssel: primär, Kandidat und extern. Wie bereits erwähnt, wird das Subschema einer Basisrelation aufgerufen, das in einer anderen (oder derselben) Basisrelation einem Primär- oder Kandidatenschlüssel im Kontext der ersten Relation entspricht Unbekannter Schlüssel. Fremdschlüssel darstellen Link-Mechanismus Tupel einiger Relationen auf Tupel anderer Relationen, d.h. es gibt Fremdschlüsseldeklarationen, die mit dem Auferlegen der bereits erwähnten sog referenzielle Integritätsbedingungen. (Diese Einschränkung wird im Mittelpunkt der nächsten Vorlesung stehen, da die Zustandsintegrität (d. h. die durch Integritätsbedingungen erzwungene Integrität) entscheidend für den Erfolg der Basisrelation und der gesamten Datenbank ist.) Das Deklarieren von Primär- und Kandidatenschlüsseln legt wiederum die entsprechenden Eindeutigkeitsbeschränkungen für das Basisbeziehungsschema fest, die wir zuvor besprochen haben. Und schließlich sollte noch über die Möglichkeit gesprochen werden, die Basisrelation zu löschen. In der Praxis des Datenbankdesigns ist es oft notwendig, eine alte unnötige Relation zu entfernen, um den Programmcode nicht zu überladen. Dies kann mit dem bereits bekannten Operator erfolgen Drop. In seiner vollständigen allgemeinen Form sieht der Löschoperator der Basisbeziehung folgendermaßen aus: Tabelle löschen der Name der Basisrelation; 3. Integritätsbeschränkung nach Staat Integritätsbeschränkung relationales Datenobjekt ab ist die sogenannte Dateninvariante. Dabei ist Integrität klar von Sicherheit abzugrenzen, was wiederum den Schutz von Daten vor unbefugtem Zugriff darauf impliziert, um Daten offenzulegen, zu verändern oder zu vernichten. Im Allgemeinen werden Integritätsbedingungen für relationale Datenobjekte klassifiziert nach Hierarchiestufen dieselben relationalen Datenobjekte (die Hierarchie relationaler Datenobjekte ist eine Folge verschachtelter Konzepte: "Attribut - Tupel - Relation - Datenbank"). Was bedeutet das? Das bedeutet, dass Integritätsbedingungen abhängen von: 1) auf Attributebene - von Attributwerten; 2) auf Tupelebene - aus den Werten des Tupels, d.h. aus den Werten mehrerer Attribute; 3) auf der Ebene der Relationen – aus einer Relation, d. h. aus mehreren Tupeln; 4) auf Datenbankebene - aus mehreren Beziehungen. Nun bleibt uns also nur noch, die Integritätsbeschränkungen für den Zustand jedes der oben genannten Konzepte genauer zu betrachten. Aber lassen Sie uns zunächst die Konzepte der prozeduralen und deklarativen Unterstützung für Zustandsintegritätsbeschränkungen erläutern. Es gibt also zwei Arten von Unterstützung für Integritätsbedingungen: 1) prozedural, d.h. erstellt durch Schreiben von Programmcode; 2) deklarativ, d. h. erstellt, indem bestimmte Einschränkungen für jedes der oben genannten verschachtelten Konzepte deklariert werden. Die deklarative Unterstützung für Integritätsbedingungen wird im Kontext der Create-Anweisung zum Erstellen der Basisbeziehung implementiert. Lassen Sie uns ausführlicher darüber sprechen. Beginnen wir mit der Betrachtung der Beschränkungen am unteren Ende unserer hierarchischen Leiter relationaler Datenobjekte, also vom Konzept eines Attributs. Einschränkung auf Attributebene beinhaltet: 1) Beschränkungen für die Art der Attributwerte. Zum Beispiel eine ganzzahlige Bedingung für Werte, d. h. eine ganzzahlige Bedingung für das Attribut "Kurs" aus einer der zuvor besprochenen Basisbeziehungen; 2) eine Attributwertbeschränkung, geschrieben als Bedingung abhängig vom Attributnamen. Wenn wir beispielsweise dieselbe grundlegende Beziehung wie im vorherigen Absatz analysieren, sehen wir, dass es in dieser Beziehung auch eine Einschränkung für Attributwerte gibt, die die Option verwenden aus der Ferne überprüfen, dh: aus der Ferne überprüfen (1 <= Kurs und Kurs <= 5); 3) Einschränkung auf Attributebene umfasst Nullwert-Einschränkungen, die durch das wohlbekannte Flag der Gültigkeit (Null) oder umgekehrt Unzulässigkeit (nicht Null) von Null-Werten definiert sind. Wie bereits erwähnt, definieren die ersten beiden Einschränkungen die Domänenbeschränkung des Attributs, dh den Wert seines Definitionssatzes. Außerdem müssen wir gemäß der hierarchischen Leiter relationaler Datenobjekte von Tupeln sprechen. So, Einschränkung auf Tupelebene reduziert sich auf eine Tupelbeschränkung und wird als Bedingung geschrieben, die von den Namen mehrerer grundlegender Attribute des Beziehungsschemas abhängt, d. h. diese Zustandsintegritätsbeschränkung ist viel kleiner und einfacher als die ähnliche und entspricht nur dem Attribut. Und wieder wäre es nützlich, sich an das Beispiel der Grundrelation zu erinnern, die wir zuvor durchgegangen sind und die die Tupelbeschränkung hat, die wir jetzt brauchen, nämlich: aus der Ferne überprüfen (0 < min Gewicht Kg und Mindestgewicht kg < Höchstgewicht kg); Und schließlich ist der letzte bedeutsame Begriff im Zusammenhang mit der Integritätseinschränkung des Staates der Begriff der Beziehungsebene. Wie wir bereits gesagt haben, Beschränkung auf Beziehungsebene beinhaltet die Begrenzung der Werte der primären (Primärschlüssel) und Kandidat (Kandidatenschlüssel) Schlüssel. Es ist merkwürdig, dass die Beschränkungen, die Datenbanken auferlegt werden, keine staatlichen Integritätsbedingungen mehr sind, sondern referenzielle Integritätsbedingungen. 4. Einschränkungen der referenziellen Integrität Die Einschränkung auf Datenbankebene enthält also die Einschränkung der referenziellen Integrität des Fremdschlüssels (Fremdschlüssel). Wir haben dies bereits kurz erwähnt, als wir über referentielle Integritätsbedingungen beim Erstellen einer Basisbeziehung und Fremdschlüssel gesprochen haben. Nun ist es an der Zeit, ausführlicher über dieses Konzept zu sprechen. Wie wir bereits gesagt haben, bezieht sich der Fremdschlüssel der deklarierten Basisrelation auf den Primär- oder Kandidatenschlüssel einer anderen (meistens) Basisrelation. Denken Sie daran, dass in diesem Fall die vom Fremdschlüssel referenzierte Relation aufgerufen wird Hinweis oder elterlich, weil es gewissermaßen ein Attribut oder mehrere Attribute in der referenzierenden Basisrelation „erzeugt“. Und wiederum wird eine Relation aufgerufen, die einen Fremdschlüssel enthält Kind, auch aus offensichtlichen Gründen. Was ist der Einschränkung der referenziellen Integrität? Und es besteht darin, dass jeder Wert des Fremdschlüssels der untergeordneten Beziehung unbedingt dem Wert eines beliebigen Schlüssels der übergeordneten Beziehung entsprechen muss, es sei denn, der Wert des Fremdschlüssels enthält Nullwerte in irgendwelchen Attributen. Tupel einer Kindbeziehung, die diese Bedingung verletzen, werden aufgerufen hängend. Wenn der Fremdschlüssel der untergeordneten Beziehung tatsächlich auf ein Attribut verweist, das in der übergeordneten Beziehung nicht existiert, dann bezieht er sich auf nichts. Genau diese Situationen müssen unbedingt vermieden werden, und das bedeutet die Wahrung der referentiellen Integrität. Aber in dem Wissen, dass keine Datenbank jemals die Erstellung eines Dangling-Tupels zulassen wird, stellen Entwickler sicher, dass es keine anfänglichen Dangling-Tupel in der Datenbank gibt und dass alle verfügbaren Schlüssel auf ein sehr reales Attribut der übergeordneten Beziehung verweisen. Dennoch gibt es Situationen, in denen bereits während des Betriebs der Datenbank baumelnde Tupel gebildet werden. Was sind das für Situationen? Es ist bekannt, dass, wenn Tupel aus der Elternbeziehung entfernt werden oder wenn der Schlüsselwert eines Tupels der Elternbeziehung aktualisiert wird, die referentielle Integrität verletzt werden kann, d. h. es können baumelnde Tupel auftreten. Um die Möglichkeit ihres Auftretens bei der Deklaration eines Fremdschlüsselwerts auszuschließen, wird eine der folgenden Angaben gemacht: drei vorhanden er hat Beibehaltung der referenziellen Integrität, die entsprechend angewendet wird, wenn der Schlüsselwert in der übergeordneten Beziehung aktualisiert wird (d. h., wie wir bereits erwähnt haben, beim Update) oder beim Entfernen eines Tupels aus der Elternbeziehung (auf löschen). Es sollte beachtet werden, dass das Hinzufügen eines neuen Tupels zur übergeordneten Beziehung aus offensichtlichen Gründen die referentielle Integrität nicht brechen kann. Denn wenn dieses Tupel gerade zur Basisrelation hinzugefügt wurde, konnte zuvor kein Attribut darauf verweisen, da es fehlt! Was sind also diese drei Regeln, die verwendet werden, um die referenzielle Integrität in Datenbanken aufrechtzuerhalten? Lassen Sie uns sie auflisten. 1. einschränkenOder Beschränkungsregel. Wenn wir beim Setzen unserer Basisrelation beim Deklarieren von Fremdschlüsseln in einer referenziellen Integritätsbedingung diese Regel der Beibehaltung angewendet haben, kann das Aktualisieren eines Schlüssels in der Elternrelation oder das Löschen eines Tupels aus der Elternrelation einfach nicht durchgeführt werden, wenn dieses Tupel ist referenziert von mindestens einem Tupel der Kindbeziehung, d. h. Operation einschränken verbietet strengstens die Durchführung von Aktionen, die zum Erscheinen von hängenden Tupeln führen könnten. Wir veranschaulichen die Anwendung dieser Regel mit dem folgenden Beispiel. Gegeben seien zwei Relationen: Elterliche Haltung
Kind Beziehung
Wir sehen, dass sich die untergeordneten Beziehungstupel (2,...) und (2,...) auf das übergeordnete Beziehungstupel (..., 2) und das untergeordnete Beziehungstupel (3,...) auf bezieht die (..., 3) elterliche Haltung. Das Tupel (100,...) der untergeordneten Beziehung baumelt und ist ungültig. Hier ermöglichen nur die übergeordneten Relationstupel (..., 1) und (..., 4) das Aktualisieren von Schlüsselwerten und das Löschen von Tupeln, da sie von keinem der Fremdschlüssel der untergeordneten Relation referenziert werden. Lassen Sie uns den Operator zum Erstellen einer grundlegenden Beziehung zusammenstellen, die die Deklaration aller oben genannten Schlüssel enthält: Tabelle erstellen Elterliche Haltung Primärschlüssel ganze Zahl nicht null Primärschlüssel (Primärschlüssel) Tabelle erstellen Kind Beziehung Unbekannter Schlüssel ganze Zahl Null Fremdschlüssel (Unbekannter Schlüssel) Referenzen Übergeordnete Beziehung (Primary_key) auf Update Einschränken löschen beschränken 2. KaskadeOder Kaskadenmodifikationsregel. Wenn wir bei der Deklaration von Fremdschlüsseln in unserer Basisbeziehung die Regel der Aufrechterhaltung der referenziellen Integrität angewendet haben Kaskade, dann bewirkt das Aktualisieren eines Schlüssels in der Elternrelation oder das Löschen eines Tupels aus der Elternrelation, dass die entsprechenden Schlüssel und Tupel der Kindrelation automatisch aktualisiert oder gelöscht werden. Sehen wir uns ein Beispiel an, um besser zu verstehen, wie die Kaskadenmodifikationsregel funktioniert. Gegeben seien die uns bereits aus dem vorigen Beispiel bekannten Grundbeziehungen: Elterliche Haltung
и Kind Beziehung
Angenommen, wir aktualisieren einige Tupel in der Tabelle, die die Beziehung „Übergeordnete Beziehung“ definiert, indem wir das Tupel (..., 2) durch das Tupel (..., 20) ersetzen, d. h. wir erhalten eine neue Beziehung: Elterliche Haltung
Und lassen Sie gleichzeitig in der Anweisung zum Erstellen unserer Basisbeziehung "Kindbeziehung" bei der Deklaration von Fremdschlüsseln die Regel der Aufrechterhaltung der referenziellen Integrität anwenden Kaskade, d. h. der Operator zum Erstellen unserer Basisbeziehung sieht folgendermaßen aus: Tabelle erstellen Elterliche Haltung Primärschlüssel ganze Zahl nicht null Primärschlüssel (Primärschlüssel) Tabelle erstellen Kind Beziehung Unbekannter Schlüssel ganze Zahl Null Fremdschlüssel (Unbekannter Schlüssel) Referenzen Übergeordnete Beziehung (Primary_key) auf Update Cascade auf Cascade löschen Was passiert dann mit der Kindbeziehung, wenn die Elternbeziehung auf die oben beschriebene Weise aktualisiert wird? Es wird folgende Form annehmen: Kind Beziehung
So in der Tat die Regel Kaskade stellt eine kaskadierende Aktualisierung aller Tupel in der Kindbeziehung als Reaktion auf Aktualisierungen der Elternbeziehung bereit. 3. Null setzenOder Nullzuweisungsregel. Wenn wir in der Anweisung zum Erstellen unserer Basisbeziehung bei der Deklaration von Fremdschlüsseln die Regel der Aufrechterhaltung der referenziellen Integrität anwenden Null setzen, dann führt das Aktualisieren des Schlüssels einer übergeordneten Beziehung oder das Löschen eines Tupels aus einer übergeordneten Beziehung dazu, dass den Fremdschlüsselattributen der untergeordneten Beziehung, die Nullwerte zulassen, automatisch Nullwerte zugewiesen werden. Daher ist die Regel anwendbar, wenn solche Attribute vorhanden sind. Schauen wir uns ein Beispiel an, das wir bereits zuvor verwendet haben. Angenommen, wir haben zwei grundlegende Beziehungen: "Erziehung"
Kind Beziehung
Wie Sie sehen können, erlauben untergeordnete Beziehungsattribute Nullwerte, daher die Regel Null setzen in diesem speziellen Fall anwendbar. Nehmen wir nun an, dass das Tupel (..., 1) aus der übergeordneten Beziehung entfernt und das Tupel (..., 2) aktualisiert wurde, wie im vorherigen Beispiel. Somit nimmt die übergeordnete Beziehung die folgende Form an: Elterliche Haltung
Unter Berücksichtigung der Tatsache, dass wir bei der Deklaration der Fremdschlüssel der untergeordneten Beziehung die Regel der Aufrechterhaltung der referenziellen Integrität angewendet haben Null setzen, sieht die untergeordnete Beziehung wie folgt aus: Kind Beziehung
Auf das Tupel (..., 1) wurde von keinem untergeordneten Beziehungsschlüssel verwiesen, daher hat das Löschen keine Konsequenzen. Der Basisbeziehungserstellungsoperator selbst verwendet die Regel Null setzen Bei der Deklaration von Fremdschlüsseln sieht die Beziehung so aus: Tabelle erstellen Elterliche Haltung Primärschlüssel ganze Zahl nicht null Primärschlüssel (Primärschlüssel) Tabelle erstellen Kind Beziehung Unbekannter Schlüssel ganze Zahl Null Fremdschlüssel (Unbekannter Schlüssel) Referenzen Übergeordnete Beziehung (Primary_key) bei Update auf Null setzen beim Löschen Null setzen Wir sehen also, dass das Vorhandensein von drei verschiedenen Regeln zur Aufrechterhaltung der referenziellen Integrität dies in Phrasen gewährleistet beim Update и auf löschen Funktionen können variieren. Es muss beachtet und verstanden werden, dass das Einfügen von Tupeln in eine Kindbeziehung oder das Aktualisieren der Schlüsselwerte von Kindbeziehungen nicht durchgeführt wird, wenn dies zu einer Verletzung der referentiellen Integrität führt, d. h. zum Auftreten von sogenannten Dangling-Tupeln. Das Entfernen von Tupeln aus einer Kindbeziehung kann unter keinen Umständen zu einer Verletzung der referentiellen Integrität führen. Interessant ist, dass eine Kind-Relation gleichzeitig als Eltern-Relation mit eigenen Regeln zur Wahrung der referentiellen Integrität fungieren kann, wenn die Fremdschlüssel anderer Basis-Relationen auf einige ihrer Attribute als Primärschlüssel verweisen. Wenn Programmierer sicherstellen möchten, dass die referentielle Integrität durch einige andere Regeln als die oben genannten Standardregeln erzwungen wird, wird eine prozedurale Unterstützung für solche nicht standardmäßigen Regeln zum Aufrechterhalten der referentiellen Integrität mit Hilfe von sogenannten Triggern bereitgestellt. Eine detaillierte Betrachtung dieses Konzeptes geht leider nicht in unseren Vortrag über. 5. Das Konzept der Indizes Die Erstellung von Schlüsseln in Basisbeziehungen ist automatisch mit der Erstellung von Indizes verknüpft. Lassen Sie uns den Begriff eines Index definieren. Index - Dies ist eine Systemdatenstruktur, die eine notwendigerweise geordnete Liste von Werten eines Schlüssels mit Links zu den Tupeln der Beziehung enthält, in denen diese Werte vorkommen. In Datenbankverwaltungssystemen gibt es zwei Arten von Indizes: 1) einfach. Ein einfacher Index wird für ein Schema-Subschema der Basisrelation von einem einzelnen Attribut genommen; 2) Verbindung. Dementsprechend ist ein zusammengesetzter Index ein Index für ein Teilschema, das aus mehreren Attributen besteht. Aber zusätzlich zur Unterteilung in einfache und zusammengesetzte Indizes gibt es in Datenbankverwaltungssystemen eine Unterteilung von Indizes in eindeutige und nicht eindeutige. So: 1) einzigartig Indizes sind Indizes, die auf höchstens ein Attribut verweisen. Eindeutige Indizes entsprechen im Allgemeinen dem Primärschlüssel der Relation; 2) nicht eindeutig Indizes sind Indizes, die mehreren Attributen gleichzeitig entsprechen können. Nicht eindeutige Schlüssel wiederum entsprechen meistens den Fremdschlüsseln der Beziehung. Betrachten Sie ein Beispiel, das die Aufteilung von Indizes in eindeutige und nicht eindeutige Indizes veranschaulicht, d. h. betrachten Sie die folgenden durch Tabellen definierten Beziehungen:
Primärschlüssel ist hier jeweils der Primärschlüssel der Beziehung, Fremdschlüssel ist der Fremdschlüssel. Es ist klar, dass in diesen Beziehungen der Index des Primärschlüsselattributs eindeutig ist, da er dem Primärschlüssel entspricht, also einem Attribut, und der Index des Fremdschlüsselattributs nicht eindeutig ist, weil er Fremdschlüsseln entspricht. Und sein Wert "20" entspricht sowohl der ersten als auch der dritten Zeile der Beziehungstabelle. Aber manchmal können Indizes ohne Berücksichtigung von Schlüsseln erstellt werden. Dies geschieht in Datenbankverwaltungssystemen, um die Durchführung von Sortier- und Suchvorgängen zu unterstützen. Beispielsweise wird eine dichotome Suche nach einem Indexwert in Tupeln in zwanzig Iterationen in Datenbankverwaltungssystemen implementiert. Woher stammen diese Informationen? Sie wurden durch einfache Berechnungen erhalten, d.h. wie folgt: 106 = (103)2 = 220; Indizes werden in Datenbankverwaltungssystemen mit der uns bereits bekannten Create-Anweisung erstellt, jedoch nur mit dem Zusatz des Index-Schlüsselworts. Ein solcher Operator sieht folgendermaßen aus: Index erstellen Indexname On Name der Basisrelation (Attributname,..); Hier sehen wir das bekannte metalinguistische Symbol „,..“ für die Möglichkeit, ein Argument durch ein Komma getrennt zu wiederholen, d. h. in diesem Operator kann ein Index erstellt werden, der mehreren Attributen entspricht. Wenn Sie einen eindeutigen Index deklarieren möchten, fügen Sie das eindeutige Schlüsselwort vor dem Indexwort hinzu, und dann wird die gesamte Erstellungsanweisung in der Basisindexbeziehung wie folgt: Erstellen Sie einen eindeutigen Index Indexname On Name der Basisbeziehung (Attributname); Wenn wir uns dann in der allgemeinsten Form an die Regel zur Bezeichnung optionaler Elemente erinnern (das metalinguistische Symbol []), sieht der Indexerstellungsoperator in der Grundrelation so aus: Erstellen Sie einen [eindeutigen] Index Indexname On Name der Basisrelation (Attributname,..); Wenn Sie einen bereits vorhandenen Index aus der Basisrelation entfernen möchten, verwenden Sie den Drop-Operator, der uns ebenfalls bereits bekannt ist: Index löschen {Name der Basisbeziehung. Indexname},.. ; Warum wird hier der qualifizierte Indexname "Name der Basisrelation. Indexname" verwendet? Ein Indexlöschoperator verwendet immer seinen qualifizierten Namen, da der Indexname innerhalb derselben Beziehung eindeutig sein muss, aber nicht mehr. 6. Änderung grundlegender Beziehungen Um erfolgreich und produktiv mit verschiedenen Basisbeziehungen zu arbeiten, müssen Entwickler diese Basisbeziehungen sehr oft auf irgendeine Weise modifizieren. Was sind die wichtigsten erforderlichen Änderungsoptionen, denen man in der Praxis des Datenbankdesigns am häufigsten begegnet? Lassen Sie uns sie auflisten: 1) Einfügen von Tupeln. Sehr oft müssen Sie neue Tupel in eine bereits gebildete Basisrelation einfügen; 2) Aktualisieren von Attributwerten. Und die Notwendigkeit für diese Änderung in der Programmierpraxis ist noch häufiger als die vorherige, denn wenn neue Informationen über die Argumente Ihrer Datenbank eintreffen, müssen Sie unweigerlich einige alte Informationen aktualisieren; 3) Entfernen von Tupeln. Und mit ungefähr gleicher Wahrscheinlichkeit ist es erforderlich, diejenigen Tupel aus der Basisrelation zu entfernen, deren Vorhandensein in Ihrer Datenbank aufgrund neuer Informationen nicht mehr erforderlich ist. Wir haben also die wichtigsten Punkte zur Änderung der grundlegenden Beziehungen skizziert. Wie kann jedes dieser Ziele erreicht werden? In Datenbankverwaltungssystemen gibt es meistens eingebaute grundlegende Beziehungsmodifikationsoperatoren. Lassen Sie uns sie in einem Pseudo-Code-Eintrag beschreiben: 1) Operator einfügen in die Basisrelation der neuen Tupel. Dies ist der Betreiber Insert. Es sieht aus wie das: Einfügen in Name der Basisbeziehung (Attributname,..) Werte (Attributwert,..); Das metalinguistische Symbol „,..“ nach dem Attributnamen und dem Attributwert sagt uns, dass dieser Operator es erlaubt, mehrere Attribute gleichzeitig zur Basisrelation hinzuzufügen. In diesem Fall müssen Sie die Attributnamen und Attributwerte durch Kommas getrennt in einer konsistenten Reihenfolge auflisten. Ключевое слово in in Kombination mit dem allgemeinen Namen des Betreibers Insert bedeutet "einfügen in" und gibt an, in welcher Relation die Attribute in Klammern einzufügen sind. Ключевое слово Werte in dieser Anweisung und bedeutet "Werte", "Werte", die diesen neu deklarierten Attributen zugewiesen werden; 2) Überlege jetzt Update-Operator Attributwerte in der Basisrelation. Dieser Operator wird aufgerufen Aktualisierung, was aus dem Englischen übersetzt wird und wörtlich „Aktualisierung“ bedeutet. Lassen Sie uns die vollständige allgemeine Form dieses Operators in einer Pseudocode-Notation angeben und entschlüsseln: Aktualisierung Name der Basisbeziehung Sept {Attributname - Attributwert},.. Wo Bedingung; Also in der ersten Zeile des Operators nach dem Schlüsselwort Aktualisierung der Name der Basisrelation, in der Aktualisierungen vorgenommen werden sollen, wird geschrieben. Das Schlüsselwort Set wird aus dem Englischen mit "set" übersetzt, und diese Zeile der Anweisung gibt die Namen der zu aktualisierenden Attribute und die entsprechenden neuen Attributwerte an. Es ist möglich, mehrere Attribute gleichzeitig in einer Anweisung zu aktualisieren, was sich aus der Verwendung des metalinguistischen Symbols ",...." ergibt. In der dritten Zeile nach dem Schlüsselwort Wo es wird eine Bedingung geschrieben, die genau anzeigt, welche Attribute dieser Basisrelation aktualisiert werden müssen; 3) Betreiber Löschenzulassen entfernen alle Tupel aus der Basisrelation. Lassen Sie uns seine vollständige Form in Pseudocode schreiben und die Bedeutung aller einzelnen syntaktischen Einheiten erklären: Löschen von Name der Basisbeziehung Wo Bedingung; Ключевое слово für kombiniert mit dem Namen des Betreibers Löschen übersetzt als "entfernen von". Und nach diesen Schlüsselwörtern in der ersten Zeile des Operators wird der Name der Basisrelation angegeben, aus der alle Tupel entfernt werden müssen. Und in der zweiten Zeile des Operators nach dem Schlüsselwort Wo ("wo") gibt die Bedingung an, durch die Tupel ausgewählt werden, die in unserer Basisbeziehung nicht mehr benötigt werden. Vorlesungsnummer 9. Funktionale Abhängigkeiten 1. Einschränkung der funktionellen Abhängigkeit Die Eindeutigkeitseinschränkung, die durch die Primär- und Kandidatenschlüsseldeklarationen einer Relation auferlegt wird, ist ein Sonderfall der mit dem Begriff verbundenen Einschränkung funktionale Abhängigkeiten. Betrachten Sie das folgende Beispiel, um das Konzept der funktionalen Abhängigkeit zu erläutern. Gegeben sei eine Relation, die Daten zu den Ergebnissen einer bestimmten Sitzung enthält. Das Schema dieser Beziehung sieht folgendermaßen aus: Sitzung (Rekordbuchnummer, Vollständiger Name, Ding, Klasse); Die Attribute „Notenbuchnummer“ und „Fach“ bilden einen zusammengesetzten (da zwei Attribute als Schlüssel deklariert sind) Primärschlüssel dieser Relation. Tatsächlich können diese beiden Attribute die Werte aller anderen Attribute eindeutig bestimmen. Allerdings muss die Relation neben der mit diesem Schlüssel verbundenen Eindeutigkeitsbedingung zwangsläufig der Bedingung unterliegen, dass ein Notenbuch auf eine bestimmte Person ausgestellt ist und daher insofern Tupel mit derselben Notenbuchnummer dieselben Werte enthalten müssen der Attribute "Nachname", "Vor- und zweiter Vorname".
