|
|






 Arabic
Arabic Bengali
Bengali Chinese
Chinese English
English French
French German
German Hebrew
Hebrew Hindi
Hindi Italian
Italian Japanese
Japanese Korean
Korean Malay
Malay Polish
Polish Portuguese
Portuguese Spanish
Spanish Turkish
Turkish Ukrainian
Ukrainian Vietnamese
Vietnamese
Vorlesungsunterlagen, Spickzettel
Allgemeine Theorie der Statistik. Vorlesungszusammenfassung: kurz das Wichtigste
Verzeichnis / Vorlesungsunterlagen, Spickzettel Inhaltsverzeichnis
VORTRAG Nr. 1. Statistik als Wissenschaft 1. Gegenstand und Methode der Statistik als Sozialwissenschaft Statistik - eine eigenständige Sozialwissenschaft, die über einen eigenen Gegenstand und eigene Forschungsmethoden verfügt, die aus den Bedürfnissen des gesellschaftlichen Lebens entstanden sind. Statistik ist eine Wissenschaft, die die quantitative Seite aller sozioökonomischen Phänomene untersucht. Der Begriff „Statistik“ kommt vom lateinischen Wort „Status“, was „Stellung, Ordnung“ bedeutet. Zum ersten Mal wurde es von dem deutschen Wissenschaftler G. Achenwal (1719-1772) verwendet. Die Hauptaufgabe der Statistik besteht darin, die gesammelten Informationen mathematisch korrekt zu beschreiben. Statistik kann als ein spezieller Bereich der Mathematik bezeichnet werden, der die eine oder andere Seite des menschlichen Lebens beschreibt. Statistik verwendet eine Vielzahl von mathematischen Methoden und Techniken, damit eine Person ein bestimmtes Problem analysieren kann. Statistiken können jedem Leiter in jedem Unternehmen eine unschätzbare Hilfe sein, wenn Sie wissen, wie man sie richtig einsetzt. Bis heute wird der Begriff „Statistik“ in drei Bedeutungen verwendet: 1) ein spezieller Zweig der praktischen Tätigkeit von Personen, die darauf abzielen, Daten zu sammeln, zu verarbeiten und zu analysieren, die die sozioökonomische Entwicklung des Landes, seiner Regionen, einzelner Wirtschaftszweige oder Unternehmen charakterisieren; 2) eine Wissenschaft, die theoretische Bestimmungen und Methoden entwickelt, die in der statistischen Praxis verwendet werden; 3) Statistiken - statistische Daten, die in den Berichten von Unternehmen, Wirtschaftssektoren sowie in Sammlungen, verschiedenen Verzeichnissen, Bulletins usw. veröffentlichten Daten enthalten sind. Statistikobjekt - Phänomene und Prozesse des sozioökonomischen Lebens der Gesellschaft, in denen die sozioökonomischen Beziehungen der Menschen dargestellt werden und ihren Ausdruck finden. Die allgemeine Theorie der Statistik ist die methodische Grundlage, der Kern jeder sektoralen Statistik. Sie entwickelt allgemeine Prinzipien und Methoden für die statistische Untersuchung sozialer Phänomene und ist die allgemeinste Kategorie der Statistik. Die Aufgaben der Wirtschaftsstatistik sind die Entwicklung und Analyse synthetischer Indikatoren, die den Zustand der Volkswirtschaft, das Verhältnis der Branchen, die Verteilung der Produktivkräfte, die Verfügbarkeit von Material, Arbeitskräften und finanziellen Ressourcen widerspiegeln. Die Sozialstatistik entwickelt ein System von Indikatoren zur Charakterisierung der Lebensweise der Bevölkerung und verschiedener Aspekte sozialer Beziehungen. Statistik - Sozialwissenschaft, die sich mit der Sammlung von Informationen anderer Art, ihrer Ordnung, ihrem Vergleich, ihrer Analyse und ihrer Interpretation (Erklärung) beschäftigt. Es hat folgende Besonderheiten: 1) untersucht die quantitative Seite sozialer Phänomene. Diese Seite des Phänomens repräsentiert seine Größenordnung, Größe, sein Volumen und hat eine numerische Dimension; 2) untersucht die qualitative Seite von Massenphänomenen. Die bereitgestellte Seite des Phänomens drückt seine Besonderheit aus, das innere Merkmal, das es von anderen Phänomenen unterscheidet. Die qualitative und die quantitative Seite eines Phänomens existieren immer zusammen, bilden ein einziges Ganzes. Alle sozialen Phänomene und Ereignisse finden in Zeit und Raum statt, und in Bezug auf jedes von ihnen kann immer festgestellt werden, wann es entstanden ist und wohin es sich entwickelt hat. Die Statistik untersucht also Phänomene unter bestimmten räumlichen und zeitlichen Bedingungen. Die von der Statistik erfassten Phänomene und Prozesse des gesellschaftlichen Lebens befinden sich in ständiger Veränderung und Entwicklung. Basierend auf der Sammlung, Verarbeitung und Analyse von Massendaten zu Veränderungen in den untersuchten Phänomenen und Prozessen wird eine statistische Regelmäßigkeit offenbart. Statistische Regelmäßigkeiten manifestieren die Wirkungen sozialer Gesetze, die das Bestehen und die Entwicklung sozioökonomischer Beziehungen in der Gesellschaft bestimmen. Das Thema Statistik ist das Studium sozialer Phänomene, der Dynamik und Richtung ihrer Entwicklung. Mit Hilfe statistischer Indikatoren stellt die Statistik die quantitative Seite eines sozialen Phänomens fest und beobachtet die Muster des Übergangs von Quantität in Qualität am Beispiel eines bestimmten sozialen Phänomens. Auf der Grundlage der gemachten Beobachtungen analysiert die Statistik die unter bestimmten räumlichen und zeitlichen Bedingungen gewonnenen Daten. Die Statistik befasst sich mit der Untersuchung sozioökonomischer Phänomene und Prozesse, die massiver Natur sind, und untersucht auch die vielen Faktoren, die sie bestimmen. Um ihre theoretischen Gesetze abzuleiten und zu bestätigen, verwenden die meisten Sozialwissenschaften Statistiken. Die Schlussfolgerungen aus statistischen Studien werden von Wirtschaftswissenschaften, Geschichte, Soziologie, Politikwissenschaft und vielen anderen Geisteswissenschaften verwendet. Statistik ist auch für die Sozialwissenschaften notwendig, um ihre theoretische Grundlage zu bestätigen, und ihre praktische Rolle ist sehr groß. Weder große Unternehmen noch seriöse Industrien kommen bei der Entwicklung einer Strategie zur wirtschaftlichen und sozialen Entwicklung eines Objekts ohne die Analyse statistischer Daten aus. Zu diesem Zweck werden in Unternehmen und Industrien spezielle analytische Abteilungen und Dienste organisiert, die Spezialisten mit einer abgeschlossenen Berufsausbildung in dieser Disziplin anziehen. Die Statistik hat wie jede andere Wissenschaft eine Reihe von Methoden, um ihr Thema zu studieren. Die Methoden der Statistik werden je nach untersuchtem Phänomen und konkretem Forschungsgegenstand (Zusammenhänge, Muster oder Entwicklung) gewählt. Methoden in der Statistik werden in der Gesamtheit aus den entwickelten und angewandten spezifischen Methoden und Techniken zur Untersuchung sozialer Phänomene gebildet. Dazu gehören Beobachtung, Zusammenfassung und Gruppierung von Daten, Berechnung verallgemeinernder Indikatoren auf der Grundlage spezieller Methoden (Mittelwertmethode, Indizes usw.). In dieser Hinsicht gibt es drei Phasen der Arbeit mit statistischen Daten: 1) Sammlung ist eine wissenschaftlich organisierte Massenbeobachtung, durch die Primärinformationen über einzelne Fakten (Einheiten) des untersuchten Phänomens gewonnen werden. Diese statistische Erfassung einer großen Anzahl oder aller Einheiten, aus denen das untersuchte Phänomen besteht, ist die Informationsbasis für statistische Verallgemeinerungen, um Rückschlüsse auf das untersuchte Phänomen oder den untersuchten Prozess zu ziehen; 2) Gruppierung und Zusammenfassung. Unter diesen Daten versteht man die Verteilung einer Menge von Fakten (Einheiten) in homogene Gruppen und Untergruppen, die Endauszählung für jede Gruppe und Untergruppe und die Darstellung der Ergebnisse in Form einer statistischen Tabelle; 3) Verarbeitung und Analyse. Die statistische Analyse schließt die Phase der statistischen Forschung ab. Es umfasst die Verarbeitung statistischer Daten, die während der Zusammenfassung erhalten wurden, die Interpretation der erhaltenen Ergebnisse, um objektive Schlussfolgerungen über den Zustand des untersuchten Phänomens und über die Muster seiner Entwicklung zu erhalten. Im Prozess der statistischen Analyse werden die Struktur, Dynamik und Verflechtung sozialer Phänomene und Prozesse untersucht. Die Hauptphasen der statistischen Analyse sind: 1) Behauptung von Tatsachen und Feststellung ihrer Einschätzung; 2) Identifizierung charakteristischer Merkmale und Ursachen des Phänomens; 3) Vergleich des Phänomens mit normativen, geplanten und anderen Phänomenen, die als Grundlage für den Vergleich genommen werden; 4) Formulierung von Schlussfolgerungen, Prognosen, Annahmen und Hypothesen; 5) statistische Überprüfung der vorgeschlagenen Annahmen (Hypothesen). 2. Theoretische Grundlagen und Grundbegriffe der Statistik Für die statistische Methodik ist die theoretische Grundlage das dialektisch-materialistische Verständnis der Gesetzmäßigkeiten des Entwicklungsprozesses der Gesellschaft. Infolgedessen verwendet die Statistik häufig Kategorien wie Quantität und Qualität, Notwendigkeit und Zufall, Regelmäßigkeit, Kausalität usw. Die Hauptbestimmungen der Statistik basieren auf den Gesetzen der Sozial- und Wirtschaftstheorie, da sie die Entwicklungsmuster sozialer Phänomene berücksichtigen, ihre Bedeutung, Ursachen und Folgen für das Leben der Gesellschaft bestimmen. Andererseits werden die Gesetze vieler Sozialwissenschaften auf der Grundlage von Statistiken und Mustern erstellt, die durch statistische Analysen identifiziert wurden, sodass wir sagen können, dass die Beziehung zwischen Statistik und anderen Sozialwissenschaften endlos und kontinuierlich ist. Die Statistik stellt die Gesetze der Sozialwissenschaften auf, und diese wiederum korrigieren die Bestimmungen der Statistik. Auch die theoretischen Grundlagen der Statistik sind eng mit der Mathematik verwandt, da es notwendig ist, mathematische Indikatoren, Gesetzmäßigkeiten und Methoden anzuwenden, um quantitative Merkmale zu messen, zu vergleichen und zu analysieren. Eine gründliche Untersuchung der Dynamik eines Phänomens, seiner zeitlichen Veränderung sowie seiner Beziehung zu anderen Phänomenen ist ohne den Einsatz höherer Mathematik und mathematischer Analyse unmöglich. Sehr oft basiert eine statistische Studie auf einem entwickelten mathematischen Modell eines Phänomens. Ein solches Modell spiegelt theoretisch die quantitativen Verhältnisse des untersuchten Phänomens wider. Aufgabe der Statistik ist es, sofern vorhanden, die im Modell enthaltenen Parameter numerisch zu ermitteln. Bei der Beurteilung der Finanzlage eines Unternehmens wird häufig das Scoring-Modell von A. Altman verwendet, bei dem die Insolvenzhöhe Z nach folgender Formel berechnet wird: Z=1,2x1 + 1,4x2 + 3,3x3 + 0,6x4 + 10,0x5, wo x1 - das Verhältnis des Fremdkapitals zur Höhe des Gesellschaftsvermögens; x2 - das Verhältnis der nicht ausgeschütteten Erträge zur Höhe des Vermögens; x3 - das Verhältnis der Betriebseinnahmen zur Höhe des Vermögens; x4 - das Verhältnis des Marktwerts der Aktien der Gesellschaft zum Gesamtschuldenbetrag; x5 - das Verhältnis der Höhe der Verkäufe zur Höhe der Vermögenswerte. Laut A. Altman droht der Firma der Bankrott, wenn Z < 2,675 ist, und wenn Z > 2,675 ist, ist die Finanzlage der Firma unbesorgt. Um diese Schätzung zu erhalten, ist es notwendig, das unbekannte x in die Formel einzusetzen1, X2, X3, X4 und x5, die bestimmte Indikatoren für Gleichgewichtslinien sind. Besonders weit verbreitet in der Statistikwissenschaft sind Bereiche der Mathematik wie die Wahrscheinlichkeitstheorie und die mathematische Statistik. Die Statistik verwendet Operationen, die direkt nach den Regeln der Wahrscheinlichkeitstheorie berechnet werden. Dies ist eine selektive Beobachtungsmethode. Die wichtigste dieser Regeln ist eine Reihe von Theoremen, die das Gesetz der großen Zahlen ausdrücken. Der Kern dieses Gesetzes besteht darin, dass im zusammenfassenden Indikator das Element der Zufälligkeit, mit dem einzelne Merkmale verbunden sind, verschwindet, da immer mehr von ihnen darin kombiniert werden. Die mathematische Statistik ist auch eng mit der Wahrscheinlichkeitstheorie verwandt. Die darin betrachteten Aufgaben lassen sich in drei Kategorien einteilen: Verteilung (Mengenstruktur), Verbindungen (zwischen Merkmalen), Dynamik (Veränderung über die Zeit). Die Analyse von Variationsreihen ist weit verbreitet, die Vorhersage der Entwicklung von Phänomenen erfolgt mit Hilfe von Extrapolationen. Kausale Zusammenhänge von Phänomenen und Prozessen werden mittels Korrelations- und Regressionsanalyse eingeführt. Schließlich verdankt die statistische Wissenschaft der mathematischen Statistik ihre wichtigsten Kategorien und Begriffe wie Totalität, Variation, Vorzeichen, Regelmäßigkeit. Das statistische Aggregat gehört zu den Hauptkategorien der Statistik und ist Gegenstand der statistischen Forschung, das heißt der systematischen wissenschaftlich fundierten Sammlung von Informationen über die sozioökonomischen Phänomene des öffentlichen Lebens und der Analyse der gewonnenen Daten. Um statistische Untersuchungen durchführen zu können, ist eine wissenschaftlich fundierte Informationsbasis erforderlich. Eine solche Informationsbasis ist ein statistisches Aggregat – eine Menge sozioökonomischer Objekte oder Phänomene des gesellschaftlichen Lebens, die durch eine gemeinsame Verbindung, eine qualitative Basis verbunden sind, sich aber in bestimmten Merkmalen voneinander unterscheiden (z. B. eine Menge von Haushalten, Familien). , Firmen usw.). Aus Sicht der statistischen Methodik ist eine statistische Population eine Menge von Einheiten, die Eigenschaften wie Einheitlichkeit, Massencharakter, eine gewisse Integrität, das Vorhandensein von Variationen und die gegenseitige Abhängigkeit des Zustands einzelner Einheiten aufweisen. Die Grundgesamtheit besteht also aus einzelnen Einheiten. Ein Objekt, eine Person, eine Tatsache, ein Vorgang kann eine Einheit der Gesamtheit sein. Die Einheit der Bevölkerung ist das primäre Element und Träger ihrer Hauptmerkmale. Das Element der Bevölkerung, für das die notwendigen Daten für eine statistische Studie erhoben werden, wird als Beobachtungseinheit bezeichnet. Die Anzahl der Einheiten in der Bevölkerung wird als Bevölkerungsgröße bezeichnet. Das statistische Aggregat kann die Bevölkerung während der Volkszählung, Unternehmen, Städte, Mitarbeiter des Unternehmens sein. Die Wahl einer statistischen Grundgesamtheit und ihrer Einheiten hängt von den spezifischen Bedingungen und der Art des untersuchten sozioökonomischen Phänomens oder Prozesses ab. Die Massennatur der Bevölkerungseinheiten hängt eng mit ihrer Vollständigkeit zusammen. Die Vollständigkeit wird durch die Erfassung von Einheiten der untersuchten Grundgesamtheit gewährleistet. Beispielsweise muss der Forscher einen Rückschluss auf die Entwicklung des Bankwesens ziehen. Daher muss er Informationen über alle in der Region tätigen Banken sammeln. Da jede Menge einen ziemlich komplexen Charakter hat, sollte Vollständigkeit als die Erfassung der Menge verschiedenster Merkmale der Menge verstanden werden, die das untersuchte Phänomen zuverlässig und wesentlich beschreiben. Werden beispielsweise Finanzergebnisse nicht in den Prozess der Bankenüberwachung einbezogen, lassen sich keine endgültigen Rückschlüsse auf die Entwicklung des Bankensystems ziehen. Darüber hinaus legt die Vollständigkeit nahe, die Merkmale der Bevölkerungseinheiten über möglichst lange Zeiträume zu untersuchen. Ziemlich vollständige Daten sind in der Regel umfangreich und erschöpfend. Die in der Praxis untersuchten sozioökonomischen Phänomene sind sehr vielfältig, daher ist es schwierig und manchmal sogar unmöglich, alle Phänomene abzudecken. Der Forscher ist gezwungen, nur einen Teil der statistischen Population zu untersuchen und Schlussfolgerungen für die gesamte Population zu ziehen. In solchen Situationen ist die wichtigste Anforderung die vernünftige Auswahl des Teils der Bevölkerung, für den die Merkmale untersucht werden. Dieser Teil soll die wesentlichen Eigenschaften, Phänomene darstellen und typisch sein. Tatsächlich können bei den untersuchten Phänomenen und Prozessen mehrere Aggregate gleichzeitig interagieren. In diesen Situationen wird der Untersuchungsgegenstand so gefunden, dass die untersuchten Populationen klar unterschieden werden können. Ein Merkmal einer Einheit eines Aggregats ist sein charakteristisches Merkmal, eine bestimmte Eigenschaft, Eigenschaft, Qualität, die beobachtet und gemessen werden kann. Die untersuchte Population muss zeitlich oder räumlich vergleichbar sein. An die Merkmale der Bevölkerungseinheiten werden folglich die Anforderungen ihrer Vergleichbarkeit und Einheitlichkeit gestellt. Dazu ist es beispielsweise erforderlich, einheitliche Kostenvoranschläge zu verwenden. Um die Gesamtheit qualitativ zu untersuchen, werden die signifikantesten oder zusammenhängendsten Merkmale untersucht. Die Anzahl der Merkmale, die die Bevölkerungseinheit charakterisieren, sollte nicht übermäßig sein. Dies erschwert die Erhebung von Daten und die Verarbeitung der Ergebnisse. Die Merkmale der Einheiten der statistischen Grundgesamtheit müssen so kombiniert werden, dass sie sich ergänzen und voneinander abhängig sind. Das Erfordernis der Homogenität der statistischen Grundgesamtheit bedeutet die Wahl des Kriteriums, nach dem die eine oder andere Einheit zur untersuchten Grundgesamtheit gehört. Wenn zum Beispiel die Initiative junger Wähler untersucht wird, dann ist es notwendig, Altersgrenzen für solche Wähler festzulegen, um Menschen der älteren Generation auszuschließen. Es ist möglich, eine solche Population auf Vertreter ländlicher Gebiete oder beispielsweise Studenten zu beschränken. Das Vorhandensein von Variationen in den Einheiten der Bevölkerung bedeutet, dass ihre Merkmale in einigen Einheiten der Bevölkerung alle Arten von Werten oder Modifikationen erhalten können. In diesem Zusammenhang werden solche Zeichen als variierend und einzelne Werte oder Modifikationen als Varianten bezeichnet. Zeichen werden in attributive und quantitative unterteilt. Ein Zeichen wird als attributiv oder qualitativ bezeichnet, wenn es durch einen semantischen Begriff ausgedrückt wird, beispielsweise das Geschlecht einer Person oder ihre Zugehörigkeit zu einer bestimmten sozialen Gruppe. Intern werden sie in nominal und ordinal unterteilt. Ein Attribut heißt quantitativ, wenn es als Zahl ausgedrückt wird. Entsprechend der Art der Variation werden quantitative Zeichen in diskrete und kontinuierliche unterteilt. Ein Beispiel für ein diskretes Merkmal ist die Anzahl der Personen in einer Familie. In Form von ganzen Zahlen werden in der Regel Varianten diskreter Merkmale ausgedrückt. Kontinuierliche Merkmale sind beispielsweise Alter, Gehalt, Betriebszugehörigkeit etc. Je nach Messmethode werden Zeichen in primäre (erfasste) und sekundäre (berechnete) unterteilt. Primäre (erfasste) drücken die Einheit der Bevölkerung als Ganzes aus, d. h. absolute Werte. Sekundäre (berechnete) werden nicht direkt gemessen, sondern berechnet (Kosten, Produktivität). Primärmerkmale liegen der Beobachtung einer statistischen Grundgesamtheit zugrunde, während Sekundärmerkmale im Prozess der Datenverarbeitung und -analyse ermittelt werden und das Verhältnis von Primärmerkmalen darstellen. In Bezug auf das charakterisierte Objekt werden Zeichen in direkte und indirekte Zeichen unterteilt. Direkte Attribute sind Eigenschaften, die dem zu charakterisierenden Objekt direkt innewohnen (Produktionsvolumen, Alter einer Person). Indirekte Attribute sind Eigenschaften, die nicht für das Objekt selbst, sondern für andere mit dem Objekt verbundene oder darin enthaltene Aggregate charakteristisch sind. Zeitlich werden Momentan- und Intervallzeichen unterschieden. Momentane Zeichen charakterisieren das untersuchte Objekt zu einem bestimmten Zeitpunkt, der durch den Plan der statistischen Forschung festgelegt wurde. Intervallzeichen charakterisieren die Ergebnisse von Prozessen. Ihre Werte können nur über ein Zeitintervall auftreten. Neben Zeichen wird der Zustand des Untersuchungsobjekts oder der Grundgesamtheit durch Indikatoren charakterisiert. Daten - eines der Hauptkonzepte der Statistik, das eine verallgemeinerte quantitative Bewertung sozioökonomischer Prozesse und Phänomene ist. Entsprechend den Zielfunktionen werden statistische Kennzahlen in Bilanzierung und Auswertung und Analytik unterteilt. Rechnungslegung und geschätzte Indikatoren - Dies ist ein statistisches Merkmal der Größe sozioökonomischer Phänomene unter den festgelegten Bedingungen von Ort und Zeit, d. H. Sie spiegeln das Verteilungsvolumen im Raum oder die zu einem bestimmten Zeitpunkt erreichten Niveaus wider. Analytische Indikatoren werden verwendet, um die Daten der untersuchten statistischen Population zu analysieren und die Besonderheiten der Entwicklung der untersuchten Phänomene zu charakterisieren. Als analytische Indikatoren in der Statistik werden Relativwerte, Durchschnittswerte, Variations- und Dynamikindikatoren sowie Kommunikationsindikatoren verwendet. Die Gesamtheit der statistischen Indikatoren, die die Beziehungen widerspiegeln, die zwischen Phänomenen bestehen, bildet ein System statistischer Indikatoren. Im Allgemeinen charakterisieren und beschreiben Indikatoren und Zeichen die statistische Population vollständig und beschreiben sie umfassend, sodass der Forscher eine vollständige Untersuchung der Phänomene und Prozesse des Lebens der menschlichen Gesellschaft durchführen kann, was eines der Ziele der statistischen Wissenschaft ist. Die zentrale Kategorie der Statistik ist die statistische Regelmäßigkeit. Unter Regelmäßigkeit versteht man allgemein einen nachweisbaren kausalen Zusammenhang zwischen Phänomenen, die Abfolge und Wiederholung einzelner Merkmale, die das Phänomen charakterisieren. Unter Regelmäßigkeit versteht man in der Statistik die quantitative Regelmäßigkeit räumlicher und zeitlicher Veränderungen von Massenphänomenen und Prozessen des gesellschaftlichen Lebens infolge der Wirkung objektiver Gesetze. Folglich ist die statistische Regelmäßigkeit nicht für einzelne Bevölkerungseinheiten, sondern für die gesamte Bevölkerung als Ganzes charakteristisch und kommt nur bei einer ausreichend großen Anzahl von Beobachtungen zum Ausdruck. Die statistische Regelmäßigkeit offenbart sich also als durchschnittliche soziale Massenregelmäßigkeit in der gegenseitigen Aufhebung individueller Abweichungen der Zeichenwerte in die eine oder andere Richtung. Die Manifestation einer statistischen Regelmäßigkeit gibt uns also die Möglichkeit, ein allgemeines Bild des Phänomens darzustellen, den Trend seiner Entwicklung zu untersuchen, ohne zufällige, individuelle Abweichungen. 3. Moderne Organisation der Statistik in der Russischen Föderation Statistik spielt eine wichtige Rolle bei der Steuerung der wirtschaftlichen und sozialen Entwicklung des Landes, da die Richtigkeit einer Management-Schlussfolgerung weitgehend von den Informationen abhängt, auf deren Grundlage sie getroffen wird. Nur genaue, zuverlässige und korrekt analysierte Daten sollten auf hoher Managementebene berücksichtigt werden. Die Untersuchung der wirtschaftlichen und sozialen Entwicklung des Landes, einzelner Regionen, Branchen, Firmen und Unternehmen wird von speziell gebildeten Stellen durchgeführt, die den statistischen Dienst bilden. In der Russischen Föderation werden die Funktionen des statistischen Dienstes von den statistischen Ämtern der Departements und den staatlichen statistischen Ämtern wahrgenommen. Das höchste Leitungsgremium für Statistik ist das Staatliche Statistikkomitee der Russischen Föderation. Es löst die Hauptaufgaben, vor denen die russische Statistik derzeit steht, bietet eine ganzheitliche methodische Grundlage für die Rechnungslegung, konsolidiert und analysiert die erhaltenen Informationen, fasst die Daten zusammen und veröffentlicht die Ergebnisse seiner Aktivitäten. Das Staatliche Komitee für Statistik der Russischen Föderation (Goskomstat of Russia) wurde gemäß dem Dekret des Präsidenten der Russischen Föderation vom 6. Dezember 1999 Nr. 1600 „Über die Umwandlung des Statistischen Amtes der Russischen Föderation in das Staatliche Komitee von der Russischen Föderation über Statistik". Das Staatliche Statistikkomitee der Russischen Föderation ist ein föderales Exekutivorgan, das für die ressortübergreifende Koordinierung und funktionale Regulierung im Bereich der staatlichen Statistik zuständig ist. Das Staatliche Komitee für Statistik der Russischen Föderation erfüllt folgende Aufgaben: 1) führt die Erhebung, Verarbeitung, den Schutz und die Speicherung statistischer Informationen, die Wahrung von Staats- und Geschäftsgeheimnissen, die erforderliche Vertraulichkeit von Daten durch; 2) gewährleistet das Funktionieren des einheitlichen staatlichen Registers von Unternehmen und Organisationen (EGRPO) auf der Grundlage der Rechnungslegung für alle wirtschaftlichen Einheiten auf dem Territorium der Russischen Föderation mit der Zuweisung von Identifikationscodes an sie, basierend auf den allrussischen Klassifikatoren von technische, wirtschaftliche und soziale Informationen; 3) Entwicklung einer wissenschaftlich fundierten statistischen Methodik, die den Bedürfnissen der Gesellschaft in der gegenwärtigen Phase sowie internationalen Standards entspricht; 4) überprüft die Umsetzung der Gesetze der Russischen Föderation, der Beschlüsse des Präsidenten der Russischen Föderation, der Regierung der Russischen Föderation über Statistiken durch alle juristischen und anderen Wirtschaftssubjekte; 5) erlässt Beschlüsse und Anweisungen zu statistischen Fragen, die für alle juristischen und anderen wirtschaftlichen Einheiten auf dem Territorium der Russischen Föderation verbindlich sind. Die vom Staatlichen Komitee für Statistik Russlands angenommenen Methoden der statistischen Indikatoren, Methoden und Formen der Erhebung und Verarbeitung statistischer Daten sind die offiziellen statistischen Standards der Russischen Föderation. Der Goskomstat Russlands orientiert sich bei seinen Hauptaktivitäten an föderalen Statistikprogrammen, die unter Berücksichtigung der Vorschläge der föderalen Exekutive und Legislative, der staatlichen Behörden der Teilstaaten der Russischen Föderation, wissenschaftlicher und anderer Organisationen gebildet und von ihnen genehmigt werden Goskomstat Russlands im Einvernehmen mit der Regierung der Russischen Föderation. Die Hauptaufgaben der statistischen Ämter des Landes bestehen darin, die Veröffentlichung und Zugänglichkeit allgemeiner (nicht individueller) Informationen sicherzustellen sowie die Zuverlässigkeit, Wahrhaftigkeit und Genauigkeit der berücksichtigten Daten zu gewährleisten. Darüber hinaus sind die Aufgaben des Staatlichen Komitees für Statistik Russlands: 1) Übermittlung amtlicher statistischer Informationen an den Präsidenten der Russischen Föderation, die Bundesversammlung der Russischen Föderation, die Regierung der Russischen Föderation, föderale Exekutivbehörden, die Öffentlichkeit sowie internationale Organisationen; 2) Entwicklung einer wissenschaftlich erprobten statistischen Methodik, die den Bedürfnissen der Gesellschaft in der gegenwärtigen Phase sowie internationalen Standards entspricht; 3) Koordinierung der statistischen Aktivitäten der föderalen Exekutivbehörden und der Exekutivbehörden der Teileinheiten der Russischen Föderation, Bereitstellung von Bedingungen für die Anwendung offizieller statistischer Standards durch diese Behörden bei der Durchführung sektoraler (departementaler) statistischer Beobachtungen; 4) Entwicklung und Analyse von wirtschaftlichen und statistischen Informationen, Erstellung der erforderlichen Bilanzberechnungen und Volkswirtschaftlichen Gesamtrechnungen; 5) Gewährleistung vollständiger und wissenschaftlich fundierter statistischer Informationen; 6) Gewährleistung des gleichen Zugangs aller Nutzer zu offenen statistischen Informationen durch die Verbreitung offizieller Berichte über die sozioökonomische Lage der Russischen Föderation, die Teileinheiten der Russischen Föderation, Branchen und Wirtschaftssektoren, die Veröffentlichung statistischer Sammlungen und anderer statistischer Daten Materialien. Als Folge der Wirtschaftsreform der Russischen Föderation hat sich auch die Struktur der statistischen Ämter geändert. Lokale statistische Kreisregister wurden abgeschafft und bezirksübergreifende statistische Ämter gebildet, die Repräsentanzen der territorialen statistischen Ämter sind. Die Organisation der statistischen Stellen in Russland befindet sich derzeit im Reformstadium. Wie oben erwähnt, unterliegt die statistische Wissenschaft in Russland derzeit einigen Veränderungen. Die wichtigsten Bereiche, in denen Reformen durchgeführt werden sollten, können festgestellt werden: 1) Es ist notwendig, das Grundgesetz der statistischen Rechnungslegung einzuhalten - Publizität und Verfügbarkeit von Informationen unter Wahrung der Vertraulichkeit einzelner Indikatoren (Geschäftsgeheimnisse); 2) es ist notwendig, die methodischen und organisatorischen Grundlagen der Statistik zu reformieren: Eine Änderung der allgemeinen Aufgaben und Prinzipien der Wirtschaftsführung führt zu einer Änderung der theoretischen Bestimmungen der Wissenschaft; 3) der Übergang zur Marktstatistik führt zu der Notwendigkeit, das System zur Erhebung und Verarbeitung von Informationen zu verbessern, indem Beobachtungsformen wie Qualifikationen, Register (Register), Volkszählungen usw. eingeführt werden; 4) Es ist notwendig, die Methodik zur Berechnung einiger statistischer Indikatoren, die den Zustand der Wirtschaft der Russischen Föderation charakterisieren, zu ändern (verbessern), wobei unter Berücksichtigung internationaler Standards und ausländischer Erfahrungen in der statistischen Rechnungslegung alle Indikatoren zu systematisieren sind und sie unter Berücksichtigung des Systems der Volkswirtschaftlichen Gesamtrechnungen (SNA) den Fragestellungen und Erfordernissen der Zeit entsprechend ordnen; 5) Es ist notwendig, die Beziehung zwischen statistischen Indikatoren sicherzustellen, die den Entwicklungsstand des öffentlichen Lebens des Landes charakterisieren. 6) Trends bei der Computerisierung sollten berücksichtigt werden. Im Zuge der Reformierung der Statistikwissenschaft soll eine einheitliche Informationsbasis (System) geschaffen werden, die die Informationsbasen aller statistischen Stellen umfasst, die auf der hierarchischen Hierarchiestufe der Organisation der staatlichen Statistik nachgeordnet sind. So vollziehen sich in Russland nach wie vor strukturelle Veränderungen, die alle Bereiche des öffentlichen Lebens des Landes betreffen. Da die Statistik mit fast allen diesen Bereichen in direktem Zusammenhang steht, ist auch der Reformprozess nicht daran vorbeigegangen. Derzeit ist viel Arbeit in die Organisation der Arbeit der statistischen Ämter investiert worden, aber noch nicht abgeschlossen, und der Verbesserung dieser für den Staat sehr wichtigen Informationsinstitution muss noch viel Aufmerksamkeit geschenkt werden. Neben den Statistischen Landesämtern gibt es die Ressortstatistik, die in Ministerien, Ämtern, Unternehmen, Verbänden und Firmen verschiedener Wirtschaftszweige geführt wird. Die Abteilung Statistik befasst sich mit der Erhebung, Verarbeitung und Analyse statistischer Informationen. Diese Informationen sind notwendig, um Managemententscheidungen zu treffen und die Aktivitäten einer Organisation oder Behörde zu planen. In kleinen Unternehmen wird diese Arbeit normalerweise entweder vom Hauptbuchhalter oder direkt vom Manager selbst ausgeführt. Bei großen Unternehmen, die über eine eigene regional verzweigte Struktur oder eine große Zahl von Mitarbeitern verfügen, sind ganze Abteilungen oder Abteilungen an der Verarbeitung und Analyse statistischer Informationen beteiligt. An solchen Arbeiten sind Spezialisten auf dem Gebiet der Statistik, Mathematik, Rechnungslegung und Wirtschaftsanalyse, Manager und Technologen beteiligt. Ein solches Team, das mit moderner Computertechnologie ausgestattet ist, auf der von der Statistiktheorie vorgeschlagenen Methodik basiert und moderne Analysemethoden anwendet, hilft beim Aufbau effektiver Strategien zur Geschäftsentwicklung sowie bei der effektiven Gestaltung der Aktivitäten öffentlicher Behörden. Es ist unmöglich, komplexe soziale und wirtschaftliche Systeme ohne vollständige, zuverlässige und zeitnahe statistische Informationen zu verwalten. Somit stehen die Organe der Staats- und Departementsstatistik vor einer sehr wichtigen Aufgabe der theoretischen Begründung des Umfangs und der Zusammensetzung statistischer Informationen, die den modernen Bedingungen der wirtschaftlichen Entwicklung entsprechen, zur Rationalisierung des Rechnungswesens und der Statistik beitragen und die Kosten der Durchführung minimieren diese Funktion. VORTRAG Nr. 2. Statistische Beobachtung 1. Das Konzept der statistischen Beobachtung, die Phasen seiner Umsetzung Eine gründliche umfassende Untersuchung jedes wirtschaftlichen oder sozialen Prozesses beinhaltet die Messung seiner quantitativen Seite und die Charakterisierung seines qualitativen Wesens, seines Platzes, seiner Rolle und seiner Beziehungen im allgemeinen System sozialer Beziehungen. Bevor Sie beginnen, statistische Methoden zur Untersuchung der Phänomene und Prozesse des sozialen Lebens einzusetzen, müssen Sie über eine erschöpfende Informationsbasis verfügen, die den Untersuchungsgegenstand vollständig und zuverlässig beschreibt. Der Prozess der statistischen Forschung umfasst die folgenden Schritte: 1) Sammlung von Informationen über Statistiken (statistische Beobachtung) und ihre primäre Verarbeitung; 2) Gruppierung und anschließende Verarbeitung von Daten, die als Ergebnis statistischer Beobachtungen erhalten wurden, basierend auf ihrer Zusammenfassung und Gruppierung; 3) Verallgemeinerung und Analyse der Ergebnisse der Verarbeitung statistischer Materialien, Formulierung von Schlussfolgerungen und Empfehlungen auf der Grundlage der Ergebnisse der gesamten statistischen Studie. Daher ist die statistische Beobachtung die erste und die Anfangsphase der statistischen Studie. Statistische Beobachtung - der Prozess der Erhebung von Primärdaten zu verschiedenen Phänomenen des sozialen und wirtschaftlichen Lebens. Das bedeutet, dass die statistische Beobachtung wie geplant, massiv und systematisch organisiert werden sollte. Die Regelmäßigkeit der statistischen Beobachtung liegt in der Tatsache, dass sie nach einem speziell entwickelten Plan durchgeführt wird, der Fragen im Zusammenhang mit der Organisation und Technik der Erhebung statistischer Informationen, der Kontrolle ihrer Zuverlässigkeit und Qualität und der Präsentation der endgültigen Materialien enthält. Der Massencharakter der statistischen Beobachtung wird durch die vollständigste Bandbreite aller Manifestationsfälle des untersuchten Phänomens oder Prozesses gewährleistet, d. H. Quantitative und qualitative Merkmale werden nicht von einzelnen Einheiten der untersuchten Bevölkerung, sondern von der Gesamtheit gemessen und erfasst Masse der Einheiten der Bevölkerung im Prozess der statistischen Beobachtung. Die systematische Natur der statistischen Beobachtung sollte nicht spontan sein. Die mit einer solchen Überwachung verbundenen Arbeiten sollten entweder kontinuierlich oder regelmäßig in regelmäßigen Abständen durchgeführt werden. Der Prozess der Vorbereitung einer statistischen Beobachtung umfasst die Festlegung des Ziels und des Beobachtungsgegenstands, die Auswahl der Beobachtungseinheit und die Zusammensetzung der aufzuzeichnenden Merkmale. Um Daten zu sammeln, ist es notwendig, Dokumentenformen zu entwickeln und die Mittel und Methoden zu ihrer Beschaffung auszuwählen. Folglich ist die statistische Beobachtung eine mühselige und sorgfältige Arbeit, die den Einsatz von qualifiziertem Personal, ihre umfassende Organisation, Planung, Vorbereitung und Durchführung erfordert. 