Wenn wir nach einer bestimmten Sitzung das folgende Fragment einer bestimmten Datenbank von Studenten einer Bildungseinrichtung haben, dann sind in Tupeln mit einer Notenbuchnummer von 100 die Attribute "Nachname", "Vorname" und "Patronym" gleich, und die Attribute "Fach" und "Bewertung" - stimmen nicht überein (was verständlich ist, da es sich um unterschiedliche Fächer und Leistungen handelt). Das bedeutet, dass die Attribute „Nachname“, „Vorname“ und „Patronym“ funktional abhängig auf das Attribut "Notenbuchnummer", während die Attribute "Fach" und "Bewertung" funktional unabhängig sind. Somit kann die funktionale Abhängigkeit ist eine einwertige Abhängigkeit, die in Datenbankverwaltungssystemen tabelliert wird. Wir geben nun eine strenge Definition der funktionellen Abhängigkeit. Definition: Seien X, Y Unterschemata des Schemas der Relation S, definierend über das Schema S funktionales Abhängigkeitsdiagramm X → Y (lesen Sie "X Pfeil Y"). Lassen Sie uns definieren funktionale Abhängigkeitsbeschränkungen inv<X → Y> als Aussage, dass in Bezug auf Schema S zwei beliebige Tupel, die in der Projektion auf das Subschema X übereinstimmen, auch in der Projektion auf das Subschema Y übereinstimmen müssen. Lassen Sie uns dieselbe Definition in Formelform schreiben: Inv<X → Y> r(S) = t1, T2 ∈ r(t1[X] = t2[X] ⇒ t1[Y]=t2 [Y]), X, Y ⊆ S; Seltsamerweise verwendet diese Definition das Konzept einer unären Projektionsoperation, auf die wir bereits gestoßen sind. In der Tat, wie sonst, wenn Sie diese Operation nicht verwenden, um die Gleichheit von zwei Spalten der Beziehungstabelle und nicht von Zeilen zueinander zu zeigen? Daher haben wir in Bezug auf diese Operation geschrieben, dass die Koinzidenz von Tupeln in der Projektion auf ein Attribut oder mehrere Attribute (Subschema X) sicherlich die Koinzidenz der gleichen Spalten-Tupel auf Subschema Y zur Folge haben wird, falls Y davon funktional abhängig ist X. Interessant ist, dass man bei einer funktionalen Abhängigkeit von Y von X auch sagt, dass X funktional definiert Y oder was Y funktional abhängig auf X. In dem funktionalen Abhängigkeitsschema X → Y wird die Teilschaltung X als linke Seite und die Teilschaltung Y als rechte Seite bezeichnet. In der Datenbankentwurfspraxis wird das funktionale Abhängigkeitsschema der Kürze halber allgemein als funktionale Abhängigkeit bezeichnet. Ende der Definition. In dem speziellen Fall, wenn die rechte Seite der funktionalen Abhängigkeit, d. h. das Teilschema Y, mit dem gesamten Schema der Beziehung übereinstimmt, wird die Einschränkung der funktionalen Abhängigkeit zu einer Primär- oder Kandidatenschlüssel-Eindeutigkeitsbeschränkung. Wirklich: Inv r(S) = ∀ t1, T2 ∈ r(t1[K] = t2 [K] → t1(S) = t2(S)), K ⊆ S; Es ist nur so, dass Sie bei der Definition einer funktionalen Abhängigkeit anstelle des Unterschemas X die Bezeichnung des Schlüssels K und anstelle der rechten Seite der funktionalen Abhängigkeit, des Unterschemas Y, das gesamte Beziehungsschema S verwenden müssen, d.h. Tatsächlich ist die Einschränkung der Eindeutigkeit der Schlüssel von Beziehungen ein Sonderfall der Einschränkung der funktionalen Abhängigkeit, wenn die rechte Seite im gesamten Beziehungsschema gleiche Schemata der funktionalen Abhängigkeit ist. Hier sind Beispiele für das Bild der funktionalen Abhängigkeit: {Kontobuchnummer} → {Nachname, Vorname, Patronym}; {Notenbuchnummer, Fach} → {Note}; 2. Armstrongs Inferenzregeln Wenn irgendeine Basisrelation vektordefinierte funktionale Abhängigkeiten erfüllt, dann ist es mit Hilfe verschiedener spezieller Inferenzregeln möglich, andere funktionale Abhängigkeiten zu erhalten, die diese Basisrelation sicherlich erfüllt. Ein gutes Beispiel für solche Sonderregeln sind die Inferenzregeln von Armstrong. Aber bevor wir mit der Analyse der Armstrong-Inferenzregeln selbst fortfahren, lassen Sie uns ein neues metalinguistisches Symbol "├" einführen, das aufgerufen wird Ableitbarkeits-Meta-Assertion-Symbol. Dieses Symbol wird bei der Formulierung von Regeln zwischen zwei syntaktische Ausdrücke geschrieben und zeigt an, dass die Formel rechts davon von der Formel links davon abgeleitet ist. Formulieren wir nun die Armstrong-Inferenzregeln selbst in Form des folgenden Theorems. Satz. Es gelten die folgenden Regeln, die als Armstrongs Inferenzregeln bezeichnet werden. Inferenzregel 1. ├ X → X; Inferenzregel 2. X → Y├ X ∪ Z → Y; Inferenzregel 3. X → Y, Y ∪ W → Z ├ X ∪ W → Z; Hier sind X, Y, Z, W beliebige Unterschemata des Schemas der Relation S. Das Ableitbarkeits-Metaaussagesymbol trennt Listen von Prämissen und Listen von Behauptungen (Schlussfolgerungen). 1. Die erste Inferenzregel heißt "Reflexivität“ und lautet wie folgt: „Die Regel wird abgeleitet: „X bringt X funktional mit sich“. Dies ist die einfachste von Armstrongs Inferenzregeln. Sie ist buchstäblich aus dem Nichts abgeleitet. Es ist interessant festzustellen, dass eine funktionale Abhängigkeit aufgerufen wird, die sowohl einen linken als auch einen rechten Teil hat reflexiv. Gemäß der Reflexivitätsregel wird die Einschränkung der reflexiven Abhängigkeit automatisch durchgeführt. 2. Die zweite Inferenzregel heißt "Nachschub“ und lautet wie folgt: „Wenn X Y funktional bestimmt, dann wird die Regel abgeleitet: „Die Vereinigung der Teilschaltungen X und Z führt funktional zu Y.“ Die Vervollständigungsregel ermöglicht es Ihnen, die linke Seite der funktionalen Abhängigkeitsbeschränkung zu erweitern. 3. Die dritte Folgerungsregel heißt "Pseudotransitivität“ und lautet wie folgt: „Wenn Teilschaltung X funktional Teilschaltung Y nach sich zieht, und die Vereinigung von Teilschaltungen Y und W funktional Z zur Folge hat, dann wird die Regel abgeleitet: „Die Vereinigung von Teilschaltungen X und W bestimmt funktional Teilschaltung Z““. Die Pseudotransitivitätsregel verallgemeinert die Transitivitätsregel entsprechend dem Spezialfall W: = 0. Geben wir eine formale Notation dieser Regel: X→Y, Y→Z ├X→Z. Es sei darauf hingewiesen, dass die zuvor gegebenen Prämissen und Schlussfolgerungen in abgekürzter Form durch die Bezeichnungen der funktionalen Abhängigkeitsschemata dargestellt wurden. In erweiterter Form entsprechen sie den folgenden funktionalen Abhängigkeitsbeschränkungen. Inferenzregel 1. Inv r(S); Inferenzregel 2. Inv r(S) ⇒ Inv r(S); Inferenzregel 3. Inv r(S)&inv r(S) ⇒ Inv r(S); Ziehen Beweise diese Schlußregeln. 1. Beweis der Regel Reflexivität folgt direkt aus der Definition der funktionalen Abhängigkeitsbeschränkung, wenn Teilschema X durch Teilschaltung Y ersetzt wird. Nehmen Sie in der Tat die funktionale Abhängigkeitsbeschränkung: Inv r(S) und ersetzen X statt Y darin, erhalten wir: Inv r(S), und das ist die Reflexivitätsregel. Die Reflexivitätsregel ist bewiesen. 2. Beweis der Regel Nachschub Lassen Sie uns anhand von Diagrammen die funktionale Abhängigkeit veranschaulichen. Das erste Diagramm ist das Paketdiagramm: Prämisse: X → Y
Zweites Diagramm: Schlussfolgerung: X ∪ Z → Y
Seien die Tupel auf X ∪ Z gleich. Dann sind sie auf X gleich. Entsprechend der Prämisse sind sie auch auf Y gleich. Die Nachschubregel ist bewiesen. 3. Beweis der Regel Pseudotransitivität Wir werden auch auf Diagrammen veranschaulichen, die in diesem speziellen Fall drei sein werden. Das erste Diagramm ist die erste Prämisse: Prämisse 1: X → Y
Prämisse 2: Y ∪ W → Z
Und schließlich ist das dritte Diagramm das Abschlussdiagramm: Schlussfolgerung: X ∪ W → Z
Seien die Tupel gleich auf X ∪ W. Dann sind sie gleich auf X und W. Nach Prämisse 1 sind sie auch auf Y gleich, also sind sie nach Prämisse 2 auch auf Z gleich. Die Pseudotransitivitätsregel ist bewiesen. Alle Regeln sind bewiesen. 3. Abgeleitete Inferenzregeln Ein weiteres Beispiel für Regeln, mit denen man ggf. neue Regeln der funktionalen Abhängigkeit ableiten kann, sind die sog abgeleitete Inferenzregeln. Was sind diese Regeln, wie werden sie erlangt? Es ist bekannt, dass, wenn andere von einigen bereits bestehenden Regeln durch legitime logische Methoden abgeleitet werden, dann diese neuen Regeln genannt werden Derivate, kann zusammen mit den ursprünglichen Regeln verwendet werden. Es sollte besonders darauf hingewiesen werden, dass diese sehr willkürlichen Regeln „Ableitungen“ genau von den Armstrong-Inferenzregeln sind, die wir zuvor durchgegangen sind. Formulieren wir die abgeleiteten Regeln zur Ableitung funktionaler Abhängigkeiten in Form des folgenden Theorems. Theorem Die folgenden Regeln werden von Armstrongs Inferenzregeln abgeleitet. Inferenzregel 1. ├ X ∪ Z → X; Inferenzregel 2. X → Y, X → Z ├ X ∪ Y → Z; Inferenzregel 3. X → Y ∪ Z ├ X → Y, X → Z; Hier sind X, Y, Z, W, wie im vorigen Fall, beliebige Unterschemata des Schemas der Relation S. 1. Die erste abgeleitete Regel wird aufgerufen Trivialitätsregel und liest sich so: "Die Regel wird abgeleitet: 'Die Vereinigung der Teilkreise X und Z führt funktional zu X'". Eine funktionale Abhängigkeit, bei der die linke Seite eine Teilmenge der rechten Seite ist, wird aufgerufen trivial. Gemäß der Trivialitätsregel werden triviale Abhängigkeitsbeschränkungen automatisch erzwungen. Interessanterweise ist die Trivialitätsregel eine Verallgemeinerung der Reflexivitätsregel und könnte wie diese direkt aus der Definition der funktionalen Abhängigkeitsbedingung abgeleitet werden. Die Tatsache, dass diese Regel abgeleitet wird, ist kein Zufall und hängt mit der Vollständigkeit des Armstrongschen Regelsystems zusammen. Auf die Vollständigkeit von Armstrongs Regelwerk kommen wir später noch zu sprechen. 2. Die zweite abgeleitete Regel wird aufgerufen Additivitätsregel und lautet wie folgt: "Wenn Teilschaltung X funktional Teilschaltung Y bestimmt und X gleichzeitig funktional Z bestimmt, dann wird aus diesen Regeln die folgende Regel abgeleitet: "X bestimmt funktional die Vereinigung der Teilschaltungen Y und Z"". 3. Die dritte abgeleitete Regel wird aufgerufen Projektivitätsregel oder die RegelAdditivitätsumkehrSie lautet wie folgt: „Bestimmt der Teilkreis X funktional die Vereinigung der Teilkreise Y und Z, so leitet sich aus dieser Regel folgende Regel ab: „X bestimmt funktional den Teilkreis Y und gleichzeitig bestimmt X funktional den Teilkreis Z"", d.h. tatsächlich ist dies die abgeleitete Regel die umgekehrte Additivitätsregel. Es ist merkwürdig, dass die Regeln der Additivität und Projektivität, wie sie auf funktionale Abhängigkeiten mit denselben linken Teilen angewendet werden, es einem ermöglichen, die rechten Teile der Abhängigkeit zu kombinieren oder umgekehrt aufzuteilen. Bei der Konstruktion von Inferenzketten wird nach Formulierung aller Prämissen die Transitivitätsregel angewendet, um eine funktionale Abhängigkeit mit der rechten Seite in den Schluss aufzunehmen. Ziehen Beweise aufgelisteten willkürlichen Inferenzregeln. 1. Beweis der Regel Nebensächlichkeiten. Führen wir ihn wie alle folgenden Beweise Schritt für Schritt durch: 1) wir haben: X → X (aus Armstrongs Regel der Reflexivität des Schlusses); 2) weiter gilt: X ∪ Z → X (erhalten durch die Anwendung der Armstrongschen Inferenzvervollständigungsregel und dann als Folge des ersten Beweisschrittes). Die Trivialitätsregel ist bewiesen. 2. Wir führen einen schrittweisen Regelbeweis durch Additivität: 1) wir haben: X → Y (das ist Prämisse 1); 2) wir haben: X → Z (das ist Prämisse 2); 3) es gilt: Y ∪ Z → Y ∪ Z (aus Armstrongs Regel der Reflexivität des Schlusses); 4) wir haben: X ∪ Z → Y ∪ Z (erhalten durch Anwendung der Regel der Pseudotransitivität von Armstrongs Schluss und dann als Folge des ersten und dritten Beweisschrittes); 5) wir haben: X ∪ X → Y ∪ Z (erhalten durch Anwendung der Armstrongschen Regel der Pseudotransitivität des Schlusses, und folgt dann aus dem zweiten und vierten Schritt); 6) wir haben X → Y ∪ Z (folgt aus dem fünften Schritt). Die Additivitätsregel ist bewiesen. 3. Und schließlich werden wir einen Beweis der Regel konstruieren Projektivität: 1) wir haben: X → Y ∪ Z, X → Y ∪ Z (das ist eine Prämisse); 2) wir haben: Y → Y, Z → Z (abgeleitet unter Verwendung von Armstrongs Regel der Reflexivität des Schlusses); 3) wir haben: Y ∪ z → y, Y ∪ z → Z (erhalten aus Armstrongs Inferenzvervollständigungsregel und der Folgerung aus dem zweiten Schritt des Beweises); 4) wir haben: X → Y, X → Z (erhalten durch Anwendung der Pseudotransitivitätsregel von Armstrongs Schluss und dann als Folge des ersten und dritten Beweisschrittes). Die Projektivitätsregel ist bewiesen. Alle Ableitungsschlussregeln sind bewiesen. 4. Vollständigkeit des Armstrong-Regelsystems Sei F(S) eine gegebene Menge funktionaler Abhängigkeiten, die über dem Beziehungsschema S definiert sind. Bezeichnen wir mit inv die Einschränkung, die durch diesen Satz funktionaler Abhängigkeiten auferlegt wird. Schreiben wir es auf: Inv r(S) = ∀X → Y ∈F(S) [Inv r(S)]. Diese Menge von Einschränkungen, die durch funktionale Abhängigkeiten auferlegt werden, wird also wie folgt entschlüsselt: Für jede Regel aus dem System funktionaler Abhängigkeiten X → Y, die zu der Menge funktionaler Abhängigkeiten F(S) gehört, ist die Einschränkung funktionaler Abhängigkeiten inv r(S) definiert über die Menge der Relationen r(S). Eine Relation r(S) erfülle diese Einschränkung. Indem man Armstrongs Inferenzregeln auf die für die Menge F(S) definierten funktionalen Abhängigkeiten anwendet, kann man, wie wir bereits gesagt und bewiesen haben, neue funktionale Abhängigkeiten erhalten. Und, was bezeichnend ist, die Relation F(S) erfüllt automatisch die Beschränkungen dieser funktionalen Abhängigkeiten, wie aus der erweiterten Form der Armstrongschen Inferenzregeln ersichtlich ist. Erinnern Sie sich an die allgemeine Form dieser erweiterten Inferenzregeln: Inferenzregel 1. inv < X → X > r(S); Inferenzregel 2. Inv r(S) ⇒ inv<X ∪ Z → Y> r(S); Inferenzregel 3. Inv r(S) & inv <Y ∪ W → Z> r(S) ⇒ inv<X ∪ W→Z>; Um zu unserer Argumentation zurückzukehren, lassen Sie uns die Menge F(S) mit neuen Abhängigkeiten ergänzen, die daraus unter Verwendung der Armstrong-Regeln abgeleitet werden. Wir werden dieses Nachschubverfahren anwenden, bis wir keine neuen funktionalen Abhängigkeiten mehr erhalten. Als Ergebnis dieser Konstruktion erhalten wir einen neuen Satz funktionaler Abhängigkeiten namens Schließung setze F(S) und bezeichne F+(S). In der Tat ist ein solcher Name ziemlich logisch, weil wir persönlich durch eine lange Konstruktion die Menge bestehender funktionaler Abhängigkeiten auf sich selbst "geschlossen" haben und alle neuen funktionalen Abhängigkeiten hinzugefügt haben (daher das "+"), die sich aus den bestehenden ergeben. Es sollte beachtet werden, dass dieser Prozess der Konstruktion eines Abschlusses endlich ist, weil das Beziehungsschema selbst, auf dem all diese Konstruktionen ausgeführt werden, endlich ist. Es versteht sich von selbst, dass eine Schließung eine Obermenge der zu schließenden Menge ist (tatsächlich ist sie größer!) und sich in keiner Weise ändert, wenn sie erneut geschlossen wird. Wenn wir das eben Gesagte formelhaft aufschreiben, erhalten wir: F(S) ⊆ F+(S), [F+(S)]+= F+(S); Ferner folgt aus der bewiesenen Wahrheit (d. h. Legalität, Legitimität) von Armstrongs Inferenzregeln und der Definition des Abschlusses, dass jede Beziehung, die die Einschränkungen einer gegebenen Menge funktionaler Abhängigkeiten erfüllt, auch die Einschränkung der zum Abschluss gehörenden Abhängigkeit erfüllen wird . X → Y ∈ F+(S) ⇒ ∀r(S) [inv r(S) ⇒ Inv r(S)]; Der Vollständigkeitssatz von Armstrong für das System der Schlußfolgerungsregeln besagt also, daß externe Implikationen rechtmäßig und vertretbar durch Äquivalenz ersetzt werden können. (Auf den Beweis dieses Satzes gehen wir nicht ein, da der Beweisprozess selbst in unserer speziellen Vorlesung nicht so wichtig ist.) Vorlesung Nummer 10. Normalformen 1. Die Bedeutung der Normalisierung des Datenbankschemas Das Konzept, das wir in diesem Abschnitt betrachten werden, ist mit dem Konzept der funktionalen Abhängigkeiten verwandt, d. h. die Bedeutung der Normalisierung von Datenbankschemata ist untrennbar mit dem Konzept der Einschränkungen verbunden, die durch ein System funktionaler Abhängigkeiten auferlegt werden, und folgt weitgehend aus diesem Konzept. Der Ausgangspunkt jedes Datenbankentwurfs besteht darin, die Domäne als eine oder mehrere Beziehungen darzustellen, und bei jedem Entwurfsschritt wird ein Satz von Beziehungsschemas erstellt, der "erweiterte" Eigenschaften hat. Der Entwurfsprozess ist also ein Prozess der Normalisierung von Beziehungsmustern, wobei jede nachfolgende Normalform Eigenschaften hat, die in gewissem Sinne besser sind als die vorherige. Jede Normalform hat einen bestimmten Satz von Einschränkungen, und eine Beziehung befindet sich in einer bestimmten Normalform, wenn sie ihren eigenen Satz von Einschränkungen erfüllt. Ein Beispiel ist die Einschränkung der ersten Normalform – die Werte aller Attribute der Relation sind atomar. In der relationalen Datenbanktheorie wird üblicherweise folgende Abfolge von Normalformen unterschieden: 1) erste Normalform (1 NF); 2) zweite Normalform (2 NF); 3) dritte Normalform (3 NF); 4) Boyce-Codd-Normalform (BCNF); 5) vierte Normalform (4 NF); 6) Fünfte Normalform oder Projection-Join-Normalform (5 NF oder PJ/NF). (Diese Vorlesung beinhaltet eine ausführliche Diskussion der ersten vier Normalformen der Grundrelationen, daher gehen wir auf die vierte und fünfte Normalform nicht im Detail ein.) Die Haupteigenschaften von Normalformen sind wie folgt: 1) jede folgende Normalform ist in gewissem Sinne besser als die vorhergehende Normalform; 2) Beim Übergang zur nächsten Normalform bleiben die Eigenschaften der vorherigen Normalformen erhalten. Der Entwurfsprozess basiert auf der Methode der Normalisierung, d.h. der Zerlegung einer Relation, die sich in der vorherigen Normalform befindet, in zwei oder mehr Relationen, die die Anforderungen der nächsten Normalform erfüllen (wir werden darauf stoßen, wenn wir diese selbst normieren müssen während wir das Material durchgehen) oder eine andere grundlegende Beziehung). Wie im Abschnitt über das Erstellen von Basisbeziehungen erwähnt, erlegen die gegebenen Sätze von funktionalen Abhängigkeiten den Schemata von Basisbeziehungen angemessene Beschränkungen auf. Diese Einschränkungen werden im Allgemeinen auf zwei Arten implementiert: 1) deklarativ, d. h. durch Deklaration verschiedener Arten von Primär-, Kandidaten- und Fremdschlüsseln in der Basisrelation (dies ist die am weitesten verbreitete Methode); 2) prozedural, d. h. durch das Schreiben von Programmcode (unter Verwendung der oben erwähnten sogenannten Trigger). Mit Hilfe einfacher Logik können Sie verstehen, was der Sinn der Normalisierung von Datenbankschemata ist. Datenbanken zu normalisieren oder Datenbanken in eine normale Form zu bringen bedeutet, solche Schemata grundlegender Beziehungen zu definieren, um die Notwendigkeit, Programmcode zu schreiben, zu minimieren, die Datenbankleistung zu erhöhen und die Aufrechterhaltung der Datenintegrität durch Zustand und referenzielle Integrität zu erleichtern. Das heißt, den Code und die Arbeit damit für Entwickler und Benutzer so einfach und bequem wie möglich zu gestalten. Um den Betrieb einer nicht normalisierten und einer normalisierten Datenbank im Vergleich visuell zu demonstrieren, betrachten Sie das folgende Beispiel. Lassen Sie uns eine Basisrelation haben, die Informationen über die Ergebnisse der Prüfungssitzung enthält. Über eine solche Datenbank haben wir uns bereits Gedanken gemacht. somit Option 1 Datenbankschemata. Sitzung (Rekordbuchnummer, Vollständiger Name, Ding, Klasse) In dieser Beziehung wird, wie Sie aus dem Bild des Basisbeziehungsschemas sehen können, ein zusammengesetzter Primärschlüssel definiert: Primärschlüssel (Klassenbuchnummer, Fach); Auch diesbezüglich wird ein System funktionaler Abhängigkeiten festgelegt: {Kontobuchnummer} → {Nachname, Vorname, Patronym}; Hier ist eine tabellarische Ansicht eines kleinen Fragments einer Datenbank mit diesem Beziehungsschema. Wir haben dieses Fragment bereits verwendet, um die Einschränkungen funktionaler Abhängigkeiten zu betrachten, daher wird es für uns ziemlich einfach sein, dieses Thema anhand seines Beispiels zu verstehen.