2. Arten und Methoden der statistischen Beobachtung Die statistische Beobachtung ist ein Prozess, der von seiner Organisation her vielfältige Methoden, Formen und Verhaltensweisen aufweisen kann. Die Aufgabe der allgemeinen Theorie der Statistik besteht darin, das Wesen der Methoden, Formen und Arten der Beobachtung zu bestimmen, um zu entscheiden, wo, wann und welche Beobachtungsmethoden angewendet werden. Statistische Beobachtungen haben zwei Hauptgruppen: 1) Erfassung von Bevölkerungseinheiten; 2) Zeitpunkt der Eintragung von Tatsachen. Je nach Abdeckungsgrad der untersuchten Population wird die statistische Beobachtung in zwei Arten unterteilt: kontinuierlich und nicht kontinuierlich. Kontinuierliche (vollständige) Beobachtung bezieht sich auf die Abdeckung aller Einheiten der untersuchten Population. Die kontinuierliche Beobachtung liefert die Vollständigkeit der Informationen über die untersuchten Phänomene und Prozesse. Diese Art der Beobachtung ist mit hohen Arbeits- und Materialkosten verbunden. Das Sammeln und Verarbeiten der gesamten Menge an notwendigen Informationen erfordert beträchtliche Zeit, so dass der Bedarf an Betriebsinformationen nicht befriedigt wird. Häufig ist eine kontinuierliche Beobachtung gar nicht möglich (z. B. wenn die untersuchte Population zu groß ist oder keine Möglichkeit besteht, Informationen über alle Bevölkerungseinheiten zu erhalten). Infolgedessen werden widersprüchliche Beobachtungen gemacht. Unter nichtkontinuierlicher Beobachtung wird nur die Erfassung eines bestimmten Teils der untersuchten Bevölkerung verstanden. Bei der Durchführung einer diskontinuierlichen Beobachtung muss im Voraus festgelegt werden, welcher Teil der untersuchten Population der Beobachtung unterzogen wird und welches Kriterium als Grundlage für die Stichprobe verwendet wird. Die Organisation einer diskontinuierlichen Beobachtung hat den Vorteil, dass sie in kurzer Zeit durchgeführt wird, mit geringsten Arbeits- und Materialkosten verbunden ist und die gewonnenen Informationen operativer Natur sind. Es gibt mehrere Arten von diskontinuierlicher Beobachtung: selektiv; Beobachtung des Hauptarrays; Monographie. Unter selektiver Beobachtung versteht man einen Teil der Einheiten der untersuchten Population, die nach der Methode der Zufallsauswahl ausgewählt werden. Mit der richtigen Organisation führt die Stichprobenbeobachtung zu ziemlich genauen Ergebnissen, die mit bedingter Wahrscheinlichkeit auf die gesamte Population ausgedehnt werden können. Die Methode der momentanen Beobachtung wird als selektive Beobachtung bezeichnet, bei der nicht nur Einheiten der untersuchten Population (sampling in space), sondern auch die Zeitpunkte ausgewählt werden, zu denen die Registrierung von Zeichen durchgeführt wird (sampling in time). Die Beobachtung des Hauptbereichs ist die Abdeckung der Erhebung bestimmter, bedeutsamster Merkmale der Bevölkerungseinheiten. Bei einer solchen Beobachtung werden die größten Einheiten der Bevölkerung berücksichtigt und die wichtigsten Merkmale für diese Studie erfasst. Beispielsweise werden 15-20 % der großen Kreditinstitute befragt, während der Inhalt ihrer Anlageportfolios erfasst wird. Die monografische Beobachtung zeichnet sich durch eine umfassende und vollständige Untersuchung nur einiger Einheiten der Bevölkerung aus, die einige besondere Merkmale aufweisen oder ein neues Phänomen darstellen. Der Zweck einer solchen Beobachtung besteht darin, bestehende oder nur aufkommende Trends in der Entwicklung eines bestimmten Prozesses oder Phänomens zu identifizieren. In einer monografischen Erhebung werden einzelne Bevölkerungseinheiten einer detaillierten Untersuchung unterzogen, die uns erlaubt, sehr wichtige Abhängigkeiten und Proportionen festzustellen, die wir mit anderen, weniger detaillierten Beobachtungen nicht finden können. Statistisch-monografische Erhebungen werden häufig in der Medizin, bei der Untersuchung von Familienbudgets etc. eingesetzt. Es ist wichtig festzuhalten, dass monografische Erhebungen eng mit kontinuierlichen und punktuellen Erhebungen verwandt sind. Erstens werden Daten aus Massenerhebungen benötigt, um ein Kriterium für die Auswahl von Bevölkerungseinheiten für die diskontinuierliche und monografische Beobachtung auszuwählen. Zweitens ermöglicht die monografische Beobachtung, die charakteristischen Merkmale und wesentlichen Merkmale des Untersuchungsobjekts zu identifizieren, um die Struktur der untersuchten Population zu verdeutlichen. Die Ergebnisse können als Grundlage für die Organisation einer neuen Massenerhebung verwendet werden. Je nach Zeitpunkt der Tatbestandsaufnahme kann die Beobachtung kontinuierlich und diskontinuierlich erfolgen. Diskontinuierliche Überwachung umfasst wiederum periodische und einmalige. Kontinuierliche (aktuelle) Beobachtung wird durch kontinuierliche Registrierung von Fakten realisiert, sobald sie verfügbar sind. Mit einer solchen Beobachtung werden alle Änderungen in den untersuchten Prozessen und Phänomenen verfolgt, was es ermöglicht, ihre Dynamik zu überwachen. Standesämter registrieren zum Beispiel Todesfälle, Geburten und Eheschließungen laufend. Die Unternehmen führen aktuelle Aufzeichnungen über die Freigabe von Materialien aus dem Lager, der Produktion usw. Die diskontinuierliche Beobachtung erfolgt entweder systematisch in festen Abständen (periodische Beobachtung) oder einmalig und bei Bedarf unregelmäßig (einmalige Beobachtung). Periodische Beobachtungen basieren in der Regel auf ähnlichen Programmen und Instrumenten, damit die Ergebnisse solcher Studien vergleichbar sind. Beispiele für periodische Beobachtungen können eine in größeren Abständen durchgeführte Volkszählung und alle Formen statistischer Beobachtungen sein, die jährlich, halbjährlich, vierteljährlich oder monatlich durchgeführt werden. Die Besonderheit einer einmaligen Beobachtung besteht darin, dass Tatsachen nicht im Zusammenhang mit ihrem Auftreten, sondern nach ihrem Zustand oder Vorhandensein zu einem bestimmten Zeitpunkt oder über einen bestimmten Zeitraum hinweg erfasst werden. Die quantitative Messung von Anzeichen eines Phänomens oder Prozesses erfolgt zum Zeitpunkt der Erhebung, und die Neuregistrierung von Anzeichen wird möglicherweise überhaupt nicht durchgeführt oder der Zeitpunkt ihrer Umsetzung ist nicht im Voraus festgelegt. Ein Beispiel für eine einmalige Beobachtung ist eine einmalige Erhebung zum Stand des Wohnungsbaus, die im Jahr 2000 durchgeführt wurde. Neben den Arten der statistischen Beobachtung betrachtet die allgemeine Theorie der Statistik Methoden zur Gewinnung statistischer Informationen, von denen die wichtigsten die dokumentarische Beobachtungsmethode sind; Methode der direkten Beobachtung; Interview. Die dokumentarische Beobachtung basiert auf der Verwendung von Daten aus verschiedenen Dokumenten, wie z. B. Buchhaltungsregistern, als Informationsquelle. Wenn man bedenkt, dass an das Ausfüllen solcher Dokumente in der Regel hohe Anforderungen gestellt werden, sind die darin wiedergegebenen Daten höchst zuverlässig und können als hochwertiges Ausgangsmaterial für Analysen dienen. Die direkte Beobachtung wird durchgeführt, indem die Tatsachen registriert werden, die von den Registraren persönlich als Ergebnis der Inspektion, Messung und Zählung der Anzeichen des untersuchten Phänomens festgestellt wurden. So werden Preise für Waren und Dienstleistungen erfasst, Arbeitszeitmessungen vorgenommen, Lagerbestände inventarisiert etc. Die Umfrage basiert auf der Erhebung von Daten von Befragten (Umfrageteilnehmern). Die Erhebung wird dort eingesetzt, wo eine Beobachtung mit anderen Methoden nicht möglich ist. Diese Art der Beobachtung ist typisch für die Durchführung verschiedener soziologischer Umfragen und Meinungsumfragen. Statistische Informationen können durch verschiedene Arten von Erhebungen gewonnen werden: Expeditions-; Korrespondent; Fragebogen; Privatgelände. Die expeditionelle (mündliche) Umfrage wird von speziell geschulten Mitarbeitern (Registratoren) durchgeführt, die die Antworten der Befragten in den Beobachtungsbögen festhalten. Das Formular ist eine Form eines Dokuments, in dem die Felder für Antworten ausgefüllt werden müssen. Die Korrespondentenmethode geht davon aus, dass die antwortenden Mitarbeiter auf freiwilliger Basis Informationen direkt an die Überwachungsstelle melden. Der Nachteil dieses Verfahrens besteht darin, dass es schwierig ist, die Korrektheit der empfangenen Informationen zu überprüfen. Bei der Fragebogenmethode füllen die Befragten Fragebögen (Fragebögen) freiwillig und meist anonym aus. Da diese Methode zur Gewinnung von Informationen nicht zuverlässig ist, wird sie in Studien verwendet, in denen keine hohe Genauigkeit der Ergebnisse erforderlich ist. In manchen Situationen reichen ungefähre Ergebnisse aus, die nur den Trend erfassen und das Auftauchen neuer Tatsachen und Phänomene erfassen. Bei der persönlichen Methode werden Informationen an die Behörden übermittelt, die die Überwachung persönlich durchführen. Auf diese Weise werden Personenstandsurkunden registriert – Ehen, Scheidungen, Todesfälle, Geburten usw. Die Theorie der Statistik betrachtet neben den Arten und Methoden der statistischen Beobachtung auch die Formen der statistischen Beobachtung: Berichterstattung; speziell organisierte statistische Beobachtung; registriert. Statistische Berichterstattung - die Hauptform der statistischen Beobachtung, die dadurch gekennzeichnet ist, dass statistische Stellen Informationen über die untersuchten Phänomene in Form von speziellen Dokumenten erhalten, die von Unternehmen und Organisationen zu bestimmten Zeiten und in der vorgeschriebenen Form eingereicht werden. Die Formen der statistischen Berichterstattung selbst, die Methoden zur Erhebung und Verarbeitung statistischer Daten und die vom Staatlichen Komitee für Statistik Russlands festgelegte Methodik statistischer Indikatoren sind die offiziellen statistischen Standards der Russischen Föderation und für alle Themen der Öffentlichkeitsarbeit obligatorisch. Die statistische Berichterstattung ist in Spezial- und Standardberichte unterteilt. Die Zusammensetzung der Indikatoren der Standardberichterstattung ist für alle Unternehmen und Organisationen gleich, während die Zusammensetzung der Indikatoren der spezialisierten Berichterstattung von den Besonderheiten der einzelnen Wirtschaftssektoren und Tätigkeitsbereiche abhängt. Je nach Zeitpunkt der Einreichung erfolgt die statistische Berichterstattung täglich, wöchentlich, zehntägig, zweiwöchentlich, monatlich, vierteljährlich, halbjährlich und jährlich. Statistische Meldungen können telefonisch, über Kommunikationswege, auf elektronischen Medien mit obligatorischer Nachreichung auf Papier, beglaubigt durch die Unterschrift der verantwortlichen Personen, übermittelt werden. Speziell organisierte statistische Beobachtung ist eine Sammlung von Informationen, die von statistischen Stellen organisiert wird, um entweder Phänomene zu untersuchen, die nicht von der Berichterstattung erfasst werden, oder um Berichtsdaten eingehender zu untersuchen, zu überprüfen und zu verfeinern. Verschiedene Arten von Volkszählungen, einmalige Erhebungen sind speziell organisierte Beobachtungen. Registrieren - Dies ist eine Form der Beobachtung, bei der die Tatsachen des Zustands einzelner Bevölkerungseinheiten kontinuierlich erfasst werden. Betrachtet man eine Einheit der Bevölkerung, so wird angenommen, dass die dort ablaufenden Prozesse einen Anfang, eine langfristige Fortsetzung und ein Ende haben. Im Register ist jede Beobachtungseinheit durch eine Reihe von Indikatoren gekennzeichnet. Alle Indikatoren werden gespeichert, bis die Beobachtungseinheit im Register ist und ihre Existenz nicht beendet hat. Einige Indikatoren bleiben gleich, solange die Beobachtungseinheit im Register enthalten ist, andere können sich von Zeit zu Zeit ändern. Ein Beispiel für ein solches Register ist das einheitliche staatliche Register der Unternehmen und Organisationen (USRE). Alle Arbeiten zu seiner Wartung werden vom Staatlichen Komitee für Statistik Russlands durchgeführt. Die Wahl der Arten, Methoden und Formen der statistischen Beobachtung hängt also von einer Reihe von Faktoren ab, von denen die wichtigsten die Ziele und Ziele der Beobachtung, die Besonderheiten des beobachteten Objekts, die Dringlichkeit der Ergebnispräsentation und die Verfügbarkeit von geschultem Personal sind , die Möglichkeit der Nutzung technischer Mittel zur Erhebung und Verarbeitung von Daten. 3. Programm- und methodische Fragen der statistischen Beobachtung Eine der wichtigsten Aufgaben, die bei der Erstellung einer statistischen Beobachtung gelöst werden müssen, ist die Bestimmung von Zweck, Gegenstand und Einheit der Beobachtung. Das Ziel fast jeder statistischen Beobachtung ist es, zuverlässige Informationen über die Phänomene und Prozesse des sozialen Lebens zu erhalten, um die Wechselbeziehungen von Faktoren zu identifizieren, das Ausmaß des Phänomens und die Muster seiner Entwicklung einzuschätzen. Ausgehend von den Beobachtungsaufgaben werden Programm und Organisationsformen festgelegt. Neben dem Ziel ist es notwendig, den Beobachtungsgegenstand festzulegen, also festzulegen, was genau beobachtet werden soll. Gegenstand der Betrachtung ist die Gesamtheit der zu untersuchenden gesellschaftlichen Phänomene oder Prozesse. Das Beobachtungsobjekt kann eine Reihe von Institutionen (Kredit, Bildung usw.), die Bevölkerung, physische Objekte des Gebäudes, Transport, Ausrüstung) sein. Bei der Festlegung des Beobachtungsobjekts ist es wichtig, die Grenzen der untersuchten Population streng und genau zu bestimmen. Dazu ist es notwendig, die wesentlichen Merkmale klar festzulegen, anhand derer bestimmt wird, ob ein Objekt in die Gesamtheit aufgenommen wird oder nicht. So ist vor einer Befragung medizinischer Einrichtungen zur Versorgung mit moderner Ausstattung beispielsweise die Kategorie, Fachbereichs- und Gebietszugehörigkeit der zu befragenden Kliniken festzulegen. Bei der Definition des Betrachtungsgegenstandes ist es notwendig, die Betrachtungseinheit und die Einheit der Grundgesamtheit anzugeben. Die Beobachtungseinheit ist ein konstituierendes Element des Beobachtungsobjekts, das eine Informationsquelle ist. Je nach Aufgabenstellung der statistischen Beobachtung kann es sich bei den Beobachtungseinheiten um einen Haushalt oder um eine Person handeln, beispielsweise um einen Studenten, einen landwirtschaftlichen Betrieb oder eine Fabrik. Bevölkerungseinheit - dies ist das sogenannte konstituierende Element des Beobachtungsobjekts, aus dem Informationen über die Beobachtungseinheit gewonnen werden, d. h. das als Grundlage für die Zählung dient und im Beobachtungsprozess registrierungspflichtige Merkmale aufweist. Beispielsweise wird bei einer Zählung von Waldplantagen die Einheit der Population ein Baum sein, da er registrierungspflichtige Merkmale aufweist (Alter, Artenzusammensetzung usw.), während die Forstwirtschaft selbst, in der die Erhebung durchgeführt wird, erfolgt , dient als Beobachtungseinheit. Beobachtungseinheiten werden Berichtseinheiten genannt, wenn sie statistische Meldungen an die statistischen Ämter übermitteln. Jedes Phänomen oder jeder Prozess des sozialen Lebens hat viele Merkmale, die sie charakterisieren. Es ist unmöglich, Informationen über alle Merkmale zu erhalten, und nicht alle sind für den Forscher von Interesse. Bei der Vorbereitung einer Beobachtung muss entschieden werden, welche Zeichen gemäß den Zielen und Zwecken der Beobachtung registrierungspflichtig sind. Um die Zusammensetzung der registrierten Merkmale zu bestimmen, wird ein Beobachtungsprogramm entwickelt. Das statistische Beobachtungsprogramm besteht aus einer Reihe von Fragen, deren Antworten während des Beobachtungsprozesses statistische Informationen darstellen sollten. Die Entwicklung eines Beobachtungsprogramms ist eine sehr wichtige und verantwortungsvolle Aufgabe, und der Erfolg der Beobachtung hängt davon ab, wie korrekt sie durchgeführt wird. Bei der Entwicklung eines Beobachtungsprogramms müssen eine Reihe von Anforderungen dafür berücksichtigt werden. Lassen Sie uns die wichtigsten auflisten. 1. Das Programm sollte nach Möglichkeit nur die Features enthalten, die notwendig sind und deren Werte für weitere Analysen oder zu Kontrollzwecken verwendet werden. Während man nach der Vollständigkeit der Informationen strebt, die den Erhalt gutartiger Materialien gewährleisten, ist es dennoch notwendig, die Menge der gesammelten Informationen zu begrenzen, um zwar kleines, aber zuverlässiges Material für die Analyse zu erhalten. 2. Fragen des Programms sollten ganz klar, ganz klar formuliert werden, um ihre falsche Interpretation auszuschließen und eine Verfälschung der Bedeutung der gesammelten Informationen zu verhindern. 3. Bei der Entwicklung eines Beobachtungsprogramms ist es wünschenswert, eine logische Abfolge von Fragen aufzubauen. Fragen des gleichen Typs oder Zeichen, die eine Seite des Phänomens charakterisieren, sollten in einem Abschnitt zusammengefasst werden. 4. Es ist wichtig, dass das Überwachungsprogramm Kontrollfragen zur Überprüfung und Korrektur der aufgezeichneten Informationen enthält. Um die Beobachtung durchzuführen, benötigen Sie Ihre eigenen Werkzeuge - Formulare und Anweisungen. statistische Form - Dies ist ein spezielles Dokument einer einzelnen Probe, in dem Antworten auf die Fragen des Programms aufgezeichnet werden. Je nach konkretem Inhalt der durchzuführenden Beobachtung kann das Formular als Form der statistischen Berichterstattung, Zählung oder Fragebogen, Karte, Karte, Fragebogen oder Formular bezeichnet werden. Es gibt zwei Arten von Formularen - Karte und Liste. Das Kartenformular (oder individuelle Formular) soll Informationen über eine Einheit der statistischen Grundgesamtheit widerspiegeln, und das Listenformular enthält Informationen über mehrere Einheiten der Grundgesamtheit. Die integralen und obligatorischen Bestandteile des statistischen Formulars sind der Titel-, Adress- und Inhaltsteil. Der Titelteil enthält den Namen der statistischen Beobachtung und der Stelle, die dieses Formular genehmigt hat, die Bedingungen für die Einreichung des Formulars und einige andere Informationen. Der Adressteil enthält die Angaben zur berichtenden Betrachtungseinheit. Der Hauptinhaltsteil des Formulars wird normalerweise in Form einer Tabelle erstellt, die in bequemer Form den Namen, die Codes und die Werte der Indikatoren enthält. Das Statistikformular wird gemäß den Anweisungen ausgefüllt. Die Anweisung enthält Anweisungen zum Verfahren zur Durchführung von Beobachtungen sowie methodische Anweisungen und Erläuterungen zum Ausfüllen des Formulars. Je nach Komplexität des Überwachungsprogramms wird die Anweisung entweder als Broschüre veröffentlicht oder auf der Rückseite des Formulars platziert. Darüber hinaus können Sie sich für die notwendigen Abklärungen an die für die Durchführung der Observation zuständigen Spezialisten, die durchführenden Stellen, wenden. Bei der Organisation der statistischen Beobachtung muss die Frage nach dem Zeitpunkt der Beobachtung und dem Ort ihrer Durchführung gelöst werden. Die Wahl des Beobachtungsortes hängt vom Zweck der Beobachtung ab. Die Wahl des Beobachtungszeitpunkts ist mit der Bestimmung eines kritischen Moments (Datums) oder Zeitintervalls und der Bestimmung des Beobachtungszeitraums (Periode) verbunden. Der kritische Moment der statistischen Beobachtung ist der Zeitpunkt, auf den die im Beobachtungsprozess erfassten Informationen getaktet werden. Der Beobachtungszeitraum bestimmt den Zeitraum, in dem die Registrierung von Informationen über das untersuchte Phänomen durchgeführt werden sollte, dh das Zeitintervall, in dem die Formulare ausgefüllt werden. Normalerweise sollte der Beobachtungszeitraum nicht zu weit vom kritischen Beobachtungszeitpunkt entfernt sein, um den Zustand des Objekts zu diesem Zeitpunkt zu reproduzieren. 4. Fragen der organisatorischen Unterstützung, Vorbereitung und Durchführung der statistischen Beobachtung Für die erfolgreiche Vorbereitung und Durchführung der statistischen Beobachtung müssen auch die Fragen ihrer organisatorischen Unterstützung gelöst werden. Dies geschieht bei der Erstellung eines organisatorischen Überwachungsplans. Der Plan spiegelt die Ziele und Ziele der Beobachtung, das Beobachtungsobjekt, den Ort, die Zeit, den Zeitpunkt der Beobachtung und den Kreis der Personen wider, die für die Durchführung der Beobachtung verantwortlich sind. Verbindlicher Bestandteil des Organisationsplans ist die Angabe der Aufsichtsbehörde. Es definiert auch den Kreis der Organisationen, die zur Unterstützung bei der Überwachung herangezogen werden. Dazu können Organe für innere Angelegenheiten, Steueraufsichtsämter, Fachministerien, öffentliche Organisationen, Einzelpersonen, Freiwillige usw. gehören. Zu den vorbereitenden Tätigkeiten gehören: 1) Entwicklung statistischer Beobachtungsformen, Wiedergabe der Dokumentation der Erhebung selbst; 2) Entwicklung eines methodologischen Instrumentariums zur Analyse und Präsentation der Beobachtungsergebnisse; 3) Entwicklung von Software für die Datenverarbeitung, Kauf von Computer- und Büroausstattung; 4) Kauf von notwendigen Materialien, einschließlich Schreibwaren; 5) Schulung von qualifiziertem Personal, Schulung von Personal, Durchführung verschiedener Arten von Briefings usw.; 6) Massenaufklärungsarbeit unter der Bevölkerung und den Teilnehmern der Beobachtung (Vorträge, Gespräche, Reden in der Presse, im Rundfunk und Fernsehen); 7) Koordinierung der Aktivitäten aller Dienste und Organisationen, die an gemeinsamen Aktionen beteiligt sind; 8) Ausstattung des Ortes der Datenerhebung und -verarbeitung; 9) Vorbereitung von Informationsübertragungskanälen und Kommunikationsmitteln; 10) Lösung von Problemen im Zusammenhang mit der Finanzierung der statistischen Beobachtung. Der Beobachtungsplan enthält daher eine Reihe von Maßnahmen sowie die sie charakterisierenden Umstände des Ortes und der Zeit, die auf den erfolgreichen Abschluss der Arbeiten zur Erfassung der erforderlichen Informationen abzielen. 5. Beobachtungsgenauigkeit und Datenvalidierungsmethoden Jede spezifische Messung der Größe der Daten, die während des Beobachtungsprozesses durchgeführt wird, ergibt in der Regel einen ungefähren Wert der Größe des Phänomens, der in gewissem Maße von dem wahren Wert dieser Größe abweicht. Genauigkeit der statistischen Beobachtung bezeichnet den Grad der Konformität eines Indikators oder Merkmals, berechnet auf der Grundlage von Beobachtungsmaterialien, mit seinem tatsächlichen Wert. Die Diskrepanz zwischen dem Ergebnis der Beobachtung und dem wahren Wert der Größe des beobachteten Phänomens wird als bezeichnet Beobachtungsfehler. Je nach Art, Stadium und Ursachen des Auftretens werden mehrere Arten von Beobachtungsfehlern unterschieden. Fehler werden naturgemäß in zufällige und systematische Fehler unterteilt. Zufällige Fehler - Dies sind Fehler, deren Auftreten auf das Einwirken von Zufallsfaktoren zurückzuführen ist. Dazu gehören Vorbehalte und Druckfehler des Befragten. Sie können darauf gerichtet sein, den Wert des Attributs zu verringern oder zu erhöhen. Sie spiegeln sich in der Regel nicht im Endergebnis wider, da sie sich bei der zusammenfassenden Verarbeitung der Beobachtungsergebnisse gegenseitig aufheben. Systematische Fehler die gleiche Tendenz haben, den Wert des Attributindikators entweder zu verringern oder zu erhöhen. Dies liegt daran, dass Messungen beispielsweise durch ein fehlerhaftes Messgerät erfolgen oder Fehler durch eine unklare Formulierung der Fragestellung des Beobachtungsprogramms etc. entstehen. Systematische Fehler sind von großer Gefahr, da sie die Messdaten erheblich verfälschen Ergebnisse der Beobachtung. Je nach Stadium des Auftretens gibt es: Registrierungsfehler; Fehler, die bei der Aufbereitung von Daten für die maschinelle Verarbeitung auftreten; Fehler, die bei der Verarbeitung in der Computertechnologie auftreten. К Registrierungsfehler Dazu gehören solche Ungenauigkeiten, die bei der Erfassung von Daten in einem statistischen Formular (Primärdokument, Formular, Bericht, Erhebungsformular) oder bei der Eingabe von Daten in Computer, Verzerrung von Daten bei der Übertragung über Kommunikationsleitungen (Telefon, E-Mail) auftreten. Häufig treten Registrierungsfehler auf, weil die Form des Formulars nicht eingehalten wird, dh der Eintrag erfolgt nicht in der festgelegten Zeile oder Spalte des Dokuments. Es gibt auch eine bewusste Verzerrung der Werte einzelner Indikatoren. In Rechenzentren oder Datenaufbereitungszentren treten Fehler bei der Aufbereitung von Daten für die maschinelle Verarbeitung oder im Prozess der Verarbeitung selbst auf. Das Auftreten solcher Fehler ist verbunden mit nachlässigem, falschem, unscharfem Ausfüllen von Daten in den Formularen, mit einem physischen Defekt des Datenträgers, mit dem Verlust eines Teils der Daten aufgrund der Nichteinhaltung der Informationsbasis-Speichertechnologie. Manchmal werden Fehler durch Hardwarefehler verursacht. Kennt man die Arten und Ursachen von Beobachtungsfehlern, ist es möglich, den Anteil solcher Informationsverzerrungen deutlich zu reduzieren. Es gibt mehrere Arten von Fehlern: 1) Messfehler im Zusammenhang mit bestimmten Fehlern, die während einer einzigen statistischen Beobachtung des Phänomens und der Prozesse des sozialen Lebens auftreten; 2) Repräsentativitätsfehler, die sich im Laufe der nicht kontinuierlichen Beobachtung ergeben und damit zusammenhängen, dass die Stichprobe selbst nicht repräsentativ ist und die auf ihrer Grundlage erhaltenen Ergebnisse nicht auf die gesamte Population ausgedehnt werden können; 3) vorsätzliche Fehler, die sich aus der absichtlichen Verzerrung von Daten für verschiedene Zwecke ergeben, einschließlich des Wunsches, den tatsächlichen Zustand des Beobachtungsobjekts zu verschönern oder umgekehrt den unbefriedigenden Zustand des Objekts zu zeigen usw. Es sollte beachtet werden, dass z Die Verzerrung von Informationen stellt einen Gesetzesverstoß dar; 4) unbeabsichtigte Fehler, die in der Regel zufälliger Natur sind und mit der geringen Qualifikation der Mitarbeiter, ihrer Unaufmerksamkeit oder Fahrlässigkeit zusammenhängen. Oft sind solche Fehler mit subjektiven Faktoren verbunden, wenn Menschen falsche Angaben zu Alter, Familienstand, Bildung, Zugehörigkeit zu einer sozialen Gruppe usw. machen oder einfach einige Fakten vergessen und dem Standesbeamten Informationen mitteilen, die gerade in Erinnerung geblieben sind. Es ist wünschenswert, einige Aktivitäten durchzuführen, die helfen, Beobachtungsfehler zu verhindern, zu identifizieren und zu korrigieren. Diese Aktivitäten umfassen: 1) Auswahl von qualifiziertem Personal und hochwertige Schulung des Personals im Zusammenhang mit der Durchführung der Überwachung; 2) Organisation von Kontrollprüfungen der Richtigkeit des Ausfüllens von Dokumenten durch eine kontinuierliche oder selektive Methode; 3) arithmetische und logische Kontrolle der erhaltenen Daten nach Abschluss der Sammlung von Beobachtungsmaterialien. Die wichtigsten Arten der Datenzuverlässigkeitskontrolle sind syntaktisch, logisch und arithmetisch. 1. Syntaktische Kontrolle bedeutet, die Richtigkeit der Struktur des Dokuments, das Vorhandensein notwendiger und obligatorischer Details und die Vollständigkeit des Ausfüllens der Formularzeilen gemäß den festgelegten Regeln zu überprüfen. Die Bedeutung und Notwendigkeit der syntaktischen Kontrolle erklärt sich aus dem Einsatz von Computertechnologie, Scannern für die Datenverarbeitung, die strenge Anforderungen an die Einhaltung der Regeln zum Ausfüllen von Formularen stellen. 2. Die logische Kontrolle überprüft die Richtigkeit der Aufzeichnung von Codes, die Einhaltung ihrer Namen und Werte von Indikatoren. Dabei werden die notwendigen Beziehungen zwischen Indikatoren überprüft, Antworten auf verschiedene Fragen verglichen und unvereinbare Kombinationen identifiziert. Um bei der logischen Kontrolle festgestellte Fehler zu korrigieren, kehren sie zu den Originaldokumenten zurück und nehmen Korrekturen vor. 3. Bei der arithmetischen Kontrolle werden die erhaltenen Summen mit vorberechneten Prüfsummen für Zeilen und Spalten verglichen. Sehr oft basiert die arithmetische Kontrolle auf der Abhängigkeit eines Indikators von zwei oder mehr anderen (z. B. ist es das Produkt anderer Indikatoren). Wenn die arithmetische Kontrolle der endgültigen Indikatoren ergibt, dass diese Abhängigkeit nicht beobachtet wird, deutet dies auf eine Ungenauigkeit der Daten hin. Somit erfolgt die Kontrolle der Zuverlässigkeit statistischer Informationen in allen Phasen der statistischen Beobachtung – von der Erhebung der Primärinformationen bis zur Phase der Ergebniserzielung. VORTRAG Nr. 3. Statistische Zusammenfassung und Gruppierung 1. Aufgaben und Inhalte zusammenfassen Die wissenschaftlich organisierte Aufbereitung statistischer Beobachtungsmaterialien nach einem vorgefertigten Programm umfasst neben der Datenkontrolle auch die Systematisierung, Gruppierung von Daten, Zusammenstellung von Tabellen, die Gewinnung von Ergebnissen und abgeleiteten Indikatoren (Durchschnitts- und Relativwerte) usw. Das gesammelte Material in Der Prozess der statistischen Beobachtung besteht aus verstreuten Primärinformationen über einzelne Einheiten des untersuchten Phänomens. In dieser Form charakterisiert das Material das Phänomen noch nicht als Ganzes: Es gibt weder eine Vorstellung von der Größe (Anzahl) des Phänomens, noch von seiner Zusammensetzung, noch von der Größe der charakteristischen Merkmale, noch von die Zusammenhänge dieses Phänomens mit anderen Phänomenen usw. Es besteht Bedarf an einer speziellen Verarbeitung statistischer Daten – Zusammenfassung von Beobachtungsmaterialien. Zusammenfassung ist eine Reihe aufeinanderfolgender Aktionen zur Verallgemeinerung spezifischer Einzeldaten, die eine Reihe bilden, um typische Merkmale und Muster zu erkennen, die dem untersuchten Phänomen als Ganzes innewohnen. Statistische Zusammenfassung im engeren Sinne des Wortes (einfache Zusammenfassung) ist eine Operation zur Berechnung der gesamten zusammenfassenden (zusammenfassenden) Daten für einen Satz von Beobachtungseinheiten. Statistische Zusammenfassung im weitesten Sinne des Wortes (komplexe Zusammenfassung) umfasst auch das Gruppieren von Beobachtungsdaten, das Berechnen allgemeiner und Gruppensummen, das Erstellen eines Systems zusammenhängender Indikatoren, das Präsentieren von Gruppierungsergebnissen und Zusammenfassungen in Form von statistischen Tabellen. Eine korrekte, wissenschaftlich organisierte Zusammenfassung, basierend auf einer vorläufigen tiefen theoretischen Analyse, ermöglicht es Ihnen, alle statistischen Ergebnisse zu erhalten, die die wichtigsten, charakteristischen Merkmale des Untersuchungsgegenstands widerspiegeln, den Einfluss verschiedener Faktoren auf das Ergebnis zu messen und all dies zu berücksichtigen in der praktischen Arbeit, bei der Erstellung aktueller und langfristiger Planungen berücksichtigen. Die Aufgabe der Zusammenfassung besteht folglich darin, den Untersuchungsgegenstand mit Hilfe statistischer Kennzahlensysteme zu charakterisieren, seine wesentlichen Merkmale und Eigenschaften zu identifizieren und auf diese Weise zu messen. Diese Aufgabe wird in drei Stufen gelöst: 1) Definition von Gruppen und Untergruppen; 2) Definition eines Systems von Indikatoren; 3) Definition von Tabellentypen. In der ersten Phase wird eine Systematisierung und Gruppierung von während der Beobachtung gesammelten Materialien durchgeführt. In der zweiten Stufe wird das im Plan vorgesehene Indikatorensystem spezifiziert, mit dessen Hilfe die Eigenschaften und Merkmale des Studienfachs quantitativ charakterisiert werden. In der dritten Phase werden die Indikatoren selbst berechnet und verallgemeinerte Daten zur Klarheit und Bequemlichkeit in Tabellen, statistischen Reihen, Grafiken und Diagrammen dargestellt. Die aufgeführten Phasen der Zusammenfassung spiegeln sich noch vor Beginn ihrer Umsetzung in einem speziell zusammengestellten Programm wider. Das statistische Übersichtsprogramm enthält eine Liste von Gruppen, in die es ratsam ist, die Bevölkerung einzuteilen, ihre Grenzen gemäß den Gruppierungsmerkmalen; ein System von Indikatoren, die die Gesamtheit charakterisieren, und die Methode ihrer Berechnung; ein System von Layouts von Entwicklungstabellen, in denen die Ergebnisse von Berechnungen präsentiert werden. Zusammen mit dem Programm gibt es einen zusammenfassenden Plan, der seine Organisation vorsieht. Der Plan zur Durchführung der Zusammenfassung sollte Anweisungen zum Ablauf und Zeitpunkt der Durchführung der einzelnen Teile, zu den für die Durchführung Verantwortlichen, zum Verfahren der Ergebnisdarstellung sowie zur Koordinierung der Arbeit aller beteiligten Organisationen enthalten in seiner Umsetzung. 2. Hauptaufgaben und Arten von Gruppen Der Gegenstand statistischer Forschung – Massenphänomene und Prozesse des gesellschaftlichen Lebens – weisen zahlreiche Merkmale und Eigenschaften auf. Ohne bestimmte wissenschaftliche Grundlagen der Datenverarbeitung ist es unmöglich, statistische Daten zusammenzufassen und die wichtigsten Merkmale und Entwicklungsformen eines Massenphänomens als Ganzes und seiner einzelnen Komponenten aufzudecken. Ohne die individuelle Vielfalt der Objekte der statistischen Beobachtung zu überwinden, verlieren sich die allgemeinen Entwicklungsmuster eines Phänomens oder Prozesses als Ganzes in den Details und Kleinigkeiten, die jedes Objekt voneinander unterscheiden, und die endgültige Verallgemeinerung bringt eine verzerrte Vorstellung von mit sich Wirklichkeit. Um eine Menge von Einheiten in Gruppen desselben Typs zu unterteilen, verwendet die Statistik die Gruppierungsmethode. Statistische Gruppierungen - die erste Stufe einer statistischen Zusammenfassung, die es ermöglicht, aus der Masse des statistischen Ausgangsmaterials homogene Gruppen von Einheiten mit allgemeinen qualitativen und quantitativen Ähnlichkeiten zu identifizieren. Es ist wichtig zu verstehen, dass es sich bei der Gruppierung nicht um eine subjektive technische Methode zur Aufteilung einer Population in Teile handelt, sondern um einen wissenschaftlich fundierten Prozess zur Aufteilung vieler Einheiten einer Population nach einem bestimmten Kriterium. Das Grundprinzip der Anwendung der Gruppierungsmethode ist eine umfassende und tiefgehende Analyse des Wesens und der Natur des untersuchten Phänomens, die es ermöglicht, seine typischen Eigenschaften und internen Unterschiede zu bestimmen. Jede allgemeine Menge ist ein Komplex von besonderen Mengen, von denen jede Phänomene einer besonderen Art, in gewisser Hinsicht von gleicher Qualität, vereint. Jeder Typ (Gruppe) hat ein spezifisches System von Merkmalen mit einem entsprechenden Niveau ihrer quantitativen Werte. Um zu bestimmen, welchem Typ, welcher bestimmten Population die gruppierten Einheiten der Gesamtpopulation zuzuordnen sind, möglicherweise auf der Grundlage einer korrekten, klaren Definition der wesentlichen Merkmale, nach denen die Gruppierung durchgeführt werden sollte. Dies ist die zweite wichtige Anforderung an eine wissenschaftlich fundierte Gruppierung. Das dritte Gruppierungserfordernis basiert auf einer objektiven, vernünftigen Bestimmung der Gruppengrenzen, vorausgesetzt, dass die gebildeten Gruppen homogene Elemente der Bevölkerung vereinen müssen und sich die Gruppen selbst (eine in Bezug auf die andere) erheblich unterscheiden müssen. Andernfalls ist die Gruppierung sinnlos. Basierend auf der Anwendung der Gruppierungsmethode werden also Gruppen nach dem Prinzip der Ähnlichkeit und Differenz von Bevölkerungseinheiten bestimmt. Ähnlichkeit ist die Homogenität von Einheiten innerhalb bestimmter Grenzen (Gruppen); der Unterschied ist ihre signifikante Divergenz in den Gruppen. somit Gruppierung - Einteilung der Gesamtbevölkerung von Einheiten nach einem oder mehreren wesentlichen Merkmalen in homogene Gruppen, die sich qualitativ und quantitativ unterscheiden und es ermöglichen, sozioökonomische Typen herauszugreifen, die Struktur der Bevölkerung zu untersuchen oder die Beziehungen zwischen einzelnen Merkmalen zu analysieren. Die Vielfalt sozialer Phänomene und ihrer Untersuchungszwecke ermöglicht es, eine große Zahl statistischer Gruppierungen von Phänomenen zu verwenden und auf dieser Grundlage eine Vielzahl spezifischer Probleme zu lösen. Die Hauptaufgaben, die mit Hilfe von Gruppierungen in der Statistik gelöst werden, sind die folgenden: 1) Zuordnung in der Gesamtheit der untersuchten Phänomene ihrer sozioökonomischen Typen; 2) Studium der Struktur sozialer Phänomene; 3) Identifizierung von Verbindungen und Abhängigkeiten zwischen sozialen Phänomenen. Alle Gruppierungen, die mit der Zuordnung in der Gesamtheit der untersuchten Phänomene ihrer sozioökonomischen Typen verbunden sind, nehmen in der Statistik einen zentralen Platz ein. Diese Aufgabe bezieht sich auf die wichtigsten, entscheidenden Aspekte des öffentlichen Lebens, z. B. Gruppierung der Bevölkerung nach sozialem Status, Geschlecht, Alter, Bildungsniveau, Gruppierung von Unternehmen und Organisationen nach ihren Eigentumsformen, Branchenzugehörigkeit. Die Konstruktion solcher Gruppierungen über lange Zeiträume ermöglicht es, den Entwicklungsprozess sozioökonomischer Beziehungen nachzuvollziehen. Die Aufgabe, die Gesamtheit sozialer Phänomene nach ihren sozioökonomischen Typen zu unterteilen, wird durch die Bildung typologischer Gruppierungen gelöst. Somit kann die Typologische Gruppierung - dies ist die Einteilung einer qualitativ heterogenen Studienpopulation in homogene Gruppen von Einheiten nach sozioökonomischen Typen. Dem Studium der Struktur sozialer Phänomene wird eine außerordentlich große Bedeutung beigemessen, d Zeit). Auf diese Weise, strukturelle Gruppierung wird eine Gruppierung genannt, bei der eine homogene Population in Gruppen unterteilt wird, die ihre Struktur gemäß einem unterschiedlichen Merkmal charakterisieren. Strukturelle Gruppierungen umfassen die Gruppierung der Bevölkerung nach Geschlecht, Alter, Bildungsniveau, die Gruppierung von Unternehmen nach der Anzahl der Beschäftigten, der Höhe der Löhne, des Arbeitsvolumens usw. Veränderungen in der Struktur sozialer Phänomene spiegeln die wichtigsten wider Muster ihrer Entwicklung. Zum Beispiel zwischen 1959 und 1994 Die städtische Bevölkerung nahm kontinuierlich zu, während die ländliche Bevölkerung abnahm, jedoch zwischen 1994 und 2002 das Verhältnis dieser Bevölkerungsgruppen hat sich nicht verändert. Die Verwendung struktureller Gruppierungen ermöglicht nicht nur die Aufdeckung der Bevölkerungsstruktur, sondern auch die Analyse der untersuchten Prozesse, ihrer Intensität, räumlichen Veränderungen und strukturellen Gruppierungen über mehrere Zeiträume hinweg zeigen Muster von Veränderungen in der Zusammensetzung auf die Bevölkerung im Laufe der Zeit. Strukturelle Gruppierungen können auf einem oder mehreren attributiven oder quantitativen Merkmalen basieren. Ihre Wahl wird durch die Ziele einer bestimmten Studie und die Art der untersuchten Population bestimmt. Die obige Gruppierung ist auf einer Attributbasis aufgebaut. Im Falle einer strukturellen Gruppierung nach einem quantitativen Merkmal wird es notwendig, die Anzahl der Gruppen und ihre Grenzen zu bestimmen. Dieses Problem wird in Übereinstimmung mit den Zielen der Studie gelöst. Ein und dasselbe statistische Material kann je nach Zielsetzung der Studie auf unterschiedliche Weise in Gruppen eingeteilt werden. Die Hauptsache ist, sicherzustellen, dass bei der Gruppierung die Merkmale des untersuchten Phänomens klar wiedergegeben und die Voraussetzungen für konkrete Schlussfolgerungen und Empfehlungen geschaffen werden. Es sollte beachtet werden, dass es technisch bequemer ist, mit gleichen Intervallen umzugehen, aber dies ist aufgrund der Eigenschaften der untersuchten Phänomene und Merkmale bei weitem nicht immer möglich. In der Wirtschaft ist es häufiger notwendig, ungleiche, progressiv zunehmende Intervalle anzuwenden, was der Natur wirtschaftlicher Phänomene geschuldet ist. Die Verwendung ungleicher Intervalle ist hauptsächlich darauf zurückzuführen, dass die absolute Änderung des Gruppierungsmerkmals um den gleichen Wert für Gruppen mit einem großen und einem kleinen Wert des Merkmals bei weitem nicht derselbe Wert ist. Beispielsweise ist zwischen zwei Unternehmen mit bis zu 300 Beschäftigten eine Differenz von 100 Beschäftigten signifikanter als bei Unternehmen mit mehr als 10 Beschäftigten. Gruppenintervalle können geschlossen werden, wenn die untere und obere Grenze angegeben werden, und offen, wenn nur eine der Gruppengrenzen angegeben wird. Offene Intervalle gelten nur für Extremgruppen. Bei Gruppierung in ungleichen Abständen ist die Bildung von Gruppen mit geschlossenen Abständen wünschenswert. Dies trägt zur Genauigkeit statistischer Berechnungen bei. Eines der Ziele der statistischen Beobachtung ist es, Verbindungen und Abhängigkeiten zwischen sozialen Phänomenen zu identifizieren. Eine wichtige Aufgabe der