Hier, um die Integrität der Daten nach Staat zu wahren, d.h. um die Einschränkung des Systems der funktionalen Abhängigkeit {Klassenbuchnummer} → {Nachname, Vorname, Patronym} zu erfüllen, wenn beispielsweise der Nachname geändert wird notwendig, alle Tupel dieser Grundrelation durchzusehen und die notwendigen Änderungen nacheinander einzugeben. Da dies jedoch ein ziemlich umständlicher und zeitaufwändiger Prozess ist (insbesondere wenn es sich um eine Datenbank einer großen Bildungseinrichtung handelt), sind die Entwickler von Datenbankverwaltungssystemen zu dem Schluss gekommen, dass dieser Prozess automatisiert werden muss , automatisch gemacht. Nun kann die Kontrolle über die Erfüllung dieser (und jeder anderen) funktionalen Abhängigkeit automatisch organisiert werden, indem verschiedene Schlüssel in der Basisrelation korrekt deklariert werden und die sogenannte Dekomposition (d. h. das Zerlegen von etwas in mehrere unabhängige Teile) dieser erfolgt Beziehung. Unterteilen wir also unser vorhandenes Beziehungsschema „Sitzung“ in zwei Schemas: das Schema „Studenten“, das nur Informationen über die Schüler einer bestimmten Bildungseinrichtung enthält, und das Schema „Sitzung“, das Informationen über die letzte vergangene Sitzung enthält. Und dann werden wir die Schlüssel so deklarieren, dass wir alle notwendigen Informationen leicht erhalten können. Lassen Sie uns zeigen, wie diese neuen Beziehungsschemata mit ihren Schlüsseln aussehen werden. Option 2 Datenbankschemata. Studenten (Rekordbuchnummer, Vollständiger Name), Primärschlüssel (Notenbuchnummer). Sitzung (Rekordbuchnummer, Betreff, Klasse), Primärschlüssel (Notenbuchnummer, Fach), Fremdschlüssel (Notenbuchnummer) verweist auf Studenten (Notenbuchnummer). Was haben wir jetzt? In Bezug auf „Schüler“ bestimmt der Primärschlüssel „Notenbuchnummer“ funktional die anderen drei Attribute: „Nachname“, „Vorname“ und „Patronym“. Und in Bezug auf „Session“ definiert der zusammengesetzte Primärschlüssel „Gradebook No., Subject“ auch eindeutig, also buchstäblich funktional, das letzte Attribut dieses Beziehungsschemas – „Score“. Und die Verbindung zwischen diesen beiden Relationen ist hergestellt: Sie erfolgt über den externen Schlüssel der Relation „Session“ „Gradebook No“, der auf das gleichnamige Attribut in der Relation „Students“ verweist und auf Wunsch liefert alle nötigen Informationen. Lassen Sie uns nun zeigen, wie die Relationen, die durch die Tabellen dargestellt werden, die der zweiten Option zum Spezifizieren der entsprechenden Datenbankschemata entsprechen, aussehen werden.
Somit sehen wir, dass das Ziel der Normalisierung in Bezug auf die durch funktionale Abhängigkeiten auferlegten Beschränkungen die Notwendigkeit ist, jeder Datenbank die erforderlichen funktionalen Abhängigkeiten aufzuerlegen, indem verschiedene Arten von Primär-, Kandidaten- und Fremdschlüsseln der Basisbeziehungen verwendet werden. 2. Erste Normalform (1NF) In den frühen Stadien des Datenbankentwurfs und der Entwicklung von Datenbankverwaltungsschemata wurden einfache und eindeutige Attribute als die produktivsten und rationalsten Codeeinheiten verwendet. Dann verwendeten sie zusammen mit einfachen und zusammengesetzten Attributen sowie zusammen mit einwertigen und mehrwertigen Attributen. Lassen Sie uns die Bedeutung jedes dieser Konzepte erklären. Zusammengesetzte AttributeIm Gegensatz zu einfachen Attributen handelt es sich um Attribute, die aus mehreren einfachen Attributen bestehen. Mehrwertige AttributeIm Gegensatz zu einwertigen Attributen handelt es sich um Attribute, die mehrere Werte darstellen. Hier sind Beispiele für einfache, zusammengesetzte, einwertige und mehrwertige Attribute. Betrachten Sie die folgende Tabelle, die die Beziehung darstellt:
Dabei ist das Attribut „Telefon“ einfach, eindeutig und das Attribut „Adresse“ einfach, aber mehrwertig. Betrachten Sie nun eine andere Tabelle mit anderen Attributen:
In dieser durch die Tabelle dargestellten Beziehung ist das Attribut „Telefone“ einfach, aber mehrwertig, und das Attribut „Adressen“ ist sowohl zusammengesetzt als auch mehrwertig. Generell sind verschiedene Kombinationen von einfachen oder zusammengesetzten Attributen möglich. In verschiedenen Fällen können Tabellen, die Beziehungen darstellen, im Allgemeinen so aussehen:
Beim Normalisieren grundlegender Beziehungsschemata können Programmierer eine der vier häufigsten Arten von Normalformen verwenden: erste Normalform (1NF), zweite Normalform (2NF), dritte Normalform (3NF) oder Boyce-Codd-Normalform (NFBC). . Zur Verdeutlichung: Die Abkürzung NF ist eine Abkürzung für den englischen Ausdruck Normal Form. Formal gibt es neben den oben genannten noch andere Arten von Normalformen, aber die oben genannten sind eine der beliebtesten. Derzeit versuchen Datenbankentwickler, zusammengesetzte und mehrwertige Attribute zu vermeiden, um das Schreiben von Code nicht zu erschweren, seine Struktur nicht zu überladen und Benutzer nicht zu verwirren. Aus diesen Überlegungen folgt logischerweise die Definition der ersten Normalform. Definition. Jede Basisbeziehung ist in erste Normalform genau dann, wenn das Schema dieser Relation nur einfache und nur einwertige Attribute und notwendigerweise mit derselben Semantik enthält. Betrachten Sie ein Beispiel, um die Unterschiede zwischen normalisierten und nicht normalisierten Beziehungen visuell zu erklären. Angenommen, es gibt eine nicht normalisierte Beziehung mit dem folgenden Schema. somit Option 1 Beziehungsschemata mit einem darauf definierten einfachen Primärschlüssel: Angestellte (Personal Nummer, Nachname, Vorname, Patronym, Positionscode, Telefone, Datum der Aufnahme oder Entlassung); Primärschlüssel (Personalnummer); Lassen Sie uns auflisten, welche Fehler es in diesem Beziehungsschema gibt, d.h. wir werden diejenigen Zeichen benennen, die dieses Schema richtig nicht normalisiert machen: 1) das Attribut „Nachname Vorname Patronym“ ist zusammengesetzt, d. h. aus heterogenen Elementen zusammengesetzt; 2) das Attribut "Telefone" ist mehrwertig, d. h. sein Wert ist eine Menge von Werten; 3) Das Attribut „Datum der Aufnahme oder Entlassung“ hat keine eindeutige Semantik, d. h. im letzteren Fall ist nicht klar, welches Datum eingetragen ist. Wenn beispielsweise ein zusätzliches Attribut eingeführt wird, um die Bedeutung eines Datums genauer zu definieren, dann ist der Wert für dieses Attribut zwar semantisch eindeutig, aber es bleibt trotzdem möglich, nur eines der angegebenen Datumsangaben für jeden Mitarbeiter zu speichern. Was muss getan werden, um diese Beziehung in eine normale Form zu bringen? Erstens ist es notwendig, zusammengesetzte Attribute in einfache aufzuteilen, um diese sehr zusammengesetzten Attribute sowie Attribute mit zusammengesetzter Semantik auszuschließen. Und zweitens ist es notwendig, diese Relation zu zerlegen, d. h. in mehrere neue unabhängige Relationen zu zerlegen, um mehrwertige Attribute auszuschließen. Somit erhalten wir unter Berücksichtigung all dessen, nachdem wir die Relation „Employees“ auf die erste Normalform oder 1NF durch Zerlegung reduziert haben, ein System der folgenden Relationen mit darauf gesetzten Primär- und Fremdschlüsseln. somit Option 2 Beziehungen: Angestellte (Personal Nummer, Nachname, Vorname, Patronym, Positionscode, Aufnahmedatum, Entlassungsdatum); Primärschlüssel (Personalnummer); Telefone (Personalnummer, Telefon); Primärschlüssel (Personalnummer, Telefon); Fremdschlüssel (Personalnummer) Referenzen Mitarbeiter (Personalnummer); Was sehen wir also? Das zusammengesetzte Attribut "Nachname Vorname Patronym" ist in unserer Beziehung nicht mehr vorhanden, stattdessen gibt es drei einfache Attribute "Nachname", "Vorname" und "Patronym", daher wurde dieser Grund für die "Abnormalität" der Beziehung ausgeschlossen . Außerdem haben wir statt des Attributs mit unklarer Semantik „Einstellungs- bzw. Entlassungsdatum“ nun zwei Attribute „Aufnahmedatum“ und „Entlassungsdatum“, die jeweils eine eindeutige Semantik haben. Damit ist auch der zweite Grund dafür, dass unsere „Mitarbeiter“-Beziehung nicht in Normalform ist, sicher eliminiert. Und schließlich ist der letzte Grund, warum die Relation „Mitarbeiter“ nicht normalisiert wurde, das Vorhandensein des mehrwertigen Attributs „Telefone“. Um dieses Attribut loszuwerden, war es notwendig, die gesamte Beziehung zu zerlegen. Als Ergebnis dieser Zerlegung wurde das Attribut „Telefone“ aus der ursprünglichen Relation „Mitarbeiter“ im Allgemeinen ausgeschlossen, aber es wurde eine zweite Relation „Telefone“ gebildet, in der es zwei Attribute gibt: „Personalnummer des Mitarbeiters“ und „Telefon“. ", also alle Attribute - wieder einfach, die Bedingung der Zugehörigkeit zur ersten Normalform ist erfüllt. Diese Attribute "Mitarbeiternummer" und "Telefon" bilden einen zusammengesetzten Primärschlüssel der Beziehung "Telefone" und das Attribut "Mitarbeiternummer" wiederum ist ein Fremdschlüssel, der auf das gleichnamige Attribut in der "Employees "Beziehung, d.h. in der Beziehung "Telefone" ist das Attribut des Primärschlüssels "Personalnummer" auch ein Fremdschlüssel, der auf den Primärschlüssel der Beziehung "Mitarbeiter" verweist. Somit wird eine Verknüpfung zwischen den beiden Beziehungen bereitgestellt. Über diesen Link kann man sich ohne großen Aufwand die gesamte Liste seiner Telefone nach Personalnummer eines beliebigen Mitarbeiters anzeigen lassen, ohne auf die Verwendung zusammengesetzter Attribute zurückzugreifen. Beachten Sie, dass, wenn es funktionale Abhängigkeiten in Bezug auf das System gäbe, nach all den oben genannten Transformationen die Normalisierung nicht abgeschlossen wäre. In diesem speziellen Beispiel gibt es jedoch keine funktionalen Abhängigkeitsbeschränkungen, sodass eine weitere Normalisierung dieser Beziehung nicht erforderlich ist. 3. Zweite Normalform (2NF) Durch die zweite Normalform oder 2NF werden strengere Anforderungen an Beziehungen gestellt. Denn die Definition der zweiten Normalform von Relationen impliziert im Gegensatz zur ersten Normalform das Vorhandensein eines Systems von Einschränkungen funktionaler Abhängigkeiten. Definition. Die Basisrelation ist in zweite Normalform relativ zu einem gegebenen Satz von funktionalen Abhängigkeiten genau dann, wenn es sich in der ersten Normalform befindet und zusätzlich jedes Nicht-Schlüsselattribut vollständig funktional von jedem Schlüssel abhängig ist. Bei dieser Definition Nicht-Schlüsselattribut ist ein beliebiges Beziehungsattribut, das in keinem Primär- oder Kandidatenschlüssel der Beziehung enthalten ist. Eine vollständige funktionale Abhängigkeit von einem Schlüssel impliziert keine funktionale Abhängigkeit von irgendeinem Teil dieses Schlüssels. Daher müssen wir nun bei der Normalisierung einer Relation auch die Erfüllung der Bedingungen dafür überwachen, dass die Relation in der ersten Normalform vorliegt, also darauf achten, dass ihre Eigenschaften einfach und eindeutig sind, sowie die Erfüllung der zweiten Bedingung bzgl die Einschränkungen funktionaler Abhängigkeiten. Es ist klar, dass Beziehungen mit einfachen Schlüsseln (Primär und Kandidat) sicherlich in zweiter Normalform sind. Tatsächlich scheint in diesem Fall eine Abhängigkeit von einem Teil des Schlüssels einfach nicht möglich, weil der Schlüssel einfach keine separaten Teile hat. Betrachten Sie nun, wie in der Passage des vorherigen Themas, ein Beispiel für ein nicht normalisiertes Beziehungsschema und den Normalisierungsprozess selbst. somit Option 1 Beziehungsschemata: Zielgruppen (Gebäude-Nr., Auditorium-Nr., Fläche qm m, Nr. Dienstkommandant des Korps); Primärschlüssel (Korpusnummer, Publikumsnummer); Darüber hinaus wird das folgende System der funktionalen Abhängigkeit definiert: {Nr. des Korps} → {Nr. des Dienstkommandanten des Korps}; Was sehen wir? Alle Bedingungen dafür, dass diese Relation „Audience“ in der ersten Normalform bleibt, sind erfüllt, weil jedes einzelne Attribut dieser Relation eindeutig und einfach ist. Aber die Bedingung, dass jedes Nicht-Schlüsselelement funktional vollständig vom Schlüssel abhängig sein muss, ist nicht erfüllt. Wieso den? Ja, denn das Attribut „Stabskommandant des Korps“ hängt funktional nicht vom zusammengesetzten Schlüssel „Korpsnummer, Publikumsnummer“ ab, sondern von einem Teil dieses Schlüssels, also vom Attribut "Nr. des Korps". Denn die Korpsnummer bestimmt ja ganz und gar, welcher Kommandant ihr zugeordnet ist, und die Personalnummer des Korpskommandanten kann wiederum nicht von irgendwelchen Saalnummern abhängen. Somit wird zur Hauptaufgabe unserer Normalisierung die Aufgabe, dafür zu sorgen, dass die Schlüssel so verteilt werden, dass insbesondere das Attribut „Nr. Um dies zu erreichen, müssen wir wieder, wie im vorigen Absatz, die Zerlegung der Relation anwenden. Also, das folgende System von Beziehungen, das ist Option 2 Die Beziehung „Publikum“ wurde einfach aus der ursprünglichen Beziehung erhalten, indem sie in mehrere neue unabhängige Beziehungen zerlegt wurde: Korps (Rumpf Nr., Nummer des Personalkommandanten des Korps); Primärschlüssel (Fallnummer); Zielgruppen (Gebäude-Nr., Auditorium-Nr., Fläche qm m); Primärschlüssel (Korpusnummer, Publikumsnummer); Fremdschlüssel (Fallnummer) Referenzen Fälle (Fallnummer); Was sehen wir jetzt? Bezüglich des „Korpus“-Nichtschlüsselattributs „Personalnummer des Korpskommandanten“ hängt es voll funktionsfähig vom Primärschlüssel „Korpsnummer“ ab. Hier ist die Bedingung zum Auffinden der Relation in der zweiten Normalform voll erfüllt. Kommen wir nun zur Betrachtung der zweiten Relation – „Publikum“. In Bezug auf „Publikum“ ist das Primärschlüsselattribut „Fall #“ auch ein Fremdschlüssel, der sich auf den Primärschlüssel der „Fall“-Beziehung bezieht. Insofern ist das Nichtschlüsselattribut „Fläche mXNUMX“ vollständig abhängig vom gesamten zusammengesetzten Primärschlüssel „Gebäude #, Hörsaal #“ und nicht, nicht einmal von einem seiner Teile. Durch die Zerlegung der ursprünglichen Beziehung sind wir also zu dem Schluss gekommen, dass alle Bedingungen aus der Definition der zweiten Normalform vollständig erfüllt sind. In diesem Beispiel werden alle funktionalen Abhängigkeitsanforderungen durch die Deklaration von Primärschlüsseln (hier keine Kandidatenschlüssel) und Fremdschlüsseln auferlegt. Daher ist keine weitere Normalisierung erforderlich. 4. Dritte Normalform (3NF) Die nächste Normalform, die wir uns ansehen werden, ist die dritte Normalform (oder 3NF). Im Gegensatz zur ersten Normalform sowie zur zweiten Normalform impliziert die dritte die Zuordnung eines Systems funktionaler Abhängigkeiten zusammen mit der Relation. Formulieren wir, welche Eigenschaften eine Relation haben muss, damit sie auf die dritte Normalform reduziert werden kann. Definition. Die Basisrelation ist in dritte Normalform in Bezug auf einen gegebenen Satz von funktionalen Abhängigkeiten genau dann, wenn es sich in der zweiten Normalform befindet und jedes Nicht-Schlüsselattribut vollständig funktional nur von Schlüsseln abhängig ist. Somit sind die Anforderungen der dritten Normalform stärker als die Anforderungen der ersten und zweiten Normalform, sogar kombiniert. Tatsächlich hängt in der dritten Normalform jedes Nicht-Schlüssel-Attribut vom Schlüssel ab, und vom gesamten Schlüssel, und von nichts anderem als dem Schlüssel. Lassen Sie uns den Prozess veranschaulichen, eine nicht normalisierte Beziehung in die dritte Normalform zu bringen. Betrachten Sie dazu ein Beispiel: eine Relation, die sich nicht in der dritten Normalform befindet. somit Option 1 Schemata der Beziehung "Mitarbeiter": Angestellte (Personal Nummer, Nachname, Vorname, Vatersname, Positionscode, Gehalt); Primärschlüssel (Personalnummer); Zusätzlich wird über diese Beziehung „Mitarbeiter“ folgendes System funktionaler Abhängigkeiten gesetzt: {Positionscode} → {Gehalt}; Tatsächlich hängt die Höhe des Gehalts, d. h. die Höhe des Lohns, in der Regel direkt von der Position und damit von ihrem Code in der entsprechenden Datenbank ab. Deshalb liegt diese Beziehung „Mitarbeiter“ nicht in dritter Normalform vor, denn es zeigt sich, dass das Nicht-Schlüsselattribut „Gehalt“ vollständig funktional vom Attribut „Positionskennzeichen“ abhängig ist, obwohl dieses Attribut kein Schlüsselattribut ist. Merkwürdigerweise wird jede Beziehung auf die dritte Normalform genauso reduziert wie auf die beiden Formen vor dieser, nämlich durch Zerlegung. Nachdem wir die Relation "Mitarbeiter" zerlegt haben, erhalten wir das folgende System neuer unabhängiger Relationen: somit Option 2 Schemata der Beziehung "Mitarbeiter": Positionen (Positionscode, Gehalt); Primärschlüssel (Positionscode); Angestellte (Personal Nummer, Nachname, Vorname, Vatersname, Positionscode); Primärschlüssel (Positionscode); Fremdschlüssel (Positionscode) referenziert Positionen (Positionscode); Wie wir nun sehen, ist in Bezug auf „Position“ das Nicht-Schlüsselattribut „Gehalt“ vollständig funktional abhängig von dem einfachen Primärschlüssel „Positionscode“ und nur von diesem Schlüssel. Beachten Sie, dass in Bezug auf „Mitarbeiter“ alle vier Nicht-Schlüsselattribute „Nachname“, „Vorname“, „Patronym“ und „Positionscode“ voll funktionsfähig vom einfachen Primärschlüssel „Anstellungsnummer“ abhängig sind. Das Attribut „Positions-ID“ ist insofern ein Fremdschlüssel, der auf den Primärschlüssel der Beziehung „Positionen“ verweist. In diesem Beispiel werden alle Anforderungen durch Deklaration einfacher Primär- und Fremdschlüssel auferlegt, sodass keine weitere Normalisierung erforderlich ist. Es ist interessant und nützlich zu wissen, dass man sich in der Praxis meist darauf beschränkt, Datenbanken in die dritte Normalform zu bringen. Gleichzeitig dürfen einige funktionale Abhängigkeiten von Schlüsselattributen von anderen Attributen derselben Beziehung nicht auferlegt werden. Die Unterstützung für solche nicht standardmäßigen funktionalen Abhängigkeiten wird unter Verwendung der zuvor erwähnten Trigger implementiert (dh prozedural, indem der entsprechende Programmcode geschrieben wird). Darüber hinaus müssen Trigger mit Tupeln dieser Relation arbeiten. 5. Boyce-Codd-Normalform (NFBC) Die Boyce-Codd-Normalform folgt in "Komplexität" direkt nach der dritten Normalform. Daher wird die Boyce-Codd-Normalform manchmal auch einfach genannt starke dritte Normalform (oder verstärkt 3 NF). Warum ist sie verstärkt? Wir formulieren die Definition der Boyce-Codd-Normalform: Definition. Die Basisrelation ist in Boyce-Normalform - Kodd genau dann, wenn es sich in der dritten Normalform befindet, und nicht nur jedes Nicht-Schlüsselattribut vollständig funktional von jedem Schlüssel abhängig ist, sondern jedes Schlüsselattribut vollständig funktional von jedem Schlüssel abhängig sein muss. Somit gilt auch für Schlüsselattribute die Forderung, dass Nichtschlüsselattribute tatsächlich vom gesamten Schlüssel und nur vom Schlüssel abhängen. In einer Relation in Boyce-Codd-Normalform werden alle funktionalen Abhängigkeiten innerhalb der Relation durch die Deklaration von Schlüsseln auferlegt. Bei der Reduzierung von Datenbankrelationen auf die Boyce-Codd-Form sind jedoch Situationen möglich, in denen sich Abhängigkeiten zwischen den Attributen verschiedener Relationen als nicht auferlegte funktionale Abhängigkeiten herausstellen. Solche funktionalen Abhängigkeiten mit Triggern zu unterstützen, die auf Tupeln unterschiedlicher Relationen arbeiten, ist schwieriger als im Fall der dritten Normalform, wenn Trigger auf Tupeln einer einzelnen Relation operieren. Die Praxis des Entwurfs von Datenbankverwaltungssystemen hat unter anderem gezeigt, dass es nicht immer möglich ist, den Grundbezug auf die Boyce-Codd-Normalform zu bringen. Der Grund für die erwähnten Anomalien liegt darin, dass die Anforderungen der zweiten Normalform und der dritten Normalform keine minimale funktionale Abhängigkeit vom Primärschlüssel von Attributen erforderten, die Komponenten anderer möglicher Schlüssel sind. Dieses Problem wird durch die Normalform gelöst, die historisch als Boyce-Codd-Normalform bezeichnet wird und eine Verfeinerung der dritten Normalform im Falle des Vorhandenseins mehrerer überlappender möglicher Schlüssel ist. Im Allgemeinen macht die Normalisierung des Datenbankschemas Datenbankaktualisierungen für das Datenbankverwaltungssystem effizienter, da sie die Anzahl der Überprüfungen und Sicherungen reduziert, die die Datenbankintegrität aufrechterhalten. Beim Entwerfen einer relationalen Datenbank erreichen Sie fast immer die zweite Normalform aller Beziehungen in der Datenbank. In Datenbanken, die häufig aktualisiert werden, versuchen sie normalerweise, die dritte Normalform der Beziehung bereitzustellen. Die Boyce-Codd-Normalform erhält viel weniger Aufmerksamkeit, da in der Praxis Situationen, in denen eine Relation mehrere zusammengesetzte überlappende Kandidatenschlüssel hat, selten sind. All dies macht die Verwendung der Boyce-Codd-Normalform bei der Entwicklung von Programmcode nicht sehr bequem, daher beschränken sich Entwickler, wie bereits erwähnt, in der Praxis normalerweise darauf, ihre Datenbanken in die dritte Normalform zu bringen. Es hat jedoch auch seine eigene, ziemlich merkwürdige Eigenschaft. Der Punkt ist, dass Situationen, in denen eine Relation in der dritten Normalform, aber nicht in der Boyce-Codd-Normalform vorliegt, in der Praxis äußerst selten sind, d Fremdschlüssel, sodass Trigger zur Unterstützung funktionaler Abhängigkeiten nicht erforderlich sind. Der Bedarf an Triggern bleibt jedoch bestehen, um Integritätsbeschränkungen zu unterstützen, die nicht durch funktionale Abhängigkeiten verknüpft sind. 6. Verschachtelung von Normalformen Was bedeutet Verschachtelung von Normalformen? Verschachtelung von Normalformen - dies ist das Verhältnis der Konzepte geschwächter und verstärkter Formen zueinander. Die Verschachtelung von Normalformen ergibt sich vollständig aus deren jeweiligen Definitionen. Stellen wir uns ein Diagramm vor, das die Verschachtelungsbeziehung der uns bekannten Normalformen veranschaulicht:
Lassen Sie uns anhand konkreter Beispiele die Begriffe abgeschwächte und verstärkte Normalformen im Verhältnis zueinander erläutern. Die erste Normalform ist gegenüber der zweiten Normalform (und auch gegenüber allen anderen Normalformen) abgeschwächt. Wenn wir uns an die Definitionen aller Normalformen erinnern, die wir durchgegangen sind, können wir sehen, dass die Anforderungen jeder Normalform die Anforderung beinhalteten, zur ersten Normalform zu gehören (schließlich war sie in jeder nachfolgenden Definition enthalten). Die zweite Normalform ist stärker als die erste Normalform, aber schwächer als die dritte Normalform und die Boyce-Codd-Normalform. Tatsächlich ist die Zugehörigkeit zur zweiten Normalform in der Definition der dritten eingeschlossen, und die zweite Form selbst schließt wiederum die erste Normalform ein. Die Boyce-Codd-Normalform wird nicht nur gegenüber der dritten Normalform verstärkt, sondern auch gegenüber allen anderen davor. Und die dritte Normalform wiederum ist nur gegenüber der Boyce-Codd-Normalform abgeschwächt. Vorlesung Nr. 11. Entwerfen von Datenbankschemata Das gebräuchlichste Mittel zum Abstrahieren von Datenbankschemata beim Entwerfen auf logischer Ebene ist das sogenannte Entity-Relationship-Modell. Es wird manchmal auch genannt ER-Modell, wobei ER eine Abkürzung des englischen Ausdrucks Entity - Relationship ist, was wörtlich übersetzt "Entität - Beziehung" bedeutet. Die Elemente solcher Modelle sind Entitätsklassen, ihre Attribute und Beziehungen. Wir werden Erklärungen und Definitionen für jedes dieser Elemente geben. Entitätsklasse ist wie eine methodenlose Klasse von Objekten im Sinne der objektorientierten Programmierung. Beim Wechsel zur physikalischen Schicht werden Entitätsklassen in grundlegende relationale Datenbankbeziehungen für bestimmte Datenbankverwaltungssysteme umgewandelt. Sie haben, wie die Grundbeziehungen selbst, ihre eigenen Attribute. Lassen Sie uns eine genauere und strengere Definition der eben gegebenen Objekte geben. Klasse wird eine benannte Beschreibung einer Sammlung von Objekten mit gemeinsamen Attributen, Operationen, Beziehungen und Semantik genannt. Grafisch wird eine Klasse meist als Rechteck dargestellt. Jede Klasse muss einen Namen (eine Textzeichenfolge) haben, der sie eindeutig von allen anderen Klassen unterscheidet. Klassenattribut ist eine benannte Eigenschaft einer Klasse, die den Satz von Werten beschreibt, die Instanzen dieser Eigenschaft annehmen können. Eine Klasse kann beliebig viele Attribute haben (insbesondere keine Attribute). Eine durch ein Attribut ausgedrückte Eigenschaft ist eine Eigenschaft der modellierten Entität, die allen Objekten der gegebenen Klasse gemeinsam ist. Ein Attribut ist also eine Abstraktion des Zustands eines Objekts. Jedes Attribut eines beliebigen Klassenobjekts muss einen Wert haben. Die sogenannten Relationen werden durch die Deklaration von Fremdschlüsseln realisiert (ähnliche Phänomene sind uns bereits begegnet), d.h. bei Relationen werden Fremdschlüssel deklariert, die auf Primär- oder Kandidatenschlüssel einer anderen Relation verweisen. Und dadurch werden mehrere verschiedene unabhängige Grundbeziehungen zu einem einzigen System namens Datenbank "verknüpft". Weiterhin wird das Diagramm, das die grafische Grundlage des Entity-Relationship-Modells bildet, mit der einheitlichen Modellierungssprache UML dargestellt. Der objektorientierten Modellierungssprache UML (oder Unified Modeling Language) sind sehr viele Bücher gewidmet, von denen viele ins Russische übersetzt (und einige von russischen Autoren geschrieben) wurden. Im Allgemeinen erlaubt Ihnen UML, verschiedene Arten von Systemen zu modellieren: reine Software, reine Hardware, Software-Hardware, gemischt, explizit einschließlich menschlicher Aktivitäten usw. Aber unter anderem, wie wir bereits erwähnt haben, wird die UML-Sprache aktiv verwendet, um relationale Datenbanken zu entwerfen. Dafür wird ein kleiner Teil der Sprache (Klassendiagramme) verwendet, und auch dann nicht vollständig. Aus Sicht des relationalen Datenbankdesigns unterscheiden sich die Modellierungsfähigkeiten nicht allzu sehr von denen von ER-Diagrammen. Wir wollten auch zeigen, dass sich im Kontext des relationalen Datenbankdesigns strukturelle Entwurfsmethoden basierend auf der Verwendung von ER-Diagrammen und objektorientierte Methoden basierend auf der Verwendung der UML-Sprache hauptsächlich nur in der Terminologie unterscheiden. Das ER-Modell ist konzeptionell einfacher als UML, es hat weniger Konzepte, Begriffe und Anwendungsmöglichkeiten. Und das ist verständlich, da verschiedene Versionen von ER-Modellen speziell entwickelt wurden, um das Design relationaler Datenbanken zu unterstützen, und ER-Modelle fast keine Funktionen enthalten, die über die tatsächlichen Bedürfnisse eines Designers relationaler Datenbanken hinausgehen. Die UML gehört zur Objektwelt. Diese Welt ist viel komplizierter (wenn Sie so wollen, unverständlicher, verwirrender) als die relationale Welt. Da die UML für die einheitliche objektorientierte Modellierung von allem verwendet werden kann, enthält die Sprache eine Fülle von Konzepten, Begriffen und Anwendungsfällen, die aus Sicht des Entwurfs relationaler Datenbanken überflüssig sind. Extrahieren wir aus dem allgemeinen Mechanismus der Klassendiagramme, was für den Entwurf relationaler Datenbanken wirklich erforderlich ist, dann erhalten wir genau ER-Diagramme mit einer anderen Notation und Terminologie. Merkwürdig ist, dass bei der Bildung von Klassennamen in der UML eine beliebige Kombination aus Buchstaben, Zahlen und sogar Satzzeichen erlaubt ist. In der Praxis empfiehlt es sich jedoch, kurze und aussagekräftige Adjektive und Substantive als Klassennamen zu verwenden, die jeweils mit einem Großbuchstaben beginnen. (Auf das Konzept eines Diagramms gehen wir im nächsten Absatz unserer Vorlesung näher ein.) 1. Verschiedene Arten und Vielfachheiten von Anleihen Die Beziehung zwischen Beziehungen beim Entwurf von Datenbankschemata wird als Linien dargestellt, die Entitätsklassen verbinden. Darüber hinaus kann (und sollte im Allgemeinen) jedes der Enden der Verbindung durch den Namen (dh die Art der Verbindung) und die Multiplizität der Rolle der Klasse in der Verbindung charakterisiert werden. Betrachten wir die Konzepte der Multiplizität und der Arten von Verbindungen genauer. Vielzahl (Multiplizität) ist ein Merkmal, das angibt, wie viele Attribute einer Entitätsklasse mit einer bestimmten Rolle an jeder Instanz einer Beziehung irgendeiner Art teilnehmen können oder sollten. Die häufigste Methode zum Festlegen der Kardinalität einer Beziehungsrolle besteht darin, direkt eine bestimmte Zahl oder einen bestimmten Bereich anzugeben. Beispielsweise bedeutet die Angabe von „1“, dass jede Klasse mit einer bestimmten Rolle an einer Instanz dieser Verbindung teilnehmen muss und genau ein Objekt der Klasse mit dieser Rolle an jeder Instanz der Verbindung teilnehmen kann. Die Angabe des Bereichs "0..1" gibt an, dass nicht alle Objekte der Klasse mit einer bestimmten Rolle an irgendeiner Instanz dieser Beziehung teilnehmen müssen, aber nur ein Objekt an jeder Instanz der Beziehung teilnehmen kann. Lassen Sie uns ausführlicher über Multiplizität sprechen. Typische, gebräuchlichste Kardinalitäten in Datenbankentwurfssystemen sind die folgenden Kardinalitäten: 1) 1 - die Multiplizität der Verbindung an ihrem entsprechenden Ende ist gleich eins; 2) 0... 1 – diese Notationsform bedeutet, dass die Multiplizität einer gegebenen Verbindung an ihrem entsprechenden Ende eins nicht überschreiten kann; 3) 0... ∞ – diese Multiplizität wird einfach als „viele“ entschlüsselt. Es ist merkwürdig, dass „viel“ in der Regel „nichts“ bedeutet; 4) 1... ∞ - diese Bezeichnung wurde der Vielzahl „eins oder mehrere“ gegeben. Lassen Sie uns ein Beispiel für ein einfaches Diagramm geben, um die Arbeit mit unterschiedlichen Verknüpfungsvielfalten zu veranschaulichen.
Anhand dieses Diagramms kann man leicht verstehen, dass jede Kasse viele Tickets hat und sich wiederum jede Karte in einer (und nicht mehr als dieser) Kasse befindet. Betrachten Sie nun die gebräuchlichsten Arten oder Namen von Links. Lassen Sie uns sie auflisten: 1) 1:1 - diese Bezeichnung erhielt die Verbindung "eins zu eins", d.h. es ist sozusagen eine Eins-zu-Eins-Korrespondenz zweier Mengen; 2) 1 : 0... ∞ – das ist eine Bezeichnung für eine Verbindung wie „eins zu vielen". Der Kürze halber wird eine solche Beziehung "1: M" genannt. In dem zuvor betrachteten Diagramm gibt es, wie Sie sehen können, eine Beziehung mit genau einem solchen Namen; 3) 0... ∞ : 1 - Dies ist eine Umkehrung der vorherigen Verbindung oder eine Verbindung vom Typ "viele zu einem"; 4) 0... ∞ : 0... ∞ ist eine Bezeichnung für eine Verbindung wie „viel zu viel", d.h. es gibt viele Attribute an jedem Ende des Links; 5) 0... 1 : 0... 1 - Dies ist eine Verbindung, die der zuvor eingeführten Verbindung vom Typ „Eins zu Eins“ ähnelt, sie heißt wiederum „nicht mehr als eins bis nicht mehr als eins"; 6) 0... 1 : 0... ∞ – Dies ist eine Verbindung, die einer Eins-zu-Viele-Verbindung ähnelt, sie wird „nicht mehr als eins zu viele“ genannt; 7) 0... ∞ : 0... 1 - Dies ist eine Verbindung, die wiederum einer Viele-zu-Eins-Verbindung ähnelt und als „viele bis nicht mehr als eins". Wie Sie sehen, wurden die letzten drei Verbindungen aus den Verbindungen gewonnen, die in unserem Vortrag unter den Nummern eins, zwei und drei aufgeführt sind, indem die Vielfachheit von „eins“ durch die Vielfachheit von „nicht mehr als eins“ ersetzt wurde. 2. Diagramme. Arten von Diagrammen Kommen wir nun endlich direkt zur Betrachtung von Diagrammen und deren Typen. Im Allgemeinen gibt es drei Ebenen des logischen Modells. Diese Ebenen unterscheiden sich in der Darstellungstiefe von Informationen über die Datenstruktur. Diese Ebenen entsprechen den folgenden Diagrammen: 1) Präsentationsdiagramm; 2) Schlüsseldiagramm; 3) vollständiges Attributdiagramm. Lassen Sie uns jede dieser Arten von Diagrammen analysieren und die Bedeutung ihrer Unterschiede in der Tiefe der Darstellung von Informationen über die Datenstruktur im Detail erläutern. 1. Präsentationsdiagramm. Solche Diagramme beschreiben nur die grundlegendsten Klassen von Entitäten und ihre Beziehungen. Die Tasten in solchen Diagrammen dürfen überhaupt nicht beschrieben werden, und dementsprechend dürfen die Verbindungen in keiner Weise individualisiert werden. Viele-zu-viele-Beziehungen sind daher akzeptabel, obwohl sie normalerweise vermieden oder, falls vorhanden, feinabgestimmt werden. Zusammengesetzte und mehrwertige Attribute sind ebenfalls vollkommen gültig, obwohl wir zuvor geschrieben haben, dass Basisbeziehungen mit solchen Attributen nicht auf irgendeine normale Form reduziert werden können. Interessanterweise geht von den drei betrachteten Diagrammtypen nur der letzte Typ (das vollständige Attributdiagramm) davon aus, dass die damit präsentierten Daten in irgendeiner normalen Form vorliegen. Während das bereits betrachtete Präsentationsdiagramm und das nachfolgende Schlüsseldiagramm nichts dergleichen implizieren. Solche Diagramme werden normalerweise für Präsentationen verwendet (daher ihr Name - Präsentation, dh für Präsentationen, Demonstrationen, bei denen keine übermäßigen Details erforderlich sind). Manchmal ist es beim Entwerfen von Datenbanken erforderlich, Experten auf dem Fachgebiet zu konsultieren, das diese spezielle Datenbank mit Informationen behandelt. Dann kommen auch Präsentationsdiagramme zum Einsatz, denn um die notwendigen Informationen von Fachleuten in einem Beruf fernab des Programmierens zu erhalten, bedarf es gar keiner übermäßigen Klärung spezifischer Details. 2. Schlüsseldiagramm. Im Gegensatz zu Präsentationsdiagrammen beschreiben Schlüsseldiagramme notwendigerweise alle Klassen von Entitäten und ihre Beziehungen, jedoch nur in Form von Primärschlüsseln. Hier sind viele-zu-viele-Beziehungen bereits notwendigerweise detailliert (d.h. Beziehungen dieser Art in ihrer reinen Form können hier einfach nicht spezifiziert werden). Mehrwertige Attribute sind weiterhin wie in einem Präsentationsdiagramm zulässig, aber wenn sie in einem Schlüsseldiagramm vorhanden sind, werden sie normalerweise in separate Entitätsklassen konvertiert. Aber seltsamerweise können einwertige Attribute immer noch unvollständig dargestellt oder als zusammengesetzt beschrieben werden. Diese "Freiheiten", die in Diagrammen wie Präsentations- und Schlüsseldiagrammen noch gelten, sind im nächsten Diagrammtyp nicht zulässig, da sie bestimmen, dass die Basisbeziehung nicht normalisiert ist. Daraus lässt sich schließen, dass Schlüsseldiagramme in Zukunft nur noch „hängende“ Attribute an bereits beschriebene Entitätsklassen annehmen, d.h. es reicht mit einem Präsentationsdiagramm die nötigsten Entitätsklassen zu beschreiben, und dann mit einem Schlüsseldiagramm alles hinzuzufügen dazu notwendige Attribute und geben Sie alle wichtigen Links an. 3. Vollständiges Attributdiagramm. Vollständige Attributdiagramme beschreiben alle oben genannten Klassen von Entitäten, ihre Attribute und Beziehungen zwischen diesen Entitätsklassen im Detail. In der Regel stellen solche Diagramme Daten dar, die sich in der dritten Normalform befinden, daher ist es selbstverständlich, dass in den durch solche Diagramme beschriebenen grundlegenden Beziehungen keine zusammengesetzten oder mehrwertigen Attribute zulässig sind, ebenso wie es keine nicht granularen Viele-zu- viele Beziehungen. Vollständige Attributdiagramme haben jedoch immer noch einen Nachteil, das heißt, sie können nicht vollständig als die vollständigsten Diagramme in Bezug auf die Datenpräsentation bezeichnet werden. So wird beispielsweise die Eigenheit bestimmter Datenbankmanagementsysteme bei der Verwendung von vollständigen Attributdiagrammen noch nicht berücksichtigt, insbesondere wird der Datentyp nur in dem Umfang spezifiziert, der für die erforderliche logische Modellierungsebene erforderlich ist. 3. Assoziationen und Schlüsselmigration Etwas früher haben wir bereits darüber gesprochen, was Beziehungen in Datenbanken sind. Insbesondere wurde die Beziehung hergestellt, als die Fremdschlüssel der Beziehung deklariert wurden. Aber in diesem Abschnitt unseres Kurses sprechen wir nicht mehr über grundlegende Beziehungen, sondern über Registrierkassen von Entitäten. In diesem Sinne ist der Prozess des Beziehungsaufbaus immer noch mit der Deklaration verschiedener Schlüssel verbunden, aber jetzt sprechen wir von den Schlüsseln von Entitätsklassen. Der Vorgang des Herstellens von Beziehungen ist nämlich mit der Übertragung eines einfachen oder zusammengesetzten Primärschlüssels einer Entitätsklasse zu einer anderen Klasse verbunden. Der Prozess einer solchen Übertragung wird auch genannt Schlüsselmigration. In diesem Fall wird die Entitätsklasse aufgerufen, deren Primärschlüssel übergeben werden Elternklasse, und die Klasse der Entitäten, in die Fremdschlüssel migriert werden, wird aufgerufen Kinderklasse Entitäten. In einer untergeordneten Entitätsklasse erhalten Schlüsselattribute den Status von Fremdschlüsselattributen und können an der Bildung ihres eigenen Primärschlüssels teilnehmen oder nicht. Wenn also ein Primärschlüssel von einer übergeordneten zu einer untergeordneten Entitätsklasse migriert wird, erscheint in der untergeordneten Klasse ein Fremdschlüssel, der auf den Primärschlüssel der übergeordneten Klasse verweist. Zur Vereinfachung der formelhaften Darstellung der Schlüsselmigration führen wir die folgenden Schlüsselmarkierungen ein: 1) PK - so bezeichnen wir jedes Attribut des Primärschlüssels (Primärschlüssel); 2) FK - mit diesem Marker bezeichnen wir die Attribute eines Fremdschlüssels (Fremdschlüssel); 3) PFK - mit einem solchen Marker bezeichnen wir ein Attribut des Primär-/Fremdschlüssels, d. h. jedes solche Attribut, das Teil des einzigen Primärschlüssels einer Entitätsklasse und gleichzeitig Teil eines Fremdschlüssels derselben Entitätsklasse ist . Somit bilden Attribute einer Entitätsklasse mit PK- und FK-Markierungen den Primärschlüssel dieser Klasse. Und Attribute mit FK-Markierungen und PFK sind Teil einiger Fremdschlüssel dieser Entitätsklasse. Im Allgemeinen können Schlüssel auf unterschiedliche Weise migrieren, und in jedem dieser unterschiedlichen Fälle entsteht eine Art Verbindung. Betrachten wir also, welche Arten von Links es je nach Schlüsselmigrationsschema gibt. Insgesamt gibt es zwei wichtige Migrationsschemata. 1. Migrationsschema ∀PK (PK |→PFK); In diesem Eintrag bedeutet das Symbol „|→“ den Begriff „migriert“, d. h. die obige Formel wird wie folgt gelesen: jedes (jedes) Attribut des Primärschlüssels PK der übergeordneten Entitätsklasse wird an die übertragen (migriert). Primärschlüssel PFK untergeordnete Entitätsklasse, die natürlich auch ein Fremdschlüssel für diese Klasse ist. In diesem Fall sprechen wir davon, dass ausnahmslos jedes Schlüsselattribut der übergeordneten Entitätsklasse in die untergeordnete Entitätsklasse migriert werden muss. Diese Art der Verbindung heißt identifizieren, da der Schlüssel der übergeordneten Entitätsklasse vollständig an der Identifizierung von untergeordneten Entitäten beteiligt ist. Unter den Verknüpfungen des identifizierenden Typs gibt es wiederum zwei weitere mögliche unabhängige Arten von Verknüpfungen. Es gibt also zwei Arten von identifizierenden Links: 1) vollständig identifizieren. Eine identifizierende Beziehung wird genau dann als vollständig identifizierend bezeichnet, wenn die Attribute des migrierenden Primärschlüssels der übergeordneten Entitätsklasse vollständig den primären (und fremden) Schlüssel der untergeordneten Entitätsklasse bilden. Eine vollständig identifizierende Beziehung wird manchmal auch genannt kategorisch, da eine vollständig identifizierende Beziehung untergeordnete Entitäten über alle Kategorien hinweg identifiziert; 2) nicht vollständig identifizieren. Eine identifizierende Beziehung wird genau dann als unvollständig identifizierend bezeichnet, wenn die Attribute des migrierenden Primärschlüssels der übergeordneten Entitätsklasse nur teilweise den primären (und gleichzeitig fremden) Schlüssel der untergeordneten Entitätsklasse bilden. Also zusätzlich zum Schlüssel mit der Markierung PFK wird auch einen Schlüssel haben, der mit PK gekennzeichnet ist. In diesem Fall wird der Fremdschlüssel PFK der untergeordneten Entitätsklasse vollständig durch den Primärschlüssel PK der übergeordneten Entitätsklasse bestimmt, aber einfach der Primärschlüssel PK dieser untergeordneten Beziehung wird nicht durch den Primärschlüssel PK der übergeordneten Entitätsklasse bestimmt Entitätsklasse, es wird für sich allein sein. 2. Schema der Migration ∃PK (PK |→ FK); Ein solches Migrationsschema ist wie folgt zu lesen: Es gibt solche Primärschlüsselattribute der übergeordneten Entitätsklasse, die bei der Migration auf die obligatorischen Nichtschlüsselattribute der untergeordneten Entitätsklasse übertragen werden. In diesem Fall sprechen wir also davon, dass einige und nicht alle, wie im vorherigen Fall, Primärschlüsselattribute der übergeordneten Entitätsklasse auf die untergeordnete Entitätsklasse übertragen werden. Wenn das vorherige Migrationsschema die Migration zum Primärschlüssel der untergeordneten Beziehung definiert hat, die gleichzeitig auch zu einem Fremdschlüssel wurde, dann bestimmt die letzte Migrationsart, dass die Primärschlüsselattribute der übergeordneten Entitätsklasse auf gewöhnlich migrieren , zunächst Nichtschlüsselattribute, die danach Fremdschlüsselstatus erlangen. Diese Art der Verbindung heißt nicht identifizierend, da der übergeordnete Schlüssel tatsächlich nicht vollständig an der Bildung von untergeordneten Entitäten beteiligt ist, er identifiziert sie einfach nicht. Unter den nicht-identifizierenden Beziehungen werden auch zwei mögliche Arten von Beziehungen unterschieden. Nicht-identifizierende Beziehungen gehören also zu den folgenden zwei Arten: 1) notwendigerweise nicht identifizierend. Nicht-identifizierende Beziehungen gelten genau dann als notwendigerweise nicht-identifizierend, wenn Nullwerte für alle migrierenden Schlüsselattribute einer untergeordneten Entitätsklasse verboten sind; 2) optional nicht identifizierend. Nicht identifizierende Beziehungen sollen genau dann nicht unbedingt nicht identifizierend sein, wenn für einige migrierende Schlüsselattribute der untergeordneten Entitätsklasse Nullwerte zulässig sind. Wir fassen alle oben genannten Punkte in Form der folgenden Tabelle zusammen, um die Aufgabe der Systematisierung und des Verständnisses des präsentierten Materials zu erleichtern. In diese Tabelle werden wir auch Informationen darüber aufnehmen, welche Arten von Beziehungen ("nicht mehr als eins zu eins", "viele zu eins", "viele zu nicht mehr als eins") welchen Beziehungstypen entsprechen (vollständig identifizierend, nicht vollständig identifizierend, notwendigerweise nicht identifizierend, nicht unbedingt nicht identifizierend). Zwischen den übergeordneten und untergeordneten Entitätsklassen wird also je nach Beziehungstyp der folgende Beziehungstyp eingerichtet.
Wir sehen also, dass in allen Fällen außer dem letzten die Referenz nicht leer (nicht null) → 1 ist. Beachten Sie den Trend, dass am übergeordneten Ende der Verbindung in allen Fällen außer dem letzten die Multiplizität auf "eins" gesetzt wird. Dies liegt daran, dass der Wert des Fremdschlüssels bei diesen Beziehungen (nämlich vollständig identifizierende, nicht vollständig identifizierende und notwendigerweise nicht identifizierende Arten von Beziehungen) notwendigerweise (und darüber hinaus dem einzigen) Wert des Primärschlüssels von entsprechen muss die übergeordnete Entitätsklasse. Und im letzteren Fall wird die Multiplizität aufgrund der Tatsache, dass der Wert des Fremdschlüssels gleich dem Null-Wert sein kann (das FK: Null-Gültigkeits-Flag), am übergeordneten Ende des auf "nicht mehr als eins" gesetzt Beziehung. Wir führen unsere Analyse weiter. Am untergeordneten Ende der Verbindung wird in allen Fällen, mit Ausnahme des ersten, die Multiplizität auf "viele" gesetzt. Denn aufgrund einer unvollständigen Identifizierung wie im zweiten Fall (bzw. gar keiner solchen Identifizierung im zweiten und dritten Fall) kann der Wert des Primärschlüssels der übergeordneten Entitätsklasse mehrfach unter den Werten vorkommen des Fremdschlüssels der Kindklasse. Und im ersten Fall ist die Beziehung vollständig identifizierend, sodass die Attribute des Primärschlüssels der übergeordneten Entitätsklasse nur einmal unter den Attributen der Schlüssel der untergeordneten Entitätsklasse vorkommen können. Vorlesung Nr. 12. Beziehungen von Entitätsklassen Alle Konzepte, die wir durchgegangen sind, nämlich Diagramme und ihre Arten, Vielheiten und Arten von Beziehungen sowie Arten von Schlüsselmigrationen, werden uns jetzt helfen, das Material über dieselben Beziehungen, aber bereits zwischen bestimmten Klassen von zu durchgehen Entitäten. Unter ihnen gibt es, wie wir sehen werden, auch Verbindungen verschiedener Art. 1. Hierarchische rekursive Beziehung Die erste Art von Beziehung zwischen Entitätsklassen, die wir betrachten werden, ist die sogenannte hierarchische rekursive Beziehung. allgemein Rekursion (oder rekursive Verknüpfung) ist die Beziehung einer Entitätsklasse zu sich selbst. Manchmal wird eine solche Verbindung in Analogie zu Lebenssituationen auch als "Angelhaken" bezeichnet. Hierarchische rekursive Beziehung (oder einfach hierarchische Rekursion) ist eine beliebige rekursive Beziehung vom Typ „höchstens eine zu vielen“. Hierarchische Rekursion wird am häufigsten verwendet, um Daten in einer Baumstruktur zu speichern. Bei der Angabe einer hierarchischen rekursiven Beziehung muss der Primärschlüssel der übergeordneten Entitätsklasse (die in diesem speziellen Fall auch als untergeordnete Entitätsklasse fungiert) als Fremdschlüssel zu den obligatorischen Nicht-Schlüsselattributen derselben Entitätsklasse migriert werden. All dies ist notwendig, um die logische Integrität des eigentlichen Konzepts der "hierarchischen Rekursion" aufrechtzuerhalten. Unter Berücksichtigung all dessen können wir also den Schluss ziehen, dass eine hierarchische rekursive Beziehung nur sein kann nicht unbedingt nicht identifizierend und keine andere, denn wenn irgendeine andere Art von Beziehung verwendet würde, wären Nullwerte für den Fremdschlüssel ungültig und die Rekursion unendlich. Es ist auch wichtig, daran zu denken, dass Attribute nicht zweimal in derselben Entitätsklasse unter demselben Namen erscheinen können. Daher müssen die Attribute des migrierten Schlüssels mit dem sogenannten Rollennamen versehen werden. Somit werden in einer hierarchischen rekursiven Beziehung die Attribute eines Knotens um einen Fremdschlüssel erweitert, der eine optionale Referenz auf den Primärschlüssel des Knotens ist, der sein unmittelbarer Vorfahr ist. Lassen Sie uns eine Präsentation und Schlüsseldiagramme erstellen, die die hierarchische Rekursion in einem relationalen Datenmodell implementieren, und ein Beispiel für eine tabellarische Form geben. Lassen Sie uns zuerst ein Präsentationsdiagramm erstellen:
Lassen Sie uns nun ein detaillierteres Schlüsseldiagramm erstellen:
Betrachten Sie ein Beispiel, das eine solche Art von Beziehung als eine hierarchische rekursive Beziehung deutlich veranschaulicht. Gegeben sei die folgende Entity-Klasse, die wie im vorigen Beispiel aus den Attributen „Ancestor Code“ und „Node Code“ besteht. Lassen Sie uns zunächst eine tabellarische Darstellung dieser Entitätsklasse zeigen:
Lassen Sie uns nun ein Diagramm erstellen, das diese Klasse von Entitäten darstellt. Dazu wählen wir aus der Tabelle alle dafür notwendigen Informationen aus: Der Vorfahre des Knotens mit dem Code „Eins“ existiert nicht oder ist nicht definiert, daraus schließen wir, dass der Knoten „Eins“ ein Scheitelpunkt ist. Derselbe Knoten „Eins“ ist der Vorfahre von Knoten mit den Codes „Zwei“ und „Drei“. Der Knoten mit dem Code „zwei“ hat wiederum zwei Kinder: den Knoten mit dem Code „vier“ und den Knoten mit dem Code „fünf“. Und der Knoten mit dem Code „drei“ hat nur ein Kind – der Knoten mit dem Code „sechs“. Lassen Sie uns unter Berücksichtigung aller oben genannten Punkte eine Baumstruktur erstellen, die die Informationen zu den in der vorherigen Tabelle enthaltenen Daten widerspiegelt:
Wir haben also gesehen, dass es wirklich praktisch ist, Baumstrukturen mit einer hierarchischen rekursiven Beziehung darzustellen. 2. Rekursive Netzwerkkommunikation Die netzwerkrekursive Verbindung von Entitätsklassen untereinander ist gleichsam ein mehrdimensionales Analogon der bereits durchlaufenen hierarchischen rekursiven Verbindung. Nur wenn die hierarchische Rekursion als eine "höchstens eine zu vielen" rekursive Beziehung definiert wurde, dann Netzwerkrekursion stellt dieselbe rekursive Beziehung dar, nur vom "viele-zu-viele"-Typ. Da an dieser Verbindung auf jeder Seite viele Klassen von Entitäten beteiligt sind, spricht man von einer Netzwerkverbindung. Wie Sie anhand der Analogie zur hierarchischen Rekursion bereits erahnen können, sind Verknüpfungen vom Typ Netzwerkrekursion dazu bestimmt, Graphdatenstrukturen darzustellen (während hierarchische Verknüpfungen, wie wir uns erinnern, ausschließlich für die Implementierung von Baumstrukturen verwendet werden). Da aber in der Verbindung vom Typ Netzwerkrekursion die Verbindungen vom Typ "many-to-many" spezifiziert sind, kann auf deren zusätzliche Detaillierung nicht verzichtet werden. Um alle Viele-zu-Viele-Beziehungen im Schema zu verfeinern, ist es daher erforderlich, eine neue unabhängige Entitätsklasse zu erstellen, die alle Verweise auf den Eltern- oder Nachfolger der Ancestor-Descendant-Beziehung enthält. Eine solche Klasse wird allgemein genannt assoziative Entitätsklasse. In unserem speziellen Fall (in den in unserem Kurs zu betrachtenden Datenbanken) hat die assoziative Entität keine eigenen zusätzlichen Attribute und heißt Berufung, weil es die Vorfahren-Nachkommen-Beziehungen benennt, indem es auf sie verweist. Daher muss der Primärschlüssel der Entitätsklasse, die die Hosts darstellt, zweimal in die assoziativen Entitätsklassen migriert werden. In dieser Klasse müssen die migrierten Schlüssel zusammen einen zusammengesetzten Primärschlüssel bilden. Aus dem Vorhergehenden können wir schließen, dass das Erstellen von Links bei der Verwendung von Netzwerkrekursion nicht vollständig identifizierend sein sollte und nichts anderes. Genau wie bei der Verwendung einer hierarchischen rekursiven Beziehung darf bei der Verwendung der Netzwerkrekursion als Beziehung kein Attribut zweimal in derselben Entitätsklasse unter demselben Namen erscheinen. Daher wird wie beim letzten Mal ausdrücklich festgelegt, dass alle Attribute des Migrationsschlüssels den Rollennamen erhalten müssen. Um die Funktionsweise der rekursiven Netzwerkkommunikation zu veranschaulichen, erstellen wir eine Präsentation und Schlüsseldiagramme, die die Netzwerkrekursion in einem relationalen Datenmodell implementieren. Beginnen wir mit einem Präsentationsdiagramm:
Lassen Sie uns nun ein detaillierteres Schlüsseldiagramm erstellen:
Was sehen wir hier? Und wir sehen, dass beide Verbindungen in diesem Schlüsseldiagramm „viele zu eins“-Verbindungen sind. Darüber hinaus steht die Multiplizität „0... ∞“ oder die Multiplizität „viele“ am Ende der Verbindung, die der benennenden Klasse von Entitäten zugewandt ist. Tatsächlich gibt es viele Links, aber alle verweisen auf einen Knotencode, der der Primärschlüssel der Entitätsklasse „Nodes“ ist. Und schließlich betrachten wir ein Beispiel, das die Operation eines solchen Verbindungstyps durch eine Entitätsklasse als Netzwerkrekursion veranschaulicht. Lassen Sie uns eine tabellarische Darstellung einer Entitätsklasse geben, sowie eine Benennungs-Entitätsklasse, die Informationen über Verknüpfungen enthält. Werfen wir einen Blick auf diese Tabellen. Knoten:
Links:
Tatsächlich ist die obige Darstellung erschöpfend: Sie gibt alle notwendigen Informationen, um die hier codierte Graphenstruktur leicht zu reproduzieren. Zum Beispiel können wir ohne Hindernisse sehen, dass der Knoten mit dem Code „Eins“ drei Kinder hat, beziehungsweise mit den Codes „Zwei“, „Drei“ und „Vier“. Wir sehen auch, dass Knoten mit den Codes „zwei“ und „drei“ überhaupt keine Nachkommen haben, und ein Knoten mit dem Code „vier“ hat (ebenso wie der Knoten „eins“) drei Nachkommen mit den Codes „eins“, „zwei“ und drei". Lassen Sie uns ein Diagramm zeichnen, das durch die oben angegebenen Entitätsklassen gegeben ist:
Das Diagramm, das wir gerade erstellt haben, sind also die Daten, für die die Entitätsklassen mithilfe einer Verbindung vom Typ Netzwerkrekursion verknüpft wurden. 3. Verein Von allen Arten von Verbindungen, die in die Betrachtung unserer speziellen Vorlesung einbezogen werden, sind nur zwei rekursive Verbindungen. Wir haben es bereits geschafft, sie zu berücksichtigen, dies sind hierarchische bzw. netzwerkrekursive Links. Alle anderen Arten von Beziehungen, die wir betrachten müssen, sind nicht rekursiv, sondern stellen in der Regel eine Beziehung mehrerer übergeordneter und mehrerer untergeordneter Entitätsklassen dar. Darüber hinaus werden, wie Sie vielleicht erraten haben, die übergeordneten und untergeordneten Entitätsklassen jetzt niemals zusammenfallen (tatsächlich sprechen wir nicht mehr von Rekursion). Die Verbindung, die in diesem Abschnitt der Vorlesung besprochen wird, heißt Assoziation und bezieht sich genau auf die nicht-rekursive Art von Verbindungen. Also rief die Verbindung an Verband, wird als Beziehung zwischen mehreren übergeordneten Entitätsklassen und einer untergeordneten Entitätsklasse implementiert. Und gleichzeitig, was merkwürdig ist, wird diese Beziehung durch Beziehungen verschiedener Art beschrieben. Es ist auch erwähnenswert, dass es während der Zuordnung nur eine übergeordnete Entitätsklasse geben kann, wie bei der Netzwerkrekursion, aber selbst in einer solchen Situation muss die Anzahl der Beziehungen, die von der untergeordneten Entitätsklasse stammen, mindestens zwei betragen. Interessanterweise gibt es sowohl in der Assoziation als auch in der Netzwerkrekursion spezielle Arten von Entitätsklassen. Ein Beispiel für eine solche Klasse ist eine untergeordnete Entitätsklasse. Tatsächlich wird im allgemeinen Fall in einer Assoziation eine untergeordnete Entitätsklasse aufgerufen assoziative Entitätsklasse. In dem speziellen Fall, dass eine assoziative Entitätsklasse keine eigenen zusätzlichen Attribute hat und nur Attribute enthält, die zusammen mit Primärschlüsseln von übergeordneten Entitätsklassen migrieren, wird eine solche Klasse aufgerufen Klasse der Benennung von Entitäten. Wie Sie sehen können, gibt es eine fast absolute Analogie zum Konzept der assoziativen und benennenden Entitäten in einer rekursiven Netzwerkverbindung. Am häufigsten wird eine Assoziation verwendet, um viele-zu-viele-Beziehungen zu verfeinern (aufzulösen). Lassen Sie uns diese Aussage veranschaulichen. Nehmen wir zum Beispiel das folgende Präsentationsdiagramm, das das Schema der Aufnahme eines bestimmten Arztes in einem bestimmten Krankenhaus beschreibt:
Dieses Diagramm bedeutet wörtlich, dass es viele Ärzte und viele Patienten im Krankenhaus gibt und es keine andere Beziehung und Korrespondenz zwischen Ärzten und Patienten gibt. Somit wäre es bei einer solchen Datenbank für die Krankenhausverwaltung natürlich nie klar, wie sie Termine bei verschiedenen Ärzten für verschiedene Patienten vereinbaren soll. Es ist klar, dass die hier verwendeten Many-to-Many-Beziehungen lediglich detailliert werden müssen, um die Beziehung zwischen den verschiedenen Ärzten und Patienten zu konkretisieren, also die Terminplanung aller Ärzte und ihrer Patienten sinnvoll zu organisieren das Krankenhaus. Lassen Sie uns nun ein detaillierteres Schlüsseldiagramm erstellen, in dem wir bereits alle vorhandenen Viele-zu-Viele-Beziehungen detailliert darstellen. Dazu führen wir entsprechend eine neue Entity-Klasse ein, wir nennen sie "Receive", die als assoziative Entity-Klasse fungiert (später werden wir sehen, warum dies eine assoziative Entity-Klasse sein wird und nicht nur eine Klasse der Benennung Entitäten, über die wir zuvor gesprochen haben). Unser Schlüsseldiagramm sieht also so aus:
Jetzt können Sie also deutlich sehen, warum die neue Klasse "Empfangen" keine Klasse zum Benennen von Entitäten ist. Immerhin hat diese Klasse ein eigenes zusätzliches Attribut "Datum - Uhrzeit", daher ist die neu eingeführte Klasse "Empfang" per Definition eine Klasse von assoziativen Entitäten. Diese Klasse „assoziiert“ die Entitätsklassen „Ärzte“ und „Patient“ anhand der Uhrzeit, zu der dieser oder jener Termin durchgeführt wird, was die Arbeit mit einer solchen Datenbank wesentlich komfortabler macht. So organisierten wir mit der Einführung des Attributs "Datum - Uhrzeit" buchstäblich den dringend benötigten Arbeitszeitplan für verschiedene Ärzte. Wir sehen auch, dass der externe Primärschlüssel „Kodex des Arztes“ der Entitätsklasse „Empfang“ auf den gleichnamigen Primärschlüssel der Entitätsklasse „Ärzte“ verweist. Und analog verweist der externe Primärschlüssel „Patientencode“ der Entitätsklasse „Empfang“ auf den gleichnamigen Primärschlüssel der Entitätsklasse „Patient“. Dabei sind selbstverständlich die Entitätsklassen „Ärzte“ und „Patient“ die Eltern und die assoziative Entitätsklasse „Empfang“ wiederum das einzige Kind. Wir können sehen, dass die Viele-zu-Viele-Beziehung im vorherigen Präsentationsdiagramm jetzt vollständig detailliert ist. Anstelle der einen Viele-zu-Viele-Beziehung, die wir im obigen Präsentationsdiagramm sehen, haben wir zwei Viele-zu-Eins-Beziehungen. Das untergeordnete Ende der ersten Beziehung hat die Multiplizität "viele", was wörtlich bedeutet, dass die Entitätsklasse "Empfang" viele Ärzte hat (alle im Krankenhaus). Und am übergeordneten Ende dieser Beziehung ist die Vielheit von „Eins“, was bedeutet das? Das bedeutet, dass in der Entitätsklasse „Empfang“ jede der verfügbaren Kennziffern des jeweiligen Arztes beliebig oft vorkommen kann. Tatsächlich kommt der Code desselben Arztes im Zeitplan des Krankenhauses viele Male an verschiedenen Tagen und zu verschiedenen Zeiten vor. Und hier ist derselbe Code, aber bereits in der Entitätsklasse "Ärzte", er kann einmal und nur einmal vorkommen. In der Liste aller Krankenhausärzte (und die Entitätsklasse "Ärzte" ist nichts anderes als eine solche Liste) kann der Code jedes einzelnen Arztes nämlich nur einmal vorhanden sein. Ähnlich verhält es sich mit der Beziehung zwischen der Elternklasse „Patient“ und der Kindklasse „Patient“. In der Liste aller Krankenhauspatienten (in der Entitätsklasse "Patienten") darf der Code jedes einzelnen Patienten nur einmal vorkommen. Andererseits kann im Terminplan (in der Entitätsklasse "Empfang") jeder Code eines bestimmten Patienten beliebig oft vorkommen. Deshalb sind die Multiplizitäten an den Enden der Bindung so angeordnet. Als Beispiel für die Implementierung einer Assoziation in einem relationalen Datenmodell bauen wir ein Modell, das den Zeitplan für Besprechungen zwischen dem Kunden und dem Auftragnehmer mit optionaler Beteiligung von Beratern beschreibt. Wir werden nicht auf das Präsentationsdiagramm eingehen, weil wir den Aufbau von Diagrammen in allen Einzelheiten betrachten müssen und das Präsentationsdiagramm diese Möglichkeit nicht bieten kann. Lassen Sie uns also ein Schlüsseldiagramm erstellen, das die Essenz der Beziehung zwischen dem Kunden, dem Auftragnehmer und dem Berater widerspiegelt.
Beginnen wir also mit einer detaillierten Analyse des obigen Schlüsseldiagramms. Erstens ist die Klasse „Graph“ eine Klasse assoziativer Entitäten, aber wie im vorherigen Beispiel ist sie keine Klasse benannter Entitäten, weil sie ein Attribut hat, das nicht zusammen mit den Schlüsseln in sie migriert, sondern es ist eigenes Attribut. Dies ist das Attribut "Datum - Uhrzeit". Zweitens sehen wir, dass die Attribute der untergeordneten Entitätsklasse „Chart“, „Kundencode“, „Executor-Code“ und „Datum – Uhrzeit“ einen zusammengesetzten Primärschlüssel dieser Entitätsklasse bilden. Das Attribut „Advisor Code“ ist einfach ein Fremdschlüssel der Entitätsklasse „Chart“. Bitte beachten Sie, dass dieses Attribut unter seinen Werten Nullwerte zulässt, da gemäß der Bedingung die Anwesenheit eines Beraters bei der Besprechung nicht erforderlich ist. Drittens stellen wir außerdem fest, dass die ersten beiden Links (der drei verfügbaren Links) nicht vollständig identifizierend sind. Nämlich nicht vollständig identifizierend, da der Migrationsschlüssel in beiden Fällen (Primärschlüssel "Kundencode" und "Executorcode") nicht vollständig den Primärschlüssel der Entitätsklasse "Graph" bildet. Tatsächlich bleibt das Attribut "Datum - Uhrzeit", das auch Teil des zusammengesetzten Primärschlüssels ist. An den Enden dieser beiden unvollständig identifizierenden Bindungen sind die Multiplizitäten "eins" und "viele" markiert. Dies geschieht, um (wie im Beispiel zu Ärzten und Patienten) den Unterschied zwischen der Erwähnung des Codes des Kunden oder des Leistungserbringers in verschiedenen Entitätsklassen aufzuzeigen. Tatsächlich kann in der Entitätsklasse "Graph" jeder Kunden- oder Auftragnehmercode beliebig oft vorkommen. Daher gibt es an diesem untergeordneten Ende der Verbindung eine Vielzahl von "Vielen". Und in der Entitätsklasse „Kunden“ bzw. „Auftragnehmer“ darf jede der Kennziffern des Auftraggebers bzw. Auftragnehmers nur einmal vorkommen, denn diese Entitätsklassen sind jeweils nichts anderes als eine vollständige Auflistung aller Kunden und Leistungserbringer. Daher gibt es an diesem Elternende der Verbindung eine Vielzahl von "eins". Beachten Sie schließlich, dass die dritte Beziehung, nämlich die Beziehung der Entitätsklasse „Graph“ mit der Entitätsklasse „Berater“, nicht unbedingt nicht-identifizierend ist. In diesem Fall handelt es sich nämlich um die Übertragung des Schlüsselattributs „Beratercode“ der Entitätsklasse „Berater“ auf das gleichnamige Nichtschlüsselattribut der Entitätsklasse „Grafik“, also den Primärschlüssel von die Entitätsklasse „Berater“ in der Entitätsklasse „Graph“ identifiziert den Primärschlüssel dieser Klasse nicht bereits. Außerdem erlaubt das Attribut "Advisor Code", wie bereits erwähnt, Nullwerte, sodass hier genau die nicht identifizierende Beziehung verwendet wird. Damit erhält das Attribut „Advisor Code“ den Status eines Fremdschlüssels und nichts weiter. Lassen Sie uns auch auf die Vielzahl von Links achten, die an den übergeordneten und untergeordneten Enden dieses unvollständig nicht identifizierenden Links platziert sind. Sein übergeordnetes Ende hat eine Vielzahl von "nicht mehr als eins". Wenn wir uns an die Definition einer Beziehung erinnern, die nicht vollständig nicht-identifizierend ist, werden wir verstehen, dass das Attribut „Beratercode“ aus der Entitätsklasse „Grafik“ nicht mehr als einem Beratercode aus der Liste aller Berater entsprechen kann (das ist die Entitätsklasse „Berater“). Und im Allgemeinen kann es sich herausstellen, dass es keinem Beratercode entspricht (denken Sie an die Checkbox für die Zulässigkeit von Nullwerten Beratercode: Null), weil laut Bedingung die Anwesenheit eines Beraters bei a Treffen zwischen Auftraggeber und Auftragnehmer ist grundsätzlich nicht erforderlich. 4. Verallgemeinerungen Eine andere Art von Beziehung zwischen Entitätsklassen, die wir betrachten werden, ist eine Beziehung der Form Verallgemeinerung. Es ist auch eine nicht-rekursive Art von Beziehung. Also eine Beziehung wie Verallgemeinerung ist als Beziehung einer übergeordneten Entitätsklasse mit mehreren untergeordneten Entitätsklassen implementiert (im Gegensatz zur vorherigen Assoziationsbeziehung, die sich mit mehreren übergeordneten Entitätsklassen und einer untergeordneten Entitätsklasse befasste). Bei der Formulierung von Datenrepräsentationsregeln mit Hilfe der Generalisierungsbeziehung muss gleich gesagt werden, dass diese Beziehung einer übergeordneten Entitätsklasse und mehrerer untergeordneter Entitätsklassen durch vollständig identifizierende Beziehungen, also kategoriale Beziehungen, beschrieben wird. In Erinnerung an die Definition vollständig identifizierender Beziehungen schließen wir, dass bei Verwendung der Generalisierung jedes Attribut des Primärschlüssels der übergeordneten Entitätsklasse auf den Primärschlüssel der untergeordneten Entitätsklassen übertragen wird, d. h. die Attribute des primären Migrationsschlüssels der übergeordneten Entitätsklasse bilden vollständig die Primärschlüssel aller untergeordneten Entitätsklassen, sie identifizieren sie. Es ist merkwürdig festzustellen, dass die Verallgemeinerung das sogenannte implementiert Kategoriehierarchie oder Vererbungshierarchie. In diesem Fall definiert die übergeordnete Entitätsklasse generische Entitätsklasse, gekennzeichnet durch Attribute, die Entitäten aller untergeordneten Klassen oder sog. gemeinsam sind kategoriale Entitäten Das heißt, eine übergeordnete Entitätsklasse ist eine wörtliche Verallgemeinerung aller ihrer untergeordneten Entitätsklassen. Als Beispiel für die Implementierung der Verallgemeinerung in einem relationalen Datenmodell werden wir das folgende Modell konstruieren. Dieses Modell basiert auf dem verallgemeinerten Konzept „Studenten“ und beschreibt die folgenden kategorialen Konzepte (d. h. es verallgemeinert die folgenden untergeordneten Entitätsklassen): „Schulkinder“, „Studenten“ und „Postgraduierte“. Lassen Sie uns also ein Schlüsseldiagramm erstellen, das die Essenz der Beziehung zwischen der übergeordneten Entitätsklasse und den untergeordneten Entitätsklassen widerspiegelt, die durch eine Verbindung des Generalisierungstyps beschrieben wird.