statistischen Analyse, die auf der Grundlage einer typologischen Gruppierung, d. h. innerhalb gleichqualitativer Populationen, durchgeführt wird, ist die Aufgabe, die Beziehung zwischen einzelnen Merkmalen zu untersuchen und zu messen. Die analytische Gruppierung ermöglicht es, die Existenz eines solchen Zusammenhangs festzustellen. Analytische Gruppierung - eine gängige Methode zur statistischen Untersuchung von Beziehungen, die durch parallelen Vergleich der verallgemeinerten Werte von Merkmalen nach Gruppen gefunden werden. Es gibt abhängige Zeichen, deren Werte sich unter dem Einfluss anderer Zeichen ändern (sie werden in der Statistik normalerweise als wirksam bezeichnet), und Faktorzeichen, die andere beeinflussen. Üblicherweise ist die Grundlage der analytischen Gruppierung ein Vorzeichenfaktor, und gemäß den effektiven Vorzeichen werden Gruppenmittelwerte berechnet, deren Wertänderung das Vorhandensein einer Beziehung zwischen den Vorzeichen bestimmt. Daher können solche Gruppierungen als analytisch bezeichnet werden, die es Ihnen ermöglichen, die Beziehung zwischen den Produktions- und Faktormerkmalen von Einheiten desselben Bevölkerungstyps herzustellen und zu untersuchen. Ein wichtiges Problem analytischer Gruppierungen ist die richtige Wahl der Anzahl der Gruppen und die Bestimmung ihrer Grenzen, die anschließend die Objektivität der Merkmale des Zusammenhangs sicherstellt. Da die Analyse in Sätzen gleicher Qualität durchgeführt wird, gibt es keine theoretischen Gründe für die Aufspaltung eines bestimmten Typs. Daher ist eine Aufteilung der Grundgesamtheit in eine beliebige Anzahl von Gruppen akzeptabel, die bestimmte Anforderungen und Bedingungen einer bestimmten Analyse erfüllt. Bei der analytischen Gruppierung sind die allgemeinen Gruppierungsregeln zu beachten, d.h. die Einheiten in den gebildeten Gruppen sollten sich signifikant unterscheiden, die Anzahl der Einheiten in den Gruppen sollte ausreichen, um verlässliche statistische Merkmale zu berechnen. Außerdem müssen Gruppendurchschnitte einem bestimmten Muster folgen: konstant steigen oder fallen. Die direkte Gruppierung statistischer Beobachtungsdaten ist die primäre Gruppierung. Bei der sekundären Gruppierung handelt es sich um eine Neugruppierung zuvor gruppierter Daten. Die Notwendigkeit einer sekundären Gruppierung entsteht in zwei Fällen: 1) wenn die zuvor vorgenommene Gruppierung die Ziele der Studie in Bezug auf die Anzahl der Gruppen nicht erfüllt; 2) Daten zu verschiedenen Zeiträumen oder zu verschiedenen Territorien zu vergleichen, wenn die Primärgruppierung nach verschiedenen Gruppierungsmerkmalen oder in verschiedenen Intervallen durchgeführt wurde. Es gibt zwei Arten der sekundären Gruppierung: 1) Vereinigung kleiner Gruppen zu größeren; 2) Zuteilung eines bestimmten Anteils von Bevölkerungseinheiten. Bei einer wissenschaftlich fundierten Gruppierung sozialer Phänomene ist es notwendig, die gegenseitige Abhängigkeit von Phänomenen und die Möglichkeit des Übergangs von allmählichen quantitativen Veränderungen der Phänomene zu grundlegenden qualitativen Veränderungen zu berücksichtigen. Eine Gruppierung kann nur dann wissenschaftlich sein, wenn nicht nur die kognitiven Ziele der Gruppierung festgelegt sind, sondern auch die Grundlage für die Gruppierung – das Gruppierungsmerkmal – richtig gewählt ist. Ist die Gruppierung eine Verteilung in homogene Gruppen nach einem Merkmal, eine Zusammenfassung einzelner Bevölkerungseinheiten zu Gruppen, die nach einem bestimmten Merkmal homogen sind, dann ist ein Gruppierungsmerkmal ein Merkmal, durch das einzelne Bevölkerungseinheiten zu getrennten Gruppen zusammengefasst werden . Bei der Auswahl eines Gruppierungsmerkmals ist nicht die Art und Weise, wie das Merkmal ausgedrückt wird, wichtig, sondern seine Bedeutung für das untersuchte Phänomen. Unter diesem Gesichtspunkt sollte man für die Gruppierung die wesentlichen Merkmale nehmen, die die charakteristischsten Merkmale des untersuchten Phänomens ausdrücken. Die einfachste Gruppierung ist die Verteilungsreihe. Verteilungsreihen werden Zahlenreihen (Ziffern) genannt, die die Zusammensetzung oder Struktur eines Phänomens charakterisieren, nachdem statistische Daten zu diesem Phänomen gruppiert wurden. Eine Verteilungsreihe ist eine Gruppierung, bei der ein Indikator zur Charakterisierung von Gruppen verwendet wird – die Größe der Gruppe, d. h. es handelt sich um eine Zahlenreihe, die zeigt, wie die Einheiten der Bevölkerung entsprechend dem untersuchten Merkmal verteilt sind. Auf Attributbasis aufgebaute Zeilen werden aufgerufen Attributzeilen. Die obige Verteilungsreihe enthält drei Elemente: Varietäten eines Attributs (Männer, Frauen); die Anzahl der Einheiten in jeder Gruppe, die Häufigkeiten der Verteilungsreihe genannt; die Anzahl der Gruppen, ausgedrückt als Anteile (Prozentsätze) an der Gesamtzahl der aufgerufenen Einheiten Frequenzen. Die Summe der Häufigkeiten ist 1, wenn sie als Bruchteil von eins ausgedrückt wird, und 100 %, wenn sie als Prozentsatz ausgedrückt wird. Auf quantitativer Basis aufgebaute Verteilungsreihen werden Variationsreihen genannt. Die Zahlenwerte eines quantitativen Merkmals in der Variationsverteilungsreihe werden als Varianten bezeichnet und sind in einer bestimmten Reihenfolge angeordnet. Varianten können durch positive und negative Zahlen ausgedrückt werden, absolut und relativ. Variationsreihen werden in diskrete und Intervalle unterteilt. Diskrete Variationsreihen charakterisieren die Verteilung von Bevölkerungseinheiten gemäß einem diskreten (diskontinuierlichen) Attribut, d. h. mit ganzzahligen Werten. Bei der Konstruktion einer Verteilungsreihe mit einer diskreten Variation eines Merkmals werden alle Optionen in aufsteigender Reihenfolge ihres Werts ausgeschrieben, es wird berechnet, wie oft der gleiche Wert der Option wiederholt wird, d. H. Häufigkeit, und in einer Zeile mit geschrieben den entsprechenden Wert der Option (z. B. Verteilung der Familien nach Anzahl der Kinder). Häufigkeiten in einer diskreten Variationsreihe sowie in einer Attributreihe können durch Häufigkeiten ersetzt werden. Bei kontinuierlicher Variation kann der Wert des Attributs innerhalb eines bestimmten Intervalls beliebige Werte annehmen, beispielsweise die Verteilung der Mitarbeiter des Unternehmens nach Einkommensniveau. Beim Erstellen einer Intervallvariationsserie ist es notwendig, die optimale Anzahl von Gruppen (Zeichenintervallen) zu wählen und die Länge des Intervalls festzulegen. Die optimale Anzahl von Gruppen wird so gewählt, dass sie die Vielfalt der Merkmalswerte in der Population widerspiegelt. Meistens wird die Anzahl der Gruppen durch die Formel bestimmt: k = 1 + 3,32 lgN = 1,441 lgN + 1 wobei k die Anzahl der Gruppen ist; N - Populationsgröße. Nehmen wir zum Beispiel an, dass es notwendig ist, eine Variationsreihe von landwirtschaftlichen Betrieben entsprechend dem Getreideertrag zu bauen. Zahl der landwirtschaftlichen Betriebe 143. Wie wird die Zahl der Gruppen bestimmt? k = 1 + 3,321 lgN = 1 + 3,321 lg143 = 8,16 Die Anzahl der Gruppen kann nur ganzzahlig sein, in diesem Fall 8 oder 9. Wenn die resultierende Gruppierung die Anforderungen der Analyse nicht erfüllt, können Sie neu gruppieren. Eine sehr große Anzahl von Gruppen sollte man nicht anstreben, da in einer solchen Gruppierung die Unterschiede zwischen den Gruppen oft verschwinden. Es ist auch notwendig, die Bildung zu kleiner Gruppen, einschließlich mehrerer Bevölkerungseinheiten, zu vermeiden, da in solchen Gruppen das Gesetz der großen Zahl nicht mehr gilt und die Manifestation des Zufalls möglich ist. Wenn es nicht möglich ist, mögliche Gruppen sofort zu identifizieren, wird das gesammelte Material zuerst in eine signifikante Anzahl von Gruppen unterteilt und dann erweitert, wodurch die Anzahl der Gruppen reduziert und qualitativ homogene Gruppen erstellt werden. Gruppierungen sollten also in jedem Fall so konstruiert werden, dass die darin gebildeten Gruppen möglichst vollständig der Realität entsprechen, die Unterschiede zwischen den Gruppen sichtbar werden und sich signifikant voneinander unterscheidende Phänomene nicht zu einer zusammengefasst werden Gruppe. 3. Statistische Tabellen Nachdem die Daten der statistischen Beobachtung gesammelt und sogar gruppiert sind, ist es schwierig, sie ohne eine bestimmte visuelle Systematisierung wahrzunehmen und zu analysieren. Die Ergebnisse der statistischen Zusammenfassungen und Gruppierungen werden in Form von statistischen Tabellen dargestellt. Statistische Tabelle - eine Tabelle, die eine quantitative Beschreibung der statistischen Grundgesamtheit gibt und eine Form der visuellen Darstellung der resultierenden statistischen Zusammenfassung und Gruppierung numerischer (numerischer) Daten darstellt. Im Aussehen ist es eine Kombination aus vertikalen und horizontalen Linien. Es muss gemeinsame Seiten- und Kopfüberschriften haben. Ein weiteres Merkmal der statistischen Tabelle ist das Vorhandensein des Subjekts (ein Merkmal der statistischen Population) und des Prädikats (ein Indikator, der die Population charakterisiert). Statistische Tabellen sind eine Form der rationellsten Darstellung der Ergebnisse einer Zusammenfassung oder Gruppierung. Tabellenthema stellt die statistische Grundgesamtheit dar, auf die in der Tabelle Bezug genommen wird, d. h. eine Liste einzelner oder aller Einheiten der Grundgesamtheit oder ihrer Gruppen. Meistens wird das Thema auf der linken Seite der Tabelle platziert und enthält eine Liste von Zeichenfolgen. Tabellenprädikat - Dies sind die Indikatoren, die das in der Tabelle dargestellte Phänomen charakterisieren. Subjekt und Prädikat der Tabelle können unterschiedlich angeordnet werden. Das ist ein technisches Problem, Hauptsache die Tabelle ist gut lesbar, kompakt und leicht verständlich. In der statistischen Praxis und Forschung werden Tabellen unterschiedlicher Komplexität verwendet. Dies hängt von der Art der untersuchten Population, der Menge der verfügbaren Informationen und den Analyseaufgaben ab. Wenn das Thema der Tabelle eine einfache Liste beliebiger Objekte oder Gebietseinheiten enthält, wird die Tabelle als einfach bezeichnet. Das Thema einer einfachen Tabelle enthält keine Gruppierungen statistischer Daten. Einfache Tabellen haben die breiteste Anwendung in der statistischen Praxis. Die Merkmale der Städte der Russischen Föderation in Bezug auf Bevölkerung, Durchschnittsgehalt und Sonstiges werden durch eine einfache Tabelle dargestellt. Wenn das Thema einer einfachen Tabelle eine Liste von Territorien enthält (z. B. Regionen, Territorien, autonome Regionen, Republiken usw.), wird eine solche Tabelle als territorial bezeichnet. Eine einfache Tabelle enthält nur beschreibende Informationen und verfügt über begrenzte Analysemöglichkeiten. Eine eingehende Analyse der untersuchten Population und der Beziehungen zwischen Merkmalen erfordert die Erstellung komplexerer Tabellen – Gruppen- und Kombinationstabellen. Gruppentabellen enthalten im Gegensatz zu einfachen im Subjekt keine einfache Auflistung von Einheiten des Beobachtungsgegenstandes, sondern deren Gruppierung nach einem wesentlichen Merkmal. Die einfachste Art von Gruppentabellen sind Tabellen, die Verteilungsreihen darstellen. Die Gruppentabelle kann komplexer werden, wenn das Prädikat nicht nur die Anzahl der Einheiten in jeder Gruppe enthält, sondern auch eine Reihe anderer wichtiger Indikatoren, die die Fächergruppen quantitativ und qualitativ charakterisieren. Solche Tabellen werden häufig verwendet, um zusammenfassende Indikatoren gruppenübergreifend zu vergleichen, wodurch bestimmte praktische Schlussfolgerungen gezogen werden können. Kombinationstabellen haben breitere analytische Möglichkeiten. Kombinationstabellen werden als statistische Tabellen bezeichnet, in deren Gegenstand Gruppen von Einheiten, die nach einem Merkmal gebildet werden, nach einem oder mehreren Merkmalen in Untergruppen unterteilt werden. Im Gegensatz zu einfachen Tabellen und Gruppentabellen ermöglichen Kombinationstabellen, die Abhängigkeit der Prädikatenindikatoren von mehreren Merkmalen zu verfolgen, die die Grundlage der kombinatorischen Gruppierung im Fach bildeten. Neben den oben aufgeführten Tabellen werden in der statistischen Praxis Kontingenztafeln (oder Häufigkeitstafeln) verwendet. Grundlage für den Aufbau solcher Tabellen ist die Gruppierung von Bevölkerungseinheiten nach zwei oder mehr Merkmalen, die als Ebenen bezeichnet werden. Zum Beispiel wird die Bevölkerung nach Geschlecht (männlich, weiblich) usw. unterteilt. Somit hat Merkmal A n Abstufungen (oder Stufen) A1 A2, Einn (im Beispiel n = 2). Als nächstes untersuchen wir die Interaktion von Merkmal A mit einem anderen Merkmal – B, das in k Abstufungen (Faktoren) B unterteilt ist1, B2, Bк. In unserem Beispiel gehört Attribut B zu einem Beruf und B1, B2,.,Bk bestimmte Werte annehmen (Arzt, Fahrer, Lehrer, Baumeister usw.). Die Gruppierung nach zwei oder mehr Merkmalen wird verwendet, um die Beziehung zwischen den Merkmalen A und B zu bewerten. In einer "gefalteten" Form können die Ergebnisse von Beobachtungen durch eine Kontingenztabelle dargestellt werden, die aus n Zeilen und k Spalten besteht, in deren Zellen die Ereignishäufigkeiten nij angegeben sind, d. h. die Anzahl der Beispielobjekte, die eine Kombination von Ebenen aufweisen EINi und Bj. Wenn zwischen den Variablen A und B eine direkte oder rückgekoppelte Eins-zu-Eins-Beziehung besteht, dann konzentrieren sich alle Frequenzen nij entlang einer der Diagonalen der Tabelle. Wenn die Verbindung nicht so stark ist, fällt eine gewisse Anzahl von Beobachtungen auch auf Elemente außerhalb der Diagonale. Unter diesen Bedingungen steht der Forscher vor der Aufgabe, herauszufinden, wie genau es möglich ist, den Wert eines Merkmals aus dem Wert eines anderen vorherzusagen. Eine Häufigkeitstabelle heißt eindimensional, wenn in ihr nur eine Variable tabelliert ist. Eine Tabelle, die auf einer Gruppierung nach zwei Merkmalen (Ebenen) basiert, die durch zwei Merkmale (Faktoren) tabelliert werden, wird als Tabelle mit zwei Eingaben bezeichnet. Häufigkeitstabellen, in denen die Werte von zwei oder mehr Merkmalen tabelliert sind, nennt man Kontingenztabellen. Von allen Arten von statistischen Tabellen werden einfache Tabellen am häufigsten verwendet, statistische Gruppen- und insbesondere kombinierte statistische Tabellen werden seltener verwendet, und Kontingenztabellen werden für spezielle Arten von Analysen erstellt. Statistische Tabellen dienen als eine der wichtigsten Möglichkeiten, soziale Massenphänomene auszudrücken und zu untersuchen, aber nur, wenn sie korrekt konstruiert sind. Die Form jeder statistischen Tabelle sollte dem Wesen des Phänomens, das sie ausdrückt, und den Zwecken ihrer Untersuchung am besten entsprechen. Dies wird durch entsprechende Entwicklung des Subjekts und des Prädikats der Tabelle erreicht. Äußerlich sollte die Tabelle klein und kompakt sein, einen Titel, eine Angabe der Maßeinheiten sowie Zeit und Ort haben, auf die sich die Angaben beziehen. Die Überschriften der Zeilen und Spalten in der Tabelle sind kurz, aber präzise und klar angegeben. Übermäßiges Durcheinander der Tabelle mit digitalen Daten, schlampiges Design erschwert das Lesen und Analysieren. Wir listen die Grundregeln für den Aufbau statistischer Tabellen auf. 1. Die statistische Tabelle sollte kompakt sein und nur jene Ausgangsdaten widerspiegeln, die das untersuchte sozioökonomische Phänomen in Statik und Dynamik direkt widerspiegeln. 2. Der Titel der statistischen Tabelle und der Titel der Spalten und Zeilen sollten klar, prägnant, prägnant sein. Der Titel sollte Gegenstand, Zeichen, Zeit und Ort der Veranstaltung widerspiegeln. 3. Spalten und Zeilen sollten nummeriert werden. 4. Spalten und Zeilen müssen Maßeinheiten enthalten, für die es allgemein übliche Abkürzungen gibt. 5. Platzieren Sie die bei der Analyse verglichenen Informationen am besten in benachbarten Spalten (oder untereinander). Dies erleichtert den Vergleichsprozess. 6. Zur besseren Lesbarkeit und Arbeitserleichterung stehen die Zahlen in der Statistiktabelle in der Mitte der Spalte, streng untereinander: Einheiten unter Einheiten, Komma unter Komma. 7. Es ist ratsam, Zahlen mit der gleichen Genauigkeit zu runden (bis zu einem ganzen Zeichen, bis zu einem Zehntel). 8. Das Fehlen von Daten wird durch das Multiplikationszeichen "h" angezeigt, wenn diese Position nicht ausgefüllt werden soll, wird das Fehlen von Informationen durch Auslassungspunkte (...) oder n angezeigt. D. oder n. St., in Abwesenheit eines Phänomens wird ein Bindestrich (-) gesetzt. 9. Um sehr kleine Zahlen anzuzeigen, verwenden Sie die Schreibweise 0.0 oder 0.00. 10. Wenn eine Zahl auf der Grundlage bedingter Berechnungen ermittelt wird, wird sie in Klammern gesetzt, zweifelhafte Zahlen werden mit einem Fragezeichen und vorläufige Zahlen mit einem „!“ versehen. Wenn zusätzliche Informationen benötigt werden, werden statistische Tabellen von Fußnoten und Anmerkungen begleitet, die beispielsweise die Art des spezifischen Indikators, die angewandte Methodik usw. erläutern. Fußnoten werden verwendet, um auf einschränkende Umstände hinzuweisen, die beim Lesen der Tabelle berücksichtigt werden müssen. Wenn diese Regeln eingehalten werden, wird die statistische Tabelle zum Hauptmittel für die Präsentation, Verarbeitung und Zusammenfassung statistischer Informationen über den Stand und die Entwicklung der untersuchten sozioökonomischen Phänomene. 4. Grafische Darstellungen statistischer Informationen Die als Ergebnis einer zusammenfassenden oder statistischen Analyse als Ganzes erhaltenen numerischen Indikatoren können nicht nur in tabellarischer, sondern auch in grafischer Form dargestellt werden. Die Verwendung von Grafiken zur Darstellung statistischer Informationen ermöglicht es, statistischen Daten Visualisierung und Aussagekraft zu verleihen, ihre Wahrnehmung und in vielen Fällen die Analyse zu erleichtern. Die Vielfalt der grafischen Darstellungen statistischer Indikatoren bietet großartige Möglichkeiten für die ausdrucksstärkste Demonstration eines Phänomens oder Prozesses. Grafiken in der Statistik werden konventionelle Bilder numerischer Größen und ihrer Beziehungen in Form verschiedener geometrischer Bilder genannt – Punkte, Linien, flache Figuren usw. Das statistische Diagramm ermöglicht es Ihnen, die Art des untersuchten Phänomens, seine inhärenten Muster und Merkmale, Entwicklungstrends und die Beziehung der es charakterisierenden Indikatoren sofort zu beurteilen. Jeder Graph besteht aus einem grafischen Bild und Hilfselementen. Grafisches Bild ist eine Sammlung von Punkten, Linien und Formen, die statistische Daten darstellen. Zu den Hilfselementen des Diagramms gehören der allgemeine Name des Diagramms, Koordinatenachsen, Skalen, numerische Gitter und numerische Daten, die die angezeigten Indikatoren ergänzen und verfeinern. Hilfselemente erleichtern das Lesen der Grafik und ihre Interpretation. Der Titel des Diagramms sollte seinen Inhalt kurz und genau beschreiben. Erklärende Texte können sich innerhalb oder neben der Grafik befinden oder außerhalb platziert werden. Zum Zeichnen und Verwenden sind Koordinatenachsen mit aufgedruckten Skalen und Zahlengittern erforderlich. Skalen können geradlinig oder krummlinig (kreisförmig), einheitlich (linear) und uneben sein. Oft empfiehlt es sich, sogenannte konjugierte Skalen zu verwenden, die auf einer oder zwei parallelen Linien aufgebaut sind. Am häufigsten wird eine der konjugierten Skalen zur Messung absoluter Werte und die zweite zur Messung der entsprechenden relativen Werte verwendet. Die Zahlen auf der Skala sind gleichmäßig verteilt und die letzte Zahl muss den maximalen Wert des Indikators überschreiten, dessen Wert auf dieser Skala berechnet wird. Ein Zahlengitter sollte in der Regel eine Grundlinie haben, deren Rolle normalerweise die x-Achse spielt. Statistische Grafiken können nach verschiedenen Kriterien klassifiziert werden: Zweck (Inhalt), Konstruktionsweise und Art des grafischen Bildes. Je nach Inhalt oder Zweck können wir unterscheiden: 1) Vergleichsgraphen im Raum; 2) Diagramme verschiedener relativer Werte (Strukturen, Dynamik usw.); 3) Graphen von Variationsreihen; 4) Platzierungspläne nach Gebiet; 5) Grafiken von miteinander verbundenen Indikatoren usw. Je nach Art der Erstellung von Grafiken können sie in Diagramme und statistische Karten unterteilt werden. Diagramme sind die gebräuchlichste Methode zur grafischen Darstellung. Dies sind Diagramme quantitativer Beziehungen. Die Arten und Methoden ihrer Konstruktion sind vielfältig. Diagramme werden zum visuellen Vergleich voneinander unabhängiger Werte in verschiedenen Aspekten (räumlich, zeitlich usw.) verwendet: Territorien, Bevölkerung usw. In diesem Fall erfolgt der Vergleich der untersuchten Populationen anhand einiger signifikant variierender Merkmale . Statistische Karten – Diagramme der quantitativen Verteilung über eine Oberfläche. In ihrem Hauptzweck sind sie eng mit Diagrammen verwandt und nur in dem Sinne spezifisch, dass sie herkömmliche Bilder statistischer Daten auf einer geografischen Konturkarte darstellen, das heißt, sie zeigen die räumliche Verteilung oder räumliche Verteilung statistischer Daten. Basierend auf der Art des grafischen Bildes werden sie in Punkt-, Linien-, Flächen- (Balken-, Streifen-, Quadrat-, Kreis-, Sektor-, geschweifte) und volumetrische Diagramme unterteilt. Bei der Erstellung von Streudiagrammen werden Ansammlungen von Punkten als grafische Bilder verwendet; bei der Erstellung von linearen Diagrammen werden Linien verwendet. Das Grundprinzip bei der Konstruktion aller planaren Diagramme besteht darin, dass statistische Größen in Form von geometrischen Figuren dargestellt werden. Statistische Karten werden grafisch in Kartogramme und Kartodiagramme unterteilt. Je nach Umfang der zu lösenden Aufgaben werden Vergleichsdiagramme, Strukturdiagramme und Dynamikdiagramme unterschieden. Die gebräuchlichsten Vergleichsdiagramme sind Balkendiagramme, deren Konstruktionsprinzip darin besteht, statistische Indikatoren in Form vertikaler Rechtecke – Balken – darzustellen. Jede Spalte zeigt den Wert einer separaten Ebene der untersuchten statistischen Reihe. Somit ist ein Vergleich statistischer Indikatoren möglich, da alle verglichenen Indikatoren in einer Maßeinheit ausgedrückt werden. Beim Erstellen von Balkendiagrammen ist es notwendig, ein rechteckiges Koordinatensystem zu zeichnen, in dem sich die Balken befinden. Die Sockel der Säulen liegen auf der horizontalen Achse; die Größe des Sockels wird willkürlich bestimmt, ist aber für alle gleich eingestellt. Entlang der vertikalen Achse befindet sich die Skala, die die Höhenskalierung der Säulen bestimmt. Die vertikale Größe jedes Balkens entspricht der Größe des im Diagramm angezeigten statistischen Indikators. Somit ist für alle Balken, aus denen das Diagramm besteht, nur eine Dimension eine Variable. Die Platzierung der Balken im Diagrammfeld kann unterschiedlich sein: 1) im gleichen Abstand voneinander; 2) nahe beieinander; 3) in privater Auferlegung aufeinander. Die Regeln zum Erstellen von Balkendiagrammen ermöglichen die gleichzeitige Platzierung von Bildern mehrerer Indikatoren auf derselben horizontalen Achse. Dabei sind die Säulen in Gruppen angeordnet, für die jeweils eine andere Dimension mit unterschiedlichen Merkmalen angenommen werden kann. Bei den Balkendiagrammen handelt es sich um sogenannte Streifendiagramme. Der Unterschied besteht darin, dass die Skala oben horizontal angeordnet ist und die Länge der Streifen bestimmt. Der Anwendungsbereich von Balken- und Streifendiagrammen ist der gleiche, da die Regeln für deren Aufbau identisch sind. Die Eindimensionalität der dargestellten statistischen Indikatoren und ihr einheitlicher Charakter für verschiedene Spalten und Streifen erfordern die Erfüllung einer einzigen Bestimmung: Einhaltung der Verhältnismäßigkeit (Säulen – in der Höhe, Streifen – in der Länge) und der Verhältnismäßigkeit zu den dargestellten Werten. Um diese Anforderung zu erfüllen, ist es notwendig: erstens, dass die Skala, auf der die Größe der Spalte (Balken) festgelegt wird, bei Null beginnt; zweitens muss diese Skala kontinuierlich sein, also alle Zahlen einer gegebenen statistischen Reihe abdecken; Das Brechen der Skala und dementsprechend Spalten (Streifen) ist nicht zulässig. Die Nichtbeachtung dieser Regeln führt zu einer verzerrten grafischen Darstellung des analysierten statistischen Materials. Balken- und Streifendiagramme als Methode zur grafischen Darstellung statistischer Daten sind grundsätzlich austauschbar, d. h. die betrachteten statistischen Indikatoren können gleichermaßen sowohl in Balken als auch in Balken dargestellt werden. In beiden Fällen wird zur Darstellung des Ausmaßes des Phänomens ein Maß für jedes Rechteck verwendet – die Höhe der Säule oder die Länge des Streifens. Daher ist der Anwendungsbereich dieser beiden Diagramme grundsätzlich gleich. Eine Variation von Balkendiagrammen (Balkendiagrammen) sind Richtungsdiagramme. Sie unterscheiden sich von gewöhnlichen durch die beidseitige Anordnung von Säulen oder Streifen und haben in der Mitte einen Maßstabsbezugspunkt. Typischerweise werden solche Diagramme verwendet, um Mengen entgegengesetzter qualitativer Werte darzustellen. Der Vergleich von Säulen (Streifen), die in verschiedene Richtungen gerichtet sind, ist weniger effektiv als solche, die in derselben Richtung nebeneinander liegen. Dennoch lässt die Analyse von Richtungsdiagrammen durchaus aussagekräftige Schlussfolgerungen zu, da die besondere Lage dem Diagramm ein helles Bild verleiht. Die zweiseitige Gruppe umfasst Diagramme reiner Abweichungen. Bei ihnen sind die Streifen von der vertikalen Nulllinie aus in beide Richtungen gerichtet: nach rechts für eine Zunahme, nach links für eine Abnahme. Mit Hilfe solcher Diagramme lassen sich Abweichungen von einem Plan oder einem bestimmten Niveau als Vergleichsbasis darstellen. Ein wichtiger Vorteil der betrachteten Diagramme ist die Möglichkeit, die Schwankungsbreite des untersuchten statistischen Merkmals zu erkennen, was an sich für die Analyse von großer Bedeutung ist. Für einen einfachen Vergleich voneinander unabhängiger Indikatoren können auch Diagramme verwendet werden, deren Konstruktionsprinzip darin besteht, dass die verglichenen Größen in Form regelmäßiger geometrischer Figuren dargestellt werden, die so aufgebaut sind, dass ihre Flächen zueinander in Beziehung stehen die durch diese Zahlen dargestellten Mengen. Mit anderen Worten: Diese Diagramme drücken die Größe des dargestellten Phänomens durch die Größe ihrer Fläche aus. Um Diagramme der betrachteten Art zu erhalten, werden verschiedene geometrische Formen verwendet – ein Quadrat, ein Kreis und seltener – ein Rechteck. Es ist bekannt, dass die Fläche eines Quadrats gleich dem Quadrat seiner Seite ist und die Fläche eines Kreises proportional zum Quadrat seines Radius bestimmt wird. Um Diagramme zu erstellen, ist es daher notwendig, zunächst die Quadratwurzel aus den verglichenen Werten zu ziehen und dann basierend auf den erhaltenen Ergebnissen die Seite des Quadrats oder den Radius des Kreises gemäß der akzeptierten Skala zu bestimmen. Am ausdrucksvollsten und am leichtesten zu erkennen ist die Methode, Vergleichsdiagramme in Form von Figurenzeichen zu erstellen. In diesem Fall werden statistische Aggregate nicht durch geometrische Figuren, sondern durch Symbole oder Zeichen dargestellt. Der Vorteil dieser grafischen Darstellungsweise liegt in einer hohen Übersichtlichkeit, indem man eine ähnliche Darstellung erhält, die den Inhalt der verglichenen Populationen widerspiegelt. Das wichtigste Merkmal eines jeden Diagramms ist der Maßstab. Um ein geschweiftes Diagramm korrekt zu erstellen, ist es daher erforderlich, die Rechnungseinheit zu bestimmen. Als letzteres wird eine separate Ziffer (Symbol) genommen, der bedingt ein bestimmter Zahlenwert zugeordnet ist. Und der untersuchte statistische Wert wird durch eine separate Anzahl von Figuren gleicher Größe dargestellt, die sich nacheinander in der Figur befinden. Allerdings ist es in den meisten Fällen nicht möglich, eine Statistik mit ganzen Zahlen darzustellen. Letzteres muss in Teile geteilt werden, da ein Zeichen maßstäblich eine zu große Maßeinheit ist. Normalerweise wird dieser Teil mit dem Auge bestimmt. Die Schwierigkeit, es genau zu bestimmen, ist ein Nachteil von geschweiften Diagrammen. Eine größere Genauigkeit bei der Darstellung statistischer Daten wird jedoch nicht angestrebt, und die Ergebnisse sind durchaus zufriedenstellend. In der Regel werden Zahlendiagramme häufig verwendet, um Statistiken und Werbung bekannt zu machen. Die Hauptstruktur von Strukturdiagrammen ist eine grafische Darstellung der Zusammensetzung statistischer Aggregate, die als Verhältnis verschiedener Teile jedes der Aggregate gekennzeichnet ist. Die Zusammensetzung der statistischen Grundgesamtheit kann sowohl anhand absoluter als auch relativer Indikatoren grafisch dargestellt werden. Im ersten Fall werden nicht nur die Größen der Teile, sondern auch die Größe des Diagramms als Ganzes durch statistische Werte bestimmt und ändern sich entsprechend deren Änderungen. Im zweiten Fall ändert sich die Größe des gesamten Diagramms nicht (da die Summe aller Teile einer Menge 100 % beträgt), und nur die Größe seiner einzelnen Teile ändert sich. Eine grafische Darstellung der Zusammensetzung der Bevölkerung in absoluten und relativen Indikatoren ermöglicht eine tiefergehende Analyse und ermöglicht internationale Vergleiche und Vergleiche sozioökonomischer Phänomene. Die gebräuchlichste Art, die Struktur statistischer Grundgesamtheiten grafisch darzustellen, ist ein Tortendiagramm, das für diesen Zweck als die Hauptform eines Diagramms angesehen wird. Dies liegt daran, dass die Idee des Ganzen sehr gut und deutlich durch den Kreis ausgedrückt wird, der die Gesamtheit darstellt. Das spezifische Gewicht jedes Bevölkerungsteils im Tortendiagramm wird durch den Wert des Zentriwinkels (der Winkel zwischen den Radien des Kreises) charakterisiert. Die Summe aller Winkel eines Kreises, gleich 360°, entspricht 100 %, und daher wird 1 % gleich 3,6° genommen. Die Verwendung von Tortendiagrammen ermöglicht nicht nur die grafische Darstellung der Bevölkerungsstruktur und ihrer Veränderung, sondern auch die Darstellung der Dynamik der Bevölkerungsgröße. Dazu werden Kreise gebildet, die proportional zum Volumen des untersuchten Merkmals sind, und dann werden seine einzelnen Teile nach Sektoren unterschieden. Die betrachtete Methode der grafischen Darstellung der Bevölkerungsstruktur hat sowohl Vor- als auch Nachteile. Somit behält ein Tortendiagramm nur bei wenigen Bevölkerungsteilen Sichtbarkeit und Aussagekraft, ansonsten ist sein Einsatz wirkungslos. Zudem nimmt die Sichtbarkeit des Tortendiagramms bei geringfügigen Änderungen in der Struktur der abgebildeten Populationen ab: Sie ist höher, wenn die Unterschiede in den verglichenen Strukturen signifikanter sind. Der Vorteil von Balken- (Band-) Strukturdiagrammen im Vergleich zu Kreisdiagrammen ist ihre große Kapazität, die Fähigkeit, eine größere Menge nützlicher Informationen widerzuspiegeln. Diese Diagramme sind jedoch effektiver für kleine Unterschiede in der Struktur der untersuchten Population. Dynamische Diagramme werden erstellt, um die zeitliche Entwicklung eines Phänomens darzustellen und zu beurteilen. Zur visuellen Darstellung von Phänomenen in der Reihe der Dynamiken werden Balken-, Streifen-, Quadrat-, Kreis-, Linear-, Radialdiagramme usw. verwendet.Die Wahl des Diagrammtyps hängt hauptsächlich von den Eigenschaften der Ausgangsdaten und dem Zweck ab die Studium. Wenn es beispielsweise eine Reihe von Dynamiken mit mehreren zeitlich ungleichmäßig verteilten Ebenen gibt (1914, 1049, 1980, 1985, 1996, 2003), werden zur besseren Übersichtlichkeit häufig Balken-, Quadrat- oder Tortendiagramme verwendet. Sie sind optisch beeindruckend, gut einprägsam, aber für die Darstellung einer großen Anzahl von Leveln nicht geeignet, da sie umständlich sind. Bei einer großen Anzahl von Ebenen in einer Reihe von Dynamiken empfiehlt es sich, Liniendiagramme zu verwenden, die die Kontinuität des Entwicklungsprozesses in Form einer durchgezogenen gestrichelten Linie wiedergeben. Darüber hinaus sind Liniendiagramme bequem zu verwenden: 1) wenn der Zweck der Studie darin besteht, den allgemeinen Trend und die Art der Entwicklung des Phänomens darzustellen; 2) wenn es notwendig ist, mehrere Zeitreihen in einem Diagramm darzustellen, um sie zu vergleichen; 3) wenn der Vergleich der Wachstumsraten am signifikantesten ist, nicht der Niveaus. Um lineare Diagramme zu erstellen, wird ein rechteckiges Koordinatensystem verwendet. Üblicherweise wird auf der Abszissenachse die Zeit (Jahre, Monate etc.) und auf der Ordinatenachse die Dimension der dargestellten Phänomene oder Prozesse aufgetragen. Auf den Ordinatenachsen sind Maßstäbe markiert. Auf ihre Auswahl sollte besonderes Augenmerk gelegt werden, da davon das Gesamterscheinungsbild der Grafik abhängt. In Grafiken ist es notwendig, auf Gleichgewicht und Proportionalität zwischen den Koordinatenachsen zu achten, da ein Ungleichgewicht zwischen den Koordinatenachsen ein falsches Bild der Entwicklung des Phänomens vermittelt. Wenn der Maßstab für die Skala auf der Abszissenachse im Vergleich zum Maßstab auf der Ordinatenachse stark gestreckt ist, dann fallen Schwankungen in der Dynamik von Phänomenen kaum auf, und umgekehrt vergrößert sich der Maßstab entlang der Ordinatenachse im Vergleich zum Maßstab auf der Ordinatenachse Die Abszissenachse weist starke Schwankungen auf. Gleiche Zeiträume und Levelgrößen müssen gleichen Segmenten der Skala entsprechen. In der statistischen Praxis werden am häufigsten grafische Bilder mit einheitlichen Maßstäben verwendet. Auf der Abszissenachse werden sie im Verhältnis zur Anzahl der Zeiträume und auf der Ordinatenachse im Verhältnis zu den Pegeln selbst aufgetragen. Der Maßstab der einheitlichen Skala ist die Länge des Segments als Ganzes. Oftmals zeigt ein linearer Graph mehrere Kurven, die eine vergleichende Beschreibung der Dynamik verschiedener Indikatoren oder desselben Indikators liefern. Sie sollten jedoch nicht mehr als 3-4 Kurven in einem Diagramm platzieren, da eine große Anzahl davon die Zeichnung zwangsläufig erschwert und das lineare Diagramm an Klarheit verliert. In einigen Fällen ermöglicht die Darstellung zweier Kurven in einem Diagramm die gleichzeitige Darstellung der Dynamik des dritten Indikators, wenn es sich um die Differenz der ersten beiden handelt. Wenn Sie beispielsweise die Dynamik von Fruchtbarkeit und Sterblichkeit darstellen, zeigt die Fläche zwischen zwei Kurven das Ausmaß des natürlichen Anstiegs oder natürlichen Rückgangs der Bevölkerung. Manchmal ist es notwendig, die Dynamik zweier Indikatoren mit unterschiedlichen Maßeinheiten in einem Diagramm zu vergleichen. In solchen Fällen benötigen Sie nicht eine, sondern zwei Waagen. Einer davon ist rechts platziert, der andere links. Ein solcher Kurvenvergleich liefert jedoch kein ausreichend vollständiges Bild der Dynamik dieser Indikatoren, da die Skalen willkürlich sind. Daher sollte der Vergleich der Dynamik des Niveaus zweier unterschiedlicher Indikatoren auf der Grundlage der Verwendung einer Skala durchgeführt werden, nachdem absolute Werte in relative Werte umgewandelt wurden. Lineare Diagramme mit einer linearen Skala haben einen Nachteil, der ihren kognitiven Wert verringert: Mit einer einheitlichen Skala können Sie nur die absoluten Zu- oder Abnahmen der Indikatoren messen und vergleichen, die sich während des Studienzeitraums im Diagramm widerspiegeln. Bei der Untersuchung der Dynamik ist es jedoch wichtig, die relativen Änderungen der untersuchten Indikatoren im Vergleich zum erreichten Niveau oder der Änderungsrate zu kennen. Es sind die relativen Veränderungen der ökonomischen Dynamikindikatoren, die verzerrt werden, wenn sie in einem Koordinatendiagramm mit einheitlichem vertikalen Maßstab dargestellt werden. Außerdem verliert es in herkömmlichen Koordinaten jede Übersichtlichkeit und wird sogar für Zeitreihen mit stark wechselnden Pegeln, die normalerweise in Zeitreihen über einen langen Zeitraum stattfinden, nicht mehr darstellbar. In diesen Fällen sollte die Einheitsskala aufgegeben werden und die Grafik auf einem halblogarithmischen System basieren. Die Grundidee des halblogarithmischen Systems besteht darin, dass darin gleiche lineare Segmente gleichen Werten der Logarithmen von Zahlen entsprechen. Dieser Ansatz hat den Vorteil, dass die Größe großer Zahlen durch ihr logarithmisches Äquivalent reduziert werden kann. Bei einer Skalenskala in Form von Logarithmen ist die Grafik jedoch schwer zu verstehen. Es ist notwendig, neben den auf der Skalenskala angegebenen Logarithmen die Zahlen selbst anzugeben, die die Ebenen der dargestellten Dynamikreihen charakterisieren, die den angegebenen Logarithmenzahlen entsprechen. Diese Arten von Diagrammen werden als Diagramme auf einem halblogarithmischen Gitter bezeichnet. Ein halblogarithmisches Gitter ist ein Gitter, in dem auf einer Achse ein linearer Maßstab und auf der anderen ein logarithmischer Maßstab aufgetragen ist. Die Dynamik wird auch durch in Polarkoordinaten erstellte Radialdiagramme dargestellt. Radialdiagramme haben das Ziel, eine bestimmte rhythmische Bewegung im Zeitverlauf visuell darzustellen. Die häufigste Verwendung dieser Diagramme ist die Darstellung saisonaler Schwankungen. Radiale Diagramme werden in geschlossene und spiralförmige Diagramme unterteilt. Konstruktionstechnisch unterscheiden sich Radialdiagramme je nachdem, was als Bezugspunkt genommen wird – der Mittelpunkt des Kreises oder der Umfang. Geschlossene Diagramme spiegeln den unterjährlichen Dynamikzyklus eines jeden Jahres wider. Spiraldiagramme zeigen den unterjährlichen Dynamikzyklus über mehrere Jahre hinweg. Die Konstruktion geschlossener Diagramme läuft wie folgt ab: Es wird ein Kreis gezeichnet, der Monatsdurchschnitt ist gleich dem Radius dieses Kreises. Anschließend wird der gesamte Kreis in 12 Radien unterteilt, die in der Grafik als dünne Linien dargestellt werden. Jeder Radius bezeichnet einen Monat, und die Position der Monate ähnelt dem Zifferblatt einer Uhr: Januar – an der Stelle, an der die Uhr 1 anzeigt, Februar – an der Stelle, an der 2 usw. An jedem