Was sehen wir also? Erstens entspricht jede der Grundrelationen (bzw. von Entitätsklassen, die gleich sind) „Schüler“, „Student“ und „Doktorand“ seinen eigenen Attributen wie „Klasse“, „Kurs“ und „Studienjahr“. " . Jedes dieser Attribute charakterisiert Mitglieder seiner eigenen Entitätsklasse. Wir sehen auch, dass der Primärschlüssel der übergeordneten Entitätsklasse „Students“ in jede untergeordnete Entitätsklasse wandert und dort den primären Fremdschlüssel bildet. Mit Hilfe dieser Verbindungen können wir anhand des Codes jedes Schülers seinen Vornamen, Nachnamen und Vatersnamen bestimmen, Informationen darüber, die wir in den entsprechenden untergeordneten Entitätsklassen selbst nicht finden werden. Da wir zweitens über eine vollständig identifizierende (oder kategoriale) Beziehung von Entitätsklassen sprechen, werden wir auf die Vielzahl von Beziehungen zwischen der übergeordneten Entitätsklasse und ihren untergeordneten Klassen achten. Das übergeordnete Ende jeder dieser Verbindungen hat eine Multiplizität von "eins", und jedes untergeordnete Ende der Verbindungen hat eine Multiplizität von "höchstens eins". Erinnern wir uns an die Definition einer vollständig identifizierenden Beziehung von Entitätsklassen, so wird deutlich, dass der wirklich eindeutige Studentencode, der der Primärschlüssel der Entitätsklasse „Students“ ist, in jeder Kindentität höchstens ein Attribut mit einem solchen Code spezifiziert Klasse „Student“, „Students“ und Postgraduierte. Daher haben alle Bindungen genau solche Vielfachheiten. Lassen Sie uns ein Fragment der Operatoren zum Erstellen der grundlegenden Beziehungen "Schulkinder" und "Studenten" mit der Definition von Regeln zur Aufrechterhaltung der referentiellen Integrität des Kaskadentyps schreiben. Also haben wir: Tabelle Schüler erstellen ... Primärschlüssel (Studentencode) Fremdschlüssel (Studentenausweis) Verweise Studenten (Studentenausweis) auf Update-Kaskade auf Kaskade löschen Erstellen Sie eine Tabelle Studenten ... Primärschlüssel (Studentencode) Fremdschlüssel (Studentenausweis) Verweise Studenten (Studentenausweis) auf Update-Kaskade auf Kaskade löschen; Wir sehen also, dass in der untergeordneten Entitätsklasse (oder Beziehung) „Student“ ein primärer Fremdschlüssel angegeben ist, der auf die übergeordnete Entitätsklasse (oder Beziehung) „Students“ verweist. Die Kaskadenregel zur Aufrechterhaltung der referentiellen Integrität legt fest, dass beim Löschen oder Aktualisieren von Attributen der übergeordneten Entitätsklasse „Schüler“ die entsprechenden Attribute der Kindbeziehung „Student“ automatisch (kaskadiert) aktualisiert oder gelöscht werden. Wenn Attribute der übergeordneten Entitätsklasse „Studenten“ gelöscht oder aktualisiert werden, werden die entsprechenden Attribute der untergeordneten Beziehung „Studenten“ ebenfalls automatisch aktualisiert oder gelöscht. Anzumerken ist, dass hier auf diese referentielle Integritätsregel zurückgegriffen wird, da es in diesem Zusammenhang (Studentenliste) nicht sinnvoll ist, das Löschen und Aktualisieren von Informationen zu verbieten und auch statt echter Informationen einen undefinierten Wert zuzuweisen . Lassen Sie uns nun ein Beispiel für die im vorherigen Diagramm beschriebenen Entitätsklassen geben, die nur in tabellarischer Form dargestellt werden. Wir haben also die folgenden Beziehungstabellen: Schüler - übergeordnete Beziehung, die Informationen über die Attribute aller anderen Beziehungen kombiniert:
Schulkinder - Kindsbeziehung:
Studierende - zweites Kind Beziehung:
Doktoranden - Drittkindbeziehung:
Wir sehen also tatsächlich, dass die untergeordneten Klassen von Entitäten keine Informationen über den Nachnamen, den Vornamen und das Patronym von Studenten enthalten, d. H. Schüler, Studenten und Doktoranden. Diese Informationen können nur durch Verweise auf die übergeordnete Entitätsklasse abgerufen werden. Wir sehen auch, dass verschiedene Studentencodes in der Entitätsklasse „Students“ verschiedenen untergeordneten Entitätsklassen entsprechen können. So ist über den Schüler mit dem Code „1“ Nikolai Zabotin in der elterlichen Beziehung außer seinem Namen nichts bekannt, und alle anderen Informationen (wer er ist, Schüler, Student oder Doktorand) können nur durch Bezugnahme gefunden werden an die entsprechende untergeordnete Entitätsklasse (bestimmt durch den Code). Ebenso müssen Sie mit den restlichen Studenten arbeiten, deren Codes in der übergeordneten Entitätsklasse "Students" angegeben sind. 5. Zusammensetzung Die Beziehung von Entitätsklassen vom Typ Composition gehört wie die beiden vorherigen nicht zum Typ der rekursiven Beziehung. Zusammensetzung (oder, wie es manchmal genannt wird, zusammengesetzte Aggregation) ist eine Beziehung einer einzelnen übergeordneten Entitätsklasse mit mehreren untergeordneten Entitätsklassen, genau wie die oben besprochene Beziehung. Verallgemeinerung. Wurde aber Generalisierung als Beziehung von Entitätsklassen definiert, die durch vollständig identifizierende Beziehungen beschrieben wird, dann wird Zusammensetzung wiederum durch unvollständig identifizierende Beziehungen beschrieben, d.h. während der Zusammensetzung wandert jedes Attribut des Primärschlüssels der übergeordneten Entitätsklasse in das Schlüsselattribut der untergeordneten Entitätsklasse. Gleichzeitig bilden die migrierenden Schlüsselattribute nur teilweise den Primärschlüssel der untergeordneten Entitätsklasse. Bei der zusammengesetzten Aggregation (mit Komposition) wird also die übergeordnete Entitätsklasse (bzw Einheit) ist mehreren untergeordneten Entitätsklassen (bzw Komponenten). In diesem Fall verweisen die Komponenten des Aggregats (d. h. die Komponenten der übergeordneten Entitätsklasse) auf das Aggregat durch einen Fremdschlüssel, der Teil des Primärschlüssels ist und daher außerhalb des Aggregats nicht existieren kann. Im Allgemeinen ist die zusammengesetzte Aggregation eine erweiterte Form der einfachen Aggregation (auf die wir später noch zu sprechen kommen). Eine Zusammensetzung (oder zusammengesetzte Aggregation) ist dadurch gekennzeichnet, dass: 1) der Bezug auf die Baugruppe ist an der Identifizierung der Komponenten beteiligt; 2) diese Komponenten können nicht außerhalb des Aggregats existieren. Eine Aggregation (eine Beziehung, die wir weiter betrachten werden) mit notwendigerweise nicht identifizierenden Beziehungen erlaubt ebenfalls keine Existenz von Komponenten außerhalb des Aggregats und kommt daher der oben beschriebenen Implementierung der zusammengesetzten Aggregation nahe. Lassen Sie uns ein Schlüsseldiagramm erstellen, das die Beziehung zwischen einer übergeordneten Entitätsklasse und mehreren untergeordneten Entitätsklassen beschreibt, d. h. die Beziehung von Entitätsklassen des zusammengesetzten Aggregationstyps beschreibt. Dies sei ein Schlüsseldiagramm, das die Zusammensetzung der Gebäude eines bestimmten Campus darstellt, einschließlich der Gebäude, ihrer Klassenzimmer und Aufzüge. Dieses Diagramm sieht also so aus:
Werfen wir also einen Blick auf das Diagramm, das wir gerade erstellt haben. Was sehen wir darin? Erstens sehen wir, dass die Beziehung, die in dieser zusammengesetzten Aggregation verwendet wird, tatsächlich identifizierend und tatsächlich nicht vollständig identifizierend ist. Denn der Primärschlüssel der übergeordneten Entitätsklasse „Gebäude“ ist an der Bildung des Primärschlüssels der untergeordneten Entitätsklassen „Publikum“ und „Aufzüge“ beteiligt, definiert diesen aber nicht vollständig. Der Primärschlüssel "Case No" der übergeordneten Entitätsklasse wandert auf die fremden Primärschlüssel "Case No" beider untergeordneten Klassen, aber zusätzlich zu diesem migrierten Schlüssel haben beide untergeordneten Entitätsklassen auch ihren eigenen Primärschlüssel bzw. "Audience No" und "Elevator No.", d.h. die zusammengesetzten Primärschlüssel der untergeordneten Entitätsklassen sind nur teilweise gebildete Attribute des Primärschlüssels der übergeordneten Entitätsklasse. Betrachten wir nun die Vielzahl von Verknüpfungen, die die Eltern- und die beiden Kindklassen verbinden. Da es sich um unvollständig identifizierende Verknüpfungen handelt, sind die Vielheiten vorhanden: „eins“ und „viele“. Die Multiplizität "Eins" steht am übergeordneten Ende beider Beziehungen und symbolisiert, dass in der Liste aller verfügbaren Korpora (und die Entitätsklasse "Korpus" ist eine solche Liste) jede Zahl nur einmal (und nicht mehr) vorkommen kann als das) mal. Und wiederum kann unter den Attributen der Klassen "Publikum" und "Aufzüge" jede Gebäudenummer viele Male vorkommen, da es mehr Publikum (oder Aufzüge) als Gebäude gibt und in jedem Gebäude mehrere Hörsäle und Aufzüge vorhanden sind. Daher werden wir bei der Auflistung aller Klassenzimmer und Aufzüge zwangsläufig die Gebäudenummern wiederholen. Und schließlich, wie im Fall des vorherigen Verbindungstyps, schreiben wir die Fragmente der Operatoren zum Erstellen grundlegender Beziehungen (oder, was dasselbe ist, Entitätsklassen) "Publikum" und "Aufzüge" auf, und wir werden es tun Tun Sie dies mit der Definition von Regeln zur Aufrechterhaltung der referenziellen Integrität des Kaskadentyps. Diese Aussage würde also so aussehen: Tabellen-Zielgruppen erstellen ... Primärschlüssel (Korpusnummer, Publikumsnummer) Fremdschlüssel (Fallnummer) Referenzen Muster (Fallnummer) auf Update-Kaskade auf Kaskade löschen Erstellen Sie Tischaufzüge ... Primärschlüssel (Fallnummer, Aufzugsnummer) Fremdschlüssel (Fallnummer) Referenzen Muster (Fallnummer) auf Update-Kaskade auf Kaskade löschen; Somit haben wir alle notwendigen Primär- und Fremdschlüssel der untergeordneten Entitätsklassen gesetzt. Wir haben wieder die Regel der Aufrechterhaltung der referentiellen Integrität als Kaskade genommen, da wir sie bereits als die rationalste beschrieben haben. Nun geben wir ein Beispiel in tabellarischer Form für alle Entitätsklassen, die wir gerade betrachtet haben. Lassen Sie uns diese grundlegenden Beziehungen beschreiben, die wir mit Hilfe eines Diagramms in Form von Tabellen widergespiegelt haben, und zur Verdeutlichung werden wir dort einige indikative Daten einführen. Muscheln Die Elternbeziehung sieht folgendermaßen aus:
Publikum - untergeordnete Entitätsklasse:
Aufzüge - die zweite untergeordnete Entitätsklasse der übergeordneten Klasse "Enclosures":
Wir können also sehen, wie Informationen für alle Gebäude, ihre Klassenzimmer und Aufzüge in dieser Datenbank organisiert sind, die von jeder realen Bildungseinrichtung verwendet werden kann. 6. Aggregation Aggregation ist die letzte Art von Beziehung zwischen Entitätsklassen, die im Rahmen unseres Kurses betrachtet wird. Es ist auch nicht rekursiv, und einer seiner beiden Typen kommt der Bedeutung der zuvor betrachteten zusammengesetzten Aggregation ziemlich nahe. somit Aggregation ist die Beziehung einer übergeordneten Entitätsklasse mit mehreren untergeordneten Entitätsklassen. In diesem Fall kann die Beziehung durch zwei Arten von Beziehungen beschrieben werden: 1) notwendigerweise nicht identifizierende Links; 2) optionale nicht identifizierende Links. Denken Sie daran, dass bei notwendigerweise nicht identifizierenden Beziehungen einige Attribute des Primärschlüssels der übergeordneten Entitätsklasse auf ein Nicht-Schlüsselattribut der untergeordneten Klasse übertragen werden und Nullwerte für alle Attribute des Migrationsschlüssels verboten sind. Und bei nicht unbedingt nicht-identifizierenden Beziehungen erfolgt die Migration von Primärschlüsseln nach genau dem gleichen Prinzip, allerdings sind Null-Werte für einige Attribute des migrierenden Schlüssels erlaubt. Beim Aggregieren wird die übergeordnete Entitätsklasse (bzw Einheit) ist mehreren untergeordneten Entitätsklassen (bzw Komponenten). Die Komponenten des Aggregats (d. h. die übergeordnete Entitätsklasse) verweisen auf das Aggregat durch einen Fremdschlüssel, der nicht Teil des Primärschlüssels ist, und daher im Fall nicht notwendigerweise nicht identifizierende LinksAggregatkomponenten können außerhalb des Aggregats existieren. Im Fall der Aggregation mit notwendigerweise nicht identifizierenden Beziehungen dürfen die Komponenten des Aggregats nicht außerhalb des Aggregats existieren, und in diesem Sinne kommt die Aggregation mit notwendigerweise nicht identifizierenden Beziehungen der zusammengesetzten Aggregation nahe. Nachdem klar geworden ist, was eine Aggregationstypbeziehung ist, erstellen wir ein Schlüsseldiagramm, das die Funktionsweise dieser Beziehung beschreibt. Lassen Sie unser Zukunftsdiagramm die markierten Komponenten von Autos (nämlich Motor und Chassis) beschreiben. Gleichzeitig gehen wir davon aus, dass die Stilllegung des Autos die Stilllegung des Fahrgestells mit sich bringt, aber nicht die gleichzeitige Stilllegung des Motors. Unser Schlüsseldiagramm sieht also so aus:
Was sehen wir also in diesem Schlüsseldiagramm? Erstens ist die Beziehung der übergeordneten Entitätsklasse „Autos“ mit der untergeordneten Entitätsklasse „Motoren“ nicht unbedingt nicht identifizierend, da das Attribut „Auto #“ Nullwerte unter seinen Werten zulässt. Dieses Attribut erlaubt wiederum Null-Werte aus dem Grund, dass die Stilllegung des Motors bedingt nicht von der Stilllegung des gesamten Fahrzeugs abhängt und daher nicht unbedingt bei der Stilllegung eines Autos auftritt. Wir sehen auch, dass der Primärschlüssel „Engine #“ der Entitätsklasse „Cars“ in das Nicht-Schlüssel-Attribut „Engine #“ der Entitätsklasse „Engines“ migriert. Gleichzeitig erhält dieses Attribut den Status eines Fremdschlüssels. Und der Primärschlüssel in dieser Engines-Entitätsklasse ist das Engine-Markierungsattribut, das auf kein Attribut der übergeordneten Beziehung verweist. Zweitens ist die Beziehung zwischen der übergeordneten Entitätsklasse „Motors“ und der untergeordneten Entitätsklasse „Chassis“ zwangsläufig eine nicht identifizierende Beziehung, da das Fremdschlüsselattribut „Car #“ keine Nullwerte unter seinen Werten zulässt. Dies wiederum geschieht, weil es durch die Bedingung bekannt ist, dass die Stilllegung des Autos die obligatorische gleichzeitige Stilllegung des Fahrgestells impliziert. Dabei wird, ebenso wie bei der vorherigen Beziehung, der Primärschlüssel der übergeordneten Entitätsklasse „Motoren“ auf das Nichtschlüsselattribut „Fahrzeugnummer“ der untergeordneten Entitätsklasse „Fahrgestell“ migriert. Primärschlüssel dieser Entitätsklasse ist dabei das Attribut „Chassis Marker“, das sich auf kein Attribut der übergeordneten Beziehung „Motors“ bezieht. Mach weiter. Lassen Sie uns zur besten Assimilation des Themas die Fragmente der Operatoren zum Erstellen der grundlegenden Beziehungen "Motoren" und "Chassis" mit der Definition von Regeln zur Aufrechterhaltung der referenziellen Integrität erneut aufschreiben. Erstellen Sie Tabellen-Engines ... Primärschlüssel (Motormarker) Fremdschlüssel (Fahrzeug-Nr.) Referenzen Autos (Fahrzeug-Nr.) auf Update-Kaskade beim Löschen auf Null setzen Tabellenchassis erstellen ... Primärschlüssel (Chassismarker) Fremdschlüssel (Fahrzeug-Nr.) Referenzen Autos (Fahrzeug-Nr.) auf Update-Kaskade auf Kaskade löschen; Wir sehen, dass wir überall die gleiche Regel zur Aufrechterhaltung der referentiellen Integrität verwendet haben - Kaskade, da wir sie schon früher als die rationalste von allen erkannt haben. Allerdings haben wir dieses Mal (zusätzlich zur Kaskadenregel) die set Null referential Integrity-Regel verwendet. Außerdem haben wir es unter der folgenden Bedingung verwendet: Wenn ein Wert des Primärschlüssels „Autonummer“ aus der übergeordneten Entitätsklasse „Autos“ gelöscht wird, dann wird der Wert des Fremdschlüssels „Autonummer“ der untergeordneten Relation „Motoren“ sich darauf beziehen, wird ein Null-Wert zugewiesen. 7. Vereinheitlichung von Attributen Gelangen bei der Migration von Primärschlüsseln einer bestimmten übergeordneten Entitätsklasse bedeutungsgleiche Attribute verschiedener übergeordneter Klassen in dieselbe untergeordnete Klasse, so müssen diese Attribute „zusammengeführt“ werden, d. h -genannt Vereinheitlichung von Attributen. Wenn beispielsweise ein Mitarbeiter in einer Organisation arbeiten kann und in nicht mehr als einer Abteilung aufgeführt ist, erhalten wir nach der Vereinheitlichung des Attributs "Organisationscode" das folgende Schlüsseldiagramm:
Bei der Migration des Primärschlüssels von den übergeordneten Entitätsklassen „Organisation“ und „Abteilungen“ auf die untergeordnete Klasse „Mitarbeiter“ gelangt das Attribut „Organisations-ID“ in die Entitätsklasse „Mitarbeiter“. Und zweimal: 1) erstmals mit Marker PFK aus der Entitätsklasse „Organisation“ bei der Herstellung einer unvollständig identifizierenden Beziehung; 2) und das zweite Mal mit dem FK-Marker mit der Bedingung, Null-Werte aus der Entitätsklasse "Abteilungen" zu akzeptieren, wenn eine nicht unbedingt nicht identifizierende Beziehung hergestellt wird. Nach der Vereinheitlichung nimmt das Attribut „Organisations-ID“ den Status eines Primär-/Fremdschlüsselattributs an und übernimmt den Status des Fremdschlüsselattributs. Lassen Sie uns ein neues Schlüsseldiagramm erstellen, das den Vereinigungsprozess selbst demonstriert:
So fand die Vereinheitlichung der Attribute statt. Vorlesung Nr. 13. Expertensysteme und Wissensproduktionsmodell 1. Ernennung von Expertensystemen Sich mit einem so neuen Konzept für uns vertraut zu machen wie Expertensysteme Zunächst werden wir die Geschichte der Entstehung und Entwicklung der Richtung „Expertensysteme“ durchgehen und dann das eigentliche Konzept der Expertensysteme definieren. In den frühen 80er Jahren. XNUMX. Jahrhundert In der Forschung zur Schaffung künstlicher Intelligenz wurde eine neue unabhängige Richtung gebildet, genannt Expertensysteme. Der Zweck dieser neuen Forschung zu Expertensystemen ist die Entwicklung spezieller Programme zur Lösung spezifischer Arten von Problemen. Was ist das für ein spezielles Problem, das die Schaffung eines völlig neuen Wissens-Engineerings erforderte? Dieser spezielle Aufgabentyp kann Aufgaben aus allen Fachgebieten umfassen. Der Hauptunterschied zu gewöhnlichen Problemen besteht darin, dass es für einen menschlichen Experten eine sehr schwierige Aufgabe zu sein scheint, sie zu lösen. Dann die erste sog Expertensystem (wo die Rolle eines Experten nicht mehr eine Person, sondern eine Maschine war) und das Expertensystem Ergebnisse erhält, die in Qualität und Effizienz den Lösungen nicht unterlegen sind, die von einer gewöhnlichen Person - einem Experten - erzielt werden. Die Ergebnisse der Arbeit von Expertensystemen können dem Anwender auf sehr hohem Niveau erklärt werden. Diese Qualität von Expertensystemen wird durch ihre Fähigkeit gewährleistet, über ihr eigenes Wissen und ihre Schlussfolgerungen nachzudenken. Expertensysteme können ihr eigenes Wissen im Prozess der Interaktion mit einem Experten ergänzen. Somit können sie mit vollem Vertrauen einer voll ausgebildeten künstlichen Intelligenz gleichgestellt werden. Forscher auf dem Gebiet der Expertensysteme verwenden für den Namen ihrer Disziplin häufig auch den zuvor erwähnten Begriff „Knowledge Engineering“, der von dem deutschen Wissenschaftler E. Feigenbaum eingeführt wurde, um „die Prinzipien und Werkzeuge der Forschung aus dem Bereich der künstlichen Intelligenz in die Lösung zu bringen schwierige Anwendungsprobleme, die Expertenwissen erfordern." Der kommerzielle Erfolg der Entwicklungsfirmen stellte sich jedoch nicht sofort ein. Ein Vierteljahrhundert von 1960 bis 1985. Die Erfolge der künstlichen Intelligenz hängen hauptsächlich mit Forschungsentwicklungen zusammen. Allerdings ab etwa 1985 und in großem Umfang von 1987 bis 1990. Expertensysteme wurden aktiv in kommerziellen Anwendungen verwendet. Die Vorzüge von Expertensystemen sind ziemlich groß und lauten wie folgt: 1) Die Expertensystemtechnologie erweitert das Spektrum praktisch bedeutsamer Aufgaben, die auf Personalcomputern gelöst werden, erheblich, deren Lösung erhebliche wirtschaftliche Vorteile bringt und alle damit verbundenen Prozesse erheblich vereinfacht; 2) Die Expertensystemtechnologie ist eines der wichtigsten Werkzeuge zur Lösung der globalen Probleme der traditionellen Programmierung, wie z. B. die Dauer, Qualität und folglich die hohen Kosten der Entwicklung komplexer Anwendungen, wodurch der wirtschaftliche Effekt erheblich verringert wurde ; 3) hohe Betriebs- und Wartungskosten komplexer Systeme, die die Kosten der Entwicklung selbst oft um ein Vielfaches übersteigen, sowie eine geringe Wiederverwendbarkeit von Programmen usw.; 4) die Kombination von Expertensystemtechnologie mit traditioneller Programmiertechnologie fügt Softwareprodukten neue Qualitäten hinzu, indem erstens eine dynamische Modifikation von Anwendungen durch einen gewöhnlichen Benutzer und nicht durch einen Programmierer bereitgestellt wird; zweitens größere "Transparenz" der Anwendung, bessere Grafik, Schnittstelle und Interaktion von Expertensystemen. Nach Ansicht normaler Benutzer und führender Experten werden Expertensysteme in naher Zukunft die folgenden Anwendungen finden: 1) Expertensysteme werden in allen Phasen des Entwurfs, der Entwicklung, der Produktion, der Verteilung, der Fehlerbehebung, der Kontrolle und der Bereitstellung von Diensten eine führende Rolle spielen; 2) Expertensystemtechnologie, die eine weite kommerzielle Verbreitung gefunden hat, wird einen revolutionären Durchbruch bei der Integration von Anwendungen aus vorgefertigten intelligenten interagierenden Modulen bieten. Im Allgemeinen sind Expertensysteme für die sog informelle Aufgaben, d. h. Expertensysteme lehnen und ersetzen nicht den traditionellen Ansatz der Programmentwicklung, der auf die Lösung formalisierter Probleme ausgerichtet ist, sondern ergänzen sie und erweitern dadurch die Möglichkeiten erheblich. Genau das kann ein bloßer menschlicher Experte nicht leisten. Solche komplexen nicht-formalisierten Aufgaben sind gekennzeichnet durch: 1) Irrtum, Ungenauigkeit, Mehrdeutigkeit sowie Unvollständigkeit und Widersprüchlichkeit der Quelldaten; 2) Irrtum, Mehrdeutigkeit, Ungenauigkeit, Unvollständigkeit und Widersprüchlichkeit des Wissens über den Problembereich und das zu lösende Problem; 3) große Dimension des Lösungsraums eines konkreten Problems; 4) dynamische Variabilität von Daten und Wissen direkt im Prozess der Lösung eines solchen informellen Problems. Expertensysteme basieren hauptsächlich auf der heuristischen Suche nach einer Lösung und nicht auf der Ausführung eines bekannten Algorithmus. Dies ist einer der Hauptvorteile der Expertensystemtechnologie gegenüber dem traditionellen Ansatz der Softwareentwicklung. Dadurch können sie die ihnen übertragenen Aufgaben so gut bewältigen. Die Expertensystemtechnologie wird zur Lösung einer Vielzahl von Problemen eingesetzt. Wir listen die wichtigsten dieser Aufgaben auf. 1. Interpretation. Expertensysteme, die Dolmetschen durchführen, verwenden meistens die Messwerte verschiedener Instrumente, um den Stand der Dinge zu beschreiben. Interpretierende Expertensysteme sind in der Lage, eine Vielzahl von Arten von Informationen zu verarbeiten. Ein Beispiel ist die Verwendung von Spektralanalysedaten und Änderungen in den Eigenschaften von Stoffen, um ihre Zusammensetzung und Eigenschaften zu bestimmen. Ein weiteres Beispiel ist die Interpretation der Messwerte von Messgeräten im Kesselraum, um den Zustand der Kessel und des darin enthaltenen Wassers zu beschreiben. Interpretierende Systeme befassen sich meistens direkt mit Hinweisen. In dieser Hinsicht treten Schwierigkeiten auf, die andere Arten von Systemen nicht haben. Was sind das für Schwierigkeiten? Diese Schwierigkeiten entstehen dadurch, dass Expertensysteme verstopfte überflüssige, unvollständige, unzuverlässige oder falsche Informationen interpretieren müssen. Daher sind entweder Fehler oder ein erheblicher Anstieg der Datenverarbeitung unvermeidlich. 