Radius ist eine bestimmte Markierung angebracht Platz entsprechend der Skala basierend auf den Daten für den entsprechenden Monat. Übersteigen die Daten den Jahresdurchschnitt, wird außerhalb des Kreises in einer Erweiterung des Radius eine Markierung angebracht. Dann werden die Markierungen verschiedener Monate durch Segmente verbunden. Nimmt man aber als Grundlage für den Bericht nicht den Kreismittelpunkt, sondern den Kreis, so nennt man solche Diagramme Spiraldiagramme. Die Konstruktion von Spiraldiagrammen unterscheidet sich von geschlossenen Diagrammen darin, dass in ihnen der Dezember eines Jahres nicht mit dem Januar desselben Jahres, sondern mit dem Januar des nächsten Jahres verbunden ist. Dadurch ist es möglich, die gesamte Dynamikreihe in Form einer Spirale darzustellen. Ein solches Diagramm ist besonders anschaulich, wenn neben jahreszeitlichen Schwankungen von Jahr zu Jahr ein stetiger Anstieg zu verzeichnen ist. Statistische Karten sind eine Art grafische Darstellung statistischer Daten auf einer schematischen geografischen Karte, die das Ausmaß oder den Grad der Verbreitung eines bestimmten Phänomens in einem bestimmten Gebiet charakterisiert. Mittel zur Darstellung der territorialen Verteilung sind Schraffuren, Hintergrundeinfärbungen oder geometrische Formen. Es gibt Kartogramme und Kartogramme. Kartogramme - это схематическая географическая карта, на которой штриховкой различной густоты, точками или окраской определенной степени насыщенности показывается сравнительная интенсивность какого-либо показателя в пределах каждой единицы нанесенного на карту территориального деления (например, плотность населения по областям или республикам, распределения районов по урожайности зерновых культур usw.). Kartogramme werden in Hintergrund und Punkt unterteilt. Hintergrund des Kartogramms - eine Art Kartogramm, auf dem eine Schattierung unterschiedlicher Dichte oder Färbung mit einem bestimmten Sättigungsgrad die Intensität eines beliebigen Indikators innerhalb einer Gebietseinheit anzeigt. Punktkartogramm - eine Art Kartogramm, in dem das Niveau des ausgewählten Phänomens mit Hilfe von Punkten dargestellt wird. Ein Punkt stellt eine Einheit im Aggregat oder eine bestimmte Anzahl von ihnen dar und zeigt auf einer geografischen Karte die Dichte oder Häufigkeit der Manifestation eines bestimmten Merkmals. Hintergrundkartogramme werden in der Regel zur Darstellung durchschnittlicher oder relativer Indikatoren, Punktkarten – für volumetrische (quantitative) Indikatoren (wie Bevölkerung, Viehbestand usw.) verwendet. Die zweite große Gruppe statistischer Karten sind Chartdiagramme, die eine Kombination von Diagrammen mit einer geografischen Karte darstellen. Diagrammfiguren (Balken, Quadrate, Kreise, Figuren, Streifen) werden als Bildzeichen in Kartogrammen verwendet, die auf der Kontur einer Landkarte platziert werden. Kartogramme ermöglichen es, geografisch komplexere statistische und geografische Konstruktionen abzubilden als Kartogramme. Unter Kartogrammen müssen Kartodiacs des einfachen Vergleichs, Graphen der räumlichen Verschiebung und Isolinien unterschieden werden. Auf einem Kartogramm eines einfachen Vergleichs sind die Diagrammzahlen, die die Werte des untersuchten Indikators darstellen, im Gegensatz zu einem regulären Diagramm nicht wie in einem regulären Diagramm in einer Reihe angeordnet, sondern entsprechend der Region über die Karte verteilt , Region oder Land, das sie repräsentieren. Elemente des einfachsten kartografischen Diagramms finden sich auf einer politischen Karte, auf der Städte je nach Einwohnerzahl durch verschiedene geometrische Formen gekennzeichnet sind. Konturen - dies sind gleichwertige Linien einer Größe in ihrer Verteilung auf der Oberfläche, insbesondere auf einer geografischen Karte oder Grafik. Die Isolinie spiegelt die kontinuierliche Veränderung der untersuchten Größe in Abhängigkeit von zwei weiteren Variablen wider und dient der Kartierung natürlicher und sozioökonomischer Phänomene. Isolinien werden verwendet, um quantitative Eigenschaften der untersuchten Größen zu erhalten und die Korrelationen zwischen ihnen zu analysieren. VORTRAG Nr. 4. Statistische Werte und Indikatoren 1. Zweck und Arten von statistischen Indikatoren und Werten Art und Inhalt statistischer Indikatoren entsprechen den wirtschaftlichen und sozialen Phänomenen und Prozessen, die sie widerspiegeln. Alle wirtschaftlichen und sozialen Kategorien oder Konzepte sind abstrakter Natur und spiegeln die wesentlichsten Merkmale, allgemeinen Zusammenhänge von Phänomenen wider. Und um die Größe und Korrelation von Phänomenen oder Prozessen zu messen, dh ihnen ein angemessenes quantitatives Merkmal zu geben, entwickeln sie ökonomische und soziale Indikatoren, die jeder Kategorie (Konzept) entsprechen. Es ist die Übereinstimmung von Indikatoren des Wesens ökonomischer Kategorien, die die Einheit der quantitativen und qualitativen Merkmale wirtschaftlicher und sozialer Phänomene und Prozesse gewährleistet. Es gibt zwei Arten von Indikatoren für die wirtschaftliche und soziale Entwicklung der Gesellschaft: geplante (Prognose) und Berichterstattung (statistische). Geplante Indikatoren sind bestimmte spezifische Werte von Indikatoren, deren Erreichung in zukünftigen Perioden vorhergesagt wird. Berichtsindikatoren charakterisieren die tatsächlichen Bedingungen der wirtschaftlichen und sozialen Entwicklung, das tatsächlich erreichte Niveau für einen bestimmten Zeitraum. Statistischer (Berichts-) Indikator - dies ist ein objektives quantitatives Merkmal (Maß) eines sozialen Phänomens oder Prozesses in seiner qualitativen Gewissheit unter bestimmten Bedingungen von Ort und Zeit. Jeder statistische Indikator hat einen qualitativen sozioökonomischen Inhalt und eine zugehörige Messmethodik. Ein statistischer Indikator hat auch die eine oder andere statistische Form (Struktur). Der Indikator kann die Gesamtzahl der Bevölkerungseinheiten, die Gesamtsumme der Werte des quantitativen Attributs dieser Einheiten, den Durchschnittswert des Attributs, den Wert dieses Attributs im Verhältnis zum Wert eines anderen usw. ausdrücken. Ein statistischer Indikator hat auch einen bestimmten quantitativen Wert oder numerischen Ausdruck. Dieser numerische Wert eines statistischen Indikators, ausgedrückt in bestimmten Maßeinheiten, wird als seine Größe bezeichnet. Der Wert des Indikators variiert normalerweise räumlich und schwankt zeitlich. Daher ist ein obligatorisches Attribut eines statistischen Indikators auch die Angabe des Gebiets und des Zeitpunkts oder Zeitraums. Statistische Indikatoren können bedingt in primäre (volumetrisch, quantitativ, umfangreich) und sekundäre (abgeleitet, qualitativ, intensiv) unterteilt werden. Primär charakterisieren entweder die Gesamtzahl der Bevölkerungseinheiten oder die Summe der Werte eines ihrer Attribute. In der Dynamik, im zeitlichen Wandel genommen, charakterisieren sie im Einzelfall den weitreichenden Entwicklungsweg der Wirtschaft als Ganzes oder eines einzelnen Unternehmens. Entsprechend der statistischen Form handelt es sich bei diesen Kennzahlen um statistische Gesamtwerte. Sekundäre (abgeleitete) Indikatoren werden normalerweise als Durchschnitts- und Relativwerte ausgedrückt und charakterisieren normalerweise den Weg intensiver Entwicklung, wenn sie in Dynamik genommen werden. Indikatoren, die die Größe einer komplexen Reihe von sozioökonomischen Phänomenen und Prozessen charakterisieren, werden oft als synthetisch bezeichnet (BIP, Volkseinkommen, soziale Arbeitsproduktivität, Verbraucherkorb usw.). Abhängig von den verwendeten Maßeinheiten gibt es Natur-, Kosten- und Arbeitsindikatoren (in Mannstunden, Standardstunden). Je nach Anwendungsbereich gibt es Indikatoren, die auf regionaler, sektoraler Ebene usw. berechnet werden. Je nach Genauigkeit des reflektierten Phänomens werden die erwarteten, vorläufigen und endgültigen Werte der Indikatoren unterschieden. Je nach Umfang und Inhalt des statistischen Untersuchungsgegenstandes werden individuelle (charakterisierende einzelne Bevölkerungseinheiten) und zusammenfassende (verallgemeinernde) Indikatoren unterschieden. Daher werden statistische Werte, die die Massen oder Mengen von Einheiten charakterisieren, als verallgemeinernde statistische Indikatoren (Werte) bezeichnet. Zusammenfassungsindikatoren spielen aufgrund der folgenden Besonderheiten eine sehr wichtige Rolle in der statistischen Forschung: 1) eine zusammenfassende (konzentrierte) Beschreibung der Aggregate von Einheiten der untersuchten sozialen Phänomene geben; 2) die zwischen den Phänomenen bestehenden Verbindungen und Abhängigkeiten auszudrücken und so eine zusammenhängende Untersuchung der Phänomene bereitzustellen; 3) charakterisieren die in den Phänomenen auftretenden Veränderungen, die sich abzeichnenden Muster ihrer Entwicklung und andere Dinge, d. H. Sie führen eine ökonomische und statistische Analyse der betrachteten Phänomene durch, einschließlich auf der Grundlage der Zerlegung der verallgemeinernden Größen selbst in ihre Bestandteile, ihre bestimmenden Faktoren usw. Eine objektive und zuverlässige Untersuchung komplexer wirtschaftlicher und sozialer Kategorien ist nur auf der Grundlage eines Systems statistischer Indikatoren möglich, die in Einheit und Verknüpfung verschiedene Aspekte und Aspekte des Zustands und der Dynamik der Entwicklung dieser Kategorien charakterisieren. Statistische Indikatoren, die die Einheit und die Zusammenhänge wirtschaftlicher und sozialer Phänomene und Prozesse objektiv widerspiegeln, sind keine weit hergeholten, willkürlich konstruierten Dogmen, die ein für alle Mal aufgestellt werden. Im Gegenteil, die dynamische Entwicklung von Gesellschaft, Wissenschaft, Computertechnologie, die Verbesserung statistischer Methoden führen dazu, dass veraltete Indikatoren, die ihren Wert verloren haben, sich ändern oder verschwinden und neue, fortschrittlichere Indikatoren erscheinen, die die aktuellen Bedingungen objektiv und zuverlässig widerspiegeln der gesellschaftlichen Entwicklung. Daher sollte die Konstruktion und Verbesserung statistischer Indikatoren auf der Beachtung zweier Grundprinzipien beruhen: 1) Objektivität und Realität (Indikatoren müssen wahrheitsgemäß und angemessen das Wesen der relevanten wirtschaftlichen und sozialen Kategorien (Konzepte) widerspiegeln); 2) umfassende theoretische und methodische Validität (die Bestimmung des Werts des Indikators, seine Messbarkeit und Vergleichbarkeit in der Dynamik müssen wissenschaftlich begründet, klar und verständlich formuliert und in einer einheitlichen Interpretation eindeutig anwendbar sein). Darüber hinaus müssen die Werte der Indikatoren korrekt quantifiziert werden, wobei das Niveau, die Größenordnung und die qualitativen Merkmale des Zustands oder der Entwicklung des entsprechenden wirtschaftlichen oder sozialen Phänomens (Branchen- und Regionalebene, ein einzelnes Unternehmen oder ein einzelner Mitarbeiter usw.) ). Gleichzeitig sollte die Konstruktion von Indikatoren bereichsübergreifender Natur sein, die es nicht nur ermöglicht, die relevanten Indikatoren zusammenzufassen, sondern auch ihre qualitative Homogenität in Gruppen und Aggregaten sicherzustellen, den Übergang von einem Indikator zum anderen vollständig den Umfang und die Struktur einer komplexeren Kategorie oder eines Phänomens charakterisieren. Schließlich sollten die Konstruktion eines statistischen Indikators, seine Struktur und sein Wesen die Möglichkeit bieten, das untersuchte Phänomen oder den untersuchten Prozess umfassend zu analysieren, die Merkmale seiner Entwicklung zu charakterisieren und die ihn beeinflussenden Faktoren zu bestimmen. Die Berechnung statistischer Größen und die Analyse von Daten zu den untersuchten Phänomenen ist die dritte und letzte Stufe der statistischen Forschung. In der Statistik werden verschiedene Arten von statistischen Größen betrachtet: absolute, relative und Durchschnittswerte. Verallgemeinernde statistische Indikatoren umfassen auch analytische Indikatoren von Zeitreihen, Indizes usw. 2. Absolute Statistik Die statistische Beobachtung liefert unabhängig von ihrem Umfang und ihren Zielen immer Informationen über bestimmte sozioökonomische Phänomene und Prozesse in Form von absoluten Indikatoren, dh Indikatoren, die ein quantitatives Merkmal sozioökonomischer Phänomene und Prozesse unter Bedingungen qualitativer Sicherheit sind. Die qualitative Sicherheit absoluter Indikatoren liegt in der Tatsache, dass sie direkt auf den spezifischen Inhalt des untersuchten Phänomens oder Prozesses, auf sein Wesen, bezogen sind. In dieser Hinsicht sollten absolute Indikatoren und absolute Werte bestimmte Maßeinheiten haben, die ihre Essenz (Inhalt) am vollständigsten und genauesten widerspiegeln. Absolute Indikatoren sind ein quantitativer Ausdruck von Anzeichen statistischer Phänomene. Zum Beispiel ist die Höhe ein Merkmal, und sein Wert ist ein Maß für das Wachstum. Ein absoluter Indikator muss die Größe des untersuchten Phänomens oder Prozesses an einem bestimmten Ort und zu einem bestimmten Zeitpunkt charakterisieren, er muss an ein Objekt oder Gebiet „gebunden“ sein und kann entweder eine separate Bevölkerungseinheit (einzelnes Objekt) charakterisieren – ein Unternehmen, ein Arbeitnehmer oder eine Gruppe von Einheiten, die einen Teil der statistischen Grundgesamtheit oder die statistische Grundgesamtheit als Ganzes (z. B. die Bevölkerung im Land) usw. darstellen. Im ersten Fall sprechen wir von individuellen Absolutwerten Indikatoren, und im zweiten geht es um aggregierte absolute Indikatoren. Individuelle Werte - absolute Werte, die die Größe einzelner Bevölkerungseinheiten charakterisieren (z. B. die Anzahl der von einem Arbeiter pro Schicht hergestellten Teile, die Anzahl der Kinder in einer separaten Familie). Sie werden direkt im Prozess der statistischen Beobachtung gewonnen und in den primären Buchhaltungsbelegen erfasst. Einzelne Indikatoren werden im Prozess der statistischen Beobachtung bestimmter Phänomene und Prozesse als Ergebnis der Bewertung, Berechnung und Messung eines festen quantitativen Merkmals von Interesse erhalten. zusammenfassende Werte - Absolutwerte erhält man in der Regel durch Summieren einzelner Einzelwerte. Zusammenfassende absolute Indikatoren werden durch Zusammenfassen und Gruppieren der Werte einzelner absoluter Indikatoren erhalten. So erhalten beispielsweise staatliche Statistikämter im Rahmen einer Volkszählung endgültige absolute Daten über die Bevölkerung des Landes, ihre Verteilung nach Regionen, nach Geschlecht, Alter usw. Absolute Indikatoren können auch Indikatoren umfassen, die nicht als Ergebnis einer statistischen Beobachtung, sondern als Ergebnis einer beliebigen Berechnung erhalten werden. Diese Indikatoren sind in der Regel Differenzcharakter und ergeben sich als Differenz zweier absoluter Indikatoren. Beispielsweise ergibt sich die natürliche Zunahme (Abnahme) der Bevölkerung als Differenz zwischen der Zahl der Geburten und der Zahl der Sterbefälle für einen bestimmten Zeitraum; Die Produktionssteigerung für das Jahr ergibt sich aus der Differenz zwischen dem Produktionsvolumen am Jahresende und dem Produktionsvolumen am Jahresanfang. Bei der Erstellung langfristiger Prognosen für die Entwicklung der Wirtschaft des Landes werden geschätzte Daten zu Material-, Arbeits- und Finanzressourcen berechnet. Wie aus den Beispielen ersichtlich ist, sind diese Indikatoren absolut, da sie absolute Maßeinheiten haben. Absolute Werte spiegeln die natürliche Grundlage von Phänomenen wider. Sie drücken entweder die Anzahl der Einheiten der untersuchten Population, ihre einzelnen Bestandteile oder ihre absolute Größe in natürlichen Einheiten aus, die sich aus ihren physikalischen Eigenschaften (wie Gewicht, Länge usw.) ergeben, oder in Maßeinheiten, die sich aus ihren wirtschaftlichen Eigenschaften ergeben (das sind die Kosten, Arbeitskosten). Daher haben absolute Werte immer eine gewisse Dimension. Außerdem werden absolute statistische Kennziffern immer als Zahlen bezeichnet, d.h. je nach Art der Prozesse und Phänomene, die sie beschreiben, werden sie in physikalischen, Kosten- und Arbeitsmaßeinheiten ausgedrückt. Natürliche Meter charakterisieren Phänomene in ihrer natürlichen Form und werden durch Länge, Gewicht, Volumen usw. oder die Anzahl der Einheiten, die Anzahl der Ereignisse ausgedrückt. Zu den natürlichen Einheiten gehören Maßeinheiten wie Tonnen, Kilogramm, Meter usw. In einigen Fällen werden kombinierte Maßeinheiten verwendet, die das Produkt zweier Größen sind, die in unterschiedlichen Dimensionen ausgedrückt werden. Beispielsweise wird die Stromproduktion in Kilowattstunden gemessen, der Güterumschlag in Tonnenkilometern usw. Zur Gruppe der natürlichen Maßeinheiten gehören auch die sogenannten bedingt natürlichen Maßeinheiten. Sie werden verwendet, um absolute Gesamtwerte zu erhalten, wenn Einzelwerte einzelne Produkttypen charakterisieren, die in ihren Verbrauchereigenschaften ähnlich sind, sich jedoch beispielsweise in Fettgehalt, Alkohol, Kaloriengehalt usw. unterscheiden In diesem Fall wird eine der Produktarten als bedingter natürlicher Meter genommen, und mit Hilfe von Umrechnungsfaktoren, die das Verhältnis der Verbrauchereigenschaften (manchmal Arbeitsintensität, Kosten usw.) der einzelnen Sorten ausdrücken, werden alle Sorten dieses Produkts angegeben. Arbeitsmaßeinheiten werden verwendet, um Indikatoren zu charakterisieren, die eine Schätzung der Arbeitskosten ermöglichen und die Verfügbarkeit, Verteilung und Verwendung von Arbeitsressourcen widerspiegeln (z. B. die Arbeitsintensität der geleisteten Arbeit in Manntagen). Natürliche und manchmal auch arbeitsbezogene Maßnahmen ermöglichen es nicht, unter Bedingungen heterogener Produkte konsolidierte absolute Indikatoren zu erhalten. In dieser Hinsicht sind Kostenmesseinheiten universell; sie geben eine monetäre (monetäre) Bewertung sozioökonomischer Phänomene und charakterisieren die Kosten eines bestimmten Produkts oder Arbeitsvolumens. Beispielsweise werden so wichtige Indikatoren für die Wirtschaft des Landes wie Nationaleinkommen, Bruttoinlandsprodukt in Geldform und auf Unternehmensebene Gewinn, Eigen- und Fremdmittel ausgedrückt. In der Statistik werden Kosteneinheiten am meisten bevorzugt, da die Kostenrechnung universell, aber nicht immer akzeptabel ist. Absolute Indikatoren können in Zeit und Raum berechnet werden. Zum Beispiel die Dynamik der Bevölkerung der Russischen Föderation von 1991 bis 2004 spiegelt sich im Zeitfaktor wider, und das Preisniveau für Backwaren in den Regionen der Russischen Föderation im Jahr 2004 ist durch einen räumlichen Vergleich gekennzeichnet. Bei Berücksichtigung absoluter Indikatoren im Zeitverlauf (in der Dynamik) kann deren Erfassung zu einem bestimmten Datum erfolgen, d.h. zu jedem Zeitpunkt (Kosten des Anlagevermögens des Unternehmens zu Beginn des Jahres) und für jeden Zeitraum der Zeit (die Anzahl der Geburten pro Jahr). Im ersten Fall sind die Indikatoren augenblicklich, im zweiten Intervall. Unter dem Gesichtspunkt der räumlichen Sicherheit werden absolute Indikatoren wie folgt unterteilt: allgemein territorial, regional und lokal. Beispielsweise ist das BIP-Volumen (Bruttoinlandsprodukt) ein allgemeiner territorialer Indikator, das BIP-Volumen (Bruttoregionalprodukt) ein regionaler Indikator und die Zahl der Beschäftigten in einer Stadt ein lokaler Indikator. Folglich charakterisiert die erste Gruppe von Indikatoren das Land als Ganzes, regional – eine bestimmte Region, lokal – eine einzelne Stadt, Ortschaft usw. Absolute Indikatoren beantworten nicht die Frage, welchen Anteil dieser oder jener Teil an der Gesamtbevölkerung hat, sie können die Ebenen der geplanten Aufgabe, den Erfüllungsgrad des Plans, die Intensität eines bestimmten Phänomens nicht charakterisieren, da sie es nicht immer sind zum Vergleich geeignet und werden daher oft nur zur Berechnung relativer Werte verwendet. 3. Relative Statistiken Eine der wichtigsten Formen der Verallgemeinerung von Kennzahlen in der Statistik sind neben den absoluten Werten die relativen Werte. Im modernen Leben sind wir oft mit der Notwendigkeit konfrontiert, Fakten zu vergleichen und gegenüberzustellen. Nicht nur, weil es ein Sprichwort gibt: „Im Vergleich erkennt man alles.“ Die Ergebnisse aller Vergleiche werden durch relative Werte ausgedrückt. Relative Werte sind verallgemeinernde Indikatoren, die das Maß quantitativer Verhältnisse ausdrücken, die bestimmten Phänomenen oder statistischen Objekten innewohnen. Bei der Berechnung eines relativen Werts wird das Verhältnis zweier miteinander zusammenhängender Werte (meist absolut) genommen, d. h. ihr Verhältnis gemessen, was in der statistischen Analyse sehr wichtig ist. Relativwerte sind in der statistischen Forschung weit verbreitet, da sie einen Vergleich verschiedener Indikatoren ermöglichen und einen solchen Vergleich anschaulich machen. Relative Größen werden als Verhältnis zweier Zahlen berechnet. In diesem Fall wird der Zähler als verglichener Wert und der Nenner als Basis des relativen Vergleichs bezeichnet. Abhängig von der Art des untersuchten Phänomens und den Zielen der Untersuchung kann die Grundgröße unterschiedliche Werte annehmen, was zu unterschiedlichen Ausdrucksformen relativer Größen führt. Relative Größen können gemessen werden: 1) in Koeffizienten; Wenn die Vergleichsbasis 1 ist, wird der relative Wert als ganze oder gebrochene Zahl ausgedrückt, die zeigt, wie oft ein Wert größer ist als der andere oder welcher Teil davon ist. 2) in Prozent, wenn die Vergleichsbasis 100 ist; 3) in ppm, wenn die Vergleichsbasis mit 1000 angenommen wird; 4) in Dezimillen, wenn die Vergleichsbasis 10 ist; 5) in benannten Zahlen (km, kg, ha) usw. In jedem konkreten Fall wird die Wahl der einen oder anderen Form des relativen Werts durch die Ziele der Studie und die sozioökonomische Essenz bestimmt, deren Maß der gewünschte relative Indikator ist. Relative Werte werden nach ihrem Inhalt in folgende Arten unterteilt: Erfüllung vertraglicher Verpflichtungen; Dynamik; Strukturen; Koordinierung; Intensität; Vergleiche. Der relative Wert der vertraglichen Verpflichtungen ist das Verhältnis der tatsächlichen Vertragserfüllung zur vertraglich festgelegten Höhe: Dieser Wert spiegelt den Umfang wider, in dem das Unternehmen seine vertraglichen Verpflichtungen erfüllt hat, und kann als Zahl (ganze oder gebrochene Zahl) oder als Prozentsatz ausgedrückt werden. Gleichzeitig ist es erforderlich, dass Zähler und Nenner des Anfangsverhältnisses derselben vertraglichen Verpflichtung entsprechen. Relativwerte der Dynamik - Wachstumsraten - sind Indikatoren, die Veränderungen im Ausmaß sozialer Phänomene im Laufe der Zeit charakterisieren. Die relative Größe der Dynamik zeigt die Veränderung ähnlicher Phänomene über einen bestimmten Zeitraum. Dieser Wert wird berechnet, indem jeder nachfolgende Zeitraum mit dem ersten oder vorherigen verglichen wird. Im ersten Fall erhalten wir grundlegende Dynamikwerte und im zweiten Fall erhalten wir Kettendynamikwerte. Beide Größen werden entweder als Koeffizienten oder als Prozentsätze ausgedrückt. Der Wahl einer Vergleichsbasis bei der Berechnung der relativen Werte der Dynamik sowie anderer relativer Indikatoren sollte besondere Aufmerksamkeit gewidmet werden, da der praktische Wert des erzielten Ergebnisses maßgeblich davon abhängt. Die relativen Werte der Struktur charakterisieren die Bestandteile der untersuchten Population. Der relative Wert der Bevölkerung wird nach folgender Formel berechnet:  Relative Werte der Struktur, üblicherweise spezifische Gewichte genannt, werden berechnet, indem ein bestimmter Teil des Ganzen durch die Gesamtmenge dividiert wird, die als 100 % angenommen wird. Dieser Wert hat ein Merkmal: Die Summe der relativen Werte der untersuchten Bevölkerung ist immer gleich 100 % oder 1 (je nachdem, wie sie ausgedrückt wird). Relative Strukturwerte werden bei der Untersuchung komplexer Phänomene verwendet, die in mehrere Gruppen oder Teile eingeteilt werden, um das spezifische Gewicht (den Anteil) jeder Gruppe an der Gesamtsumme zu charakterisieren. Relative Koordinationswerte charakterisieren das Verhältnis einzelner Bevölkerungsteile zu einem von ihnen, das dem Vergleich zugrunde gelegt wird. Bei der Ermittlung dieses Wertes wird einer der Teile des Ganzen als Vergleichsbasis genommen. Mit diesem Wert können Sie die Anteile zwischen den Komponenten der Grundgesamtheit beobachten. Indikatoren für die Koordinierung sind beispielsweise die Zahl der Stadtbewohner pro 100 Landbewohner; die Anzahl der Frauen pro 100 Männer; Da Zähler und Nenner der relativen Zuordnungswerte die gleiche Maßeinheit haben, werden diese Werte nicht in benannten Zahlen, sondern in Prozenten, ppm oder Vielfachverhältnissen ausgedrückt. Relative Intensitätswerte sind Indikatoren, die die Prävalenz eines bestimmten Phänomens in jeder Umgebung bestimmen. Sie werden als Verhältnis des absoluten Wertes eines bestimmten Phänomens zur Größe der Umgebung, in der es sich entwickelt, berechnet. Relative Intensitätswerte sind in der Praxis der Statistik weit verbreitet. Beispiele für diesen Wert können das Verhältnis der Bevölkerung zur Wohnfläche, die Kapitalproduktivität, die Versorgung der Bevölkerung mit medizinischer Versorgung (Anzahl der Ärzte pro 10 Einwohner), die Höhe der Arbeitsproduktivität (Output pro Arbeiter bzw pro Arbeitszeiteinheit) usw. . So charakterisieren die relativen Intensitätswerte die Effizienz der Nutzung verschiedener Arten von Ressourcen (materiell, finanziell, Arbeit), den sozialen und kulturellen Lebensstandard der Bevölkerung des Landes und viele andere Aspekte des öffentlichen Lebens. Relative Intensitätswerte werden durch den Vergleich entgegengesetzter absoluter Werte berechnet, die in einem bestimmten Verhältnis zueinander stehen, und im Gegensatz zu anderen Arten von relativen Werten werden sie normalerweise als Zahlen bezeichnet und haben die Dimension jener absoluten Werte, zu deren Verhältnis sie stehen ausdrücken. Dennoch werden in einigen Fällen, wenn die erhaltenen Berechnungsergebnisse zu klein sind, sie der Übersichtlichkeit halber mit 1000 oder 10 multipliziert, wodurch Kennwerte in ppm und Dezimille erhalten werden. Von besonderem Interesse ist eine Vielzahl relativer Intensitätswerte – Bruttoinlandsprodukt pro Kopf. Erweitert man diesen Indikator im Kontext von Branchen oder bestimmten Produkttypen, erhält man die folgenden relativen Intensitätswerte: Produktion von Strom, Treibstoff, Maschinen, Ausrüstung, Dienstleistungen, Waren und anderem pro Kopf. Relative Vergleichswerte sind relative Kennziffern, die sich aus einem Vergleich gleicher Niveaus bezogen auf unterschiedliche Objekte oder Territorien im gleichen Zeitraum oder zu einem bestimmten Zeitpunkt ergeben. Sie werden ebenfalls in Koeffizienten oder Prozentzahlen berechnet und zeigen an, wie oft ein vergleichbarer Wert größer oder kleiner als ein anderer ist. Relative Vergleichswerte werden häufig bei der vergleichenden Bewertung verschiedener Leistungsindikatoren einzelner Unternehmen, Städte, Regionen, Länder verwendet. Dabei werden beispielsweise die Ergebnisse eines bestimmten Unternehmens als Vergleichsgrundlage herangezogen und konsequent mit den Ergebnissen ähnlicher Unternehmen in anderen Branchen, Regionen, Ländern etc. korreliert. Bei der statistischen Untersuchung sozialer Phänomene ergänzen sich absolute und relative Werte. Wenn absolute Werte sozusagen die Statik von Phänomenen charakterisieren, dann ermöglichen relative Werte, Grad, Dynamik und Intensität der Entwicklung von Phänomenen zu untersuchen. Für die korrekte Anwendung und Verwendung absoluter und relativer Werte in der wirtschaftlichen und statistischen Analyse ist Folgendes erforderlich: 1) Berücksichtigen Sie die Besonderheiten von Phänomenen bei der Auswahl und Berechnung der einen oder anderen Art von absoluten und relativen Werten (da die quantitative Seite der durch diese Größen gekennzeichneten Phänomene untrennbar mit ihrer qualitativen Seite verbunden ist); 2) um die Vergleichbarkeit des verglichenen und des grundlegenden absoluten Werts in Bezug auf das Volumen und die Zusammensetzung der Phänomene, die sie darstellen, die Richtigkeit der Methoden zum Erhalten der absoluten Werte selbst sicherzustellen; 3) Relative und absolute Werte im Analyseprozess umfassend verwenden und nicht voneinander trennen (da die Verwendung von relativen Werten allein isoliert von absoluten zu ungenauen und sogar fehlerhaften Schlussfolgerungen führen kann). VORTRAG №5. Mittelwerte und Variationsindikatoren 1. Durchschnittswerte und allgemeine Grundsätze für ihre Berechnung Durchschnittswerte beziehen sich auf verallgemeinernde statistische Indikatoren, die ein zusammenfassendes (endgültiges) Merkmal sozialer Massenphänomene geben, da sie auf der Grundlage einer großen Anzahl individueller Werte eines variierenden Attributs aufgebaut sind. Um das Wesen des Durchschnittswerts zu verdeutlichen, müssen die Merkmale der Bildung der Werte der Zeichen dieser Phänomene berücksichtigt werden, nach denen der Durchschnittswert berechnet wird. Es ist bekannt, dass die Einheiten jedes Massenphänomens zahlreiche Merkmale aufweisen. Welches dieser Zeichen auch genommen wird, seine Werte für einzelne Einheiten werden unterschiedlich sein, sie ändern sich oder, wie man in der Statistik sagt, variieren von einer Einheit zur anderen. So wird beispielsweise das Gehalt eines Arbeitnehmers durch seine Qualifikation, die Art der Tätigkeit, die Dauer der Betriebszugehörigkeit und eine Reihe weiterer Faktoren bestimmt und variiert daher sehr stark. Der kumulierte Einfluss aller Faktoren bestimmt die Höhe des Verdienstes jedes Mitarbeiters. Dennoch können wir über die durchschnittlichen Monatslöhne der Arbeitnehmer in verschiedenen Wirtschaftssektoren sprechen. Hier operieren wir mit einem typischen, charakteristischen Wert eines variablen Attributs, bezogen auf eine Einheit einer großen Population. Der Durchschnittswert spiegelt das Allgemeine wider, das für alle Einheiten der untersuchten Bevölkerung charakteristisch ist. Gleichzeitig gleicht es den Einfluss aller Faktoren aus, die auf die Größe des Attributs einzelner Bevölkerungseinheiten einwirken, als ob sie sich gegenseitig aufheben würden. Das Niveau (oder die Größe) jedes sozialen Phänomens wird durch die Wirkung von zwei Gruppen von Faktoren bestimmt. Einige von ihnen sind allgemein und hauptsächlich, ständig in Betrieb, eng mit der Art des untersuchten Phänomens oder Prozesses verbunden und bilden das, was für alle Einheiten der untersuchten Bevölkerung typisch ist und sich im Durchschnittswert widerspiegelt. Andere sind individuell, ihre Wirkung ist weniger ausgeprägt und episodisch, zufällig. Sie wirken in die entgegengesetzte Richtung, verursachen Unterschiede zwischen den quantitativen Merkmalen einzelner Bevölkerungseinheiten und versuchen, den konstanten Wert der untersuchten Merkmale zu ändern. Die Wirkung einzelner Zeichen wird im Mittelwert ausgelöscht. Im kumulativen Einfluss typischer und individueller Faktoren, die sich in verallgemeinernden Merkmalen ausgleichen und gegenseitig aufheben, manifestiert sich das aus der mathematischen Statistik bekannte Grundgesetz der großen Zahl in allgemeiner Form. Im Aggregat verschmelzen die Einzelwerte der Zeichen zu einer gemeinsamen Masse und lösen sich gleichsam auf. Der Durchschnitt fungiert somit als „unpersönlicher“ Wert, der von den einzelnen Merkmalswerten abweichen kann und mit keinem von ihnen quantitativ übereinstimmt. Somit spiegelt der Durchschnitt das Allgemeine, Charakteristische und Typische der gesamten Bevölkerung wider, da zufällige, atypische Unterschiede zwischen den Vorzeichen ihrer einzelnen Einheiten in ihr gegenseitig aufgehoben werden, da ihr Wert sozusagen durch die gemeinsame Resultierende von bestimmt wird alle Ursachen. Damit der Durchschnitt jedoch den typischsten Wert eines Merkmals widerspiegelt, sollte er nicht für beliebige Grundgesamtheiten bestimmt werden, sondern nur für Grundgesamtheiten, die aus qualitativ homogenen Einheiten bestehen. Diese Anforderung ist die Hauptvoraussetzung für die wissenschaftlich fundierte Anwendung von Durchschnittswerten und impliziert eine enge Beziehung zwischen der Durchschnittsmethode und der Gruppierungsmethode bei der Analyse sozioökonomischer Phänomene. Folglich wird die Durchschnittswert - Dies ist ein allgemeiner Indikator, der das typische Niveau eines variablen Merkmals pro Einheit einer homogenen Population unter bestimmten räumlichen und zeitlichen Bedingungen charakterisiert. Bei dieser Definition des Wesens von Durchschnittswerten muss betont werden, dass die korrekte Berechnung eines Durchschnitts die Erfüllung der folgenden Anforderungen impliziert: 1) qualitative Homogenität der Bevölkerung, für die der Durchschnitt berechnet wird. Die Berechnung des Durchschnitts für Phänomene unterschiedlicher Qualität (verschiedener Typen) widerspricht dem Wesen des Durchschnitts, da die Entwicklung solcher Phänomene anderen als allgemeinen Gesetzen und Ursachen unterliegt. Dies bedeutet, dass die Berechnung von Durchschnittswerten auf der Gruppierungsmethode basieren sollte, die die Auswahl homogener, gleichartiger Phänomene gewährleistet; 2) Ausschluss des Einflusses zufälliger, rein individueller Ursachen und Faktoren auf die Berechnung des Mittelwertes. Dies ist in dem Fall erreicht, wenn der Berechnung des Durchschnitts ein ausreichend massives Material zugrunde liegt, in dem sich die Wirkung des Gesetzes der großen Zahl manifestiert und sich alle Unfälle gegenseitig aufheben; 3) Bei der Berechnung des Durchschnittswerts ist es wichtig, den Zweck seiner Berechnung und den sogenannten Definitionsindikator (Eigenschaft) festzulegen, an dem er sich orientieren sollte. Der bestimmende Indikator kann als Summe der Werte des gemittelten Merkmals, als Summe seiner Kehrwerte, als Produkt seiner Werte usw. fungieren. Die Beziehung zwischen dem definierenden Indikator und dem Durchschnitt wird wie folgt ausgedrückt: wenn alle Werte des gemittelten Merkmals durch ihren Mittelwert ersetzt werden, dann wird der Summen- oder Produktfall, der definierende Indikator, nicht geändert. Anhand dieser Verknüpfung des bestimmenden Indikators mit dem Mittelwert wird ein erstes quantitatives Verhältnis zur direkten Berechnung des Mittelwerts gebildet. Die Fähigkeit von Durchschnitten, die Eigenschaften statistischer Grundgesamtheiten beizubehalten, wird als definierende Eigenschaft bezeichnet. Der für die Gesamtbevölkerung berechnete Durchschnitt wird als allgemeiner Durchschnitt bezeichnet, die für jede Gruppe berechneten Durchschnitte werden als Gruppendurchschnitte bezeichnet. Der allgemeine Durchschnitt spiegelt die allgemeinen Merkmale des untersuchten Phänomens wider, der Gruppendurchschnitt gibt ein Merkmal der Größe des Phänomens wieder, das sich unter den spezifischen Bedingungen dieser Gruppe entwickelt. Die Berechnungsmethoden können unterschiedlich sein, und in diesem Zusammenhang werden in der Statistik mehrere Arten von Durchschnitten unterschieden, von denen die wichtigsten der arithmetische Durchschnitt, der harmonische Durchschnitt und der geometrische Durchschnitt sind. In der Wirtschaftsanalyse ist die Verwendung von Durchschnittswerten ein wirksames Instrument, um die Ergebnisse des wissenschaftlichen und technischen Fortschritts, soziale Maßnahmen zu bewerten und verborgene und ungenutzte Reserven für die wirtschaftliche Entwicklung zu finden. Gleichzeitig sollte daran erinnert werden, dass eine übermäßige Fokussierung auf Durchschnittswerte zu voreingenommenen Schlussfolgerungen bei der Durchführung wirtschaftlicher und statistischer Analysen führen kann. Dies liegt daran, dass Durchschnittswerte als verallgemeinernde Kennziffern tatsächlich vorhandene Unterschiede in den quantitativen Merkmalen einzelner Bevölkerungseinheiten aufheben und von eigenständigem Interesse sein können. 2. Arten von Durchschnittswerten In der Statistik werden verschiedene Arten von Durchschnittswerten verwendet, die in zwei große Klassen unterteilt werden: 1) Leistungsmittelwerte (harmonisches Mittel, geometrisches Mittel, arithmetisches Mittel, quadratisches Mittel, kubisches Mittel); 2) strukturelle Durchschnitte (Modus, Median). Um die Leistungsmittel zu berechnen, müssen alle verfügbaren Werte des Attributs verwendet werden. Modus und Median werden nur durch die Struktur der Verteilung bestimmt. Daher werden sie als strukturelle Positionsmittelwerte bezeichnet. Der Median und der Modus werden häufig als durchschnittliches Merkmal in Populationen verwendet, in denen die Berechnung des mittleren Exponentials unmöglich oder unpraktisch ist. Die gebräuchlichste Art des Durchschnitts ist das arithmetische Mittel. Das arithmetische Mittel ist der Wert eines Merkmals, den jede Einheit der Grundgesamtheit hätte, wenn die Gesamtsumme aller Werte des Merkmals gleichmäßig auf alle Einheiten der Grundgesamtheit verteilt wäre. Im Allgemeinen besteht die Berechnung darin, alle Werte des variierenden Merkmals zu summieren und den resultierenden Betrag durch die Gesamtzahl der Einheiten in der Grundgesamtheit zu dividieren. Zum Beispiel erfüllten fünf Arbeiter einen Auftrag zur Herstellung von Teilen, während der erste 5 Teile produzierte, der zweite - 7, der dritte - 4, der vierte - 10, der fünfte - 12. Da in den Quelldaten der Wert von jedem Wenn diese Option nur einmal vorkam, sollten Sie zur Ermittlung der durchschnittlichen Leistung eines Arbeiters die einfache arithmetische Durchschnittsformel anwenden:  also in unserem Beispiel die durchschnittliche Leistung eines Arbeiters  Neben dem einfachen arithmetischen Mittel wird das gewichtete arithmetische Mittel untersucht. Lassen Sie uns beispielsweise das Durchschnittsalter der Schüler in einer Gruppe von 20 Schülern berechnen, deren Alter zwischen 18 und 22 liegt, wobei xi - Varianten des gemittelten Merkmals, f - Frequenz, die zeigt, wie oft der i-te Wert in der Population vorkommt. Durch Anwendung der gewichteten arithmetischen Mittelformel erhalten wir: 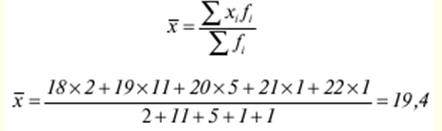 Es gibt eine bestimmte Regel für die Auswahl eines gewichteten arithmetischen Mittels: Wenn es eine Reihe von Daten zu zwei miteinander verbundenen Indikatoren gibt, von denen einer den Durchschnittswert berechnen muss, und gleichzeitig die numerischen Werte der Nenner seiner logischen Formel bekannt sind und die Werte des Zählers nicht bekannt sind, aber als Produkt dieser Indikatoren gefunden werden können, dann sollte der Durchschnittswert nach der Formel des arithmetisch gewichteten Durchschnitts berechnet werden. In einigen Fällen ist die Beschaffenheit der anfänglichen statistischen Daten so, dass die Berechnung des arithmetischen Mittels ihre Bedeutung verliert und der einzige verallgemeinernde Indikator nur eine andere Art von Mittelwert sein kann – das harmonische Mittel. Derzeit haben die rechnerischen Eigenschaften des arithmetischen Mittels aufgrund der weit verbreiteten Einführung elektronischer Rechentechnik ihre Relevanz für die Berechnung allgemeiner statistischer Indikatoren verloren. Große praktische Bedeutung hat der harmonische Mittelwert erlangt, der auch einfach und gewichtet sein kann. Wenn die Zahlenwerte des Zählers einer logischen Formel bekannt sind, die Werte des Nenners jedoch nicht, wird der Durchschnittswert mithilfe der harmonisch gewichteten Durchschnittsformel berechnet. Wenn bei Verwendung der durchschnittlichen harmonischen Gewichtung aller Optionen (f;) gleich sind, dann können Sie anstelle des gewichteten ein einfaches (ungewichtetes) harmonisches Mittel verwenden:  wo x - individuelle Optionen; n ist die Anzahl der Varianten des gemittelten Merkmals. Beispielsweise kann ein einfacher harmonischer Mittelwert auf die Geschwindigkeit angewendet werden, wenn die Segmente des mit unterschiedlichen Geschwindigkeiten zurückgelegten Weges gleich sind. Jeder Durchschnittswert sollte so berechnet werden, dass sich der Wert eines endgültigen, verallgemeinernden Indikators, der dem gemittelten Indikator zugeordnet ist, nicht ändert, wenn er jede Variante des gemittelten Merkmals ersetzt. Wenn Sie also die tatsächlichen Geschwindigkeiten auf einzelnen Streckenabschnitten durch ihren Durchschnittswert ersetzen, sollte die Durchschnittsgeschwindigkeit) die Gesamtstrecke nicht ändern. Die Durchschnittsformel wird durch die Art (Mechanismus) der Beziehung dieses letzten Indikators zum Durchschnitt bestimmt. Daher wird der letzte Indikator, dessen Wert sich nicht ändern sollte, wenn die Optionen durch ihren Durchschnittswert ersetzt werden, als definierender Indikator bezeichnet. Um die Durchschnittsformel abzuleiten, müssen Sie eine Gleichung aufstellen und lösen, indem Sie die Beziehung des gemittelten Indikators zum bestimmenden verwenden. Diese Gleichung wird konstruiert, indem die Varianten des gemittelten Merkmals (Indikator) durch ihren Durchschnittswert ersetzt werden. Neben dem arithmetischen Mittelwert und dem harmonischen Mittelwert werden in der Statistik auch andere Arten (Formen) des Mittelwerts verwendet. Alle sind Sonderfälle des Potenzmittelwerts. Wenn wir alle Arten von Potenzgesetz-Mittelwerten für dieselben Daten berechnen, werden sich ihre Werte als gleich herausstellen, hier gilt die Regel der Majoranz von Durchschnitten. Wenn der Exponent des Mittelwerts zunimmt, steigt auch der Mittelwert selbst. Das geometrische Mittel wird bei n Wachstumsfaktoren verwendet, während die einzelnen Werte des Attributs in der Regel relative Werte der Dynamik, aufgebaut in Form von Kettenwerten, im Verhältnis zum vorherigen Niveau sind jeder Ebene in der Dynamik-Reihe. Der Durchschnitt charakterisiert somit die durchschnittliche Wachstumsrate. Der geometrische einfache Mittelwert wird nach folgender Formel berechnet:  Die Formel für den geometrisch gewichteten Durchschnitt lautet wie folgt:  Die obigen Formeln sind identisch, aber eine wird auf aktuelle Koeffizienten oder Wachstumsraten und die zweite auf die absoluten Werte der Ebenen der Reihe angewendet. Der quadratische Mittelwert wird beim Rechnen mit den Werten von Quadratfunktionen verwendet, er dient zur Messung des Schwankungsgrades der Einzelwerte eines Merkmals um das arithmetische Mittel in der Verteilungsreihe und wird nach der Formel berechnet: 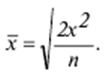 Der gewichtete quadratische Mittelwert wird mit einer anderen Formel berechnet:  Der durchschnittliche Kubikwert wird bei der Berechnung mit den Werten kubischer Funktionen verwendet und nach folgender Formel berechnet:  und der kubisch gewichtete Durchschnitt: 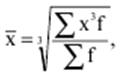 Alle oben genannten Durchschnittswerte können als allgemeine Formel dargestellt werden: 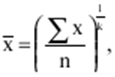 wobei x der Durchschnittswert ist; x - individueller Wert; n ist die Anzahl der Einheiten der untersuchten Grundgesamtheit; k - Exponent, der die Art des Durchschnitts bestimmt. Bei gleichen Anfangsdaten gilt: je mehr k in der allgemeinen Potenzmittelformel, desto größer der Mittelwert. Daraus folgt, dass zwischen den Werten der Machtmittel ein regelmäßiger Zusammenhang besteht:  Die oben beschriebenen Durchschnittswerte geben einen allgemeinen Überblick über die untersuchte Bevölkerung und unter diesem Gesichtspunkt ist ihre theoretische, angewandte und pädagogische Bedeutung unbestreitbar. Es kommt jedoch vor, dass der Durchschnittswert mit keiner der tatsächlich vorhandenen Optionen übereinstimmt. Daher ist es in der statistischen Analyse ratsam, zusätzlich zu den betrachteten Durchschnittswerten die Werte bestimmter Optionen zu verwenden, die eine ganz bestimmte Position in der geordneten (Rangfolge-)Reihe von Attributwerten einnehmen. Unter diesen Größen werden am häufigsten strukturelle (oder beschreibende) Durchschnittswerte verwendet – Modus (Mo) und Median (Me). Mode - der Wert des Merkmals, das in dieser Population am häufigsten vorkommt. Bei den Variationsreihen ist der Modus der am häufigsten vorkommende Wert der Rangreihe, also die Variante mit der höchsten Häufigkeit. Mode kann verwendet werden, um die meistbesuchten Geschäfte und den gängigsten Preis für jedes Produkt zu ermitteln. Es zeigt die Größe des Merkmals, das für einen erheblichen Teil der Bevölkerung charakteristisch ist, und wird durch die Formel bestimmt: 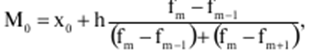 wo x0 - die untere Grenze des Intervalls; h ist der Wert des Intervalls; fm- Intervallfrequenz; fm1- Häufigkeit des vorherigen Intervalls; fm+1- Häufigkeit des nächsten Intervalls. Median Die Option in der Mitte der Rangfolge wird aufgerufen. Der Median teilt die Reihe so in zwei gleiche Teile, dass sich auf beiden Seiten gleich viele Bevölkerungseinheiten befinden. In diesem Fall hat eine Hälfte der Einheiten in der Grundgesamtheit einen Wert des variierenden Merkmals, der kleiner als der Median ist, und die andere Hälfte hat einen Wert, der größer als dieser ist. Der Median wird verwendet, wenn ein Element untersucht wird, dessen Wert größer oder gleich oder gleichzeitig kleiner oder gleich der Hälfte der Elemente einer Verteilungsreihe ist. Der Median gibt eine allgemeine Vorstellung davon, wo die Attributwerte konzentriert sind, mit anderen Worten, wo ihr Mittelpunkt liegt. Der beschreibende Charakter des Medians zeigt sich darin, dass er die quantitative Grenze der Werte des variierenden Attributs charakterisiert, die die Hälfte der Bevölkerungseinheiten besitzt. Das Problem, den Median für eine diskrete Variationsreihe zu finden, wird einfach gelöst. Wenn alle Einheiten der Serie Seriennummern erhalten, dann ist die Seriennummer der mittleren Variante definiert als (n + 1) / 2 bei einer ungeraden Mitgliederzahl n. Wenn die Anzahl der Mitglieder der Serie eine gerade Zahl ist, dann ist der Median der Mittelwert zweier Varianten mit den Seriennummern n / 2 und n/2 + 1. Bei der Bestimmung des Medians in Intervallvariationsreihen wird zunächst das Intervall bestimmt, in dem er liegt (das Medianintervall). Dieses Intervall ist dadurch gekennzeichnet, dass seine kumulierte Summe von Häufigkeiten gleich oder größer als die Hälfte der Summe aller Häufigkeiten der Reihe ist. Die Berechnung des Medians der Intervallvariationsreihe erfolgt nach der Formel:  wo x0 - die untere Grenze des Intervalls; h ist der Wert des Intervalls; fm- Intervallfrequenz; f ist die Anzahl der Mitglieder der Reihe; ∫ m -1 - die Summe der akkumulierten Mitglieder der Reihe, die dieser vorausgeht. Um die Struktur der untersuchten Bevölkerung besser zu charakterisieren, werden neben dem Median auch andere Werte von Optionen verwendet, die eine ganz bestimmte Position in der Rangfolge einnehmen. Dazu gehören Quartile und Dezile. Quartile teilen die Reihe durch die Summe der Häufigkeiten in vier gleiche Teile und Dezile in zehn gleiche Teile. Es gibt drei Quartile und neun Dezile. Median und Modus löschen im Gegensatz zum arithmetischen Mittel individuelle Unterschiede in den Werten eines variablen Attributs nicht aus und sind daher zusätzliche und sehr wichtige Merkmale der statistischen Grundgesamtheit. In der Praxis werden sie oft anstelle des Durchschnitts oder zusammen mit ihm verwendet. Es ist besonders zweckmäßig, den Median und den Modus in den Fällen zu berechnen, in denen die untersuchte Grundgesamtheit eine bestimmte Anzahl von Einheiten mit einem sehr großen oder sehr kleinen Wert des variablen Attributs enthält. Diese Werte von Optionen, die für die Bevölkerung nicht sehr charakteristisch sind, beeinflussen zwar den Wert des arithmetischen Mittels, wirken sich jedoch nicht auf die Werte des Medians und des Modus aus, was letztere zu sehr wertvollen Indikatoren für die wirtschaftliche und statistische Analyse macht . 3. Variationsindikatoren Der Zweck der statistischen Forschung besteht darin, die grundlegenden Eigenschaften und Muster der untersuchten statistischen Grundgesamtheit zu identifizieren. Bei der zusammenfassenden Verarbeitung statistischer Beobachtungsdaten werden Verteilungsreihen erstellt. Es gibt zwei Arten von Verteilungsreihen – attributive und Variationsreihen – je nachdem, ob das der Gruppierung zugrunde liegende Merkmal qualitativ oder quantitativ ist. Variationsverteilungsreihen werden genannt, die auf quantitativer Basis aufgebaut sind. Die Werte quantitativer Merkmale in einzelnen Bevölkerungseinheiten sind nicht konstant, sondern unterscheiden sich mehr oder weniger voneinander. Dieser Unterschied in der Größe eines Merkmals wird Variation genannt. Separate numerische Werte eines Merkmals, die in der untersuchten Population vorkommen, werden als Wertvarianten bezeichnet. Das Vorhandensein von Variationen in einzelnen Einheiten der Population ist auf den Einfluss einer großen Anzahl von Faktoren auf die Bildung des Merkmalsniveaus zurückzuführen. Die Untersuchung der Art und des Variationsgrades der Zeichen in einzelnen Einheiten der Bevölkerung ist die wichtigste Frage jeder statistischen Studie. Variationsindikatoren werden verwendet, um das Maß der Merkmalsvariabilität zu beschreiben. Eine weitere wichtige Aufgabe der statistischen Forschung besteht darin, die Rolle einzelner Faktoren oder ihrer Gruppen bei der Variation bestimmter Merkmale der Bevölkerung zu bestimmen. Um ein solches Problem in der Statistik zu lösen, werden spezielle Methoden zur Untersuchung der Variation verwendet, die auf der Verwendung eines Systems von Indikatoren basieren, die die Variation messen. In der Praxis wird der Forscher mit einer ausreichend großen Anzahl von Optionen für die Werte des Attributs konfrontiert, die keine Vorstellung von der Verteilung der Einheiten nach dem Wert des Attributs im Aggregat geben. Dazu werden alle Varianten der Attributwerte in aufsteigender oder absteigender Reihenfolge angeordnet. Dieser Vorgang wird als Reihenranking bezeichnet. Die Rangfolge gibt sofort einen Überblick über die Werte, die das Feature in der Summe einnimmt. Die Unzulänglichkeit des Durchschnittswerts für eine erschöpfende Charakterisierung der Population macht es erforderlich, die Durchschnittswerte durch Indikatoren zu ergänzen, die es ermöglichen, die Typizität dieser Durchschnittswerte zu beurteilen, indem die Fluktuation (Variation) des untersuchten Merkmals gemessen wird. Die Verwendung dieser Variationsindikatoren ermöglicht es, die statistische Analyse vollständiger und aussagekräftiger zu machen und somit das Wesen der untersuchten sozialen Phänomene besser zu verstehen. Die einfachsten Variationszeichen sind Minimum und Maximum – dies ist der kleinste und größte Wert des Merkmals im Aggregat. Die Anzahl der Wiederholungen einzelner Varianten von Merkmalswerten wird als Wiederholungshäufigkeit bezeichnet. Häufigkeit - ein relativer Häufigkeitsindikator, der in Bruchteilen einer Einheit oder einem Prozentsatz ausgedrückt werden kann, ermöglicht es Ihnen, Variationsreihen mit einer unterschiedlichen Anzahl von Beobachtungen zu vergleichen. Formal haben wir: 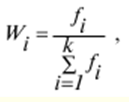 wo fi - Anzahl der Optionen. Um die Variation eines Merkmals zu messen, werden verschiedene absolute und relative Indikatoren verwendet. Zu den absoluten Variationsindikatoren gehören die mittlere lineare Abweichung, die Variationsbreite, die Varianz und die Standardabweichung. Die Variationsbreite (R) ist die Differenz zwischen den maximalen und minimalen Werten des Merkmals in der untersuchten Population, formal haben wir: R=Xmax-XMin. Dieser Indikator gibt nur die allgemeinste Vorstellung von der Schwankung des untersuchten Merkmals, da er nur den Unterschied zwischen den Grenzwerten der Varianten anzeigt. Es ist völlig unabhängig von den Häufigkeiten in der Variationsreihe, dh von der Art der Verteilung, und seine Abhängigkeit nur von den Extremwerten des Attributs kann ihm einen instabilen, zufälligen Charakter verleihen. Die Schwankungsbreite gibt keine Auskunft über die Merkmale der untersuchten Populationen und erlaubt keine Beurteilung des Typizitätsgrades der erhaltenen Mittelwerte. Der Anwendungsbereich dieses Indikators ist auf ziemlich homogene Aggregate beschränkt. Genauer gesagt charakterisiert der Indikator die Variation eines Merkmals, basierend auf der Berücksichtigung der Variabilität aller Werte des Merkmals. Um die Variation eines Merkmals zu charakterisieren, muss man in der Lage sein, die Abweichungen all dieser Werte von einem typischen Wert für die untersuchte Population zu verallgemeinern. Variationsindikatoren wie die mittlere lineare Abweichung, Varianz und Standardabweichung basieren auf der Berücksichtigung von Abweichungen der Werte des Attributs einzelner Bevölkerungseinheiten vom arithmetischen Mittel. Durchschnittliche lineare Abweichung ist das arithmetische Mittel der Absolutwerte der Abweichungen einzelner Optionen von ihrem arithmetischen Mittel:  wobei d die durchschnittliche lineare Abweichung ist; |x−x| - der Absolutwert (Modul) der Abweichung der Variante vom arithmetischen Mittel; f - Frequenz. Die erste Formel wird angewendet, wenn jede der Optionen insgesamt nur einmal vorkommt, und die zweite - in Reihe mit ungleichen Häufigkeiten. Es gibt eine andere Möglichkeit, die Abweichungen von Optionen vom arithmetischen Mittel zu mitteln. Bei dieser in der Statistik sehr verbreiteten Methode geht es darum, die quadrierten Abweichungen von Optionen vom Durchschnitt zu berechnen und diese dann zu mitteln. In diesem Fall erhalten wir einen neuen Variationsindikator – die Streuung. Varianz (σ2) - der Durchschnitt der quadrierten Abweichungen der Varianten der Merkmalswerte von ihrem Durchschnittswert: 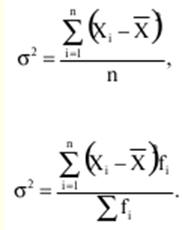 Die zweite Formel wird verwendet, wenn die Varianten eigene Gewichte (bzw. Häufigkeiten der Variantenreihe) haben. In der wirtschaftlichen und statistischen Analyse ist es üblich, die Variation eines Attributs am häufigsten anhand der Standardabweichung zu bewerten. Standardabweichung (σ) ist die Quadratwurzel der Varianz:  Die mittleren linearen und mittleren quadratischen Abweichungen zeigen, wie stark der Wert des Attributs im Durchschnitt für die Einheiten der untersuchten Grundgesamtheit schwankt, und werden in denselben Einheiten wie die Varianten ausgedrückt. In der statistischen Praxis wird es oft notwendig, die Streuung verschiedener Merkmale zu vergleichen. Beispielsweise ist es von großem Interesse, Altersunterschiede von Mitarbeitern und deren Qualifikation, Betriebszugehörigkeit und Entlohnung usw. zu vergleichen. Für solche Vergleiche sind natürlich Indikatoren für die absolute Variabilität von Merkmalen (durchschnittliche lineare und Standardabweichung) sind ungeeignet. Es ist in der Tat unmöglich, die in Jahren ausgedrückte Schwankung der Berufserfahrung mit der in Rubel und Kopeken ausgedrückten Lohnschwankung zu vergleichen. Beim Vergleich der Variabilität verschiedener Merkmale im Aggregat ist es zweckmäßig, relative Variationsindikatoren zu verwenden. Diese Indikatoren werden als Verhältnis der absoluten Indikatoren zum arithmetischen Mittel (oder Median) berechnet. Verwendet man als absolute Schwankungsbreite die Schwankungsbreite, die durchschnittliche lineare Abweichung, die Standardabweichung, erhält man die relativen Schwankungsgrößen:  Der Variationskoeffizient ist der am häufigsten verwendete Indikator für die relative Volatilität, der die Homogenität der Population charakterisiert. Der Satz gilt als homogen, wenn der Variationskoeffizient 33 % für Verteilungen nahe der Normalverteilung nicht überschreitet. VORTRAG №6. Selektive Beobachtung 1. Allgemeines Konzept der selektiven Beobachtung Die statistische Beobachtung kann als kontinuierlich und nicht kontinuierlich organisiert werden. Kontinuierlich beinhaltet die Untersuchung aller Einheiten der untersuchten Population des Phänomens, nichtkontinuierlich - nur seine Teile. Selektive Beobachtung gehört auch zu diskontinuierlich. Die Probenbeobachtung ist eine der am weitesten verbreiteten Arten der Teilbeobachtung. Diese Beobachtung basiert auf der Idee, dass ein bestimmter Teil der zufällig ausgewählten Einheiten die gesamte Population des untersuchten Phänomens entsprechend den für den Forscher interessanten Merkmalen repräsentieren kann. Der Zweck der Stichprobenbeobachtung besteht darin, Informationen zu erhalten, die in erster Linie dazu dienen, die zusammenfassenden allgemeinen Merkmale der gesamten untersuchten Population zu bestimmen. Die selektive Beobachtung fällt ihrem Zweck nach mit einer der Aufgaben der kontinuierlichen Beobachtung zusammen, und daher können wir darüber sprechen, welche der beiden Beobachtungsarten – kontinuierlich oder selektiv – besser durchzuführen ist. Bei der Lösung dieses Problems ist von folgenden Grundvoraussetzungen für die statistische Beobachtung auszugehen: 1) Informationen müssen zuverlässig sein, d. h. so weit wie möglich der Realität entsprechen; 2) die Informationen müssen vollständig genug sein, um die Forschungsprobleme zu lösen; 3) die Auswahl der Informationen sollte so schnell wie möglich erfolgen, um ihre Verwendung für betriebliche Zwecke sicherzustellen; 4) Geld- und Arbeitskosten für die Organisation und Durchführung sollten minimal sein. Bei einer punktuellen Beobachtung werden diese Anforderungen in höherem Maße erfüllt als bei einer kontinuierlichen Beobachtung. Die Vorteile der selektiven Beobachtung gegenüber der kontinuierlichen Beobachtung kommen voll zur Geltung, wenn sie streng nach den wissenschaftlichen Grundsätzen der Theorie der Probenahmeverfahren organisiert und durchgeführt wird. Ein solches Prinzip soll die Zufälligkeit der Auswahl der Einheiten und deren ausreichende Anzahl sicherstellen. Die Einhaltung des Prinzips ermöglicht es, eine solche Menge von Einheiten zu erhalten, die gemäß den für den Forscher interessanten Merkmalen die gesamte untersuchte Menge repräsentiert, d. h. repräsentativ (repräsentativ) ist. Bei einer Stichprobenbeobachtung werden nicht alle Einheiten des Untersuchungsobjekts untersucht, also nicht alle Einheiten der Gesamtbevölkerung, sondern nur ein bestimmter, speziell ausgewählter Teil davon. Das erste Prinzip der Auswahl – die Gewährleistung der Zufälligkeit – besteht darin, dass bei der Auswahl jeder der untersuchten Einheiten der Grundgesamtheit die gleichen Chancen auf Aufnahme in die Stichprobe gegeben sind. Zufällige Auswahl ist keine zufällige Auswahl. Eine zufällige Auswahl kann nur gewährleistet werden, wenn eine bestimmte Methodik befolgt wird (z. B. durch Auswahl von Losen, Verwendung von Zufallszahlentabellen usw.). Der zweite Auswahlgrundsatz – Sicherstellung einer ausreichenden Anzahl ausgewählter Einheiten – steht in engem Zusammenhang mit dem Konzept der Repräsentativität der Stichprobe. Der Begriff der Repräsentativität des ausgewählten Satzes von Einheiten sollte nicht als seine Repräsentativität in allen Belangen, d. h. in allen Belangen der untersuchten Grundgesamtheit, verstanden werden. Eine solche Darstellung ist kaum möglich. Jede Stichprobenbeobachtung wird mit einem bestimmten Zweck und klar formulierten spezifischen Aufgaben durchgeführt, und das Konzept der Repräsentativität sollte mit dem Zweck und den Zielen der Studie verbunden sein. Der aus der gesamten untersuchten Population ausgewählte Teil sollte in erster Linie in Bezug auf die untersuchten Merkmale repräsentativ sein oder einen signifikanten Einfluss auf die Bildung summarischer generalisierender Merkmale haben. Lassen Sie uns einige Konzepte vorstellen, die bei der selektiven Beobachtung verwendet werden. Durchschnittsbevölkerung wird der gesamte untersuchte Satz von Einheiten genannt, der gemäß den für den Forscher interessanten Merkmalen untersucht wird. Probenahme-Set ein Teil davon wird zufällig aus der allgemeinen Bevölkerung ausgewählt. Diese Stichprobe unterliegt dem Erfordernis der Repräsentativität, das heißt der Möglichkeit, durch die Untersuchung nur eines Teils der Allgemeinbevölkerung die Erkenntnisse auf die Gesamtbevölkerung auszudehnen. Die Merkmale der allgemeinen und Stichprobenpopulationen können die Durchschnittswerte der untersuchten Merkmale, ihre Varianzen und Standardabweichungen, Modus und Median usw. sein. Forscher könnten auch an der Verteilung der Einheiten gemäß den untersuchten Merkmalen in der Allgemein- und Stichprobenpopulation interessiert sein. In diesem Fall werden die Frequenzen allgemeine bzw. Abtastfrequenzen genannt. Das System der Auswahlregeln und Möglichkeiten zur Charakterisierung der untersuchten Bevölkerungseinheiten bildet den Inhalt des Stichprobenverfahrens. Das Wesentliche der Stichprobenmethode besteht darin, Primärdaten zu erhalten, die durch Beobachtung der Stichprobe durchgeführt werden, gefolgt von Verallgemeinerung, Analyse und Verteilung an die gesamte Bevölkerung, um zuverlässige Informationen über das untersuchte Phänomen zu erhalten. Die Repräsentativität der Stichprobe wird durch die Beachtung des Prinzips der zufälligen Auswahl von Objekten in der Grundgesamtheit der Stichprobe gewährleistet. Ist die Grundgesamtheit qualitativ homogen, so wird das Zufallsprinzip durch eine einfache Zufallsauswahl von Stichprobenobjekten umgesetzt. Die einfache Zufallsauswahl ist ein solches Stichprobenverfahren, das für jede Stichprobe einer bestimmten Größe die gleiche Wahrscheinlichkeit für jede zur Beobachtung auszuwählende Einheit der Grundgesamtheit bietet. Der Zweck des Stichprobenverfahrens besteht also darin, auf der Grundlage von Informationen einer Zufallsstichprobe aus dieser Bevölkerung einen Rückschluss auf den Wert der Merkmale der Allgemeinbevölkerung zu ziehen. 2. Stichprobenfehler Zwischen den Merkmalen der Stichprobenpopulation und den Merkmalen der Allgemeinbevölkerung besteht in der Regel eine gewisse Diskrepanz, die als statistischer Beobachtungsfehler bezeichnet wird. Bei der Massenbeobachtung sind Fehler unvermeidlich, aber sie entstehen aus verschiedenen Gründen. Der Wert eines möglichen Fehlers eines Stichprobenmerkmals setzt sich aus Registrierungsfehlern und Repräsentativitätsfehlern zusammen. Registrierungsfehler oder technische Fehler sind mit unzureichender Qualifikation der Beobachter, ungenauen Berechnungen, Unvollkommenheit der Instrumente usw. verbunden. Unter Repräsentativitätsfehler (Repräsentationsfehler). die Diskrepanz zwischen dem Stichprobenmerkmal und dem geschätzten Merkmal der Allgemeinbevölkerung verstehen. Repräsentativitätsfehler können zufällig oder systematisch sein. Systematische Fehler sind mit der Verletzung etablierter Auswahlregeln verbunden. Zufällige Fehler werden durch eine unzureichend einheitliche Darstellung verschiedener Kategorien von Einheiten der Allgemeinbevölkerung in der Stichprobe erklärt. Aufgrund des ersten Grundes kann sich die Stichprobe leicht als verzerrt herausstellen, da bei der Auswahl jeder Einheit ein Fehler gemacht wird, der immer in die gleiche Richtung geht. Dieser Fehler wird Offset-Fehler genannt. Seine Größe kann den Wert eines zufälligen Fehlers überschreiten. Ein Merkmal des Bias-Fehlers ist, dass er als konstanter Bestandteil des Repräsentativitätsfehlers mit der Stichprobengröße zunimmt. Der zufällige Fehler nimmt mit zunehmender Stichprobengröße ab. Außerdem kann die Größe des Zufallsfehlers bestimmt werden, während die Größe des systematischen Fehlers in der Praxis sehr schwierig und manchmal unmöglich direkt zu bestimmen ist. Daher ist es wichtig, die Ursachen des Offsetfehlers zu kennen und Maßnahmen zu seiner Beseitigung vorzusehen. Bias-Fehler sind entweder beabsichtigt oder unbeabsichtigt. Der Grund für den absichtlichen Fehler ist ein voreingenommener Ansatz bei der Auswahl von Einheiten aus der Allgemeinbevölkerung. Um das Auftreten eines solchen Fehlers zu verhindern, muss das Prinzip der zufälligen Auswahl von Einheiten beachtet werden. Unbeabsichtigte Fehler können in der Phase der Vorbereitung einer Stichprobenbeobachtung, der Bildung einer Stichprobenpopulation und der Analyse ihrer Daten auftreten. Um solche Fehler zu vermeiden, ist ein guter Stichprobenrahmen erforderlich, d. h. die Grundgesamtheit, aus der ausgewählt werden soll, beispielsweise eine Liste von Stichprobeneinheiten. Die Stichprobengrundlage muss zuverlässig, vollständig und mit dem Untersuchungszweck vereinbar sein und die Stichprobeneinheiten und ihre Eigenschaften müssen dem tatsächlichen Stand zum Zeitpunkt der Erstellung der Stichprobe entsprechen. Nicht selten erschweren einige Einheiten der Stichprobe die Informationsbeschaffung durch Abwesenheit zum Beobachtungszeitpunkt, fehlende Auskunftsbereitschaft etc. In solchen Fällen müssen diese Einheiten durch andere ersetzt werden. Es ist darauf zu achten, dass der Austausch durch gleichwertige Einheiten erfolgt. Zufällige Stichprobenfehler treten als Ergebnis zufälliger Unterschiede zwischen den Einheiten in der Stichprobe und den Einheiten der Allgemeinbevölkerung auf, d. H. Sie sind mit einer zufälligen Auswahl verbunden. Die theoretische Rechtfertigung für das Auftreten zufälliger Stichprobenfehler ist die Wahrscheinlichkeitstheorie und ihre Grenzwertsätze. Das Wesen der Grenzwertsätze besteht darin, dass bei Massenphänomenen der kumulative Einfluss verschiedener zufälliger Ursachen auf die Bildung von Regelmäßigkeiten und verallgemeinernden Merkmalen ein beliebig kleiner Wert sein wird oder praktisch nicht vom Fall abhängt. Da zufällige Stichprobenfehler durch zufällige Unterschiede zwischen den Einheiten der Stichprobe und der Allgemeinbevölkerung entstehen, werden sie bei ausreichend großem Stichprobenumfang beliebig klein. Die Grenzwertsätze der Wahrscheinlichkeitstheorie erlauben es, die Größe zufälliger Stichprobenfehler zu bestimmen. Unterscheiden Sie zwischen mittleren (Standard-) und marginalen Stichprobenfehlern. Unter durchschnittlicher (Standard-)Fehler Stichprobe bezieht sich auf die Diskrepanz zwischen dem Mittelwert der Stichprobe und dem Mittelwert der Grundgesamtheit. marginaler Fehler Es ist üblich, die maximal mögliche Diskrepanz, also den maximalen Fehler bei gegebener Wahrscheinlichkeit seines Auftretens, als Stichprobe zu betrachten. In der mathematischen Theorie des Stichprobenverfahrens werden die durchschnittlichen Merkmale der Merkmale der Stichprobe und der Allgemeinbevölkerung verglichen und es wird nachgewiesen, dass mit zunehmender Stichprobengröße die Wahrscheinlichkeit großer Fehler und die Grenzen des maximal möglichen Fehlers steigen Verringerung. Je mehr Einheiten befragt werden, desto geringer wird die Diskrepanz zwischen Stichprobe und allgemeinen Merkmalen sein. Basierend auf dem von P. L. Chebyshev bewiesenen Theorem kann der Wert des Standardfehlers einer einfachen Zufallsstichprobe mit ausreichend großem Stichprobenumfang (n) durch die Formel bestimmt werden: 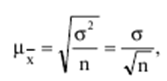 wo µxist Standardfehler. Aus dieser Formel für den mittleren (Standard-)Fehler einer einfachen Stichprobe ist ersichtlich, dass der Wert µx abhängig von der Variabilität des Merkmals in der Allgemeinbevölkerung (je größer die Variation des Merkmals, desto größer der Stichprobenfehler) und vom Stichprobenumfang n, je mehr Einheiten erhoben werden, desto geringer ist die Diskrepanz zwischen Stichprobe und allgemeinen Merkmalen) . Der Akademiker A. M. Lyapunov hat bewiesen, dass die Wahrscheinlichkeit des Auftretens eines zufälligen Stichprobenfehlers mit einer ausreichend großen Größe dem Gesetz der Normalverteilung gehorcht. Diese Wahrscheinlichkeit wird durch die Formel bestimmt:  In der mathematischen Statistik wird der Konfidenzfaktor t verwendet, und die Werte der Funktion F(t) werden für ihre verschiedenen Werte tabelliert und die entsprechenden Konfidenzniveaus erhalten. Mit dem Konfidenzkoeffizienten können Sie den marginalen Stichprobenfehler berechnen, der nach folgender Formel berechnet wird: 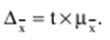 Aus der Formel folgt, dass der marginale Stichprobenfehler gleich - mal der Anzahl der durchschnittlichen Stichprobenfehler ist. Somit kann der Wert des marginalen Stichprobenfehlers mit einer bestimmten Wahrscheinlichkeit festgelegt werden. Die Stichprobenbeobachtung ermöglicht die Bestimmung des arithmetischen Mittels der Stichprobe x und der marginale Fehler dieses Durchschnitts Δx, die mit einer gewissen Wahrscheinlichkeit angibt), wie stark die Stichprobe vom allgemeinen Durchschnitt nach oben oder unten abweichen kann. Dann wird der Wert des allgemeinen Durchschnitts durch eine Intervallschätzung dargestellt, für die die Untergrenze gleich ist  Das Intervall, in dem der unbekannte Wert des geschätzten Parameters mit einem bestimmten Wahrscheinlichkeitsgrad eingeschlossen wird, wird als Konfidenzintervall bezeichnet, und die Wahrscheinlichkeit P wird als Konfidenzwahrscheinlichkeit bezeichnet. Meistens wird die Konfidenzwahrscheinlichkeit gleich 0,95 oder 0,99 genommen, dann ist der Konfidenzkoeffizient t gleich 1,96 bzw. 2,58. Das bedeutet, dass das Konfidenzintervall den allgemeinen Mittelwert mit einer gegebenen Wahrscheinlichkeit enthält. Neben dem Absolutwert des marginalen Stichprobenfehlers wird auch der relative Stichprobenfehler berechnet, der als prozentualer Anteil des marginalen Stichprobenfehlers zum entsprechenden Merkmal der Grundgesamtheit definiert ist: 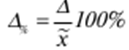 Je größer der Wert des marginalen Stichprobenfehlers ist, desto größer ist der Wert des Konfidenzintervalls und desto geringer ist folglich die Genauigkeit der Schätzung. Der durchschnittliche (Standard-)Fehler der Stichprobe hängt von der Stichprobengröße und dem Variationsgrad des Merkmals in der Allgemeinbevölkerung ab. 3. Bestimmung der erforderlichen Stichprobengröße Eines der wissenschaftlichen Prinzipien der Stichprobentheorie besteht darin, sicherzustellen, dass eine ausreichende Anzahl von Einheiten ausgewählt wird. Theoretisch wird die Notwendigkeit, dieses Prinzip einzuhalten, in den Beweisen der Grenzwertsätze der Wahrscheinlichkeitstheorie dargestellt, mit denen Sie feststellen können, wie viele Einheiten aus der allgemeinen Bevölkerung ausgewählt werden sollten, damit es ausreichend ist und die Repräsentativität der Stichprobe gewährleistet ist. Eine Verringerung des Standardfehlers der Stichprobe (und damit eine Erhöhung der Genauigkeit der Schätzung) ist immer mit einer Erhöhung des Stichprobenumfangs verbunden. Daher muss bereits in der Phase der Organisation einer Stichprobenbeobachtung entschieden werden, wie groß die Stichprobe sein soll, um die erforderliche Genauigkeit der Beobachtungsergebnisse sicherzustellen. Die Berechnung des erforderlichen Stichprobenumfangs basiert auf Formeln, die von den Formeln für die marginalen Stichprobenfehler (∆) abgeleitet sind, die der einen oder anderen Art und Methode der Auswahl entsprechen. Für eine zufällig wiederholte Stichprobengröße (n) gilt also: 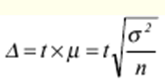  Die Bedeutung dieser Formel ist, dass im Falle einer zufälligen Neuauswahl der erforderlichen Anzahl der Stichprobenumfang direkt proportional zum Quadrat des Konfidenzkoeffizienten (t2) und der Varianz des Variationsmerkmals (σ2) und ist umgekehrt proportional zum Quadrat des marginalen Stichprobenfehlers (∆2). Insbesondere bei einer Erhöhung des maximalen Fehlers um den Faktor 2 kann die erforderliche Stichprobengröße um den Faktor 4 reduziert werden. Von den drei Parametern werden zwei (t und ∆) vom Forscher festgelegt. In diesem Fall muss der Forscher anhand des Zwecks und der Ziele der Stichprobenerhebung entscheiden, in welcher quantitativen Kombination diese Parameter besser einbezogen werden sollten, um die optimale Option sicherzustellen. In einem Fall ist er möglicherweise mit der Zuverlässigkeit der erhaltenen Ergebnisse (t) zufriedener als mit dem Genauigkeitsmaß (∆), in einem anderen Fall – umgekehrt. Schwieriger ist es, das Problem hinsichtlich der Größe des maximalen Stichprobenfehlers zu lösen, da der Forscher in der Phase der Planung der Stichprobenbeobachtung nicht über diesen Indikator verfügt. Daher ist es in der Praxis üblich, den Wert des maximalen Stichprobenfehlers festzulegen, der normalerweise innerhalb von 10 % des erwarteten Durchschnittsniveaus des Attributs liegt. Die Ermittlung des geschätzten Durchschnitts kann auf unterschiedliche Weise erfolgen: unter Verwendung von Daten aus ähnlichen früheren Erhebungen oder unter Verwendung von Daten aus dem Stichprobenrahmen und Durchführung einer kleinen Pilotstichprobe. Die Frage der Bestimmung des erforderlichen Stichprobenumfangs wird komplizierter, wenn die Stichprobenerhebung die Untersuchung mehrerer Merkmale von Stichprobeneinheiten beinhaltet. In diesem Fall sind die durchschnittlichen Niveaus jedes der Merkmale und ihre Variation in der Regel unterschiedlich, und daher ist es möglich, nur unter Berücksichtigung des Zwecks und der Ziele zu entscheiden, welche Streuung welchen der Merkmale zu bevorzugen ist die Umfrage. Beim Entwerfen einer Stichprobenbeobachtung wird ein vorgegebener Wert des zulässigen Stichprobenfehlers in Übereinstimmung mit den Zielen einer bestimmten Studie und der Wahrscheinlichkeit von Schlussfolgerungen basierend auf den Ergebnissen der Beobachtung angenommen. Im Allgemeinen ermöglicht uns die Formel für den Grenzfehler des Stichprobenmittels, die folgenden Probleme zu lösen: 1) Bestimmen Sie das Ausmaß möglicher Abweichungen der Indikatoren der Allgemeinbevölkerung von den Indikatoren der Stichprobenpopulation. 2) um die erforderliche Stichprobengröße zu bestimmen, wobei die erforderliche Genauigkeit bereitgestellt wird, bei der die Grenzen eines möglichen Fehlers einen bestimmten, vorbestimmten Wert nicht überschreiten; 3) Bestimmen Sie die Wahrscheinlichkeit, dass der Fehler in der Stichprobe eine bestimmte Grenze hat. 4. Auswahlmethoden und Arten der Probenahme In der Theorie des Stichprobenverfahrens wurden verschiedene Auswahlverfahren und Stichprobenarten entwickelt, um die Repräsentativität zu gewährleisten. Unter Auswahlverfahren das Verfahren zur Auswahl von Einheiten aus der Allgemeinbevölkerung verstehen. Es gibt zwei Auswahlverfahren: wiederholt und nicht wiederholt. Bei der Nachauswahl gelangt jede zufällig ausgewählte Einheit nach ihrer Prüfung wieder in die Allgemeinbevölkerung und kann bei anschließender Auswahl erneut in die Stichprobe fallen. Diese Auswahlmethode ist nach dem Schema "zurückgegebener Ball" aufgebaut. Bei dieser Auswahlmethode ändert sich die Wahrscheinlichkeit, in die Stichprobe zu gelangen, für jede Einheit der Allgemeinbevölkerung unabhängig von der Anzahl der ausgewählten Einheiten nicht. Bei der sich nicht wiederholenden Auswahl wird jede zufällig ausgewählte Einheit nach ihrer Prüfung nicht an die allgemeine Bevölkerung zurückgegeben. Dieses Auswahlverfahren ist nach dem Schema "nicht zurückgegebener Ball" aufgebaut. Die Wahrscheinlichkeit, für jede Einheit der Grundgesamtheit ausgewählt zu werden, steigt mit der Auswahl. Je nach Stichprobenmethodik werden folgende Hauptarten der Stichprobenziehung unterschieden: eigentlich zufällig, mechanisch, typisch (stratifiziert, regionalisiert), seriell (verschachtelt), kombiniert, mehrstufig, mehrphasig, interpenetrierend. Die Bildung der eigentlichen Zufallsstichprobe erfolgt streng nach wissenschaftlichen Grundsätzen und Regeln der Zufallsauswahl. Um eine wirklich zufällige Stichprobe zu erhalten, wird die Gesamtbevölkerung strikt in Stichprobeneinheiten unterteilt und anschließend eine ausreichende Anzahl von Einheiten in zufälliger, wiederholter oder sich nicht wiederholender Reihenfolge ausgewählt. Die zufällige Reihenfolge ist eine Reihenfolge, die einer Auslosung entspricht. In der Praxis lässt sich diese Reihenfolge am besten durch die Verwendung spezieller Zufallszahlentabellen erreichen. Sollen beispielsweise aus einer Grundgesamtheit von 1587 Einheiten 40 Einheiten ausgewählt werden, so werden aus der Tabelle 40 vierstellige Zahlen ausgewählt, die kleiner als 1587 sind. Bei einem nicht-repetitiven Auswahlverfahren erfolgt die Berechnung des Standardfehlers nach der Formel: 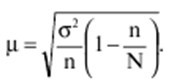