2. Prognose. Expertensysteme, die eine Vorhersage von etwas durchführen, bestimmen die probabilistischen Bedingungen gegebener Situationen. Beispiele sind die Vorhersage von Schäden an der Getreideernte durch widrige Wetterbedingungen, die Einschätzung der Gasnachfrage auf dem Weltmarkt, Wettervorhersagen nach meteorologischen Stationen. Vorhersagesysteme verwenden manchmal Modellierung, d. h. Programme, die einige Beziehungen in der realen Welt darstellen, um sie in einer Programmierumgebung nachzubilden, und entwerfen dann Situationen, die mit bestimmten Anfangsdaten auftreten können. 3. Diagnose verschiedener Geräte. Expertensysteme führen solche Diagnosen durch, indem sie Beschreibungen jeglicher Situation, Verhaltensweisen oder Daten über die Struktur verschiedener Komponenten verwenden, um die möglichen Ursachen eines fehlerhaften diagnostizierbaren Systems zu bestimmen. Beispiele sind die Feststellung der Krankheitsumstände durch die bei Patienten (in der Medizin) beobachteten Symptome; Identifizierung von Fehlern in elektronischen Schaltungen und Identifizierung fehlerhafter Komponenten in den Mechanismen verschiedener Geräte. Diagnosesysteme sind oft Assistenten, die nicht nur eine Diagnose stellen, sondern auch bei der Fehlersuche helfen. In solchen Fällen können diese Systeme durchaus mit dem Benutzer interagieren, um bei der Fehlerbehebung zu helfen, und dann eine Liste von Maßnahmen bereitstellen, die zu ihrer Lösung erforderlich sind. Gegenwärtig werden viele Diagnosesysteme als Anwendungen für Ingenieur- und Computersysteme entwickelt. 4. Planung verschiedener Veranstaltungen. Expertensysteme, die für die Planung verschiedener Operationen entwickelt wurden. Systeme geben eine nahezu vollständige Abfolge von Aktionen vor, bevor deren Umsetzung beginnt. Beispiele für eine solche Planung von Ereignissen sind die Erstellung von Plänen für militärische Operationen, sowohl defensiv als auch offensiv, die für einen bestimmten Zeitraum festgelegt sind, um einen Vorteil gegenüber feindlichen Streitkräften zu erlangen. 5. Design-. Expertensysteme, die Design durchführen, entwickeln verschiedene Formen von Objekten unter Berücksichtigung der vorherrschenden Umstände und aller damit verbundenen Faktoren. Ein Beispiel ist die Gentechnik. 6. Steuern. Expertensysteme, die die Kontrolle ausüben, vergleichen das gegenwärtige Verhalten des Systems mit seinem erwarteten Verhalten. Beobachtende Expertensysteme erkennen kontrolliertes Verhalten, das ihre Erwartungen gegenüber normalem Verhalten oder ihrer Annahme möglicher Abweichungen bestätigt. Steuernde Expertensysteme müssen naturgemäß in Echtzeit arbeiten und eine zeitabhängige und kontextabhängige Interpretation des Verhaltens des gesteuerten Objekts implementieren. Beispiele sind die Überwachung der Messwerte von Messgeräten in Kernreaktoren zur Erkennung von Notfällen oder die Auswertung diagnostischer Daten von Patienten auf der Intensivstation. 7. Management. Schließlich ist allgemein bekannt, dass Expertensysteme, die die Kontrolle ausüben, das Verhalten des Systems als Ganzes sehr effektiv steuern. Ein Beispiel ist das Management verschiedener Branchen sowie der Vertrieb von Computersystemen. Steuerungsexpertensysteme müssen Beobachtungskomponenten enthalten, um das Verhalten eines Objekts über einen langen Zeitraum zu steuern, aber sie können auch andere Komponenten von den bereits analysierten Aufgabentypen benötigen. Expertensysteme werden in verschiedenen Bereichen eingesetzt: Finanztransaktionen, Öl- und Gasindustrie. Die Expertensystemtechnologie kann auch in den Bereichen Energie, Transport, Pharmaindustrie, Weltraumentwicklung, Hütten- und Bergbauindustrie, Chemie und vielen anderen Bereichen eingesetzt werden. 2. Aufbau von Expertensystemen Die Entwicklung von Expertensystemen weist eine Reihe signifikanter Unterschiede zur Entwicklung eines herkömmlichen Softwareprodukts auf. Die Erfahrung mit der Erstellung von Expertensystemen hat gezeigt, dass die Verwendung der in der traditionellen Programmierung verwendeten Methodik bei ihrer Entwicklung entweder den Zeitaufwand für die Erstellung von Expertensystemen erheblich erhöht oder sogar zu einem negativen Ergebnis führt. Expertensysteme werden im Allgemeinen unterteilt in statisch и dynamisch. Betrachten Sie zunächst ein statisches Expertensystem. Standard Statisches Expertensystem besteht aus folgenden Hauptkomponenten: 1) Arbeitsspeicher, auch Datenbank genannt; 2) Wissensbasen; 3) ein Löser, auch Interpreter genannt; 4) Komponenten des Wissenserwerbs; 5) erklärende Komponente; 6) Dialogkomponente. Betrachten wir nun jede Komponente genauer. Arbeitsgedächtnis (in absoluter Analogie zum Arbeits-, d. h. Computer-RAM) dient zum Empfangen und Speichern der Anfangs- und Zwischendaten der Aufgabe, die gerade gelöst wird. Wissens dient zum Speichern von Langzeitdaten, die einen bestimmten Themenbereich beschreiben, und von Regeln, die die rationale Transformation von Daten in diesem Bereich des zu lösenden Problems beschreiben. Löserauch genannt Dolmetscher, funktioniert wie folgt: Mit den Ausgangsdaten aus dem Arbeitsgedächtnis und Langzeitdaten aus der Wissensbasis bildet es die Regeln, deren Anwendung auf die Ausgangsdaten zur Lösung des Problems führt. Mit einem Wort, er „löst“ wirklich das ihm gestellte Problem; Wissenserwerbskomponente automatisiert das Befüllen des Expertensystems mit Expertenwissen, d.h. diese Komponente versorgt die Wissensbasis mit allen notwendigen Informationen aus diesem speziellen Themengebiet. Bauteil erklären erklärt, wie das System eine Lösung für dieses Problem erhalten hat oder warum es diese Lösung nicht erhalten hat und welches Wissen es dabei verwendet hat. Mit anderen Worten, die EXPLAIN-Komponente generiert einen Fortschrittsbericht. Diese Komponente ist im gesamten Expertensystem sehr wichtig, da sie das Testen des Systems durch einen Experten erheblich erleichtert und außerdem das Vertrauen des Benutzers in das erhaltene Ergebnis erhöht und somit den Entwicklungsprozess beschleunigt. Dialogkomponente dient der Bereitstellung einer benutzerfreundlichen Oberfläche sowohl bei der Lösung eines Problems als auch bei der Aneignung von Wissen und der Bekanntgabe von Arbeitsergebnissen. Nachdem wir nun wissen, aus welchen Komponenten ein statistisches Expertensystem im Allgemeinen besteht, wollen wir ein Diagramm erstellen, das die Struktur eines solchen Expertensystems widerspiegelt. Es sieht aus wie das:
Statische Expertensysteme werden am häufigsten in technischen Anwendungen eingesetzt, in denen es möglich ist, Änderungen in der Umgebung, die während der Lösung eines Problems auftreten, nicht zu berücksichtigen. Es ist interessant zu wissen, dass die ersten Expertensysteme, die praktische Anwendung fanden, genau statisch waren. Damit beenden wir die Betrachtung des statistischen Expertensystems vorerst, gehen wir zur Analyse des dynamischen Expertensystems über. Leider enthält das Programm unseres Kurses keine detaillierte Betrachtung dieses Expertensystems, so dass wir uns darauf beschränken, nur die grundlegendsten Unterschiede zwischen einem dynamischen Expertensystem und einem statischen zu analysieren. Im Gegensatz zu einem statischen Expertensystem ist die Struktur Dynamisches Expertensystem Darüber hinaus werden die folgenden zwei Komponenten eingeführt: 1) ein Subsystem zur Modellierung der Außenwelt; 2) ein Subsystem der Beziehungen zur äußeren Umgebung. Subsystem der Beziehungen zur äußeren Umgebung Es stellt nur Verbindungen zur Außenwelt her. Sie tut dies durch ein System aus speziellen Sensoren und Controllern. Darüber hinaus werden einige traditionelle Komponenten eines statischen Expertensystems erheblichen Änderungen unterzogen, um die zeitliche Logik von Ereignissen widerzuspiegeln, die derzeit in der Umgebung auftreten. Dies ist der Hauptunterschied zwischen statischen und dynamischen Expertensystemen. Ein Beispiel für ein dynamisches Expertensystem ist die Verwaltung der Herstellung verschiedener Arzneimittel in der pharmazeutischen Industrie. 3. Beteiligte an der Entwicklung von Expertensystemen An der Entwicklung von Expertensystemen sind Vertreter verschiedener Fachrichtungen beteiligt. Meist wird ein spezifisches Expertensystem von drei Spezialisten entwickelt. Dies ist normalerweise: 1) Experte; 2) Wissensingenieur; 3) ein Programmierer für die Entwicklung von Tools. Lassen Sie uns die Verantwortlichkeiten jedes der hier aufgeführten Spezialisten erläutern. Experte ist Spezialist auf dem Fachgebiet, dessen Aufgaben mit Hilfe dieses speziell zu entwickelnden Expertensystems gelöst werden. Wissensingenieur ist ein Spezialist für die Entwicklung eines Expertensystems direkt. Die von ihm verwendeten Technologien und Methoden werden als Knowledge-Engineering-Technologien und -Methoden bezeichnet. Ein Wissensingenieur hilft einem Experten, aus allen Informationen des Fachgebiets die Informationen zu identifizieren, die für die Arbeit mit einem bestimmten zu entwickelnden Expertensystem erforderlich sind, und es dann zu strukturieren. Es ist merkwürdig, dass das Fehlen von Wissensingenieuren unter den Teilnehmern an der Entwicklung, dh ihr Ersatz durch Programmierer, entweder zum Scheitern des gesamten Projekts zur Erstellung eines bestimmten Expertensystems führt oder die Zeit für seine Entwicklung erheblich verlängert. Und endlich, Programmierer entwickelt Werkzeuge (falls Werkzeuge neu entwickelt werden), die dazu bestimmt sind, die Entwicklung von Expertensystemen zu beschleunigen. Diese Werkzeuge enthalten im Endeffekt alle Hauptkomponenten eines Expertensystems; Der Programmierer verbindet seine Werkzeuge auch mit der Umgebung, in der sie verwendet werden. 4. Betriebsarten von Expertensystemen Das Expertensystem arbeitet in zwei Hauptmodi: 1) im Modus des Wissenserwerbs; 2) im Modus der Problemlösung (auch Konsultationsmodus oder Modus der Nutzung des Expertensystems genannt). Das ist logisch und verständlich, denn zunächst muss das Expertensystem sozusagen mit Informationen aus dem Fachgebiet geladen werden, in dem es arbeiten soll, dies ist der "Trainings"-Modus des Expertensystems, der Modus, wenn es erhält Wissen. Und nachdem alle für die Arbeit notwendigen Informationen geladen wurden, folgt die Arbeit selbst. Das Expertensystem wird betriebsbereit und kann nun für Beratungen oder zur Lösung etwaiger Probleme genutzt werden. Lassen Sie uns genauer betrachten Wissenserwerbsmodus. Im Modus des Wissenserwerbs wird die Arbeit mit dem Expertensystem von einem Experten durch einen Wissensingenieur ausgeführt. In diesem Modus füllt der Experte unter Verwendung der Wissensakquisitionskomponente das System mit Wissen (Daten), was wiederum dem System ermöglicht, Probleme aus diesem Themengebiet im Lösungsmodus ohne die Beteiligung eines Experten zu lösen. Es sei darauf hingewiesen, dass der Wissenserwerbsmodus im traditionellen Ansatz zur Programmentwicklung den Phasen der Algorithmusisierung, Programmierung und Fehlersuche entspricht, die direkt vom Programmierer durchgeführt werden. Daraus folgt, dass im Gegensatz zum traditionellen Ansatz bei Expertensystemen die Entwicklung von Programmen nicht von einem Programmierer, sondern von einem Experten durchgeführt wird, natürlich mit Hilfe von Expertensystemen, also im Großen und Ganzen , eine Person, die keine Programmierkenntnisse hat. Betrachten wir nun die zweite Funktionsweise des Expertensystems, d.h. Problemlösungsmodus. Im Problemlösungsmodus (oder im sogenannten Konsultationsmodus) erfolgt die Kommunikation mit Expertensystemen direkt durch den Endbenutzer, der am Endergebnis der Arbeit und manchmal am Verfahren zu seiner Erzielung interessiert ist. Es sei darauf hingewiesen, dass je nach Zweck des Expertensystems der Benutzer kein Experte auf diesem Problemgebiet sein muss. In diesem Fall wendet er sich an Expertensysteme, um das Ergebnis zu erhalten, da er nicht über ausreichende Kenntnisse verfügt, um Ergebnisse zu erhalten. Oder der Benutzer verfügt möglicherweise noch über einen ausreichenden Wissensstand, um das gewünschte Ergebnis selbst zu erzielen. In diesem Fall kann der Benutzer das Ergebnis selbst erhalten, wendet sich jedoch an Expertensysteme, um entweder den Prozess des Erhaltens des Ergebnisses zu beschleunigen oder monotone Arbeit den Expertensystemen zuzuweisen. Im Konsultationsmodus gelangen Daten über die Aufgabe des Benutzers, nachdem sie von der Dialogkomponente verarbeitet wurden, in den Arbeitsspeicher. Der Solver generiert auf der Grundlage von Eingabedaten aus dem Arbeitsspeicher, allgemeinen Daten über den Problembereich und Regeln aus der Datenbank eine Lösung für das Problem. Bei der Lösung eines Problems führen Expertensysteme nicht nur den vorgeschriebenen Ablauf einer bestimmten Operation aus, sondern bilden sie auch vorläufig. Dies geschieht für den Fall, dass die Reaktion des Systems für den Benutzer nicht ganz klar ist. In dieser Situation kann der Benutzer eine Erklärung verlangen, warum dieses Expertensystem eine bestimmte Frage stellt oder warum dieses Expertensystem diese Operation nicht ausführen kann, wie dieses oder jenes Ergebnis erhalten wird, das von diesem Expertensystem geliefert wird. 5. Produktionsmodell des Wissens In seinem Kern Produktionsmodelle des Wissens in der Nähe von logischen Modellen, wodurch Sie sehr effektive Verfahren für logische Datenrückschlüsse organisieren können. Das ist einerseits. Betrachtet man andererseits Produktionsmodelle des Wissens im Vergleich zu logischen Modellen, dann bilden erstere das Wissen klarer ab, was ein unbestreitbarer Vorteil ist. Daher ist das Produktionsmodell von Wissen zweifellos eines der wichtigsten Mittel zur Repräsentation von Wissen in Systemen der künstlichen Intelligenz. Beginnen wir also mit einer detaillierten Betrachtung des Konzepts eines Produktionsmodells des Wissens. Das traditionelle Produktionsmodell des Wissens umfasst die folgenden grundlegenden Komponenten: 1) eine Reihe von Regeln (oder Produktionen), die die Wissensbasis des Produktionssystems darstellen; 2) Arbeitsgedächtnis, das die ursprünglichen Fakten speichert, sowie Fakten, die von den ursprünglichen Fakten unter Verwendung des Inferenzmechanismus abgeleitet werden; 3) der logische Inferenzmechanismus selbst, der es erlaubt, aus den verfügbaren Fakten gemäß den bestehenden Inferenzregeln neue Fakten abzuleiten. Und seltsamerweise kann die Anzahl solcher Operationen unendlich sein. Jede Regel, die die Wissensbasis des Produktionssystems darstellt, enthält einen bedingten und einen abschließenden Teil. Der Bedingungsteil der Regel enthält entweder eine einzelne Tatsache oder mehrere Tatsachen, die durch eine Konjunktion verbunden sind. Der letzte Teil der Regel enthält Fakten, die mit dem Arbeitsspeicher aufgefüllt werden müssen, wenn der bedingte Teil der Regel wahr ist. Versucht man, das Produktionsmodell des Wissens schematisch darzustellen, so wird die Produktion als Ausdruck folgender Form verstanden: (i) Q; P; A→B; N; Hier ist i der Name des Wissensproduktionsmodells oder seine Seriennummer, mit deren Hilfe diese Produktion von der Gesamtheit der Produktionsmodelle unterschieden wird und eine Art Identifikation erhält. Eine lexikalische Einheit, die die Essenz dieses Produkts widerspiegelt, kann als Name fungieren. Tatsächlich benennen wir Produkte zur besseren Wahrnehmung durch das Bewusstsein, um die Suche nach dem gewünschten Produkt aus der Liste zu vereinfachen. Nehmen wir ein einfaches Beispiel: den Kauf eines Notizbuchs“ oder „eines Satzes Buntstifte. Offensichtlich wird jedes Produkt normalerweise mit Worten bezeichnet, die für den Moment geeignet sind. Mit anderen Worten, nennen Sie die Dinge beim Namen. Mach weiter. Das Q-Element charakterisiert den Umfang dieses speziellen Wissensproduktionsmodells. Solche Sphären sind im menschlichen Geist leicht zu unterscheiden, daher gibt es in der Regel keine Schwierigkeiten bei der Definition dieses Elements. Nehmen wir ein Beispiel. Stellen Sie sich folgende Situation vor: Nehmen wir an, in einem Bereich unseres Bewusstseins ist das Wissen gespeichert, wie man Essen zubereitet, in einem anderen, wie man zur Arbeit kommt, im dritten, wie man die Waschmaschine richtig bedient. Eine ähnliche Teilung ist auch im Gedächtnis des Produktionsmodells von Wissen vorhanden. Diese Aufteilung des Wissens in separate Bereiche ermöglicht es Ihnen, die Zeit für die Suche nach bestimmten Produktionsmodellen des Wissens, die derzeit benötigt werden, erheblich zu sparen, und vereinfacht dadurch den Prozess der Arbeit mit ihnen erheblich. Das Hauptelement der Produktion ist natürlich ihr sogenannter Kern, der in unserer obigen Formel als A → B bezeichnet wurde. Diese Formel kann interpretiert werden als „wenn Bedingung A erfüllt ist, dann sollte Aktion B ausgeführt werden.“ Handelt es sich um komplexere Kernkonstrukte, dann ist auf der rechten Seite folgende Alternativauswahl erlaubt: „Wenn Bedingung A erfüllt ist, dann soll Aktion B ausgeführt werden1, andernfalls sollten Sie Aktion B ausführen2". Die Interpretation des Kerns des Produktionsmodells von Wissen kann jedoch unterschiedlich sein und davon abhängen, was links und rechts vom nachfolgenden Zeichen "→" steht. Mit einer der Interpretationen des Kerns des Produktionsmodells des Wissens kann die Folge im üblichen logischen Sinne interpretiert werden, also als Zeichen der logischen Konsequenz der Handlung B aus der wahren Bedingung A. Dennoch sind auch andere Interpretationen des Kerns des Wissensproduktionsmodells möglich. So kann A beispielsweise eine Bedingung beschreiben, deren Erfüllung notwendig ist, damit eine Handlung B ausgeführt werden kann. Als nächstes betrachten wir ein Element des Wissensproduktionsmodells R. Element Р ist als Bedingung für die Anwendbarkeit des Produktkerns definiert. Wenn die Bedingung P wahr ist, wird der Produktionskern aktiviert. Andernfalls, wenn die Bedingung P nicht erfüllt ist, d. h. falsch ist, kann der Kern nicht aktiviert werden. Betrachten Sie als anschauliches Beispiel das folgende Wissensproduktionsmodell: „Verfügbarkeit von Geld“; "Wenn Sie Sache A kaufen möchten, dann sollten Sie die Kosten an der Kasse bezahlen und den Scheck dem Verkäufer vorlegen." Wir schauen, wenn die Bedingung P wahr ist, also der Kauf bezahlt und der Scheck vorgelegt wird, dann wird der Kern aktiviert. Kauf abgeschlossen. Wenn in diesem Wissensproduktionsmodell die Bedingung der Anwendbarkeit des Kerns falsch ist, d. h. kein Geld vorhanden ist, dann kann der Kern des Wissensproduktionsmodells nicht angewendet werden und wird nicht aktiviert. Und schließlich zum Element gehen N. Das Element N wird als Nachbedingung des Produktionsdatenmodells bezeichnet. Die Nachbedingung definiert die Aktionen und Prozeduren, die nach der Implementierung des Produktionskerns durchgeführt werden müssen. Zur besseren Wahrnehmung ein einfaches Beispiel: Nach dem Kauf einer Sache in einem Geschäft muss die Anzahl der Dinge dieser Art im Warenbestand dieses Geschäfts um eins reduziert werden, d.h. wenn der Kauf getätigt wird (also , der Kern ist verkauft), dann hat das Geschäft eine Einheit dieses bestimmten Produkts weniger. Daher die Nachbedingung „Einheit des gekauften Artikels durchstreichen“. Zusammenfassend lässt sich sagen, dass die Repräsentation von Wissen als Regelwerk, d. h. durch die Verwendung eines Produktionsmodells von Wissen, folgende Vorteile hat: 1) es ist die Leichtigkeit, individuelle Regeln zu erstellen und zu verstehen; 2) es ist die Einfachheit des logischen Wahlmechanismus. Allerdings gibt es bei der Repräsentation von Wissen in Form eines Regelwerks auch Nachteile, die Umfang und Häufigkeit der Anwendung von Produktionswissensmodellen noch einschränken. Der Hauptnachteil dieser Art ist die Mehrdeutigkeit der gegenseitigen Beziehungen zwischen den Regeln, die ein spezifisches Produktionsmodell des Wissens ausmachen, sowie den Regeln der logischen Wahl. Aufzeichnungen 1. Die unterstrichene Schriftart in der gedruckten Ausgabe des Buches entspricht Fett Kursiv in dieser (elektronischen) Version des Buches. (ca. e. Hrsg.)
▪ Krisenmanagement. Vorlesungsnotizen ▪ Pathologische Anatomie. Vorlesungsnotizen ▪ Geschichte der Weltreligionen. Krippe
Verkehrslärm verzögert das Wachstum der Küken
06.05.2024 Kabelloser Lautsprecher Samsung Music Frame HW-LS60D
06.05.2024 Eine neue Möglichkeit, optische Signale zu steuern und zu manipulieren
05.05.2024
▪ Signaturgröße und Narzissmus ▪ 300-GB-Freeze-Ray-Speichersystem für optische Platten ▪ Stromnetze vor Cyberangriffen schützen ▪ Organische LEDs für medizinische Geräte
▪ Abschnitt der Website Auto. Artikelauswahl ▪ Artikel Verkehrsunfälle. Warnregeln. Grundlagen eines sicheren Lebens ▪ Artikel Wie alt sind Kegelspiele? Ausführliche Antwort ▪ Artikel über Autopfleger. Enzyklopädie der Funkelektronik und Elektrotechnik ▪ Artikel Erfahrungen mit Wärmeleitfähigkeit. physikalisches Experiment
Startseite | Bibliothek | Artikel | Sitemap | Site-Überprüfungen
www.diagramm.com.ua |