Da dieser Anteil immer kleiner als eins ist, ist der Fehler bei nicht-repetitiver Selektion unter sonst gleichen Bedingungen immer geringer als bei wiederholter Selektion. Die nicht-wiederholende Auswahl ist praktisch immer einfacher zu organisieren als die wiederholte Auswahl und wird häufiger verwendet. Die Bildung einer Stichprobe in strikter Übereinstimmung mit den Regeln der Zufallsauswahl ist praktisch sehr schwierig und manchmal unmöglich, da bei der Verwendung von Zufallszahlentabellen alle Einheiten der allgemeinen Bevölkerung nummeriert werden müssen. Sehr oft ist die allgemeine Bevölkerung so groß, dass es äußerst schwierig und unpraktisch ist, solche Vorarbeiten durchzuführen. Daher werden in der Praxis andere Arten von Stichproben verwendet, von denen jede nicht streng zufällig ist. Sie sind jedoch so organisiert, dass eine größtmögliche Annäherung an die Bedingungen der Zufallsauswahl gewährleistet ist. Bei einer rein mechanischen Stichprobe muss die gesamte Grundgesamtheit von Einheiten zunächst in Form einer Liste von Auswahleinheiten präsentiert werden, die in einer bezüglich des untersuchten Merkmals neutralen Reihenfolge, beispielsweise alphabetisch, zusammengestellt wird. Dann wird die Liste der Stichprobeneinheiten in so viele gleiche Teile geteilt, wie zur Auswahl von Einheiten erforderlich sind. Ferner wird gemäß einer vorbestimmten Regel, die sich nicht auf die Variation des untersuchten Merkmals bezieht, eine Einheit aus jedem Teil der Liste ausgewählt. Diese Art der Stichprobenentnahme stellt möglicherweise nicht immer eine zufällige Auswahl dar, und die resultierende Stichprobe kann verzerrt sein. Dies erklärt sich aus der Tatsache, dass erstens die Anordnung der Einheiten der allgemeinen Bevölkerung ein nicht zufälliges Element enthalten kann. Zweitens kann die Stichprobenziehung aus jedem Teil der Bevölkerung bei falscher Herkunft ebenfalls zu einem systematischen Fehler führen. Es ist jedoch praktisch einfacher, eine mechanische Stichprobe zu organisieren als eine echte Zufallsstichprobe, und diese Art der Stichprobenziehung wird am häufigsten bei Stichprobenerhebungen verwendet. Eine typische (in Zonen aufgeteilte, geschichtete) Probenahme hat zwei Ziele: 1) Sicherstellung der Repräsentation der entsprechenden typischen Gruppen der Allgemeinbevölkerung in der Stichprobe nach den für den Forscher interessanten Merkmalen; 2) Erhöhung der Genauigkeit der Ergebnisse der Stichprobenerhebung. Bei einer typischen Stichprobe wird die Grundgesamtheit der Einheiten vor Beginn ihrer Bildung in typische Gruppen eingeteilt. Ein sehr wichtiger Punkt ist in diesem Fall die richtige Wahl des Gruppierungsmerkmals. Die ausgewählten typischen Gruppen können die gleiche oder eine unterschiedliche Anzahl von Auswahleinheiten enthalten. Im ersten Fall wird die Stichprobenpopulation mit einem gleichen Anteil der Auswahl aus jeder Gruppe gebildet, im zweiten Fall mit einem Anteil, der proportional zu ihrem Anteil an der Gesamtbevölkerung ist. Wenn eine Stichprobe mit einem gleichen Auswahlanteil gebildet wird, entspricht sie im Wesentlichen einer Anzahl echter Zufallsstichproben aus kleineren Populationen, von denen jede eine typische Gruppe darstellt. Die Auswahl aus jeder Gruppe erfolgt auf zufällige (wiederholte oder nicht wiederholte) oder mechanische Weise. Bei einer typischen Stichprobe (sowohl mit gleichem als auch ungleichem Auswahlanteil) ist es möglich, den Einfluss der Intergruppenvariation des untersuchten Merkmals auf die Genauigkeit seiner Ergebnisse zu eliminieren, da obligatorische Darstellung jeder der typischen Gruppen in der Stichprobe Bevölkerung ist gewährleistet. Der Standardstichprobenfehler hängt nicht vom Wert der Gesamtvarianz – σ – ab2, und vom Wert des Mittelwerts der Gruppenstreuungen σi2. Da der Mittelwert der Gruppenvarianzen immer kleiner als die Gesamtvarianz ist, ist der Standardfehler einer typischen Stichprobe unter sonst gleichen Bedingungen kleiner als der Standardfehler einer Zufallsstichprobe selbst. Bei der Bestimmung der Standardfehler einer typischen Probe werden die folgenden Formeln verwendet: 1) mit der wiederholten Auswahlmethode: 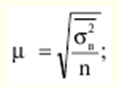 2) mit einer sich nicht wiederholenden Auswahlmethode:  wo σв2- der Durchschnitt der Gruppenvarianzen in der Stichprobengesamtheit. Serielle (verschachtelte) Abtastung - Hierbei handelt es sich um eine Art Stichprobenbildung, bei der nicht die zu erhebenden Einheiten, sondern Gruppen von Einheiten (Serien, Nester) zufällig ausgewählt werden. Innerhalb der ausgewählten Serien (Nester) werden alle Einheiten untersucht. Serienbemusterungen sind praktisch einfacher zu organisieren und durchzuführen als die Auswahl einzelner Einheiten. Allerdings ist bei dieser Art der Stichprobenziehung erstens nicht die Repräsentation jeder Serie gewährleistet und zweitens wird der Einfluss der Interserienvariation des untersuchten Merkmals auf die Erhebungsergebnisse nicht eliminiert. Wenn diese Variation signifikant ist, erhöht sie den zufälligen Repräsentativitätsfehler. Bei der Wahl der Probenart muss der Forscher diesen Umstand berücksichtigen. Der Standardfehler der seriellen Probenahme wird durch die Formeln bestimmt: 1) mit der wiederholten Auswahlmethode:  wo σв2- Interserien-Varianz der Stichprobenpopulation; r - Nummer der ausgewählten Serie; 2) mit einer sich nicht wiederholenden Auswahlmethode:  wobei R die Anzahl der Serien in der Allgemeinbevölkerung ist. In der Praxis werden je nach Zweck und Zielsetzung von Stichprobenerhebungen sowie den Möglichkeiten ihrer Organisation und Durchführung bestimmte Methoden und Arten der Stichprobenziehung eingesetzt. Meistens wird eine Kombination aus Probenahmeverfahren und Probenahmearten verwendet. Solche Proben werden kombiniert genannt. Die Kombination ist in verschiedenen Kombinationen möglich: mechanische und serielle Stichprobe, typische und mechanische, serielle und zufällige usw. Die kombinierte Stichprobe wird verwendet, um die größte Repräsentativität bei geringstem Arbeits- und Geldaufwand für die Organisation und Durchführung der Umfrage zu gewährleisten. Bei einer kombinierten Stichprobe besteht der Wert des Standardfehlers der Stichprobe aus den Fehlern bei jedem ihrer Schritte und kann als Quadratwurzel der Summe der Fehlerquadrate der entsprechenden Stichproben bestimmt werden. Wenn also mechanisches und typisches Sampling in Kombination mit kombiniertem Sampling verwendet wurden, kann der Standardfehler durch die Formel bestimmt werden: 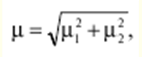 wo μ1 und μ2sind die Standardfehler der mechanischen bzw. typischen Proben. Die Besonderheit der mehrstufigen Stichprobe besteht darin, dass die Stichprobenpopulation entsprechend den Auswahlstufen schrittweise gebildet wird. In der ersten Stufe werden die Einheiten der ersten Stufe anhand einer vorgegebenen Methode und Art der Auswahl ausgewählt. In der zweiten Stufe werden aus jeder in der Stichprobe enthaltenen Einheit der ersten Stufe Einheiten der zweiten Stufe ausgewählt usw. Die Anzahl der Stufen kann mehr als zwei betragen. Im letzten Schritt wird eine Stichprobenpopulation gebildet, deren Einheiten befragt werden. So werden beispielsweise für eine Stichprobenerhebung zu Haushaltsbudgets in der ersten Stufe territoriale Subjekte des Landes, in der zweiten Stufe Kreise in ausgewählten Regionen, in der dritten Stufe Unternehmen oder Organisationen in jeder Gemeinde usw. ausgewählt In der vierten Phase schließlich werden Familien aus ausgewählten Unternehmen ausgewählt. Somit wird der Stichprobensatz in der letzten Stufe gebildet. Mehrstufige Stichproben sind flexibler als andere Arten, obwohl sie im Allgemeinen weniger genaue Ergebnisse liefern als eine einstufige Stichprobe derselben Größe. Gleichzeitig hat es jedoch einen wichtigen Vorteil, nämlich dass der Stichprobenrahmen bei der mehrstufigen Auswahl auf jeder Stufe nur für die Einheiten erstellt werden muss, die in der Stichprobe enthalten sind, und dies ist sehr wichtig, da dies der Fall ist oft kein vorgefertigter Stichprobenrahmen. Der Standardfehler der Stichprobenziehung bei mehrstufiger Auswahl mit Gruppen unterschiedlicher Volumina wird durch die Formel bestimmt: 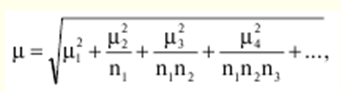 wo μ1μ2μ3,… - Standardfehler in verschiedenen Stadien; n1, N2, N3,… - die Anzahl der Proben in den entsprechenden Auswahlstufen. Für den Fall, dass die Gruppen nicht gleich groß sind, kann diese Formel theoretisch nicht verwendet werden. Wenn aber der Gesamtanteil der Selektion auf allen Stufen konstant ist, führt die Berechnung nach dieser Formel in der Praxis nicht zu einer Verzerrung des Fehlers. Das Wesen der mehrphasigen Stichprobe besteht darin, dass auf der Grundlage der ursprünglich gebildeten Stichprobenpopulation eine Teilstichprobe gebildet wird, aus dieser Teilstichprobe die nächste Teilstichprobe usw. Die anfängliche Stichprobenpopulation stellt die erste Phase dar, eine Teilstichprobe daraus – die zweite usw. Mehrphasen-Probenahme Es empfiehlt sich, in mehreren Fällen zu verwenden: 1) wenn eine ungleiche Stichprobengröße erforderlich ist, um verschiedene Merkmale zu untersuchen; 2) wenn die Fluktuation der untersuchten Merkmale nicht gleich ist und die erforderliche Genauigkeit unterschiedlich ist; 3) wenn in Bezug auf alle Einheiten der anfänglichen Stichprobenpopulation (erste Phase) einige weniger detaillierte Informationen und in Bezug auf die Einheiten jeder nachfolgenden Phase andere detailliertere Informationen gesammelt werden müssen. Einer der unbestrittenen Vorteile der Mehrphasenabtastung ist die Tatsache, dass die in der ersten Phase erhaltenen Informationen als zusätzliche Informationen in nachfolgenden Phasen verwendet werden können, Informationen in der zweiten Phase können als zusätzliche Informationen in nachfolgenden Phasen verwendet werden usw. Diese Informationsnutzung nimmt zu die Genauigkeit der Ergebnisse der Stichprobenerhebung. Bei der Organisation einer mehrphasigen Probenahme kann eine Kombination verschiedener Methoden und Arten der Auswahl verwendet werden (typische Probenahme mit mechanischer Probenahme usw.). Mehrphasenauswahl kann mit mehrstufig kombiniert werden. In jeder Stufe kann die Probenahme mehrphasig sein. Der Standardfehler in einer mehrphasigen Stichprobe wird für jede Phase separat gemäß den Formeln des Auswahlverfahrens und der Art der Stichprobe berechnet, mit deren Hilfe ihre Stichprobe gebildet wurde. Sich gegenseitig durchdringende Stichproben sind zwei oder mehr unabhängige Stichproben aus derselben Grundgesamtheit, die nach demselben Verfahren und Typ gebildet wurden. Es ist ratsam, auf Durchdringungsstichproben zurückzugreifen, wenn es notwendig ist, in kurzer Zeit vorläufige Ergebnisse von Stichprobenerhebungen zu erhalten. Sich gegenseitig durchdringende Stichproben sind effektiv für die Auswertung von Umfrageergebnissen. Wenn die Ergebnisse in unabhängigen Stichproben gleich sind, deutet dies auf die Zuverlässigkeit der Stichprobenerhebungsdaten hin. Durchdringende Stichproben können manchmal verwendet werden, um die Arbeit verschiedener Forscher zu testen, indem jeder Forscher eine andere Stichprobenerhebung durchführt. Der Standardfehler für sich durchdringende Stichproben wird auf die gleiche Weise definiert wie für typische proportionale Stichproben. Durchdringende Stichproben erfordern mehr Arbeit und Geld als andere Arten, daher muss der Forscher dies berücksichtigen, wenn er eine Stichprobenerhebung entwirft. Grenzfehler für verschiedene Auswahlverfahren und Arten der Probenahme werden durch die Formel bestimmt: Δ = tμ, wobei μ der entsprechende Standardfehler ist. VORTRAG №7. Indexanalyse 1. Allgemeines Indexkonzept und Indexverfahren In der statistischen Praxis sind Indizes neben Durchschnittswerten die gebräuchlichsten statistischen Indikatoren. Mit ihrer Hilfe wird die Entwicklung der Volkswirtschaft als Ganzes und ihrer einzelnen Sektoren charakterisiert, die Rolle einzelner Faktoren bei der Bildung der wichtigsten Wirtschaftsindikatoren untersucht. Indizes werden auch in internationalen Vergleichen von Wirtschaftsindikatoren verwendet, die den Lebensstandard bestimmen, die Geschäftstätigkeit in der Wirtschaft überwachen usw. Index (lat. Index) ist ein relativer Wert, der angibt, wie oft sich das Niveau des untersuchten Phänomens unter bestimmten Bedingungen von dem Niveau desselben Phänomens unter anderen Bedingungen unterscheidet. Der Unterschied in den Bedingungen kann sich in der Zeit (Dynamikindizes), im Raum (territoriale Indizes) und in der Wahl einer bestimmten Bedingungsebene als Vergleichsbasis manifestieren. Entsprechend der Abdeckung der Elemente der Bevölkerung (ihre Objekte, Einheiten und ihre Merkmale) werden einzelne (elementare) und zusammenfassende (komplexe) Indizes unterschieden, die in allgemeine und Gruppen unterteilt sind. Einzelne Indizes - Dies ist das Ergebnis des Vergleichs zweier Indikatoren, die sich auf dasselbe Objekt beziehen, z. B. der Vergleich der Preise eines Produkts, des Verkaufsvolumens usw. Bei der statistischen und wirtschaftlichen Analyse der Aktivitäten von Unternehmen und Branchen werden einzelne Indizes von Qualitative und quantitative Indikatoren sind weit verbreitet, zum Beispiel der Preisindex . Bestimmt durch die Formel: 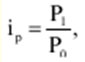 Der Preisindex charakterisiert die relative Veränderung des Stückpreises jeder Produktart im Berichtszeitraum gegenüber der Baseline und ist ein qualitativer Indikator. Der physikalische Volumenindex wird durch die Formel bestimmt: 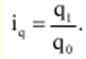 Der physische Volumenindex zeigt, wie oft sich die Produktion dieser Art von Produkten im Berichtszeitraum gegenüber dem Vergleichszeitraum verändert hat, und ist ein quantitativer Indikator. Der zusammengesetzte Index charakterisiert das Verhältnis der Niveaus mehrerer Elemente der Bevölkerung (z. B. eine Änderung des Produktionsvolumens mehrerer Arten von Produkten mit unterschiedlicher Naturstoffform oder eine Änderung des Niveaus der Arbeitsproduktivität in die Herstellung verschiedener Arten von Produkten). Wenn die untersuchte Population aus mehreren Gruppen besteht, sind die zusammengesetzten Indizes, von denen jeder die Änderung der Niveaus einer separaten Gruppe von Einheiten charakterisiert, die Gruppe (Unterindizes) und der zusammengesetzte Index, der die gesamte Population von Einheiten abdeckt , ist ein allgemeiner (Gesamt-)Index. Zusammengesetzte Indizes drücken das Verhältnis komplexer sozioökonomischer Phänomene aus und bestehen aus zwei Teilen: 1) vom indexierten Wert; 2) von einem Co-Meter, das als Gewicht bezeichnet wird. Der Indikator, dessen Veränderung den Index charakterisiert, wird indexiert genannt. Indizierte Indikatoren können von zweierlei Art sein. Einige von ihnen messen die allgemeine Gesamtgröße (Volumen) eines bestimmten Phänomens und werden bedingt als volumetrisch, umfangreich (Menge, d. h. das physische Volumen eines bestimmten Produkttyps, die Anzahl der Mitarbeiter, die gesamten Arbeitskosten für die Produktion, die Gesamtproduktionskosten usw.) P.). Diese Indikatoren werden als Ergebnis einer direkten Berechnung oder Summierung erhalten und sind anfänglich und primär. Andere Indikatoren messen das Niveau eines Phänomens oder Merkmals in Bezug auf die eine oder andere Einheit der Bevölkerung und werden bedingt als qualitativ, intensiv bezeichnet: Produktionsleistung pro Zeiteinheit (oder pro Mitarbeiter), Arbeitszeit pro Produktionseinheit, Kosten pro Einheit der Produktion usw. Diese Indikatoren werden durch Dividieren von volumetrischen Indikatoren erhalten, d. H. Sie sind kalkulierter, sekundärer Natur. Sie messen die Intensität, Wirksamkeit eines Phänomens oder Prozesses und sind in der Regel entweder Durchschnitts- oder Relativwerte. Bei der Verwendung der Indexmethode wird eine bestimmte Symbolik angewendet, d. h. ein System von Konventionen. Jeder indizierte Indikator wird durch einen bestimmten Buchstaben gekennzeichnet, normalerweise lateinisch): Q – Menge (Volumen) der produzierten Produkte (oder Menge der verkauften Waren) einer bestimmten Art in physischer Hinsicht; T – die Gesamtkosten der Arbeitszeit (Arbeit) für die Herstellung von Produkten dieser Art, gemessen in Mannstunden oder Manntagen; in einigen Fällen bezeichnet derselbe Buchstabe die durchschnittliche Anzahl der Mitarbeiter; z sind die Kosten pro Produktionseinheit; p ist der Preis einer Produktionseinheit oder eines Produkts; M ist der Gesamtverbrauch an Rohstoffen, Materialien oder Brennstoffen für die Herstellung von Produkten einer bestimmten Art und eines bestimmten Volumens. Indikatoren für den Basiszeitraum haben in den Formeln einen Index „0“ und für den verglichenen (aktuellen, Berichtszeitraum) einen „1“. Einzelne Indizes werden mit dem Buchstaben i bezeichnet und zusätzlich mit einem Index versehen – der Bezeichnung des indizierten Indikators. Ja, 1Q bezeichnet einen individuellen Index der Menge (physisches Volumen) von hergestellten Produkten (oder verkauften Waren) eines bestimmten Typs; ichz - individueller Stückkostenindex eines bestimmten Produkttyps usw. Zusammengesetzte Indizes sind mit dem Buchstaben I gekennzeichnet und werden auch von tiefgestellten Indikatoren der Indikatoren begleitet, deren Veränderung sie charakterisieren. Zum Beispiel icht - zusammengesetzter Index der Arbeitsintensität einer Produktionseinheit usw. Einzelne Indizes sind gewöhnliche relative Werte, dh sie können nur im weiteren Sinne als Indizes bezeichnet werden. Auch Indizes im engeren Sinne bzw. eigentliche Indizes sind relative Indikatoren, allerdings von besonderer Art. Sie haben eine komplexere Konstruktions- und Berechnungsmethode, und die spezifischen Methoden ihrer Konstruktion sind die Essenz der Indexmethode. Sozioökonomische Phänomene und sie charakterisierende Indikatoren können angemessen sein, dh ein gemeinsames Maß haben, und inkommensurabel sein. So sind die Mengen von Produkten oder Waren derselben Art und Sorte, die in verschiedenen Unternehmen hergestellt oder in verschiedenen Geschäften verkauft werden, angemessen und können summiert werden, während die Mengen verschiedener Arten von Produkten oder Waren inkommensurabel sind und nicht direkt summiert werden können. Es ist zum Beispiel unmöglich, Kilogramm Brot mit Litern Milch, Metern Kleidung und Paar Schuhen zu addieren. Die Inkommensurabilität und Unmöglichkeit der direkten Summierung bei der Konstruktion und Berechnung des zusammengesetzten Index erklärt sich hier weniger aus der Differenz der natürlichen Maßeinheiten als aus der Differenz der Verbrauchereigenschaften, der ungleichen naturstofflichen Form dieser Produkte oder Güter. In diesem Zusammenhang ist es zur Berechnung zusammengesetzter Indizes erforderlich, deren Komponenten in eine vergleichbare Form zu bringen. Die Einheit verschiedener Arten von Produkten oder unterschiedlichen Gütern liegt darin, dass sie Arbeitsprodukte sind, einen bestimmten Wert und seinen monetären Ausdruck – den Preis (p) – haben. Jedes Produkt hat auch den einen oder anderen Preis (z) und die Arbeitsintensität (t). Diese qualitativen Indikatoren können als allgemeines Maß verwendet werden – Vergleichskoeffizienten unterschiedlicher Produkte. Indem wir das Volumen jedes Produkttyps (Q) mit dem entsprechenden Preis, den Kosten oder der Arbeitsintensität pro Produktionseinheit multiplizieren, reduzieren wir die verschiedenen Produkte auf die gleiche Einheit und erhalten vergleichbare Indikatoren, die zusammengefasst werden können. Ähnlich verhält es sich bei der Konstruktion zusammengesetzter Indizes qualitativer Indikatoren. Angenommen, wir interessieren uns beispielsweise für die Änderung des allgemeinen Preisniveaus der verschiedenen verkauften Waren. Obwohl die Preise verschiedener Waren formal vergleichbar sind, ergibt ihre direkte Summierung (ohne Berücksichtigung der verkauften Warenmenge jeder Art) einen Wert ohne eigenständige praktische Bedeutung. Daher kann der zusammengesetzte Preisindex nicht als Verhältnis einfacher Summen konstruiert werden: 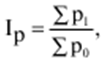 Die Preise der einzelnen Waren berücksichtigen nicht die spezifische Anzahl der verkauften Waren und ihr statistisches Gewicht und ihre Rolle im Prozess der Warenzirkulation. Einfache Summen von Preisen einzelner Waren eignen sich nicht zur Bildung eines zusammengesetzten Indexes, auch weil die Preise von der Maßeinheit der Waren abhängen, deren Änderung unterschiedliche Beträge und einen anderen Indexwert ergibt. Folglich können bei der Erstellung zusammenfassender Indizes von Qualitätsindikatoren diese nicht isoliert von den zugehörigen volumetrischen Indikatoren betrachtet werden, für deren Einheit diese Qualitätsindikatoren berechnet werden. Nur durch Multiplikation des einen oder anderen qualitativen Indikators (p, z, t) mit dem direkt zugehörigen volumetrischen Indikator (Q) kann man die Rolle und das statistische Gewicht jedes Produkttyps (oder Produkts) in dem einen oder anderen Wirtschaftsprozess berücksichtigen - der Prozess der Bildung des Gesamtwerts ( pQ), Gesamtkosten (zQ), Gesamtarbeitszeitkosten (tQ) usw. Gleichzeitig ist es möglich, Indikatoren zu erhalten, deren Summierung von praktischer Bedeutung ist. Das erste Merkmal der Indexmethode und der Indizes selbst ist also, dass der indizierte Indikator nicht isoliert, sondern in Verbindung mit anderen Indikatoren betrachtet wird. Durch die Multiplikation des indizierten Indikators mit einem anderen, verwandten Indikator reduzieren wir verschiedene Phänomene auf ihre Einheit, stellen ihre quantitative Vergleichbarkeit sicher und berücksichtigen ihr Gewicht im realwirtschaftlichen Prozess. Daher werden mit indexierten Indikatoren verbundene Multiplikatorindikatoren normalerweise Gewichtungen von Indizes genannt, und die Multiplikation mit ihnen wird als Gewichtung bezeichnet. Die Multiplikation der Werte eines indizierten Indikators mit den Werten eines anderen damit verbundenen Indikators (Gewicht) löst jedoch noch nicht das Problem des Index selbst. Indem man beispielsweise die Preise der entsprechenden Warenmengen multipliziert, kann man den Wert dieser Waren in jeder Periode finden und damit das Problem der Verhältnismäßigkeit und Gewichtung lösen. Vergleicht man jedoch die erhaltenen Produktsummen (∑S1Q1 und ∑poQo) gibt einen Indikator an, der Veränderungen des Handelsumsatzes in Abhängigkeit von zwei Faktoren charakterisiert – Preise und Mengen (Volumen) von Gütern, aber keine Veränderungen des Preisniveaus und des Produktionsniveaus von Gütern charakterisiert: 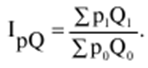 Damit der Index die Veränderung nur eines Faktors charakterisiert, ist es notwendig, die Veränderung des anderen Faktors in der obigen Formel zu eliminieren und sowohl im Zähler als auch im Nenner auf dem Niveau des gleichen Zeitraums zu fixieren. Um beispielsweise das Volumen heterogener Produkte in zwei Vergleichsperioden abzuschätzen, ist es notwendig, die in beiden Perioden verkauften Waren zu gleichen, beispielsweise Grundpreisen zu bewerten (S0). Der resultierende Indikator spiegelt die Änderung nur eines Faktors wider – des physischen Produktionsvolumens Q: 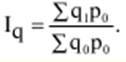 Und um die Änderung des Preisniveaus für eine Warengruppe abzuschätzen, ist es notwendig, die gleichen Volumina dieser Waren zu vergleichen, d.h. die Anzahl der Waren (Q) sowohl im Zähler als auch im Nenner des Index festzulegen auf der gleichen Ebene (entweder auf Basis- oder Berichtsebene). Somit werden die konstruierten zusammengesetzten Preisindizes nur die Preisänderung, d. h. den indexierten Indikator, charakterisieren, da die Änderung der Gewichte (Q) aufgrund ihrer Fixierung eliminiert (eliminiert) wird:  In beiden Fällen (Tq und Tp) spiegelte der Index die Änderung nur eines Faktors – des indexierten Indikators – wider, da der andere (Gewichte) auf demselben Niveau fixiert war. Das zweite Merkmal von Indizes und der Indexmethode besteht darin, den Einfluss von Gewichtsänderungen zu eliminieren, indem sie im Zähler und Nenner des Index auf derselben Ebene fixiert werden. Unter Berücksichtigung der Probleme, die bei der Konstruktion der eigentlichen Indizes auftreten, bestand die Aufgabe darin, eine vergleichende Beschreibung der Ebenen eines komplexen Phänomens zu geben, das aus heterogenen Elementen (verschiedene Arten von Produkten usw.) besteht. Ja, Tp muss zeigen, wie sich das Gesamtpreisniveau verändert hat, d.h. die Dynamik der Preise verschiedener Güter in Form eines allgemeinen Indikators messen. Historisch gesehen entstanden die Indizes selbst als Ergebnis der Lösung genau dieses ökonomischen Problems – des Problems der Verallgemeinerung, der Synthese der Dynamik einzelner Elemente eines komplexen Phänomens in einem verallgemeinernden Indikator – einem zusammengesetzten Index. Die Indizes selbst werden jedoch zur Lösung eines anderen Problems verwendet – der Analyse der Auswirkungen von Änderungen einzelner Faktorindikatoren auf die Änderung des Indikators, der die Funktion dieser Faktorargumente darstellt. Somit sind die Gesamtkosten der verkauften Waren eine Funktion ihrer Preise (p) und Mengen (Volumen – Q). Daher können wir uns die Aufgabe stellen, den Einfluss jedes dieser Faktoren auf Änderungen des Handelsumsatzes zu messen: Bestimmen Sie, wie er sich aufgrund von Änderungen jedes Faktors separat verändert hat. Indizes zur Lösung solcher analytischer Probleme werden ebenfalls unter Verwendung spezifischer Merkmale der Indexmethode erstellt – Wägen und Eliminieren von Gewichtsänderungen. Der Index selbst ist also ein relativer Indikator besonderer Art, bei dem die Niveaus eines sozioökonomischen Phänomens im Zusammenhang mit einem anderen (oder anderen) Phänomen betrachtet werden, dessen Veränderung in diesem Fall eliminiert wird. Die mit dem indexierten Indikator verbundenen Indikatoren werden als Indexgewichte verwendet, und die Gewichtung und Eliminierung von Gewichtsänderungen (Festlegung im Zähler und Nenner des Index auf demselben Niveau) sind die Besonderheiten der Indizes selbst und der Indexmethode. 2. Aggregierte Indizes qualitativer Indikatoren Jeder qualitative Indikator ist mit dem einen oder anderen Volumenindikator verbunden, basierend auf der Maßeinheit, von der er berechnet wird (oder von der Maßeinheit, auf die er sich bezieht). Der Einheitspreis eines Gutes hängt also von seiner Menge (Q) ab; Qualitätsindikatoren wie Preis (p), Kosten (z) und Arbeitsintensität werden mit dem Produktionsvolumen in Verbindung gebracht  Produktionseinheiten sowie der spezifische Verbrauch von Rohstoffen, Materialien 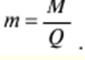 Zusammenfassende Indizes von Qualitätsindikatoren sollten nicht deren allgemeine Veränderung in Bezug auf eine beliebige Menge von Gütern oder Produkten charakterisieren, sondern die Veränderung von Preisen, Kosten, Arbeitsintensität oder Stückkosten einer ganz bestimmten Menge produzierter oder verkaufter Güter. Dies wird durch Gewichtung – Multiplikation der Stufen des indizierten Qualitätsindikators mit dem Wert des zugehörigen volumetrischen Indikators (Gewicht) – und Fixierung der Gewichte im Zähler und Nenner des Index auf der gleichen Stufe erreicht. Der Vergleich der Summen solcher Produkte ergibt einen Gesamtindex. In ähnlicher Weise können aggregierte Indizes der Kosten- und Arbeitsintensitätsdynamik pro Produktionseinheit sowie ein Index des spezifischen Verbrauchs von Rohstoffen oder Materialien erstellt werden. Das Hauptproblem bei der Erstellung dieser zusammenfassenden Indizes ist die wirtschaftlich sinnvolle Wahl des Niveaus, auf dem die Indexgewichte festgelegt werden müssen, d. h. in diesem Fall das Volumen der Produkte (oder Güter) – Q. Normalerweise besteht die Aufgabe vor dem zusammengesetzten Index der Dynamik eines qualitativen Indikators darin, nicht nur die relative Änderung des Niveaus zu messen, sondern auch den absoluten Wert des wirtschaftlichen Effekts, der in der aktuellen Periode als Ergebnis dieser Änderung erzielt wird : die Höhe der Einsparungen für Käufer aufgrund von Preissenkungen (oder die Höhe ihrer Mehrkosten, wenn die Preise gestiegen sind), die Höhe der Ersparnis (oder Mehrkosten) aufgrund von Kostenänderungen usw. Diese Problemstellung führt zu Indizes der Dynamik qualitativer Indikatoren mit Gewichtungen der aktuellen Periode. Erstens interessiert den Forscher die Veränderung der Kosten oder der Arbeitsintensität der Produkte, die derzeit hergestellt werden, und nicht in der Vergangenheit; Zweitens sollte der wirtschaftliche Effekt an die tatsächlichen Ergebnisse der aktuellen Berichtsperiode und nicht an die vorherige (Basis-)Periode gebunden sein. Nehmen wir als Beispiel den Gesamtkostenindex: 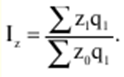 Somit stellt in diesem Index der Zähler die Höhe der tatsächlichen Kosten für Produkte im Berichtszeitraum dar, und der Nenner ist ein bedingter Wert, der angibt, wie viel Geld im Berichtszeitraum für Produkte ausgegeben worden wäre, wenn die Stückkosten für jede Art von Das Produkt wurde auf dem Grundniveau gehalten. Der durch Änderung der Produktionsstückkosten erzielte reale wirtschaftliche Effekt wird als absoluter Wert ausgedrückt, der als Differenz zwischen den Beträgen im Zähler und Nenner des Index berechnet wird 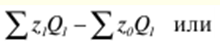 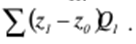 Daher verbindet die Gewichtung mit den Gewichten des (aktuellen) Berichtszeitraums den Index des qualitativen Indikators mit dem Indikator des wirtschaftlichen Effekts, der durch Änderung des indexierten Indikators erhalten wird. Daher werden in der Regel aggregierte Indizes der Dynamik qualitativer Indikatoren erstellt und mit den Gewichtungen des Berichtszeitraums berechnet: 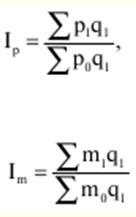 In diesen Indizes charakterisiert die Differenz zwischen Zähler und Nenner: im ersten Fall eine Verringerung oder Erhöhung der Kosten für den Kauf derselben Warengruppe, je nach Vorzeichen der Differenz; im zweiten Fall - eine Erhöhung oder Verringerung des Materialverbrauchs für die Herstellung der gleichen Produktmenge. 3. Aggregierte Indizes von Volumenindikatoren Volumenindikatoren können angemessen (Volumen von Produkten oder Gütern desselben Typs) und inkommensurabel (Volumen von Produkten oder Gütern unterschiedlicher Art – Q) sein. Vergleichbare volumetrische Indikatoren können direkt zusammengefasst werden, und die Konstruktion aggregierter Indizes bereitet keine Schwierigkeiten. Um ein allgemeines Ergebnis zu erhalten und einen aggregierten Index eines unterschiedlichen Volumenindikators zu erstellen, müssen zunächst die einzelnen Werte dieses Indikators gemessen werden. Basierend auf dem wirtschaftlichen Wesen des Phänomens ist es notwendig, ein gemeinsames Maß zu finden und es als Messkoeffizient zu verwenden. Ein solches gemeinsames Maß für volumetrische Indikatoren ist der zugehörige Qualitätsindikatoren mit ihnen. Somit können die Mengen verschiedener Arten von Produkten anhand des Preises (p), der Kosten (z) und der Arbeitsintensität (t) einer Einheit dieser Produkte gemessen werden. Die Multiplikation des indizierten Volumenindex mit dem einen oder anderen qualitativen Index bietet nicht nur die Möglichkeit der Summierung, sondern berücksichtigt gleichzeitig auch die Rolle jedes Elements, beispielsweise eines Produkts, im realen Wirtschaftsprozess, d.h. seine statistisches Gewicht in diesem Prozess. Da verschiedene qualitative Indikatoren als Gewichte im Volumenindex fungieren können, stellt sich die Frage, welche davon verwendet werden sollen. Diese Frage muss im Einzelfall entsprechend der vor den Index gestellten erkenntnisökonomischen Aufgabe gelöst werden, d. h. die Wahl bestimmter Gewichtungs-Kommensuratoren muss ökonomisch begründet werden. In der Praxis der wirtschaftlichen und statistischen Arbeit werden Preise üblicherweise als Gewichte für den aggregierten Produktionsindex verwendet. Auf diese Weise werden Indizes des Volumens industrieller und landwirtschaftlicher Produkte sowie Indizes des physischen Handelsvolumens gebildet. In einer Reihe von Fällen interessiert uns eine Änderung des Produktionsvolumens nicht an sich, sondern im Hinblick auf ihren Einfluss auf die Änderung eines Indikators einer komplexeren Ordnung – der Gesamtkosten der Produktion, ihrer Gesamtkosten, die Gesamtkosten der Arbeitszeit, das Gesamtproduktionsvolumen in einem bestimmten Bereich usw. In solchen Fällen wird die Wahl der Vergleichsskalen durch das Verhältnis der Indikatorfaktoren bestimmt, von denen ein komplexerer Indikator abhängt. Damit der Index nur die Veränderung des indexierten Volumenindikators widerspiegelt, werden die Gewichtungen in Zähler und Nenner auf dem Niveau des gleichen Zeitraums fixiert. In der Praxis der wirtschaftlichen Arbeit in den Indizes der Dynamik von Volumenindikatoren werden die Gewichte in der Regel auf dem Niveau der Basisperiode festgelegt. Dadurch ist es möglich, Systeme miteinander verbundener Indizes aufzubauen. Für einzelne Mengenindikatoren (Verkaufsmenge, Produktivitätsmenge, besäte Fläche) werden die Gewichte auf der Ebene des Basiszeitraums ausgewählt. Zum Beispiel:  wo ichn - zusammengesetzter Renditeindex; Ip - zusammengesetzter Index der Kosten des Warenumsatzes; Iq - konsolidierter Kostenindex. Im Gegensatz zu Qualitätsindizes, die anhand einer vergleichbaren Reihe von Einheiten (vergleichbaren Produkten) berechnet werden, sollten zusammengesetzte Volumenindizes der Vollständigkeit und Genauigkeit halber die gesamte Bandbreite der produzierten oder verkauften Einheiten in jedem Zeitraum abdecken. In diesem Zusammenhang stellt sich die Frage, welche Gewichte für diejenigen Produktarten angesetzt werden sollen, die nicht in einem der Vergleichszeiträume hergestellt wurden. In der statistischen Praxis werden in solchen Fällen zwei Methoden angewendet. Bei der Berechnung der Indizes des Volumens der Industrieproduktion werden neue Arten der Industrieproduktion, für die es keine Preise der Basisperiode gibt, bedingt zu den Preisen der laufenden Periode geschätzt. Bei der Berechnung der Indizes des verkauften Warenvolumens wird eine Methode verwendet, die auf der bedingten Annahme basiert, dass sich die Preise neuer Waren im gleichen Maße wie die Preise des verglichenen Sortiments ähnlicher Waren geändert haben. 4. Reihe aggregierter Indizes mit konstanten und variablen Gewichtungen Bei der Untersuchung der Dynamik wirtschaftlicher Phänomene werden Indizes für eine Reihe aufeinanderfolgender Perioden erstellt und berechnet. Sie bilden eine Reihe von Basis- oder Kettenindizes. Bei einer Reihe von Basisindizes wird der indexierte Indikator in jedem Index mit dem Stand der gleichen Periode verglichen, und bei einer Reihe von Kettenindizes wird der indexierte Indikator mit dem Stand der vorherigen Periode verglichen. In jedem einzelnen Index sind die Gewichte in Zähler und Nenner notwendigerweise auf dem gleichen Niveau festgelegt. Wenn eine Reihe von Indizes erstellt wird, können die darin enthaltenen Gewichte entweder für alle Indizes der Reihe konstant oder variabel sein. Eine Reihe grundlegender Indizes des Produktionsvolumens: 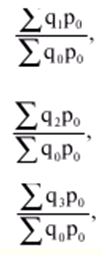 Konstante Gewichte (S0) hat auch eine Reihe von Kettenindizes:  Eine Reihe von Kettenpreisindizes:  Für Dynamik-Indizes mit konstanten Gewichten gilt der Zusammenhang zwischen Ketten- und Basis-Wachstumsraten (Indizes):  So ermöglicht die Verwendung konstanter Gewichte über mehrere Jahre den Übergang von Kettenindizes zu Basisindizes und umgekehrt. Daher werden die Indizesreihen für das Produktionsvolumen und das verkaufte Warenvolumen in der statistischen Praxis mit konstanten Gewichten konstruiert. Beispielsweise werden in Produktionsvolumenindizes Preise, die auf dem Niveau fixiert sind, das am 1. Januar eines Basisjahres festgesetzt wurde, als konstante Gewichte verwendet. Solche über mehrere Jahre verwendeten Preise werden als vergleichbar (fest) bezeichnet. Die Verwendung vergleichbarer Preise in den Indizes des Produktionsvolumens (Güter) ermöglicht es, durch einfache Summierung Ergebnisse für mehrere Jahre zu erhalten. Vergleichspreise sollten nicht wesentlich von aktuellen (aktuellen) Preisen abweichen. Daher werden sie regelmäßig überprüft und auf neue vergleichbare Preise umgestellt. Um Produktionsmengenindizes für längere Zeiträume mit unterschiedlichen Vergleichspreisen berechnen zu können, wird die Produktion eines Jahres sowohl zu den alten als auch zu den neuen Festpreisen bewertet. Der Index für einen langen Zeitraum wird nach der Kettenmethode berechnet, dh durch Multiplikation der Indizes für einzelne Segmente dieses Zeitraums. Die Reihen von Indizes qualitativer Indikatoren, die nach den Gewichten der aktuellen Periode wirtschaftlich korrekt zu gewichten sind, werden mit variablen Gewichten konstruiert. 5. Aufbau konsolidierter Gebietsindizes Bei der Erstellung von Territorialindizes, d. h. beim räumlichen Vergleich von Indikatoren (Kreisübergreifend, Vergleich zwischen verschiedenen Unternehmen etc.), stellen sich Fragen zur Wahl einer Vergleichsbasis und einer Region (Objekt), auf deren Ebene die Indexgewichte gesetzt werden sollen repariert sein. In jedem konkreten Fall müssen diese Fragen auf der Grundlage der Ziele der Studie angegangen werden. Die Wahl der Vergleichsbasis hängt insbesondere davon ab, ob die Vergleiche bilateral (z. B. Vergleich der Indikatoren zweier benachbarter Gebietseinheiten) oder multilateral (Vergleich der Indikatoren mehrerer Territorien, Objekte) erfolgen. Bei zweiseitigen Vergleichen kann jedes Gebiet oder Objekt mit gleicher Grundlage sowohl als Vergleich als auch als Vergleichsbasis herangezogen werden. In diesem Zusammenhang stellt sich die Frage, die Gewichte des zusammengesetzten Index auf der Ebene einer bestimmten Region (Objekt) festzulegen. Beispielsweise muss festgestellt werden, in welchem der beiden Bereiche und um wie viel Prozent die Produktionsstückkosten niedriger und das Produktionsvolumen größer sind. Wenn wir Bereich A mit Bereich B vergleichen, besteht eine ziemlich vernünftige und einfache Möglichkeit darin, im Kostenindex die Produktionsmengen im Allgemeinen für beide Gebiete festzulegen (Q = QA + QE), dann bekommst du: 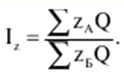 Bei multilateralen Vergleichen, beispielsweise beim Vergleich qualitativer Indikatoren in mehreren Bereichen, ist es notwendig, die Grenzen des Territoriums, auf dessen Ebene die Gewichte festgelegt werden, entsprechend zu erweitern. In den konsolidierten Gebietsindizes der Mengenindikatoren können die für die verglichenen Gebiete als Ganzes berechneten Durchschnittsniveaus der entsprechenden qualitativen Indikatoren als Gewichte verwendet werden. 6. Durchschnittliche Indizes Je nach Methodik zur Berechnung einzelner und zusammengesetzter Indizes gibt es arithmetische Mittelwerte und mittlere harmonische Indizes. Mit anderen Worten, der auf der Grundlage des individuellen Index gebildete allgemeine Index hat die Form eines arithmetischen Mittelwerts oder eines harmonischen Index, d. h. er kann in einen arithmetischen Mittelwert und einen durchschnittlichen harmonischen Index umgewandelt werden. Die Idee, einen zusammengesetzten Index als Durchschnitt einzelner (Gruppen-) Indizes zu konstruieren, ist ganz natürlich, da der zusammengesetzte Index ein allgemeines Maß ist, das die durchschnittliche Änderung des indizierten Indikators charakterisiert, und natürlich sollte sein Wert davon abhängen die Werte einzelner Indizes. Und das Kriterium für die Richtigkeit der Bildung eines zusammengesetzten Index in Form eines Durchschnittswerts (Durchschnittsindex) ist seine Identität mit dem Gesamtindex. Die Transformation des Gesamtindex in den Durchschnitt der einzelnen (Gruppen-)Indizes erfolgt wie folgt: Entweder im Zähler oder im Nenner des Gesamtindex wird der indizierte Indikator durch seinen Ausdruck in Bezug auf den entsprechenden Einzelindex ersetzt . Erfolgt eine solche Ersetzung im Zähler, so wird der Gesamtindex in das arithmetische Mittel umgerechnet, im Nenner dann in das harmonische Mittel der Einzelindizes. Beispielsweise sind der individuelle Index des physischen Volumens und die Produktionskosten jedes Typs im Basiszeitraum bekannt (q0p0). Ausgangsbasis für die Mittelwertbildung der einzelnen Indizes ist der zusammengesetzte Index des physischen Volumens:  Aus den verfügbaren Daten kann nur der Nenner der Formel direkt durch Summation erhalten werden. Der Zähler kann erhalten werden, indem die Kosten eines einzelnen Produkttyps der Basisperiode mit einem einzelnen Index multipliziert werden: 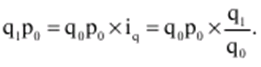 Dann nimmt die Formel des zusammengesetzten Index die Form an: 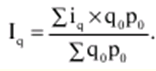 Folglich erhalten wir den arithmetischen Durchschnittsindex des physischen Volumens, wobei die Gewichte die Kosten bestimmter Arten von Produkten im Basiszeitraum sind. Nehmen wir an, wir haben Informationen über die Dynamik des Produktionsvolumens jedes Produkttyps (dq) und die Kosten für jede Produktart im Berichtszeitraum (S1q1). Um die Gesamtveränderung des Outputs eines Unternehmens in diesem Fall zu bestimmen, ist es zweckmäßig, die Paasche-Formel zu verwenden: 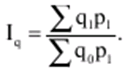 Den Zähler der Formel erhält man durch Summieren der Größen q1p1und der Nenner – indem die tatsächlichen Kosten jedes Produkttyps durch den entsprechenden individuellen Index des physischen Produktionsvolumens dividiert werden, d.h. dividieren p1q1 / ichq, Dann: 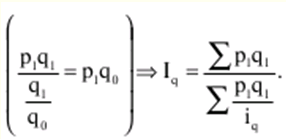 So erhalten wir die Formel für den durchschnittlichen gewichteten harmonischen Index des physikalischen Volumens. Die Verwendung der einen oder anderen Formel für den Index des physikalischen Volumens (Aggregat, arithmetisches Mittel und harmonisches Mittel) hängt von den verfügbaren Informationen ab. Es ist auch zu beachten, dass der Gesamtindex nur dann als Durchschnitt einzelner Indizes umgerechnet und berechnet werden kann, wenn die Liste der Waren- oder Warenarten (deren Sortiment) im Berichts- und Basiszeitraum übereinstimmt, d basierend auf einer vergleichbaren Palette von Einheiten ( aggregierte Indizes qualitativer Indikatoren und aggregierte Indizes von Volumenindikatoren, vorbehaltlich eines vergleichbaren Sortiments). VORTRAG №8. Merkmale des Systems von Indikatoren, die die wirtschaftliche Tätigkeit des Unternehmens bestimmen 1. Grundsätze für die Bildung eines Indikatorensystems Das allgemeine Prinzip, das der Bildung eines Systems von Indikatoren der Unternehmensstatistik zugrunde liegt, lautet wie folgt. 1. Das Thema Statistik - dies ist die Erhebung und Verarbeitung von Wirtschaftsindikatoren, die eine Analyse der Wirtschaftstätigkeit von Unternehmen verschiedener Arten und Branchen ermöglichen. Die Erhebung statistischer Informationen über die Bestellungen bestimmter Verbraucher erfolgt im Rahmen der Branchenstatistik. Dies ist beispielsweise die Tätigkeit kleiner Unternehmen. Alle Informationen sind in zwei Ströme unterteilt: 1) die wichtigsten Ergebnisse aller wirtschaftlichen Aktivitäten von Kleinunternehmen, unabhängig von ihrer Branche (Formular Nr. MP – T-Abschnitt, die wichtigsten Wirtschaftsindikatoren); 2) Statistische Indikatoren für die Produktion von Waren oder die Erbringung von Dienstleistungen in kleinen Unternehmen bestimmter Branchen, einschließlich der physischen Produktion, werden unter Verwendung des TT-Abschnitts des Formulars Nr. MP und einer Reihe von Branchenformularen entwickelt, die sich durch Signifikanz auszeichnen Differenzierung und Detaillierung der Menge der angeforderten Informationen. Außerdem wird daran gearbeitet, Basisindikatoren für Statistiken über große und mittlere Unternehmen zu erstellen. Die Analysebereiche der Aktivitäten großer und mittlerer Unternehmen, die die Zusammensetzung der im Rahmen der Unternehmensstatistik erhobenen Informationen bestimmen, sind: 1) die Effizienz der wirtschaftlichen Tätigkeit des Unternehmens, das Verhältnis von Ergebnissen und Kosten (die Struktur von Gewinnen und Kosten, die Rentabilität der Produktion, das Verhältnis von Vermögenswerten und Verbindlichkeiten usw.); 2) Finanz- und Vermögensstatus von Unternehmen (Anlage- und Betriebskapital, Quellen und Richtungen der Geldausgabe, Schulden usw.); 3) Investitionen und Geschäftstätigkeit von Unternehmen (Investitionen, Produktionskapazitäten und deren Nutzung, Lagerbestand, Produktnachfrage, Arbeiterbewegung usw.); 4) strukturelle und demografische Merkmale von Unternehmen. Arbeitsphasen zur Bestimmung der Zusammensetzung der wichtigsten Wirtschaftsindikatoren: 1) Bestandsaufnahme und Analyse der aktuellen Branchenberichterstattung im Hinblick auf die Zusammensetzung der Indikatoren, die Methodik für ihre Bildung, den Zeitpunkt der Einreichung, die Bandbreite der Berichtseinheiten usw.; 2) die Bildung der wichtigsten Wirtschaftsindikatoren der Mikroebene unter Berücksichtigung der allgemeinen Struktur des konzeptionellen Schemas zur Analyse der sozioökonomischen Entwicklung Russlands und der Zusammensetzung einzelner Spezialblöcke; 3) Vergleich der Indikatorenliste mit den in der aktuellen Berichterstattung verfügbaren statistischen Indikatoren; 4) Entwicklung statistischer Berichtsformulare für große und mittlere Unternehmen; 5) Ausarbeitung von Vorschlägen zur Überarbeitung der Formen der statistischen Branchenberichterstattung. Die Branchenberichterstattung gilt in Bezug auf die Produktion. Es deckt die Fragen der wertmäßigen und physischen Bilanzierung von Produkten mit allen Berechnungen ab und spiegelt die Besonderheiten der Arbeit von Unternehmen in einer bestimmten Branche wider. Integrierte Berichtsformulare helfen, die Wiederholbarkeit statistischer Indikatoren zu beseitigen und die Informationslast für das Unternehmen zu verringern. 2. Form der Strukturerhebung von Unternehmen ist ein Beispiel für integrierte Berichtsformulare für verschiedene Arten von Herstellern. Die Hauptsache auf Strukturerhebung ist die regelmäßige Bereitstellung statistischer Daten über den Zustand der Struktur des Produktionssystems für eine umfassende Analyse der Hauptparameter der finanziellen und wirtschaftlichen Aktivitäten von Unternehmen, die Bildung einzelner makroökonomischer Indikatoren. 2. Herstellungsprozess. Eigenschaften seines Modells Herstellungsprozess ist eine Reihe separater Arbeitsprozesse, die darauf abzielen, Rohstoffe und Materialien in fertige Produkte umzuwandeln. Die Zusammensetzung des Produktionsprozesses hat einen gewissen Einfluss auf die Struktur des Unternehmens und seiner Produktionseinheiten. Der Produktionsprozess ist die Grundlage der wirtschaftlichen Tätigkeit eines jeden Unternehmens. Die Hauptfaktoren, die die Art der Produktion bestimmen: 1) Arbeitsmittel (Maschinen, Ausrüstung, Gebäude, Bauwerke usw.); 2) Arbeitsgegenstände (Rohstoffe, Materialien, Halbfabrikate); 3) Arbeit ist die Aktivität von Menschen. Das Zusammenspiel dieser Hauptfaktoren bildet die Zusammensetzung des Produktionsprozesses. Zu Arbeitsressourcen bezieht sich auf Personal, Arbeitskräfte, die als die Arbeitsfähigkeit einer Person definiert sind. Arbeitskraft im Produktionsprozess wird in Form von Lebenshaltungskosten, gemessen an der Arbeitszeit, als natürliches Maß für die zielgerichtete Tätigkeit der Arbeitnehmer verbraucht. Ein Unternehmer, der in seiner wirtschaftlichen Tätigkeit Personal einsetzt, sieht sich mit der Tatsache konfrontiert, dass es sich bei der Arbeitskraft auf dem Arbeitsmarkt um ein ganz spezifisches Produkt mit Wert handelt. Das Volumen der aufgewendeten Arbeit wird in Geldwerten (Löhnen) ausgedrückt. Für einen effektiven Produktionsprozess muss ein Unternehmer hinreichend genaue und umfassende Informationen über die Gesamtmenge der verfügbaren Arbeitsressourcen, deren qualitative Merkmale (berufliche Zusammensetzung, Qualifikation etc.) und die Besonderheiten der Arbeitskostenbildung erhalten. Ressourcen von Arbeitsmitteln ist eine Reihe verschiedener fester Produktionsanlagen. Das Informationssubsystem der Ressourcen von Arbeitsmitteln sollte Indikatoren enthalten, die ihre Verfügbarkeit, Zusammensetzung nach Art, technischen Zustand und Rolle bei der Bildung von Produktions- und Vertriebskosten widerspiegeln. Ein Merkmal der Arbeitsmittel ist ihr Funktionieren während mehrerer Produktionszyklen. Die Arbeitsmittel übertragen ihren Wert auf das Produkt in Teilen, das heißt, indem sie sich abnutzen. In die Produktionskosten eines Produktionszyklus gehen die Arbeitsmittel mit dem entsprechenden Anteil ihrer Abschreibung ein, die monetär durch die entsprechende Höhe der Abschreibung bestimmt wird. Zu den Arbeitsgegenständen des Unternehmens umfassen: Vorräte an Rohstoffen, Materialien, Brennstoffen und anderen materiellen Ressourcen, einschließlich Halbfabrikate, Komponenten und Warenvorräte. Alle diese Ressourcen der Arbeitsgegenstände des Unternehmens sind für den normalen Ablauf der Produktionsprozesse notwendig. In monetärer Hinsicht bilden sie den Großteil des Betriebskapitals des Unternehmens, das auch Mittel in Vergleichen, freie Barmittel und andere Arten von Finanzanlagen umfasst. Um das Vorhandensein und die Verwendung von Arbeitsgegenständen zu charakterisieren, sollte das System von Indikatoren Daten über ihre natürliche und materielle Zusammensetzung, Verfügbarkeit, Eingang und Ausgabe im Produktionsprozess, Merkmale der Effizienz ihres Verbrauchs usw. enthalten, die bestimmende Indikatoren der Beitrag der Arbeitsgegenstände zur Bildung der Gesamtkosten des Unternehmens. Die mit dem Einsatz von Produktionsfaktoren verbundenen Produktionskosten werden sowohl auf die Gesamtkosten als auch auf die Kosten des hergestellten Produkts übertragen, die die Gesamtkosten übersteigen müssen. Das endgültige Ergebnis des Produktionsprozesses und der Zirkulation für den Unternehmer wird zum Zeitpunkt des Geldeingangs (Einnahmen) geklärt, den Käufer der Produkte des Unternehmens in bar oder in bar erhalten. Die vom Unternehmer erhaltenen Bareinnahmen werden in mehrere Richtungen verteilt, diese sind: 1) Erstattung der mit der Wiederaufnahme der Produktion verbundenen Kosten in beliebiger Höhe, die vom Eigentümer des Unternehmens festgelegt wird und die die Investition finanzieller Mittel in die Erneuerung der Bestände an Arbeitsgegenständen erfordert, um die Ressourcen an Arbeitsmitteln zu erhalten und zu erneuern um die Kosten zu bezahlen, die mit dem laufenden Verbrauch lebender Arbeitsressourcen verbunden sind; 2) ein Teil des Unternehmensertrags wird vom Unternehmer zur Deckung persönlicher Bedürfnisse verwendet; 3) Ein Teil der Erlöse geht an die Umwelt außerhalb des Unternehmens (Zahlung von Steuern, Zahlungen an Sonder- und Sonderfonds usw.). 3. Merkmale von Indikatorensystemen, die das Ressourcenpotenzial und die Ergebnisse aller Aktivitäten des Unternehmens bestimmen Die Rolle der Arbeitsressourcen nimmt ständig zu, und das nicht nur in der Zeit der Marktbeziehungen. Arbeitskollektiv - eine der Hauptaufgaben des Unternehmers, die der Schlüssel zum Erfolg der unternehmerischen Tätigkeit, zum Ausdruck und zum Wohlstand des Unternehmers ist. Als Arbeitskollektiv wird ein Team von Gleichgesinnten und Partnern bezeichnet, die in der Lage sind, die Pläne der Unternehmensleitung zu verwirklichen, zu verstehen und umzusetzen. Die Arbeitsbeziehungen sind ein komplexer Aspekt des Unternehmens. Der Produktionsprozess hängt vom Menschen ab, d. h. von seiner Arbeitslust und -fähigkeit und dementsprechend von seiner Qualifikation. Die entstehenden neuen Produktionssysteme bestehen nicht nur aus Maschinen, sondern auch aus Menschen, die eng zusammenarbeiten. Humankapital, Ausrüstung und Lagerbestände sind die Eckpfeiler für Wettbewerbsfähigkeit, Wirtschaftswachstum und Effizienz. Die Hauptfaktoren, die die Steigerung der Effizienz des Unternehmens beeinflussen: 1) Personalauswahl und -förderung; 2) Schulung des Personals und seine kontinuierliche Weiterbildung; 3) Stabilität und Flexibilität der Zusammensetzung der Mitarbeiter; 4) Verbesserung der materiellen und moralischen Bewertung der Arbeit der Mitarbeiter. Für die Auswahl und Beförderung von Mitarbeitern gibt es zwei Kriterien: 1) hohe berufliche Qualifikation und Lernfähigkeit; 2) Kommunikationserfahrung und Kooperationsbereitschaft. Beschäftigungssicherheit, reduzierte Personalfluktuation, hohe Löhne bieten einen erheblichen wirtschaftlichen Effekt und wecken bei den Mitarbeitern den Wunsch, die Arbeitseffizienz zu verbessern. Die Vergütung soll die Steigerung der Arbeitsproduktivität stimulieren und motivierend wirken. Um die Effizienz und Produktivität zu steigern, müssen sowohl die Löhne als auch der Ansatz zu ihrer Bildung geändert werden. Die Arbeitsorganisation und das Management des Unternehmensteams umfassen: 1) Einstellung von Mitarbeitern auf Teilzeit- oder Wochenbasis; 2) die Vermittlung von Arbeitern in Übereinstimmung mit dem etablierten Produktionssystem; 3) Aufgabenverteilung unter den Mitarbeitern des Unternehmens; 4) Umschulung oder Schulung des Personals; 5) Stimulation der Wehen; 6) Verbesserung der Arbeitsorganisation. Das Arbeitskollektiv des Unternehmens passt sich dem bestehenden System der Produktionsprozesse an. Die Struktur des Produktionsprozesses basiert auf den wissenschaftlichen Prinzipien der Arbeitsorganisation, zu denen gehören: 1) Arbeitsteilung und Verbesserung ihrer Zusammenarbeit auf der Grundlage der Teilung des Produktionsprozesses; 2) Auswahl von Fach- und Facharbeitern und deren Vermittlung; 3) Verbesserung der Arbeitsprozesse durch die Entwicklung und Umsetzung rationeller Arbeitsmethoden und -techniken; 4) Verbesserung der Dienstleistungen von Arbeitsplätzen auf der Grundlage einer klaren Regelung jeder Dienstleistungsfunktion; 5) die Einführung effektiver Formen der Teamarbeit, die Entwicklung abteilungsübergreifender Dienstleistungen und die Kombination von Berufen; 6) Verbesserung der Arbeitsrationierung auf der Grundlage der Nutzung von Reserven, Senkung der Arbeitskosten und der rationellsten Betriebsarten der Ausrüstung; 7) Organisation und Durchführung von systematischen Produktionseinweisungen - Weiterbildung der Arbeitnehmer, Erfahrungsaustausch und Verbreitung fortschrittlicher Arbeitsmethoden; 8) Schaffung von sanitären und hygienischen, psychophysiologischen, ästhetischen Arbeitsbedingungen und Arbeitssicherheit, Einführung von rationellen Arbeitsplänen, Arbeits- und Ruheregimen bei der Arbeit. Allgemeine Indikatoren für die Umsetzung dieser Grundsätze sind: 1) Wachstum der Arbeitsproduktivität; 2) Erfüllung aller Arbeitsbedingungen; 3) Zufriedenheit mit dem Inhalt der Arbeit und ihrer Attraktivität. Die wichtigsten Rekrutierungsquellen des Unternehmens sind alle Arten von Bildungseinrichtungen, Unternehmen mit ähnlichen Berufen und das Arbeitsamt. Die Aufgabenverteilung und der Einsatz von Arbeitskräften erfolgt nach einem arbeitsteiligen System. Folgende Formen der Arbeitsteilung haben sich verbreitet: 1) technologisch - nach Art der Arbeit, Berufen und Fachgebieten; 2) operativ - für bestimmte Arten von Operationen des technologischen Prozesses; 3) nach den Funktionen der durchgeführten Arbeit - Haupt-, Hilfs-, Nebentätigkeit; 4) nach Qualifikation. Wenn der Eigentümer eines Unternehmens Mitarbeiter ausgewählt hat, die alle seine Anforderungen erfüllen, ist es notwendig, einen Arbeitsvertrag oder Vertrag auszuarbeiten – dabei handelt es sich um eine Vereinbarung zwischen dem Unternehmer und der eingestellten Person, in der ein bestimmtes Einstellungssystem angewendet wird häusliche Praxis. Das gesamte Personal des Unternehmens ist in Kategorien eingeteilt. 1) Arbeiter; 2) Angestellte; 3) Spezialisten; 4) Führer. Zu den Arbeitnehmern des Unternehmens gehören Arbeitnehmer, die direkt an der Schaffung materieller Werte oder der Erbringung von Transport- und Produktionsdienstleistungen beteiligt sind. Arbeiter werden in Haupt- und Hilfskräfte unterteilt. Ihr Verhältnis ist ein analytischer Indikator des Unternehmens. Die Mitarbeiterzahl der Hauptarbeitskräfte wird durch die Formel bestimmt:  wobei Tvr die durchschnittliche Anzahl von Hilfskräften im Unternehmen, in Werkstätten, am Standort (Person) ist; Tr - die durchschnittliche Anzahl aller Arbeitnehmer im Unternehmen, in der Werkstatt, auf der Baustelle (Person). Fach- und Führungskräfte (Direktoren, Meister, Chefspezialisten etc.) organisieren und leiten den Produktionsprozess. Zu den Mitarbeitern gehören Mitarbeiter, die Finanzabrechnungen, Lieferungen und Marketing sowie andere Funktionen ausführen (Vertreter, Kassierer, Angestellte, Sekretärinnen, Statistiker usw.). Die Qualifikation der Arbeit wird durch das Niveau der Fachkenntnisse und praktischen Fähigkeiten bestimmt und charakterisiert den Grad der Komplexität der Arbeit. Die Einhaltung der Fähigkeiten, körperlichen und geistigen Eigenschaften eines jeden Berufes bedeutet die berufliche Eignung des Mitarbeiters. Personalstruktur des Unternehmens ist das Verhältnis der verschiedenen Kategorien von Arbeitnehmern zu ihrer Gesamtzahl. Zur Analyse der Personalstruktur wird der Anteil jeder Mitarbeiterkategorie dpi an der gesamten durchschnittlichen Mitarbeiterzahl des Unternehmens T ermittelt und verglichen: 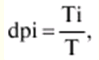 wo Ti - durchschnittliche Anzahl der Beschäftigten der Kategorie (Personen). Der Zustand der Frames wird anhand von Koeffizienten bestimmt. Ausfallrate Quadrat (%) ist das Verhältnis der Zahl der aus verschiedenen Gründen entlassenen Arbeitnehmer für einen bestimmten Zeitraum von Tuv. zur durchschnittlichen Zahl der Arbeitnehmer für denselben Zeitraum T: 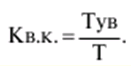 Rahmenakzeptanzrate (Kp.k). (%) ist das Verhältnis der Anzahl der Mitarbeiter, die für einen bestimmten Zeitraum, bezeichnet mit Tp, eingestellt wurden, zur durchschnittlichen Anzahl der Mitarbeiter für denselben Zeitraum, bezeichnet mit T:  Personalstabilitätskoeffizient Кс.к. wird zur Bewertung des Organisationsgrades des Produktionsmanagements sowohl im Unternehmen in einzelnen Abteilungen als auch insgesamt verwendet:  wo ist Tuv. - die Zahl der Mitarbeiter, die im Berichtszeitraum freiwillig und wegen Verstoßes gegen die Arbeitsdisziplin gekündigt haben (Personen); T - die durchschnittliche Anzahl der Mitarbeiter des Unternehmens in der Periode vor dem Berichtszeitraum (Personen); Tp - die Anzahl der neu eingestellten Mitarbeiter für den Berichtszeitraum (Personen). Die Fluktuationsrate (Kt.k.) wird ermittelt, indem die Anzahl der Mitarbeiter des Unternehmens, die in den Ruhestand getreten sind oder für einen bestimmten Zeitraum (Tuv.) entlassen wurden, durch die durchschnittliche Anzahl für denselben Zeitraum T (%) dividiert wird: 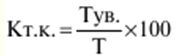 Die Arbeitskräftestatistik untersucht die Zusammensetzung und Größe der Erwerbsbevölkerung. Im Bereich der materiellen Produktion wird die Belegschaft in Personal, das mit der Haupttätigkeit des Unternehmens beschäftigt ist, und Personal, das nicht zum Kerngeschäft gehört, unterteilt. Die Hauptkategorie des Personals sind Arbeiter. Die Arbeitnehmer werden nach Beruf, Grad der Mechanisierung der Arbeit und Qualifikation gruppiert. Der Hauptindikator für die Qualifikation ist die Tarifkategorie bzw. der Tarifkoeffizient. Das durchschnittliche Qualifikationsniveau wird durch die durchschnittliche Tarifkategorie bestimmt, berechnet als arithmetisches Mittel der Kategorien, gewichtet mit der Anzahl oder dem Prozentsatz der Arbeitnehmer:  wo P - Tarifkategorien; T - die Anzahl (%) der Arbeitnehmer mit einer bestimmten Kategorie. Alle Mitarbeiter sind nach Geschlecht, Alter, Berufserfahrung und Ausbildung gruppiert. Die Kategorien der Zahl der Arbeiter und Angestellten umfassen die Gehaltsabrechnung und die Zahl der Angestellten die Zahl der tatsächlich Beschäftigten. Der Personalstand umfasst alle Arbeitnehmer des Unternehmens, die für einen oder mehrere Tage eingestellt werden. Die Wahlbeteiligung umfasst Arbeitnehmer, die zur Arbeit gekommen sind, sowie diejenigen, die auf Dienstreise sind und im Auftrag ihrer Organisation in anderen Unternehmen beschäftigt sind. Alle Personalbestandskategorien werden für ein bestimmtes Datum ermittelt, für viele wirtschaftliche Berechnungen ist es jedoch notwendig, die durchschnittliche Anzahl der Arbeitnehmer zu kennen – die durchschnittliche Anzahl der Arbeitnehmer, die durchschnittliche Anzahl der Beschäftigten und die durchschnittliche Anzahl der tatsächlich arbeitenden Personen. Die durchschnittliche Anzahl wird auf folgende Weise bestimmt. Unter der Annahme, dass die Gehaltsabrechnung zu Beginn und am Ende des Zeitraums bekannt ist, wird der durchschnittliche Personalbestand als die Hälfte der Summe dieser Werte ermittelt. Der durchschnittliche Personalbestand für ein Quartal, ein halbes Jahr und ein Jahr wird als arithmetisches Mittel der Monatsmittel ermittelt: T \uXNUMXd Summe der durchschnittlichen monatlichen Mitarbeiterzahlen / Anzahl der Monate des Zeitraums. Ist der Personalstand für Termine in regelmäßigen Abständen bekannt, z. B. zu Beginn oder Ende eines jeden Monats, so ergibt sich der durchschnittliche Personalbestand für ein Quartal, ein halbes Jahr oder ein Jahr nach der durchschnittlichen Zeitformel: 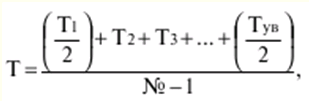 wobei Nr.-1 die Anzahl der Indikatoren ist; T1- Nummer beim ersten Date, T2, T3 - für andere Daten. Drei Formeln liefern die genauesten Ergebnisse:  Die durchschnittliche Anzahl der Mitarbeiter wird durch die Formel bestimmt:  Die durchschnittliche Zahl der tatsächlich Erwerbstätigen errechnet sich nach der Formel:  Die Arbeitszeit wird in Manntagen und Mannstunden gemessen. In der Statistik werden folgende Arbeitszeitmittel (in Personentagen) betrachtet. Kalenderfonds - dies ist die gesamte Zeit des Berichtszeitraums, sie entspricht dem Produkt aus der Anzahl der Kalendertage im Zeitraum und der Anzahl der abgerechneten Arbeitnehmer. Der Personalfonds ist um die Anzahl der Feiertage und Wochenenden an Manntagen geringer als der Kalenderfonds. Der maximal mögliche Fonds ist aufgrund des Zeitpunkts der nächsten Ferien geringer als der Personalfonds. Tatsächlich liegt der aufgewendete Zeitfonds aufgrund verschiedener Arbeitszeitverluste unter dem maximal möglichen. Die Verwendung von Zeitmitteln wird anhand der folgenden Koeffizienten gemessen:
Die Statistik analysiert auch die Nutzung der Schichtarbeitszeit, hierfür werden folgende Indikatoren verwendet:  Angepasster Schaltfaktor = Kontinuitätsfaktor x Schaltmodus-Nutzungsfaktor. Durch Arbeit werden natürliche Gegenstände oder Rohstoffe in ein fertiges Produkt umgewandelt. Diese Arbeitsfähigkeit wird Produktivkraft genannt. Die Arbeitsproduktivität ist ein Indikator für Erfolg. Arbeitsproduktivität - Dies ist die Effektivität lebendiger Arbeit, die Effektivität produktiver Aktivitäten, um im Laufe der Zeit ein Produkt zu schaffen. Die Aufgaben der Arbeitsproduktivitätsstatistik sind: 1) Verbesserung der Methodik zur Berechnung der Arbeitsproduktivität; 2) Identifizierung von Wachstumsfaktoren der Arbeitsproduktivität; 3) Bestimmung des Einflusses der Arbeitsproduktivität auf die Veränderung des Outputs. Die Arbeitsproduktivität wird durch Indikatoren der Arbeitsintensität und des Outputs charakterisiert. Der Output (W) von Produkten pro Zeiteinheit wird durch das Verhältnis des Outputvolumens (q) zu den Kosten (T) der Arbeitszeit (durchschnittliche Mitarbeiterzahl) gemessen: 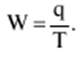 Dies ist ein direkter Indikator für die Arbeitsproduktivität. Das Gegenteil ist die Arbeitsintensität: 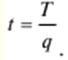 Die Produktion zeigt, wie viel Produkt pro Arbeitszeiteinheit produziert wird. Das System der statistischen Indikatoren der Arbeitsproduktivität wird durch die Maßeinheit des Volumens der hergestellten Produkte bestimmt. Einheiten können natürlich, bedingt natürlich, Arbeit und Kosten sein. Sie verwenden natürliche, bedingt natürliche, Arbeits- und Kostenmethoden zur Messung des Niveaus und der Dynamik der Arbeitsproduktivität. Je nach Messung der Arbeitskosten werden folgende Produktivitätsstufen unterschieden.  Dieses Niveau kennzeichnet die durchschnittliche Leistung eines Arbeitnehmers für eine Stunde tatsächlicher Arbeit. 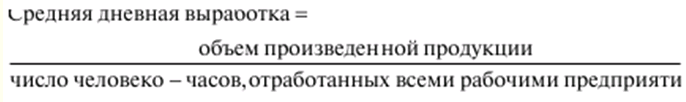 Diese Ebene zeigt den Grad der Produktionsauslastung des Arbeitstages.  Der Nenner spiegelt die Arbeitsreserven wider. Die durchschnittliche Quartalsleistung wird ähnlich wie der Monatsdurchschnitt ermittelt. Die durchschnittliche Leistung wird durch das Verhältnis der marktfähigen Produkte und die durchschnittliche Mitarbeiterzahl charakterisiert. Zwischen allen betrachteten Indikatoren besteht eine Beziehung: W1PPP = Wч × Srd × Spn × DArbeiten в IFR wo W.1nnn - Leistung pro Mitarbeiter; Wч - durchschnittliche Stundenleistung; Пrd - Arbeitszeit; Пpn - Dauer der Arbeitszeit; dArbeiten в IFR - Anteil der Arbeitnehmer an der Gesamtzahl des Industrie- und Produktionspersonals. Abhängig von der Methode der Niveaumessung wird die Dynamik der Arbeitsproduktivität anhand der folgenden statistischen Indizes analysiert: 1) natürlicher Index: 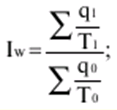 2) Arbeitsindex: 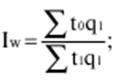 3) Index des Akademikers S. G. Strumilin: 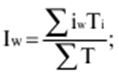 4) Wertindex:  4. Anlagekapital des Unternehmens Erst wenn zwei Faktoren vorliegen, wird produziert. Erstens ist dies Arbeit – zielgerichtete menschliche Tätigkeit. Zweitens handelt es sich um Produktionsmittel, die in Arbeitsmittel (Maschinen, Instrumente etc.) und Arbeitsgegenstände (Materialien, Brennstoffe, Rohstoffe etc.) unterteilt werden. Mit Hilfe von Arbeitsmitteln erfolgt eine direkte Einwirkung auf Arbeitsgegenstände – deren Gewinnung, Sammlung, Verarbeitung etc. oder es werden Bedingungen geschaffen, die den Produktionsprozess sicherstellen – das sind Industriegebäude, Bauwerke etc. Der Unterschied zwischen Arbeitsmitteln und Arbeitsgegenständen liegt darin, dass die Arbeitsgegenstände in einem Produktionszyklus verbraucht werden und ihr Wert vollständig und einmalig auf Produkte übergeht, während die Arbeitsmittel unter Beibehaltung ihrer natürlichen Form in den Produktionsprozess, übertragen ihren Wert bei jedem Produktionslauf viele Male in Teilen auf Produkte. Alle Arbeitsmittel, die im Produktionsprozess eingesetzt werden, sind Anlagevermögen. Sachanlagen sind also Arbeitsmittel, die den Produktionsprozess beeinflussen, Arbeitsgegenstände oder Bedingungen für die Durchführung des Produktionsprozesses im Unternehmen schaffen, aber bei längerer Funktion ihren Wert teilweise auf die entstehenden Produkte übertragen . Zusammensetzung und Struktur des Anlagevermögens Kapital ist ein Produktionsfaktor. Äußerlich drückt sich Kapital in bestimmten Formen aus - das sind Produktionsmittel (Produktionskapital), Geld (Cash), Güter (Ware). Ein Teil des Produktionskapitals (Gebäude, Bauwerke, Maschinen und Ausrüstung) wird als Anlagekapital bezeichnet. Ein weiterer Teil des Produktionskapitals (Rohstoffe, Materialien, Energieressourcen usw.) ist das Betriebskapital. In der Buchhaltung gibt es Begriffe wie "Anlagevermögen", "Anlagevermögen". In den Marktbeziehungen nimmt das Problem der Steigerung der Produktionskapazität der Organisation und der Effizienz der Nutzung des Anlagevermögens den Hauptplatz ein. Der Platz des Unternehmens in der industriellen Produktion, seine finanzielle Situation und seine Wettbewerbsfähigkeit auf dem Markt hängen davon ab, wie effektiv diese Probleme gelöst werden. Mitarbeiter von Unternehmen im Produktionsprozess mit Hilfe von Arbeitswerkzeugen beeinflussen die Arbeitsgegenstände und verwandeln sie in verschiedene Arten von Fertigprodukten. Das im Produktionsprozess funktionierende Anlagevermögen wird unterteilt in Produktionsanlagevermögen, zu dem der Teil des Anlagevermögens gehört, der am Produktionsprozess und an der Wertbildung beteiligt ist, und in nichtproduktives Anlagevermögen – das sind Mittel, die es nicht sind Sie stehen in direktem Zusammenhang mit der materiellen Produktion und beziehen sich im Wesentlichen auf die Dienstleistungsbereiche der Arbeitnehmer, auf die Befriedigung ihrer alltäglichen und kulturellen Bedürfnisse (Wohngebäude, Kinder- und Sporteinrichtungen und andere Einrichtungen). Die ständige Zunahme des nichtproduktiven Anlagevermögens ist mit einer Verbesserung des Wohlbefindens der Mitarbeiter des Unternehmens und einer Erhöhung des materiellen und kulturellen Niveaus ihres Lebens verbunden, was sich auf die Leistung des Unternehmens auswirkt. Die wichtigsten Produktionsgüter sind die materielle und technische Basis der gesellschaftlichen Produktion. Die Produktionskapazität des Unternehmens und das Niveau der technischen Ausstattung der Arbeitskräfte hängen vom Umfang des Anlagevermögens ab. Der Arbeitsprozess wird bereichert durch die Akkumulation des Anlagevermögens und die Vermehrung der technischen Ausstattung der Arbeit. Die in der Industrie tätigen Produktionsanlagen stellen industrielle Produktionsanlagen dar – diese Anlagen werden aufgrund ihrer Vielfalt umfassend untersucht. Um den Umfang und die Zusammensetzung der industriellen Produktionsanlagen zu untersuchen, werden diese nach verschiedenen Kriterien gruppiert – nach Eigentumsform, nach Branche und nach ihrer natürlichen Form. Derzeit werden industrielle Produktionsanlagen nach ihrer natürlichen Form gemäß der im Buchhaltungssystem festgelegten Klassifizierung gruppiert. Der Kern der Klassifizierung besteht darin, die Möglichkeit zu schaffen, das Anlagevermögen von Unternehmen nach seinem Zweck im Produktionsprozess zu verteilen und sein technisches Niveau widerzuspiegeln. Die wichtigsten Produktionsanlagen von Industrieunternehmen sind in Gruppen unterteilt: 1) Gebäude, Bauwerke; 2) Übertragungsgeräte; 3) Maschinen und Geräte – das sind Kraftmaschinen, Geräte, Arbeitsmaschinen und Geräte, Mess- und Regelinstrumente und -geräte sowie Laborgeräte, Computertechnik, sonstige Maschinen und Geräte; 4) Werkzeuge und Vorrichtungen, die länger als ein Jahr halten und mehr als 1 Million Rubel kosten. ein Stück. Werkzeuge und Geräte, die weniger als ein Jahr dienen oder weniger als 1 Million Rubel kosten. pro Stück werden als Betriebskapital als geringwertig und verschlissen behandelt; 5) Produktion und Haushaltsinventar. Das Verhältnis der einzelnen Gruppen des Anlagevermögens zu ihrer Gesamtheit Volumen repräsentiert die spezifische Struktur des Anlagevermögens. Gebäude, Strukturen, Inventar stellen das Funktionieren der aktiven Elemente des Anlagevermögens sicher und gehören daher zum passiven Teil des Anlagevermögens. Wenn der Anteil der Ausrüstung an den Kosten des Anlagevermögens der Produktion hoch ist, ergibt sich unter sonst gleichen Bedingungen eine höhere Produktionsleistung und eine höhere Kapitalproduktivitätsquote. Die Verbesserung der Struktur des Anlagevermögens der Produktion ist eine Voraussetzung für die Steigerung der Produktions- und Kapitalproduktivität, die Kostensenkung und die Erhöhung der Bargeldeinsparungen der Unternehmen. Faktoren, die die Struktur des Anlagevermögens beeinflussen, sind: die Art der Produkte, das Produktionsvolumen, der Grad der Mechanisierung und Automatisierung, der Grad der Zusammenarbeit und Spezialisierung, der geografische Standort der Organisationen und die klimatischen Bedingungen. Der Einfluss der Art der hergestellten Produkte spiegelt sich in der Größe und den Kosten von Gebäuden, dem Anteil von Fahrzeugen und Übertragungseinrichtungen wider. Bei einem hohen Ausbringungsvolumen wird auch der Anteil an speziellen progressiven Arbeitsmaschinen und -geräten höher. Diese Situation ist auch charakteristisch für den Einfluss des dritten und vierten Faktors auf die Fondsstruktur. Der Anteil der Gebäude und Strukturen hängt von den klimatischen Bedingungen ab. Die Planung und Abrechnung des Anlagevermögens erfolgt in natürlicher und monetärer Form. Bei der Bewertung des Sachanlagevermögens werden die Anzahl der Maschinen, deren Produktivität, Kapazität, Größe der Produktionsflächen und andere verschiedene Zahlenwerte ermittelt. Diese Daten werden verwendet, um die Produktionskapazität von Unternehmen und Industrien zu berechnen, das Produktionsprogramm zu planen, Reserven für die Steigerung der Produktionsleistung der Ausrüstung zu erstellen und eine Bilanz der Ausrüstung zu erstellen. Die Grundlage für die physische Buchführung des Anlagevermögens ist dessen Passportierung sowie eine Bestandsaufnahme, Erfassung seiner Ankunft und Entsorgung. Für jede einzelne Einheit des Anlagevermögens wird ein Pass erstellt, in dem die Produktions- und technischen Merkmale angegeben sind, der es ermöglicht, sie nach technischen Merkmalen, Produktionszweck und nach ihrem Zustand zu gruppieren. Mit der monetären Bewertung des Anlagevermögens können Sie die erweiterte Reproduktion des Anlagevermögens planen, den Abschreibungsgrad und die Höhe der Abschreibung sowie das Privatisierungsvolumen bestimmen. In der Rechnungslegungspraxis werden verschiedene Arten von Bewertungen des Anlagevermögens verwendet, die mit ihrer langfristigen Teilnahme und allmählichen Abnutzung im Produktionsprozess sowie Änderungen der Reproduktionsbedingungen in diesem Zeitraum verbunden sind: zum Original-, Wiederbeschaffungs- und Restwert . Die Anschaffungskosten des Anlagevermögens sind die Summe der Kosten für den Erwerb oder die Herstellung von Mitteln, deren Installation und Lieferung. Zunächst erfolgt die Bewertung des Anlagevermögens zu Anschaffungskosten. Die Anschaffungskosten des Anlagevermögens umfassen die Kosten für den Erwerb, den Transport, die Montage und die Installation des Anlagevermögens, d. h. dies sind alle Kosten, die mit der Anschaffung und Inbetriebnahme verbunden sind. Wiederbeschaffungskosten - die Kosten der Reproduktion des Anlagevermögens unter Marktbedingungen. Die Wiederbeschaffungskosten werden bei der Neubewertung der Fonds ermittelt. Der Restwert ist die Differenz zwischen den Anschaffungs- oder Wiederbeschaffungskosten des Anlagevermögens und dem Betrag seiner Abschreibung. Die wichtigsten Produktionsanlagen nutzen sich während des Funktionierens ab und übertragen ihren Wert auf die hergestellten Produkte. Amortisierung ist der auf Produkte übertragene Geldwert der Abschreibung des Anlagevermögens. Abschreibungen sind in den Herstellungskosten enthalten. Die jährliche Höhe der Abschreibungsabzüge wird durch die Formel bestimmt: A \uXNUMXd (B - L) / T, wobei B die gesamten Anschaffungskosten des Anlagevermögens sind; L - Liquidationswert des Anlagevermögens abzüglich der Kosten für deren Demontage; T ist die Standardnutzungsdauer des Anlagevermögens; M sind die geschätzten Modernisierungskosten während der gesamten Betriebszeit. Die jährlichen Abschreibungssätze werden ebenfalls durch die folgende Formel bestimmt:  Die jährlichen Bilanzen des Anlagevermögens werden erstellt, um die Veränderung des Volumens und der Bewegung des Anlagevermögens, seine Reproduktion zu charakterisieren, auf ihrer Grundlage werden die Prozesse ihrer Reproduktion analysiert, die Dynamik untersucht, die Indikatoren für Erneuerung, Entsorgung und Zustand von Anlagevermögen berechnet. Die jährliche Abschreibung des Anlagevermögens entspricht dem Betrag der aufgelaufenen Abschreibung für das Jahr. Einnahmequellen des Anlagevermögens sind: 1) Inbetriebnahme neuer Sachanlagen; 2) Kauf von Anlagevermögen von juristischen und natürlichen Personen; 3) unentgeltliche Entgegennahme von Anlagevermögen anderer juristischer und natürlicher Personen; 4) Leasing von Anlagevermögen. Abgänge können während der Liquidation aufgrund von Verfall und Abnutzung, Verkauf des Anlagevermögens an verschiedene juristische und natürliche Personen, unentgeltliche Übertragung, Übertragung des Anlagevermögens zur langfristigen Vermietung erfolgen. Auf der Grundlage dieser Bilanzen können eine Reihe von Indikatoren berechnet werden, die den Zustand und die Reproduktion des Anlagevermögens charakterisieren: 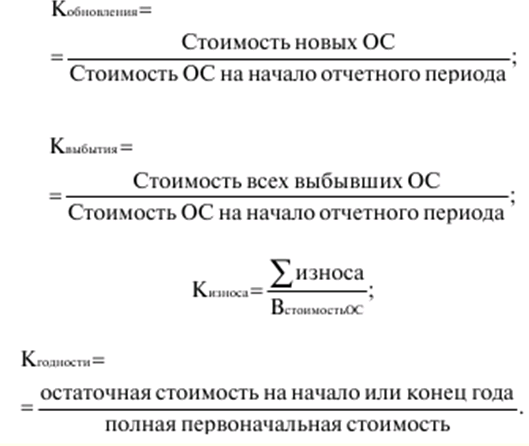 Indikatoren für die Verwendung des Anlagevermögens. Kapitalrendite:  Kapitalintensität:  Kapital-Arbeits-Verhältnis:  5. Umlaufvermögen des Unternehmens Betriebskapital - dies sind in Gegenstände investierte Finanzmittel, deren Ausgabe durch das Unternehmen innerhalb eines kurzen kalendarischen Zeitraums erfolgt. Zu den im Betriebskapital enthaltenen Artikeln gehören Artikel mit einer Lebensdauer von höchstens einem Jahr, unabhängig von ihrem Wert, sowie Artikel mit einem Wert unterhalb der festgelegten Grenze von höchstens dem 50-fachen des Mindestlohns pro Einheit zum Zeitpunkt des Kaufs , unabhängig von der Lebensdauer und ihren Kosten. Zusammensetzung des Betriebskapitals: 1) Produktionsbestände; 2) unfertige Erzeugnisse und Halbfabrikate; 3) unvollendete landwirtschaftliche Produktion; 4) Futter und Futter; 5) Ausgaben zukünftiger Berichtsperioden; 6) fertige Produkte; 7) Waren; 8) andere Inventargegenstände; 9) versandte Ware; 10) Bargeld; 11) Schuldner; 12) kurzfristige Finanzanlagen; 13) Sonstiges Umlaufvermögen. In der Zusammensetzung der Vorräte befinden sich: Rohstoffe und Materialien, zugekaufte Halbfabrikate, Komponenten, Kraft- und Schmierstoffe, Kraftstoffe, Komponenten usw. Die Quelle der Bildung von Working-Capital-Elementen sind finanzielle Ressourcen. Die Zusammensetzung der Finanzmittel umfasst: Eigenmittel (Mittel des genehmigten Kapitals, Sondervermögen, die auf Kosten des Gewinns gebildet werden), angezogene Mittel (gewerbliche Darlehen, Einlagen, ausgestellte Wechsel usw.). Working Capital besteht aus Vermögenswerten, die in ständiger Bewegung sind und zu Bargeld werden. Um die Verwendung von Betriebskapital zu charakterisieren, sind drei Indikatoren für die Geschwindigkeit ihrer Zirkulation. Umsatzquote charakterisiert die Anzahl der Umsätze des durchschnittlichen Saldos des Produktionsumlaufvermögens für den Berichtszeitraum:  wobei P die Kosten der für den Zeitraum verkauften Waren sind; SO - der durchschnittliche Saldo des Betriebskapitals, definiert als arithmetischer Durchschnitt der monatlichen Durchschnitte (für ein Quartal, ein halbes Jahr, ein Jahr) oder als chronologischer Durchschnitt. Koeffizient der Festsetzung des Betriebskapitals - Dieser Wert zeigt an, wie viel Betriebskapital Sie für 1 Rubel benötigen. Kosten der verkauften Produkte. Durchschnittliche Dauer eines Arbeitskapitalumschlags in Tagen: 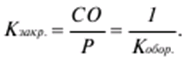 Durchschnittliche Dauer eines Arbeitskapitalumschlags in Tagen:  wobei D die Anzahl der Tage im Zeitraum ist. Die durchschnittlichen Indikatoren für die Umlaufgeschwindigkeit des Betriebskapitals werden berechnet. Die Umsatz- und Fixierungsverhältnisse werden als arithmetisch gewichtete Mittelwerte berechnet: 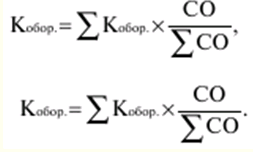 Die durchschnittliche Dauer einer Umdrehung in Tagen wird als harmonisch gewichteter Durchschnitt definiert: 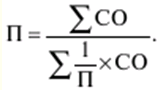 Die Wirkung der Beschleunigung des Umschlags des Betriebskapitals wird durch die Menge der Mittel ausgedrückt, die aufgrund der Beschleunigung ihres Umschlags bedingt aus dem Umlauf freigegeben werden. Der Indikator für den Einsatz von Arbeitsgegenständen ist die Materialintensität, die monetär den Verbrauch materieller Ressourcen pro Einheit Produktionsergebnis charakterisiert. Der Indikator für den Materialverbrauch wird nach folgender Formel berechnet: 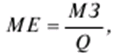 wo MZ - Materialherstellungskosten ohne Abschreibung des Anlagevermögens; Q - das Volumen des gesamten Sozialprodukts, des Volkseinkommens oder der Produkte einzelner Branchen und Unternehmen. 