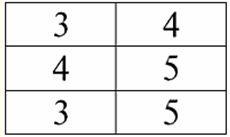
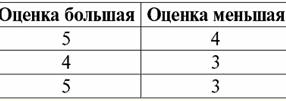

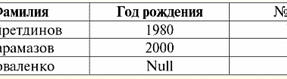

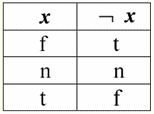

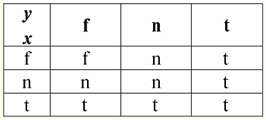
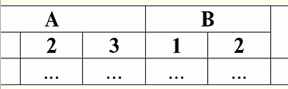


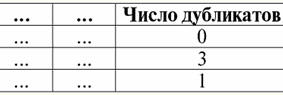
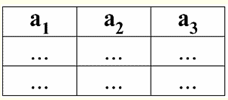






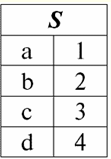
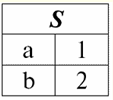

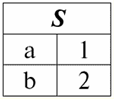

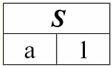
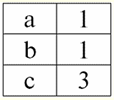

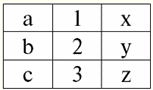









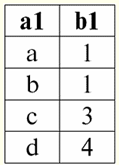






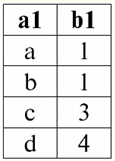



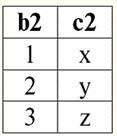

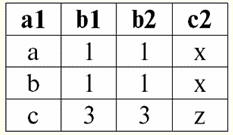




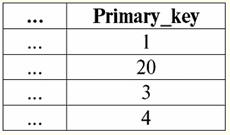

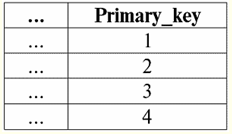

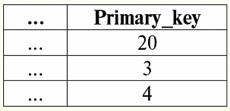
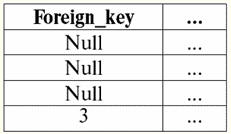

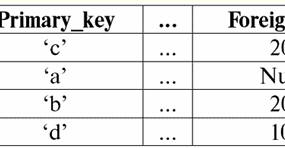








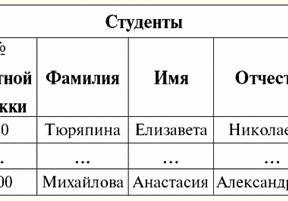
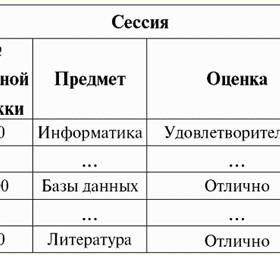




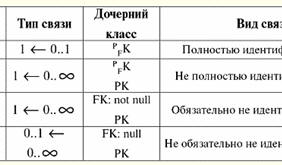









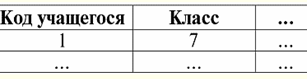
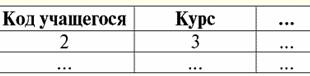





 Siehe andere Artikel Abschnitt
Siehe andere Artikel Abschnitt 