6. Statistische Untersuchung der Unternehmensfinanzierung Unternehmensfinanzierung - Dies sind in Geldform ausgedrückte Beziehungen, die bei der Bildung, Verteilung und Verwendung von Geldmitteln und Einsparungen im Prozess der Produktion und des Verkaufs von Waren, der Ausführung von Arbeiten und der Erbringung verschiedener Dienstleistungen entstehen. Die quantitativen Merkmale der Finanz- und Währungsbeziehungen sind zusammen mit ihren qualitativen Merkmalen aufgrund der Bildung, Verteilung und Verwendung finanzieller Ressourcen die Erfüllung von Verpflichtungen wirtschaftlicher Einheiten untereinander, gegenüber dem Finanz- und Bankensystem und dem Staat Studienfach Finanzstatistik. Die Hauptaufgaben der Finanzstatistik: 1) Untersuchung des Standes und der Entwicklung der finanziellen und monetären Beziehungen der Wirtschaftssubjekte; 2) den Umfang und die Struktur der Quellen der Bildung von Finanzmitteln zu analysieren; 3) bestimmen die Richtung der Mittelverwendung; 4) Analyse der Höhe und Dynamik der Gewinne und der Rentabilität des Unternehmens; 5) Bewertung der Finanzstabilität und Zahlungsfähigkeit; 6) Bewertung der Erfüllung von Finanz- und Kreditverpflichtungen durch Wirtschaftssubjekte. Finanzielle Resourcen - es sich um Eigen- und Fremdmittel wirtschaftlicher Einheiten handelt, die ihnen zur Verfügung stehen und dazu bestimmt sind, finanzielle Verpflichtungen zu erfüllen und Herstellungskosten zu verursachen. Der Umfang und die Zusammensetzung der Finanzmittel hängen vom Entwicklungsstand des Unternehmens und seiner Effizienz ab. Wenn das Unternehmen erfolgreich ist, dann ist die Höhe seiner Bareinnahmen hoch. Die Vermögensbildung erfolgt zum Zeitpunkt der Gründung der gesetzlichen Kasse. Die Quellen des genehmigten Kapitals sind: 1) Aktienkapital; 2) Aktieneinlagen von Genossenschaftsmitgliedern; 3) langfristige Kredite; 4) Haushaltsmittel. Bei etablierten Unternehmen in einer Marktwirtschaft sind die Quellen der Finanzmittel: 1) Gewinn aus verkauften Produkten, durchgeführten Arbeiten oder erbrachten Dienstleistungen; 2) Abschreibungen, Erlöse aus dem Verkauf von Aktien, Wertpapieren; 3) kurz- und langfristige Darlehen; 4) Einkünfte aus dem Verkauf von Immobilien usw. Profit charakterisiert die Endergebnisse von Handels- und Produktionsaktivitäten. Der Gewinn ist der Hauptindikator für die finanzielle Lage des Unternehmens. In der Unternehmensfinanzstatistik gibt es folgende Gewinnarten: 1) Bilanzgewinn; 2) Gewinn aus dem Verkauf von Produkten (Arbeiten, Dienstleistungen); 3) Bruttogewinn; 4) Reingewinn. Bilanzgewinn - Dies ist der Gewinn, der durch den Verkauf von Produkten des Anlagevermögens und sonstigen Vermögens von Wirtschaftseinheiten erzielt wird, sowie Einnahmen abzüglich Verluste aus Nichtverkaufsgeschäften. Der Gewinn aus dem Verkauf von Produkten wird als Differenz zwischen den Erlösen aus dem Verkauf von Produkten und den Produktions- und Verkaufskosten berechnet, die in den Produktionskosten enthalten sind. Der Bruttogewinn als Teil der nicht betrieblichen Erträge und Verluste berücksichtigt gezahlte Bußgelder und Strafen. Die Unternehmen bestimmen selbst Richtung, Umfang und Art der Verwendung des Reingewinns. Auf Kosten des Nettogewinns werden ein Produktionsentwicklungsfonds, ein Akkumulationsfonds, ein Sozialentwicklungsfonds und ein materieller Anreizfonds sowie ein Reservefonds gebildet. Rentabilitätsindikatoren 1. Gesamtrentabilität: 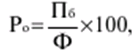 wobei Pб - der gesamte Bilanzgewinn; F - die durchschnittlichen jährlichen Kosten des Anlagevermögens und des normalisierten Betriebskapitals. 2. Rentabilität der verkauften Produkte: 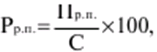 wobei P r.p. - Gewinn aus dem Verkauf von Produkten; C sind die Gesamtkosten der verkauften Waren. Indikatoren der Geschäftstätigkeit des Unternehmens Die Geschäftstätigkeit des Unternehmens wird anhand des Indikators des gesamten Kapitalumsatzes ermittelt:  wobei B der Erlös aus dem Verkauf von Produkten ist; K - das Hauptkapital des Unternehmens. Die Analyse der finanziellen Stabilität des Unternehmens ist in einer Marktwirtschaft sehr wichtig. Finanzielle Stabilität - Dies ist die Fähigkeit einer Wirtschaftseinheit, die in Anlage- und Betriebskapital sowie immaterielle Vermögenswerte investierten Kosten rechtzeitig aus eigenen Mitteln zu erstatten und ihre Verpflichtungen zu begleichen, dh zahlungsfähig zu sein. Zur Bewertung der Stabilitätsmessung werden Koeffizienten angewendet. 1. Autonomiekoeffizient: 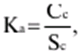 wobei Cс - Eigenmittel; Sс - die Summe aller Finanzierungsquellen. 2. Stabilitätsfaktor: 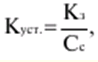 wo Kз - Verbindlichkeiten aus Lieferungen und Leistungen und andere geliehene Mittel. 3. Agilitätsfaktor: Kilometer = (Cс + DKZ-OSt..) / AUSс, wo DKZ - langfristige Kredite und Darlehen; Osv. - Anlagevermögen und sonstiges Anlagevermögen. 4. Liquiditätsquote: 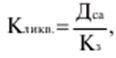 wo Dsa - Mittel, die in Wertpapiere, Vorräte, Forderungen investiert sind; KZ - kurzfristige Schulden. VORTRAG №9. Dynamische Analyse 1. Die Dynamik sozioökonomischer Phänomene und die Aufgaben ihrer statistischen Untersuchung Die von der sozioökonomischen Statistik untersuchten Phänomene des gesellschaftlichen Lebens unterliegen einem ständigen Wandel und einer ständigen Entwicklung. Im Laufe der Zeit – von Monat zu Monat, von Jahr zu Jahr – ändern sich die Bevölkerungsgröße und ihre Zusammensetzung, das Produktionsvolumen, das Niveau der Arbeitsproduktivität usw. Daher ist die Untersuchung von Veränderungen eine der wichtigsten Aufgaben der Statistik in sozialen Phänomenen im Laufe der Zeit – der Prozess ihrer Entwicklung, ihre Dynamik. Die Statistik löst dieses Problem durch die Konstruktion und Analyse dynamischer Reihen (Zeitreihen). Bereich der Dynamik (chronologisch, dynamisch, Zeitreihen) ist eine zeitlich geordnete Folge numerischer Indikatoren, die den Entwicklungsstand des untersuchten Phänomens charakterisieren. Die Reihe umfasst zwei obligatorische Elemente: Zeit und den spezifischen Wert des Indikators (Reihenebene). Jeder numerische Wert des Indikators, der das Ausmaß und die Größe des Phänomens charakterisiert, wird als Reihenebene bezeichnet. Zusätzlich zu den Ebenen enthält jede Reihe von Dynamiken Angaben zu den Momenten oder Zeitabschnitten, auf die sich die Ebenen beziehen. Bei der Zusammenfassung der Ergebnisse der statistischen Beobachtung werden absolute Indikatoren zweier Arten erhalten. Einige von ihnen charakterisieren den Zustand des Phänomens zu einem bestimmten Zeitpunkt: das Vorhandensein von beliebigen Bevölkerungseinheiten zu diesem Zeitpunkt oder das Vorhandensein des einen oder anderen Volumens eines Merkmals. Zu solchen Indikatoren gehören die Bevölkerung, der Fuhrpark, der Wohnungsbestand, die Lagerbestände usw. Der Wert solcher Indikatoren kann nur zu einem bestimmten Zeitpunkt direkt bestimmt werden, weshalb diese Indikatoren und die entsprechenden Zeitreihen als Momentanwerte bezeichnet werden. Andere Indikatoren charakterisieren die Ergebnisse eines Prozesses für einen bestimmten Zeitraum (Intervall) (Tag, Monat, Quartal, Jahr usw.). Solche Indikatoren sind beispielsweise die Anzahl der Geburten, die Anzahl der produzierten Produkte, die Inbetriebnahme von Wohngebäuden, der Lohnfonds usw. Der Wert dieser Indikatoren kann nur für einen bestimmten Zeitraum (Zeitraum) berechnet werden. Daher werden solche Indikatoren und Reihen ihrer Werte als Intervall bezeichnet. Einige Merkmale (Eigenschaften) der Niveaus der entsprechenden Zeitreihen ergeben sich aus der unterschiedlichen Natur der Intervall- und absoluten Momentindikatoren. In der Intervallreihe hängt der Wert des Pegels, der das Ergebnis eines beliebigen Prozesses für ein bestimmtes Zeitintervall (Periode) ist, von der Dauer dieser Periode (Länge des Intervalls) ab. Bei ansonsten gleichen Bedingungen ist die Höhe der Intervallreihe umso größer, je länger das Intervall ist, zu dem diese Ebene gehört. In der Momentenreihe der Dynamik, wo es auch Intervalle gibt (Zeitintervalle zwischen benachbarten Daten in einer Reihe), hängt der Wert einer bestimmten Ebene nicht von der Dauer des Zeitraums zwischen benachbarten Daten ab. Jeder Pegel einer Intervallreihe stellt bereits die Summe der Pegel über kürzere Zeiträume dar. In diesem Fall ist eine Bevölkerungseinheit, die Teil einer Ebene ist, nicht in anderen Ebenen enthalten. Daher können in einer Intervallreihe von Dynamiken Niveaus für benachbarte Zeiträume summiert werden, wodurch Ergebnisse (Niveaus) für längere Zeiträume erhalten werden (so dass wir durch Summieren monatlicher Niveaus vierteljährliche Niveaus erhalten; durch Summieren vierteljährlicher Niveaus erhalten wir jährliche Niveaus). ; summiert man die jährlichen Werte, erhält man mehrjährige Werte). Manchmal wird durch sequentielles Addieren der Stufen der Intervallreihe für benachbarte Zeitintervalle eine Reihe kumulativer Summen gebildet, bei der jede Stufe die Summe nicht nur für einen bestimmten Zeitraum, sondern auch für andere Zeiträume ab einem bestimmten Datum (von Jahresanfang usw.). ). Solche kumulativen Ergebnisse werden häufig in der Buchhaltung und anderen Berichten von Unternehmen angegeben. In einer Moment-Zeitreihe werden in der Regel dieselben Bevölkerungseinheiten in mehreren Ebenen erfasst. Daher ist die Summierung der Ebenen der Momentenreihe der Dynamik an sich nicht sinnvoll, da die dabei erzielten Ergebnisse keine eigenständige ökonomische Bedeutung haben. Oben sprachen wir über die Reihe von Dynamiken absoluter Werte, die anfänglich, primär sind. Zusammen mit ihnen können Dynamikreihen konstruiert werden, deren Niveaus relative und durchschnittliche Werte sind. Sie können auch entweder kurzzeitig oder intervallartig sein. In der Intervallreihe der Dynamik von Relativ- und Durchschnittswerten ist die direkte Summierung der Pegel an sich bedeutungslos, da die Relativ- und Durchschnittswerte Ableitungen sind und durch Division anderer Werte berechnet werden. Bei der Konstruktion und vor der Analyse einer Dynamikreihe ist zunächst darauf zu achten, dass die Ebenen der Reihen miteinander vergleichbar sind, da nur in diesem Fall die Dynamikreihe die Entwicklung des Phänomens korrekt widerspiegelt . Vergleichbarkeit von Ebenen einer Reihe von Dynamiken - Dies ist die wichtigste Bedingung für die Gültigkeit und Richtigkeit der Schlussfolgerungen, die sich aus der Analyse dieser Reihe ergeben. Bei der Erstellung einer Zeitreihe ist zu beachten, dass die Reihe einen großen Zeitraum abdecken kann, in dem es zu Veränderungen kommen kann, die die Vergleichbarkeit beeinträchtigen (Gebietsänderungen, Änderungen des Objektumfangs, Berechnungsmethodik etc.). Beim Studium der Dynamik sozialer Phänomene löst die Statistik folgende Aufgaben: 1) misst die absolute und relative Wachstumsrate oder Abnahme des Niveaus für verschiedene Zeiträume; 2) gibt allgemeine Eigenschaften des Niveaus und der Änderungsrate für einen bestimmten Zeitraum an; 3) enthüllt und numerisch charakterisiert die Haupttendenzen in der Entwicklung von Phänomenen in einzelnen Stadien; 4) gibt eine vergleichende numerische Beschreibung der Entwicklung dieses Phänomens in verschiedenen Regionen oder in verschiedenen Stadien; 5) enthüllt die Faktoren, die die zeitliche Veränderung des untersuchten Phänomens verursachen; 6) macht Prognosen für die Entwicklung des Phänomens in der Zukunft. 2. Die Hauptindikatoren der Reihe der Dynamik Beim Studium der Dynamik werden verschiedene Indikatoren und Analysemethoden verwendet, sowohl elementare als auch einfachere und komplexere, die die Verwendung komplexerer Abschnitte der Mathematik erfordern. Die einfachsten Analyseindikatoren, die zur Lösung einer Reihe von Problemen verwendet werden (hauptsächlich bei der Messung der Änderungsrate des Niveaus einer Reihe von Dynamiken), sind absolutes Wachstum, Wachstum und Wachstumsraten sowie der absolute Wert (Inhalt) von 1% Wachstum. Die Berechnung dieser Indikatoren basiert auf dem Vergleich der Ebenen einer Reihe von Dynamiken miteinander. Gleichzeitig wird die Ebene, mit der verglichen wird, als Basisebene bezeichnet, da sie die Vergleichsbasis ist. Üblicherweise wird entweder die vorherige Ebene oder eine vorherige Ebene, beispielsweise die erste Ebene einer Reihe, als Vergleichsbasis genommen. Wenn jede Ebene mit der vorherigen verglichen wird, werden die in diesem Fall erhaltenen Indikatoren als Kettenindikatoren bezeichnet, da sie sozusagen Glieder in der Kette sind, die die Ebenen der Reihe verbindet. Wenn alle Ebenen derselben Ebene zugeordnet sind, die als konstante Vergleichsbasis dient, werden die in diesem Fall erhaltenen Indikatoren als Basis bezeichnet. Oft beginnt die Konstruktion einer Reihe von Dynamiken mit der Ebene, die als konstante Vergleichsbasis verwendet wird. Die Wahl dieser Grundlage sollte durch die historischen und sozioökonomischen Merkmale der Entwicklung des untersuchten Phänomens begründet werden. Es ist zweckmäßig, als Basisniveau ein charakteristisches, typisches Niveau zu nehmen, beispielsweise das Endniveau der vorangegangenen Entwicklungsstufe (bzw. dessen Durchschnittsniveau, wenn auf der vorangegangenen Stufe das Niveau entweder angestiegen oder abgesunken ist). Absolutes Wachstum zeigt an, um wie viele Einheiten sich der Pegel im Vergleich zum Ausgangswert erhöht (oder verringert) hat, d. h. für einen bestimmten Zeitraum (Zeitraum). Der absolute Anstieg entspricht der Differenz zwischen den verglichenen Niveaus und wird in denselben Einheiten wie diese Niveaus gemessen: Δ=yi − jai - 1, Δ=yi − ja0, wo yi - Niveau des i-ten Jahres; yi - 1 - das Niveau des Vorjahres; y0 - Niveau des Basisjahres. Die Pegelabnahme gegenüber der Basis kennzeichnet die absolute Pegelabnahme. Das absolute Wachstum pro Zeiteinheit (Monat, Jahr) misst die absolute Wachstumsrate (oder Abnahme) des Niveaus. Ketten- und absolutes Grundwachstum sind miteinander verbunden: Die Summe aufeinanderfolgender Kettenwachstums ist gleich dem entsprechenden Grundwachstum, d. h. dem Gesamtwachstum für die gesamte Periode. Eine vollständigere Charakterisierung des Wachstums kann nur erhalten werden, wenn absolute Werte durch relative ergänzt werden. Relative Dynamikindikatoren sind Wachstumsraten und Wachstumsraten, die die Intensität des Wachstumsprozesses charakterisieren. Wachstumsrate (Tр) ist ein statistischer Indikator, der die Intensität der Veränderungen der Niveaus einer Reihe von Dynamiken widerspiegelt und zeigt, wie oft das Niveau im Vergleich zum Basisniveau gestiegen ist und im Falle einer Abnahme, welcher Teil des Basisniveaus ist verglichenes Niveau. Sie wird anhand des Verhältnisses des aktuellen Niveaus zum vorherigen bzw. Grundniveau gemessen:  Wie andere relative Werte kann die Wachstumsrate nicht nur in Form eines Koeffizienten (ein einfaches Verhältnis von Stufen), sondern auch in Prozent ausgedrückt werden. Wie absolute Wachstumsraten sind Wachstumsraten für beliebige Zeitreihen selbst Intervallindikatoren, d.h. sie charakterisieren den einen oder anderen Zeitraum (Intervall). Es besteht eine bestimmte Beziehung zwischen Ketten- und Basiswachstumsraten, ausgedrückt in Form von Koeffizienten: Das Produkt aufeinanderfolgender Kettenwachstumsraten ist gleich der Basiswachstumsrate für den gesamten entsprechenden Zeitraum. Zum Beispiel: 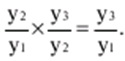 Wachstumsrate (Tпр) charakterisiert den relativen Wert der Steigerung, d. h. es ist das Verhältnis der absoluten Steigerung zum vorherigen oder Basisniveau.  In Prozent ausgedrückt, zeigt die Wachstumsrate, um wie viel Prozent das Niveau im Vergleich zum Ausgangswert, angenommen als 100 %, gestiegen (oder gesunken) ist. Bei der Analyse der Entwicklungsraten sollte man nie aus den Augen verlieren, welche absoluten Werte – Niveaus und absolute Inkremente – sich hinter den Wachstumsraten und Zuwächsen verbergen. Insbesondere ist zu berücksichtigen, dass bei einer Abnahme (Verlangsamung) des Wachstums und der Wachstumsraten das absolute Wachstum zunehmen kann. In diesem Zusammenhang ist es wichtig, einen weiteren Dynamikindikator zu untersuchen - den absoluten Wert (Inhalt) von 1% (ein Prozent) des Wachstums, der als Ergebnis der Division des absoluten Wachstums durch die entsprechende Wachstumsrate bestimmt wird: 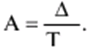 Dieser Wert zeigt, wie viel absolut jedes Prozent Wachstum ergibt. Manchmal sind die Niveaus des Phänomens für ein Jahr aufgrund von territorialen, abteilungsbezogenen und anderen Änderungen (Änderungen in der Rechnungslegungsmethode und Berechnung von Indikatoren usw.) nicht mit den Niveaus für andere Jahre vergleichbar. Um die Vergleichbarkeit zu gewährleisten und eine für die Analyse geeignete Zeitreihe zu erhalten, ist es notwendig, nicht mit anderen vergleichbare Pegel direkt neu zu berechnen. Manchmal sind die dafür erforderlichen Daten jedoch nicht verfügbar. In solchen Fällen können Sie eine spezielle Technik anwenden, die als Schließung der Reihe von Dynamiken bezeichnet wird. Nehmen wir zum Beispiel an, dass sich die Grenzen des Territoriums geändert haben, in dem die Dynamik der Entwicklung eines Phänomens im i-ten Jahr untersucht wurde. Dann sind die vor diesem Jahr erhobenen Daten nicht mit den Daten der Folgejahre vergleichbar. Um diese Reihen zu schließen und die Dynamik der Reihen für den gesamten Zeitraum analysieren zu können, nehmen wir als Vergleichsbasis jeweils das Niveau des i-ten Jahres, für das sowohl in den Daten als auch Daten vorliegen alte und in den neuen Grenzen des Territoriums. Diese beiden Zeilen mit derselben Vergleichsbasis können dann durch eine geschlossene Dynamikzeile ersetzt werden. Aus den Daten einer solchen geschlossenen Reihe kann man die Wachstumsrate im Vergleich zu einem beliebigen Jahr berechnen. Sie können auch die absoluten Pegel für den gesamten Zeitraum in den neuen Grenzen berechnen. Es muss natürlich berücksichtigt werden, dass die Ergebnisse, die durch Schließen der Dynamikreihe erhalten werden, einige Fehler enthalten. Grafisch wird die Dynamik von Phänomenen meist in Form von Balken- und Liniendiagrammen dargestellt. Es werden auch andere Formen von Diagrammen verwendet – geschweifte, quadratische, Kreisdiagramme usw. Analytische Diagramme werden normalerweise in Form von Liniendiagrammen erstellt. 3. Durchschnittliche Dynamik Im Laufe der Zeit ändern sich nicht nur die Ebenen der Phänomene, sondern auch Indikatoren ihrer Dynamik – absolute Steigerungen und Entwicklungsraten. Daher werden für ein verallgemeinertes Merkmal der Entwicklung, zur Identifizierung und Messung typischer Haupttrends und Muster und zur Lösung anderer Analyseprobleme durchschnittliche Indikatoren einer Zeitreihe verwendet – durchschnittliche Niveaus, durchschnittliche absolute Anstiege und durchschnittliche Dynamikraten. Um die Vergleichbarkeit von Zähler und Nenner bei der Berechnung von Durchschnitts- und Relativwerten sicherzustellen, ist es häufig erforderlich, bereits bei der Erstellung einer Zeitreihe auf die Berechnung der Durchschnittswerte einer Dynamikreihe zurückzugreifen. Angenommen, Sie müssen eine Reihe von Dynamiken der Stromproduktion pro Kopf in der Russischen Föderation aufbauen. Dazu ist es notwendig, für jedes Jahr die in diesem Jahr erzeugte Strommenge (Intervallindikator) durch die Bevölkerung im selben Jahr zu dividieren (Momentanindikator, dessen Wert sich im Laufe des Jahres kontinuierlich ändert). Es ist klar, dass die Bevölkerungsgröße zu einem bestimmten Zeitpunkt in der Regel nicht mit der Produktionsmenge des gesamten Jahres vergleichbar ist. Um die Vergleichbarkeit zu gewährleisten, ist es notwendig, die Bevölkerungsgröße irgendwie auf das gesamte Jahr abzustimmen, und dies kann nur durch die Berechnung der durchschnittlichen Bevölkerungsgröße für das Jahr erfolgen. Es ist oft notwendig, auf durchschnittliche Dynamikindikatoren zurückzugreifen, auch weil die Niveaus vieler Phänomene von Periode zu Periode stark schwanken, zum Beispiel von Jahr zu Jahr, entweder steigend oder fallend. Dies gilt insbesondere für viele Indikatoren der Landwirtschaft, wo Jahr für Jahr nicht sinkt. Daher arbeiten sie bei der Analyse der Entwicklung der Landwirtschaft oft nicht mit Jahresindikatoren, sondern mit typischeren und stabileren durchschnittlichen Jahresindikatoren für mehrere Jahre. Bei der Berechnung der durchschnittlichen Dynamikindikatoren ist zu berücksichtigen, dass für diese Durchschnittswerte die allgemeinen Bestimmungen der Durchschnittstheorie in vollem Umfang gelten. Dies bedeutet zunächst einmal, dass der dynamische Durchschnitt dann typisch ist, wenn er einen Zeitraum mit homogenen, mehr oder weniger stabilen Bedingungen für die Entwicklung des Phänomens charakterisiert. Die Identifizierung solcher Perioden – Entwicklungsstadien – ähnelt in gewisser Hinsicht der Gruppierung. Wenn der dynamische Durchschnitt für einen Zeitraum berechnet wird, in dem sich die Bedingungen für die Entwicklung des Phänomens erheblich geändert haben, also für einen Zeitraum, der verschiedene Stadien der Entwicklung des Phänomens abdeckt, muss ein solcher Durchschnitt mit großer Vorsicht verwendet und ergänzt werden mit Durchschnittswerten für einzelne Etappen. Die durchschnittlichen Dynamikindikatoren müssen auch die logische und mathematische Anforderung erfüllen, wonach beim Ersetzen der tatsächlichen Werte, aus denen der Durchschnitt berechnet wird, der Wert des definierenden Indikators, d. h. eines mit dem gemittelten Indikator verbundenen verallgemeinernden Indikators, sollte sich nicht ändern. Die Methode zur Berechnung des Durchschnittsniveaus einer Reihe von Dynamiken hängt in erster Linie von der Art des der Reihe zugrunde liegenden Indikators ab, d. h. von der Art der Zeitreihe. Die einfachste Art zu berechnen ist das durchschnittliche Niveau der Intervallreihe der Dynamik von Absolutwerten mit gleichen Niveaus. Die Berechnung erfolgt nach der Formel eines einfachen arithmetischen Mittels: 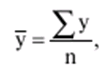 wobei n die Anzahl der tatsächlichen Pegel für aufeinanderfolgende gleiche Zeitintervalle ist. Komplizierter ist die Situation bei der Berechnung des durchschnittlichen Niveaus der Momentenreihe der Dynamik der Absolutwerte. Die Momentanzeige kann sich nahezu kontinuierlich ändern. Daher liegt es auf der Hand, dass wir das Durchschnittsniveau umso genauer berechnen können, je detaillierter und umfassender die Daten über seine Veränderung sind. Darüber hinaus hängt die Berechnungsmethode selbst davon ab, wie detailliert die verfügbaren Daten sind. Hier sind verschiedene Fälle möglich. Wenn umfassende Daten zur Änderung des Momentindikators vorliegen, wird sein Durchschnittsniveau nach der Formel des arithmetisch gewichteten Durchschnitts für eine Intervallreihe mit unterschiedlichen Niveaus berechnet:  wobei t die Anzahl der Zeiträume ist, in denen sich der Pegel nicht geändert hat. Wenn die Zeitintervalle zwischen benachbarten Daten gleich sind, d. h. wenn wir es mit gleichen (oder ungefähr gleichen) Intervallen zwischen Daten zu tun haben (z. B. wenn die Niveaus zu Beginn jedes Monats oder Quartals, Jahres bekannt sind), dann für eine Instant-Serie mit gleichen Pegeln, berechnen wir den Durchschnittspegel der Serie mit der chronologischen Durchschnittsformel: 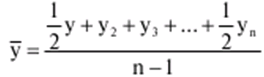 Für eine Instant-Serie mit unterschiedlichen Niveaus wird das durchschnittliche Niveau der Serie anhand der Formel berechnet: 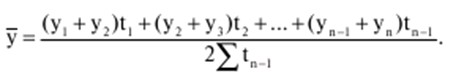 Oben haben wir über das durchschnittliche Niveau der Reihe von Dynamiken absoluter Werte gesprochen. Für die Reihe der Dynamik von Durchschnitts- und Relativwerten muss das Durchschnittsniveau auf der Grundlage des Inhalts und der Bedeutung dieser Durchschnitts- und Relativindikatoren berechnet werden. Durchschnittliches absolutes Wachstum zeigt an, um wie viele Einheiten sich der Pegel im Vergleich zum vorherigen im Durchschnitt pro Zeiteinheit (im Durchschnitt monatlich, jährlich usw.) erhöht oder verringert hat. Der durchschnittliche absolute Anstieg kennzeichnet die durchschnittliche absolute Wachstumsrate (bzw. Rückgang) des Niveaus und ist immer ein Intervallindikator. Es wird berechnet, indem das Gesamtwachstum für den gesamten Zeitraum durch die Länge dieses Zeitraums in verschiedenen Zeiteinheiten dividiert wird: 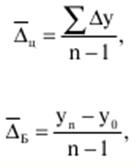 wobei Δ - Kettenabsolutinkremente für aufeinanderfolgende Zeiträume; n ist die Anzahl der Ketteninkremente; у0 - die Höhe des Basiszeitraums. Als Grundlage und Kriterium für die Richtigkeit der Berechnung der durchschnittlichen Wachstumsrate (wie auch der durchschnittlichen absoluten Zunahme) kann man das Produkt der Kettenwachstumsraten, das gleich der Wachstumsrate für den gesamten Betrachtungszeitraum ist, als a verwenden bestimmender Indikator. Wenn wir also n Kettenwachstumsraten multiplizieren, erhalten wir die Wachstumsrate für den gesamten Zeitraum:  Die Gleichberechtigung muss gewahrt werden:  Diese Gleichheit stellt die Formel für das einfache geometrische Mittel dar Aus dieser Gleichheit folgt: 
wobei n die Anzahl der Ebenen der Dynamikreihe ist; Т1, T2, Tп - Kettenwachstumsraten. Die durchschnittliche Wachstumsrate, ausgedrückt in Form eines Koeffizienten, zeigt, wie oft sich das Niveau im Vergleich zum vorherigen im Durchschnitt pro Zeiteinheit (im Durchschnitt jährlich, monatlich usw.) erhöht hat. Für durchschnittliches Wachstum und Wachstumsraten gilt die gleiche Beziehung wie zwischen normalem Wachstum und Wachstumsraten:  Die durchschnittliche Wachstumsrate (oder Rückgangsrate), ausgedrückt in Prozent, gibt an, um wie viel Prozent das Niveau im Vergleich zum vorherigen im Durchschnitt pro Zeiteinheit (im Durchschnitt jährlich, monatlich usw.) gestiegen (oder gesunken) ist. Die durchschnittliche Wachstumsrate charakterisiert die durchschnittliche Wachstumsintensität, d. h. die durchschnittliche relative Geschwindigkeit der Niveauänderung. Von den beiden Arten von Formeln für die durchschnittliche Wachstumsrate wird die zweite häufiger verwendet, da sie nicht die Berechnung aller Kettenwachstumsraten erfordert. Nach der ersten Formel ist es ratsam, nur in den Fällen zu rechnen, in denen weder die Niveaus der Dynamikreihe noch die Wachstumsrate für den gesamten Zeitraum bekannt sind, sondern nur die Kettenwachstumsraten (oder das Wachstum). 4. Identifizierung und Charakterisierung des wichtigsten Entwicklungstrends Eine der Aufgaben, die sich bei der Analyse von Zeitreihen ergeben, besteht darin, Muster der Veränderung der Niveaus des untersuchten Indikators im Laufe der Zeit zu ermitteln. Dazu ist es notwendig, solche Entwicklungsperioden (Stadien) herauszugreifen, die in Bezug auf die Beziehung dieses Phänomens zu anderen und in Bezug auf die Bedingungen für seine Entwicklung ausreichend homogen sind. Die Identifizierung von Entwicklungsstadien ist eine Aufgabe an der Schnittstelle zwischen Wissenschaft, die dieses Phänomen untersucht (Wirtschaft, Soziologie usw.) und Statistik. Die Lösung dieses Problems erfolgt nicht nur und nicht einmal so sehr mit Hilfe statistischer Methoden (obwohl sie von gewissem Nutzen sein können), sondern auf der Grundlage einer sinnvollen Analyse des Wesens, der Natur des Phänomens und des Allgemeinen Gesetze seiner Entwicklung. Für jede Entwicklungsstufe ist es notwendig, den Haupttrend der Änderung des Phänomenniveaus zu identifizieren und numerisch zu charakterisieren. Ein Trend ist eine allgemeine Richtung einer Zunahme, Abnahme oder Stabilisierung des Niveaus eines Phänomens im Laufe der Zeit. Wenn der Pegel kontinuierlich ansteigt oder kontinuierlich abnimmt, ist der Aufwärts- oder Abwärtstrend klar und deutlich: Er lässt sich visuell leicht anhand eines Zeitreihendiagramms erkennen. Es ist jedoch zu bedenken, dass sowohl der Anstieg als auch der Rückgang der Werte auf unterschiedliche Weise erfolgen können: entweder gleichmäßig, beschleunigt oder verlangsamt. Mit gleichmäßigem Wachstum (oder Rückgang) meinen wir hier Wachstum (Abnahme) mit einer konstanten absoluten Rate, wenn die absoluten Kettenzuwächse (4) gleich sind. Bei beschleunigtem Wachstum oder Rückgang nimmt der absolute Wert der Ketteninkremente systematisch zu, bei langsamem Wachstum oder Rückgang sinken sie (auch im absoluten Wert). In der Praxis nehmen die Pegel einer Reihe von Dynamiken sehr selten streng gleichmäßig zu (oder ab). Auch eine systematische Zunahme oder Abnahme der Ketteninkremente ohne eine einzige Abweichung ist selten. Solche Abweichungen erklären sich entweder durch eine Veränderung im Laufe der Zeit des gesamten Komplexes der Hauptursachen und Faktoren, von denen das Ausmaß des Phänomens abhängt, oder durch eine Änderung der Richtung und Stärke der Wirkung sekundärer (einschließlich zufälliger) Umstände und Faktoren. Daher sprechen wir bei der Analyse der Dynamik nicht nur über den Entwicklungstrend, sondern über den Haupttrend, der in dieser Entwicklungsphase ziemlich stabil (nachhaltig) ist. In manchen Fällen wird diese Regelmäßigkeit, der allgemeine Trend in der Entwicklung eines Objekts ganz deutlich durch die Ebenen der dynamischen Reihe dargestellt. Haupttrend (Trend) bezeichnet eine ziemlich gleichmäßige und stabile Änderung des Niveaus eines Phänomens im Laufe der Zeit, die mehr oder weniger frei von zufälligen Schwankungen ist. Der Haupttrend kann entweder analytisch – in Form einer Trendmodellgleichung – oder grafisch dargestellt werden. In der Statistik wird die Identifizierung des Hauptentwicklungstrends (Trends) auch als Zeitreihenausrichtung bezeichnet, und Methoden zur Identifizierung des Haupttrends werden als Alignment-Methoden bezeichnet. Eine der gebräuchlichsten Methoden, um die Haupttrends (Trend) einer Reihe von Dynamiken zu identifizieren, ist: 1) Methode der Intervallvergrößerung; 2) Methode des gleitenden Durchschnitts (der Kern der Methode besteht darin, absolute Daten durch arithmetische Mittelwerte für bestimmte Zeiträume zu ersetzen). Die Berechnung der Durchschnittswerte erfolgt nach der gleitenden Methode, d. h. dem allmählichen Ausschluss aus dem akzeptierten Zeitraum der ersten Ebene und der Einbeziehung der nächsten; 3) analytische Ausrichtungsmethode. In diesem Fall werden die Pegel der Dynamikreihen als Funktionen der Zeit ausgedrückt: a) f(t)= a0+ ajt- lineare Abhängigkeit; b) f(t) = a0 + cijt + a2t2- parabolische Abhängigkeit. Die Methode zur Vergrößerung von Intervallen und ihren Merkmalen um Durchschnittswerte besteht darin, von kürzeren zu längeren Intervallen überzugehen, beispielsweise von Tagen zu Wochen oder Jahrzehnten, von Jahrzehnten zu Monaten, von Monaten zu Quartalen oder Jahren, von jährlichen Intervallen zu mehrjährigen Intervallen . Wenn die Niveaus einer Reihe von Dynamiken mit mehr oder weniger einer bestimmten Periodizität (wellenartig) schwanken, ist es ratsam, das vergrößerte Intervall gleich der Schwankungsperiode (der Länge der „Welle“ des Zyklus) anzunehmen. Fehlt eine solche Periodizität, erfolgt die Vergrößerung schrittweise von kleinen zu immer größeren Intervallen, bis die allgemeine Richtung des Trends hinreichend deutlich wird. Wenn die Dynamikreihe momentan ist, und auch in Fällen, in denen das Niveau der Reihe ein relativer oder durchschnittlicher Wert ist, ist die Summierung der Niveaus nicht sinnvoll und die aggregierten Zeiträume sollten durch durchschnittliche Niveaus charakterisiert werden. Wenn die Intervalle vergrößert werden, wird die Anzahl der Mitglieder der dynamischen Reihe stark reduziert, wodurch die Niveaubewegung innerhalb des vergrößerten Intervalls aus dem Blickfeld fällt. Um den Haupttrend und seine detaillierteren Merkmale zu identifizieren, wird die Reihe in diesem Zusammenhang mit einem gleitenden Durchschnitt geglättet. Die Glättung einer Reihe von Dynamiken mithilfe eines gleitenden Durchschnitts besteht aus der Berechnung des Durchschnittsniveaus aus einer bestimmten Anzahl der in der Reihenfolge ersten Ebenen der Reihe, dann des Durchschnittsniveaus aus der gleichen Anzahl von Ebenen, beginnend mit der zweiten und dann beginnend mit der dritten usw. Auf diese Weise scheinen sie bei der Berechnung des Durchschnittsniveaus entlang der Zeitreihe vom Anfang bis zum Ende zu gleiten, wobei jedes Mal ein Niveau am Anfang verworfen und das nächste hinzugefügt wird. Daher der Name – gleitender Durchschnitt. Jeder Link des gleitenden Durchschnitts ist das durchschnittliche Niveau für den entsprechenden Zeitraum. Bei einer grafischen Darstellung und bei einigen Berechnungen wird herkömmlicherweise jede Verbindung auf das zentrale Intervall des Zeitraums bezogen, für den die Berechnung durchgeführt wurde (für eine sofortige Reihe auf das zentrale Datum). Die Frage, für welchen Zeitraum die gleitenden Durchschnittsverknüpfungen berechnet werden sollen, hängt von den Besonderheiten der Dynamik ab. Wie bei der Vergrößerung der Intervalle ist es bei einer gewissen Periodizität der Pegelschwankungen ratsam, die Glättungszeit gleich der Schwingungsdauer oder einem Vielfachen ihres Wertes zu nehmen. Bei vierteljährlichen Niveaus mit jährlichen saisonalen Rückgängen und Anstiegen ist es daher ratsam, einen Durchschnitt von vier oder acht Quartalen usw. zu verwenden. Wenn die Niveauschwankungen unregelmäßig sind, ist es ratsam, das Glättungsintervall allmählich zu erhöhen Es entsteht ein klares Trendmuster. Die analytische Ausrichtung der Zeitreihen ermöglicht es Ihnen, ein analytisches Modell des Trends zu erhalten. Es wird auf folgende Weise hergestellt. 1. Basierend auf einer aussagekräftigen Analyse wird eine Entwicklungsstufe herausgegriffen und die Art der Dynamik in dieser Stufe festgestellt. 2. Basierend auf der Annahme des einen oder anderen Wachstumsmusters und der Art der Dynamik, der Form des analytischen Ausdrucks des Trends, der Art der Näherungsfunktion, die grafisch einer bestimmten Linie entspricht – Gerade, Parabel, Exponentiallinie Kurve usw. werden ausgewählt. Diese Linie (Funktion) drückt das erwartete Muster aus, eine sanfte Änderung des Niveaus über die Zeit, d. h. den Haupttrend. In diesem Fall wird jede Ebene der Dynamikreihe herkömmlicherweise als Summe zweier Komponenten (Komponenten) betrachtet: yt = f(t) + ε. Einer von ihnen (Jt = f(t)), der den Trend ausdrückt, charakterisiert den Einfluss permanenter Hauptfaktoren und wird als systematischer Regelanteil bezeichnet. Eine weitere Komponente (е!) spiegelt den Einfluss zufälliger Faktoren und Umstände wider und wird als Zufallskomponente bezeichnet. Diese Komponente wird auch Residuum (oder einfach Residuum) genannt, da sie gleich der Abweichung des tatsächlichen Niveaus vom Trend ist. Es wird also angenommen (bedingt angenommen), dass der Haupttrend (Trend) unter dem Einfluss ständig wirkender Hauptfaktoren entsteht und sekundäre, zufällige Faktoren dazu führen, dass das Niveau vom Trend abweicht. Die Wahl der Kurvenform bestimmt maßgeblich die Ergebnisse der Trendextrapolation. Grundlage für die Wahl des Kurventyps kann eine aussagekräftige Analyse des Wesens der Entwicklung eines bestimmten Phänomens sein. Sie können sich auch auf die Ergebnisse bisheriger Forschung in diesem Bereich verlassen. Die einfachste empirische Methode ist die visuelle: Auswahl der Form eines Trends basierend auf einer grafischen Darstellung einer Reihe – einer gestrichelten Linie. In der Praxis wird die lineare Abhängigkeit aufgrund ihrer Einfachheit häufiger verwendet als die parabolische. Autor: Konik N.V.
▪ Allgemeine Geschichte. Krippe
Energie aus dem Weltraum für Raumschiff
08.05.2024 Neue Methode zur Herstellung leistungsstarker Batterien
08.05.2024 Alkoholgehalt von warmem Bier
07.05.2024
▪ Website-Abschnitt Beleuchtung. Artikelauswahl ▪ Artikel über weißen Terror. Populärer Ausdruck ▪ Artikel Was ist Breiten- und Längengrad? Ausführliche Antwort ▪ Fonio-Artikel. Legenden, Kultivierung, Anwendungsmethoden ▪ Bratunis Artikel. Enzyklopädie der Funkelektronik und Elektrotechnik ▪ Artikel Täuschende Finger. Fokusgeheimnis
Startseite | Bibliothek | Artikel | Sitemap | Site-Überprüfungen
www.diagramm.com.ua |


 - der Anteil der Einheiten der Allgemeinbevölkerung, die nicht in die Stichprobe aufgenommen wurden.
- der Anteil der Einheiten der Allgemeinbevölkerung, die nicht in die Stichprobe aufgenommen wurden.


 Siehe andere Artikel Abschnitt
Siehe andere Artikel Abschnitt 